

说实话,我一开始对”给 Agent 加记忆”这件事是有偏见的。不就是存个 JSON 文件、记几个键值对吗?大多数所谓”记忆系统”到头来就是个带时间戳的键值对仓库,查点历史对话还行,但要让它理解”这个任务是谁布置的、当前被什么阻塞了、项目 A 和项目 B 之间有没有耦合”,完全指望不上。
后来我看到了 Ontology 这个 Skill,在 ClawHub 上有 185k 下载量、619 个星标,安全审计也过了。花了一下午拆完它的设计之后,我发现自己之前对 Agent 记忆的认知确实有点浅。它不是存数据,是在建模关系。
你品,大多数 Agent 写出来的”记忆”是平的。Ontology 做了一件反直觉的事:它要求你先定义实体类型、属性约束、关系规则,然后再往里填数据。听起来像是把简单问题搞复杂了,但跑起来之后你会发现,这种”先建模后写入”的方式,恰恰是让 Agent 产生可靠推理能力的前提。这篇文章会走一遍它的核心设计、实操流程和我自己踩过的几个坑。
环境准备
Ontology 的安装门槛不高。它是标准的 OpenClaw Skill,一条命令就能拉下来:
openclaw skills install ontology
装完之后需要初始化存储目录。它默认把数据写在 memory/ontology/graph.jsonl 里,用 JSONL 追加模式,而不是覆盖写。这个设计细节我后面会聊,但先把它跑起来:
mkdir -p memory/ontology
touch memory/ontology/graph.jsonl
我第一次在这卡了五分钟,不是因为命令写错了,而是没意识到它需要你先定义 schema 之后才能做约束校验。如果你直接 create --type Task 而不先配 schema,它是不会拒绝你的,只不过所有约束校验形同虚设。建议装完第一时间跑 python3 scripts/ontology.py schema-append 把核心类型的必填字段配好,至少把 Task、Project、Person 三个类型的 required 字段补上。
对了,Ontology 依赖 Python 3 环境,没有其他外部服务。所有数据都在本地 JSONL 文件中,不存在同步延迟或网络调用的问题。这一点在后续聊跨技能通信的时候会很关键。
操作流程
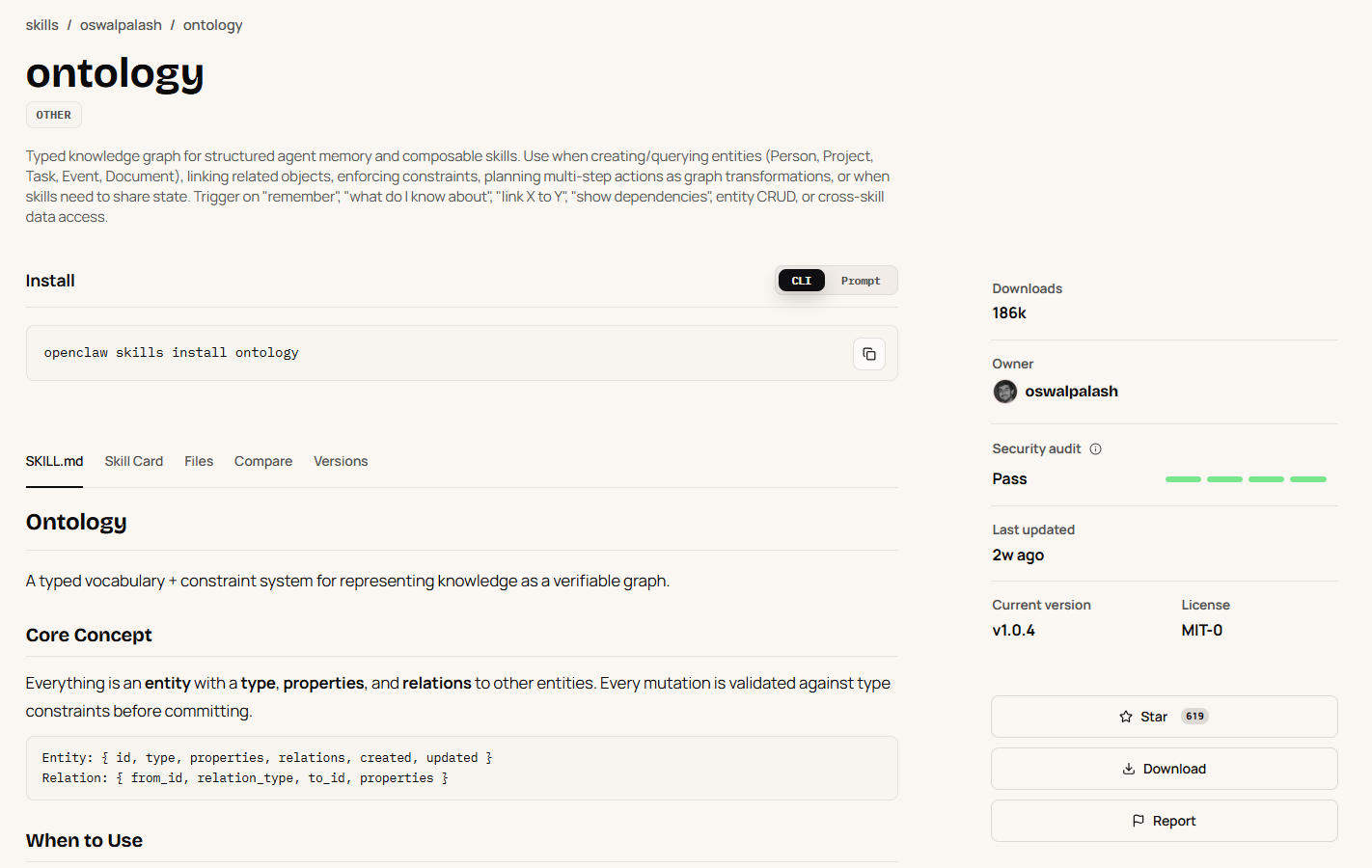
Ontology 的操作围绕四个核心动作展开:创建实体、查询实体、建立关系、验证约束。这四个动作串起来就是一次完整的图谱操作。
先说创建。你告诉它实体是什么类型、有什么属性,它把这件事记成一条 JSONL 记录。跟传统数据库不一样的地方在于,它不要求你事先定义表结构,但如果你配了 schema,它会在写入时做校验。比如 Task 类型要求 title 和 status 是必填字段,你漏了 status,它会在 validate 时直接报错。
python3 scripts/ontology.py create --type Person --props '{"name":"Alice","email":"alice@example.com"}'
python3 scripts/ontology.py create --type Project --props '{"name":"Website Redesign","status":"active"}'
python3 scripts/ontology.py create --type Task --props '{"title":"Draft wireframes","status":"open","assignee":"p_001"}'
查询这块有个让我挺意外的设计。它支持用 --where 做条件过滤,语法是 JSON 格式的键值匹配。比如查所有 open 状态的任务:
python3 scripts/ontology.py query --type Task --where '{"status":"open"}'
python3 scripts/ontology.py get --id task_001
但真正让它区别于普通 KV 存储的,是关系查询。你可以查某个项目的所有任务、某个人的所有待办、或者某个任务被哪些东西阻塞了:
python3 scripts/ontology.py relate --from proj_001 --rel has_task --to task_001
python3 scripts/ontology.py related --id proj_001 --rel has_task
我在实际跑的时候发现一个容易忽略的点:关系也是有类型约束的。schema 里可以定义 has_owner 关系的 from_types 和 to_types,如果你把 Task 关联到一个 Document 类型的实体上,validate 会直接报类型不匹配。这个约束机制在早期用起来有点”烦”,但当你数据量上去了之后,你会发现它替你拦住了很多因果关系上的错误。
关键设计
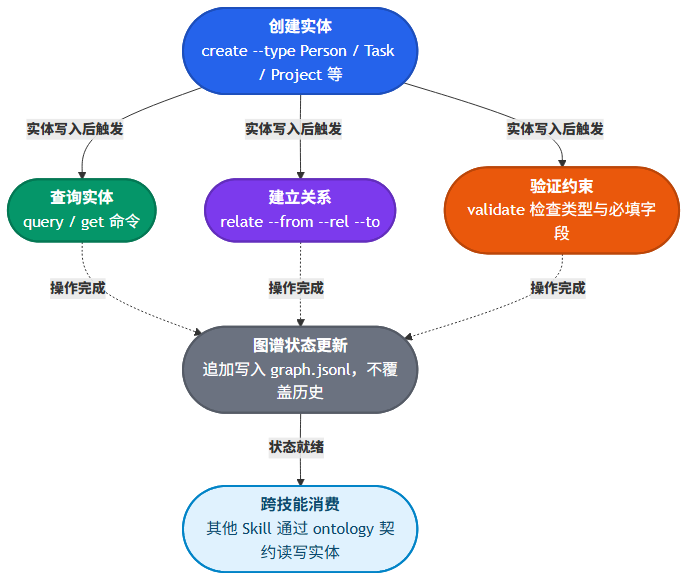
拆完 Ontology 的架构,有三个设计决策让我觉得这个作者确实想清楚了 Agent 记忆系统到底需要什么。
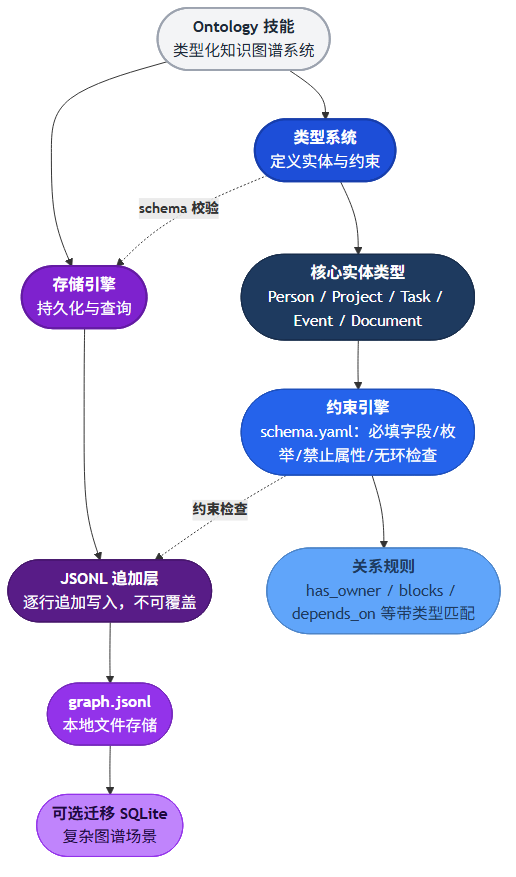
第一个是 JSONL 追加模式。很多人在做本地存储时会自然选择 SQLite 或一个内存字典 dump 到 JSON。Ontology 选了 JSONL 追加写,每条操作独立成行,不覆盖、不合并。这个选择的核心价值不在性能,在可追溯性。你永远可以看到图谱的完整变更历史,哪条记录什么时候创建的、谁关联了谁,所有操作都有操作日志可查。坏处也很明显,文件会一直膨胀,大量冗余的旧状态不会被自动清理。作者在文档里也提到了,对于复杂图谱建议迁移到 SQLite,但默认方案的选择逻辑是对的:简单场景下,可追溯性比空间效率重要得多。
第二个是约束系统和 schema 的前置设计。Ontology 的 schema 定义在 memory/ontology/schema.yaml 里,不仅管必填字段,还管枚举值范围、禁止属性、关系类型匹配、甚至无环性检查。比如 Credential 类型禁止直接存 password、secret、token 字段,它强制你通过 secret_ref 间接引用,避免密钥泄露。Tasks 之间的 blocks 关系标记了 acyclic: true,防止你搞出一个互相阻塞的死循环。这种约束前置的设计在初期会让你觉得”多写了好多配置”,但当图谱的数据量积累到几百条实体之后,你会庆幸这些约束在。
第三个设计是 Skill Contract。Ontology 提出了一套让其他 Skills 声明自己对图谱读写需求的契约机制。每个 Skill 在其 SKILL.md 中声明 ontology.reads 和 ontology.writes 的范围,附带前置条件和后置条件。这样一来,当你同时挂了五六个 Skills 在一个 Agent 上时,不会出现两个 Skill 争抢同一条 Task 的归属者或者互相覆盖对方写入的状态。这个设计在我见过的 Agent 技能生态里算比较超前的。
使用场景
Ontology 最直接的场景是项目管理类 Agent。比如你的 Agent 需要跟踪多个并行项目、每个项目下面十几个任务、任务之间有依赖关系、还有人员分配和时间节点。这种场景下用普通键值存储基本不可维护,而 Ontology 的实体类型体系天然适配。
我拿一个实际例子跑了一下:一个三人的小团队,两个项目并行,每个项目五到八个任务。用 Ontology 建模之后,Agent 可以回答”项目 A 当前有多少个被阻塞的任务”“Alice 手上同时在做的任务有哪些””哪些任务没有 assignee”这种需要跨实体推理的问题。这些查询在传统 KV 存储里需要写大量过滤逻辑,在 Ontology 里一条 related --rel has_task 就能拿到。
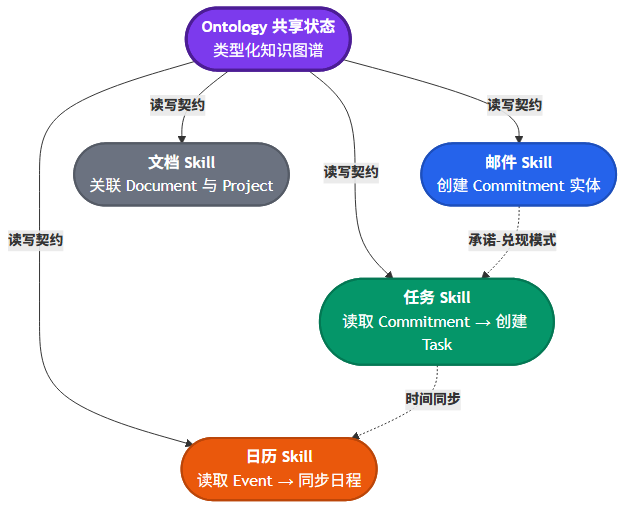
另一个我没有预期到的使用场景是跨技能通信。Ontology 设计了一套”承诺-兑现”模式:邮件 Skill 读到一封邮件后创建一个 Commitment 实体,描述”某人承诺在某个时间前完成某事”。任务管理 Skill 周期性地扫描 pending 状态的 Commitment,自动创建对应的 Task 并建立溯源关联。两个 Skill 不直接通信,通过 Ontology 这个共享状态层实现了松耦合的信息流转。
// 邮件技能创建承诺
{"op":"create","entity":{"id":"cmt_001","type":"Commitment","properties":{"source_message":"msg_042","description":"Send report by Friday","due":"2026-01-31"}}}
// 任务技能读取承诺并创建任务
{"op":"create","entity":{"id":"task_008","type":"Task","properties":{"title":"Send report","due":"2026-01-31","status":"open"}}}
{"op":"relate","from":"task_008","rel":"derived_from","to":"cmt_001"}
这个场景的价值在于,它把”Agent 记忆”从单技能的上下文存储升级到了多技能的共享状态层。以前 Agent 的不同 Skill 之间基本靠”把上一步的输出粘到下一步的 Prompt 里”来传信息,Ontology 给出了一套更结构化的方案。
洞察与反思
用了 Ontology 之后我最大的感受是:Agent 记忆系统的瓶颈不在存储容量,在结构。没有类型系统的记忆,数据越多越乱。Ontology 用一套不算复杂的实体-关系模型解决了这个核心问题,但它的边界也很清晰。
它不适合实时性要求高的场景。JSONL 追加写和约束校验都是操作级开销,高并发大量写入时性能会掉得很明显。文档里提了 SQLite 迁移方案,但迁移本身需要开发者在两种模式之间做选择,对于非技术用户是个门槛。
另一个让我觉得有意思的点是:Ontology 本质上是在 Agent 的记忆层引入了一个轻量级的数据库范式。Schema 约束、关系完整性、无环性检查,这些概念来自传统数据库设计,但被压缩成了一个几十 KB 的 YAML 配置文件加一个 Python 脚本。它不是要替代真正的数据库,而是在”写个 JSON 凑合”和”搭一个 PostgreSQL”之间找到了一个精准的中间地带。
185k 下载量说明社区对这个方向是有认可的。但我更期待的是后续版本在自动 schema 推断上的进展。现在的 schema 完全靠人工编写,如果 Agent 能在使用的过程中根据数据类型自动建议 schema 约束,那体验会有质的提升。毕竟让用户自己写 YAML 配置始终是 Ontology 最大的上手门槛。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/oswalpalash/ontology |
| 安全审计 | https://hub.openclaw.ai/oswalpalash/ontology/security-audit |
| SkillHub 中文站 | https://skillhub.cloud.tencent.com/skills/ontology |
总结
Ontology 解决的不是”Agent 能不能记住东西”的问题,而是”Agent 记住之后能不能理解这些信息之间的关系”。它用一个类型化的实体-关系模型,把 Agent 记忆从扁平键值对升级到了可推理的结构化图谱。
如果你现在的 Agent 只有一个 Skill、任务量不大、不需要跨技能共享状态,Ontology 对你来说可能有点重。但一旦你的 Agent 开始管理多个并行项目、在多个 Skill 之间传递上下文、或者需要回答”A 和 B 是什么关系”这类推理性问题,Ontology 提供的约束和关系查询能力会让你少写很多胶水代码。
先装一个试试吧。记得第一时间配好 schema,不然等于白装。
FAQ 常见问题
Q: Ontology 适合什么规模的 Agent 项目?
A: 小型项目(单一 Skill、任务数少于 20)用键值对就够。中型项目(多 Skill 协作、任务数 20-100)是 Ontology 的甜点区。大型项目(任务数 100+)建议迁移到 SQLite。
Q: 和直接写个 SQLite 数据库有什么区别?
A: Ontology 的优势在 Agent 原生集成。它有 CLi 命令、Skill Contract 机制、schema 约束校验、JSONL 可追溯性,不用你从头搭一层 ORM 和关系验证逻辑。如果你已经有成熟的数据库架构,直接用它可能反而多一层抽象。
Q: 最大的缺点是什么?
A: Schema 需要人工编写,上手有一定成本。JSONL 在大量写入时性能不如 SQLite。没有内置的自动清理机制,文件会持续膨胀。对于非技术用户,写 YAML 配置定义类型约束这件事本身就是一个门槛。
Q: 安全方面有什么需要注意的?
A: 安全审计已通过。Credential 类型设计上禁止直接存储密码和密钥,强制使用间接引用。但所有数据存储在本地 JSONL 文件中,不加密。敏感项目需要自己处理文件级加密。