

你上一次在终端里手打
gh pr checks是什么时候?我猜大多数人的回答是”从来没用过”。GitHub CLI 装是装了,但那些子命令名和参数格式,每次都得现查文档。ClawHub 上 steipete 发布的 GitHub Skill 解决的就是这个问题。它把
ghCLI 的常用操作封装进 OpenClaw 的 Skill 系统里,让你在非 Git 目录下也能用自然语言驱动 GitHub 操作。185k 下载量、618 Star,这个数字放在一个”CLI 封装”技能上,说实话让我挺意外的。
说真的,这篇文章不是来教你怎么装这个 Skill 的,一条命令的事。我更想拆清楚的是,为什么一个看起来”就是把 gh 命令包了一层”的东西,能拿到 185k 下载量。这个数字本身就是个值得追问的信号。
环境准备
装这个 Skill 的唯一前置条件是已经装了 OpenClaw 和 GitHub CLI。OpenClaw 的安装去官网 openclaw.ai 看引导就行,GitHub CLI 用 winget install GitHub.cli 或者 brew install gh 搞定。都没什么坑。
Skill 本身的安装只有一行:
openclaw skills install github
跑完之后不需要额外配置,Skill 直接可用。这一点我挺欣赏的,没有 OAuth 流程、没有 API Key 配置、没有环境变量。它复用的是你本机已经登录好的 gh auth 会话。
唯一可能踩坑的地方是 gh 本身没登录。如果你跑 gh auth status 返回的是未登录,那 Skill 的所有功能都会报错。先 gh auth login 走一遍 OAuth,选 HTTPS 协议就行。我第一次在这卡了两分钟,以为是 Skill 装坏了,结果只是 gh 没登。
操作流程
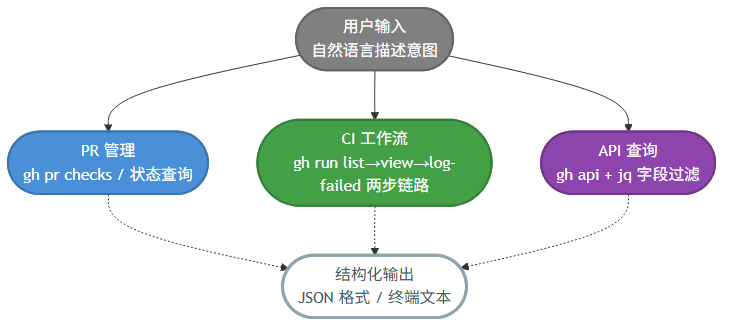
GitHub Skill 的核心操作链路围绕 gh 的三个能力域展开:PR 管理、CI 工作流、API 查询。每个域对应一组简洁的命令封装。
PR 管理这块,最常用的场景是”这个 PR 的 CI 过了没”。以前我得打开浏览器、点到 PR 页面、找到 Checks 标签。现在 Agent 直接跑:
gh pr checks 55 --repo owner/repo
一行命令拿到所有 checks 的状态和链接。--repo 参数是必须的,因为 Skill 的环境不一定在 git 目录里。这是个设计上很聪明的约束,避免了”自动检测仓库”可能带来的上下文错误。
CI 工作流的查询链路更完整一点。先用 gh run list 列出最近的运行记录,找到失败的那个 run id,然后用 gh run view --log-failed 只看出错的那几步日志。
gh run list --repo owner/repo --limit 10
gh run view 1234567890 --repo owner/repo --log-failed
这个”先列后查”的两步链路让我想起 Kubernetes 的 kubectl get pods 然后 kubectl logs。熟悉的感觉,上手几乎零成本。
真正让我觉得”这设计有点东西”的,是 API 查询能力的引入。gh api 直接调用 GitHub REST API,配合 --jq 做字段过滤。这意味着你能查到所有 gh 子命令覆盖不到的数据。
gh api repos/owner/repo/pulls/55 --jq '.title, .state, .user.login'
比如你想批量查一个 org 下所有 repo 的 Star 数、想知道某个 milestone 关联了多少 issue——这些 gh 子命令都不支持,但 API 端点全都有。Skill 把这条路打通了,等于给 Agent 开了一个”GitHub 数据全量查询”的后门。
关键设计
拆完操作流程,有几个设计决策值得单独拿出来说。
第一个是 --repo 显式声明的约束。GitHub CLI 本身在 git 目录下可以自动推断仓库,但 Skill 强制要求显式传 --repo owner/repo。这个设计看着像是”多此一举”,实际上避免了 Agent 在非 git 目录下执行时因上下文缺失而误操作别的仓库。OpenClaw 的 Agent 不一定在项目目录里跑,不显式指定仓库的话,鬼知道它会改到哪个 repo 上去。这个约束看似是限制,其实是安全兜底。
第二个是 JSON 输出的优先级设计。gh 的很多子命令支持 --json 参数输出结构化数据,Skill 文档里专门强调了这一点。这说明设计者的意图不只是”让 Agent 能跑命令”,而是”让 Agent 能消费结构化结果”。对 Agent 来说,解析 JSON 比解析终端 ANSI 彩色文本靠谱太多了。
第三个让我有点疑惑的是,Skill 没有封装任何写入操作。gh pr create、gh issue create、gh pr merge 这些写操作全都没有。文档里只展示了读操作和查询。这可能是刻意为之,把”读”和”写”分开,降低 Skill 的破坏半径。也有可能后续版本会加。不管怎样,目前这个”只读优先”的设计确实降低了使用风险。
使用场景
这个 Skill 最对口的场景是 DevOps 自动化。比如说,你的 CI 跑挂了,Agent 要自己去排查原因。以前 Agent 看到的是”CI failed”这一句话,现在它能自己跑 gh run view --log-failed 把出错的日志拉出来,然后分析问题、甚至直接修。
我自己最常用的场景是 PR Review 前的状态检查。打开一个 PR 之前,先让 Agent 跑一遍 gh pr checks,确认所有 CI 都绿了再看代码。这个流程省掉的不只是几秒钟的浏览器操作,是上下文切换的成本。从 IDE 切到浏览器、找仓库、找 PR、点 Checks——这个切换本身就会打断心流。
另一个很多人忽视的场景是跨仓库数据聚合。假设你维护了五个微服务,想快速了解一下这周各仓库的 issue 趋势。gh issue list --json 配合 jq 过滤,几分钟就能拉出一份数据汇总。纯手工操作的话,五个 repo 点来点去,半天就没了。
当然,它也有明显的边界。没有写入操作意味着你不能用它来创建 PR 或者关闭 issue。如果 CI 日志特别大,--log-failed 拉出来的内容可能会超出 Agent 的上下文窗口。另外,gh api 需要你知道准确的 API 端点路径,对 GitHub API 不熟的人还是得先翻文档。
洞察与反思
拆完这个 Skill,我最大的感受是:好设计不一定要复杂。GitHub Skill 只有一页 SKILL.md,不到 100 行,功能就是 gh 命令的几个封装。但它拿下了 185k 下载量。这个数字反过来证明了一件事——OpenClaw 社区对”让 Agent 能干活”的需求远比”让 Agent 变聪明”更迫切。
很多人对 Agent Skill 的期待是”能做更多事”,但实际壁垒往往不在能力上,在接口上。Agent 够聪明了,它缺的是接入真实系统的管道。GitHub Skill 做的就是这件事:把 gh CLI 这个已经存在的管道,用 Agent 友好的方式重新接了一遍。
这让我重新审视 ClawHub 上的 Data & APIs 类技能。它们看起来都很”无聊”,Github、Notion、Slack、Linear——全是已有 API 的薄封装。但这种”无聊”恰恰是价值所在。薄封装不增加认知负担,不引入新抽象,就是把现有工具塞进 Agent 的工作流里。这个策略比重新发明一个”Agent 专用的 Issue 管理系统”聪明太多了。
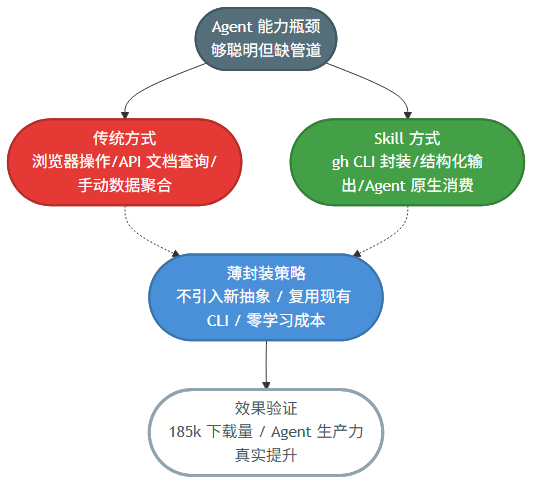
换个角度看,GitHub Skill 的”薄”反而是它最大的优点。它不试图定义一套新的 GitHub 交互范式,不发明新的 DSL,不引入新的权限体系。它就做一件事:让 Agent 能说 gh 的语言。这种克制在 AI 工具圈挺罕见的。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub 页面 | https://clawhub.ai/steipete/github |
| 作者 GitHub | https://github.com/steipete |
| ClawHub 仓库 | https://github.com/openclaw/clawhub |
| OpenClaw 官网 | https://openclaw.ai |
| ClawHub 文档 | https://docs.openclaw.ai/clawhub/ |
总结
GitHub Skill 是一个典型的”薄封装”案例。它不创造新能力,而是把 GitHub CLI 的能力翻译成 Agent 能消费的语言。185k 的下载量说明了一个朴素的事实:Agent 生态当前最缺的不是更聪明的模型,是更多连通真实系统的管道。
如果你已经在用 OpenClaw,装这个 Skill 几乎是零成本的选择。一条命令、零配置、即装即用。如果你还没用过 gh CLI,这也是一个不错的入门契机。
具体怎么用,取决于你的工作流。如果你每天在 PR 和 CI 之间切来切去,它能把切换成本压到几乎为零。如果你维护多个仓库,跨仓库查询的便捷性会让你回不去浏览器。
FAQ 常见问题
Q: 这个 Skill 适合什么人?
A: 已经在用 OpenClaw 的开发者,尤其是日常需要频繁操作 GitHub PR 和 CI 的。如果你还没用 OpenClaw,单独为这个 Skill 折腾环境不划算。
Q: 和直接装 gh CLI 有什么区别?
A: 核心区别在于消费方式。gh CLI 是给人用的,输出是终端文本。GitHub Skill 是给 Agent 用的,输出强调 JSON 结构化,Agent 能直接解析并做出后续动作。
Q: 为什么没有写入操作?
A: 文档没有给出官方解释,但从设计逻辑看,应该是故意把”读”和”写”拆开,降低误操作风险。后续版本可能会通过权限控制引入写操作。
Q: 最大的缺点是什么?
A: 功能覆盖面窄,只封装了 gh 的一小部分命令。如果你需要复杂的仓库管理(branch 操作、release 管理),这个 Skill 帮不上忙。另外 --log-failed 对超大日志可能超出上下文窗口。