
文章概览

-
引言
-
数字人直播架构 -
数字人推流端对接
-
SRS生产环境搭建与调优
-
多平台分发与合规接入
-
容灾架构与成本控制
-
避坑指南
-
结语:数字人直播的下一站
作者介绍:
王涛,2023年9月加入去哪儿旅行,目前在技术中心酒店主站团队,主要负责国内酒店主站相关业务以及酒店AIGC相关项目落地。
黄哲,2020年9月加入去哪儿旅行,目前在技术中心酒店研发主站团队,主要负责国内酒店主站相关业务以及agent平台基建和日常维护工作。
引言
去年我们团队完成了数字人形象克隆和实时渲染引擎的接入,当我们自信满满地把渲染画面接入客户端,推到APP测试——结果当场翻车:直播延迟10秒、卡顿掉帧、几小时后直播中断。更惨的是,当我们要同时开50个直播间时,推流服务直接卡死。
数字人直播的后端,远比想象中复杂。
与真人直播不同,数字人直播有几个致命特点:
-
直播10小时必断流
-
打开首屏,必卡5s以上
-
端到端延迟稳定在10秒以上
-
日志里满是内存泄漏和推流超时
我们这才清醒:让一个数字人动起来是技术演示,让一百个数字人7×24小时稳定卖货是系统工程。
一、数字人直播架构
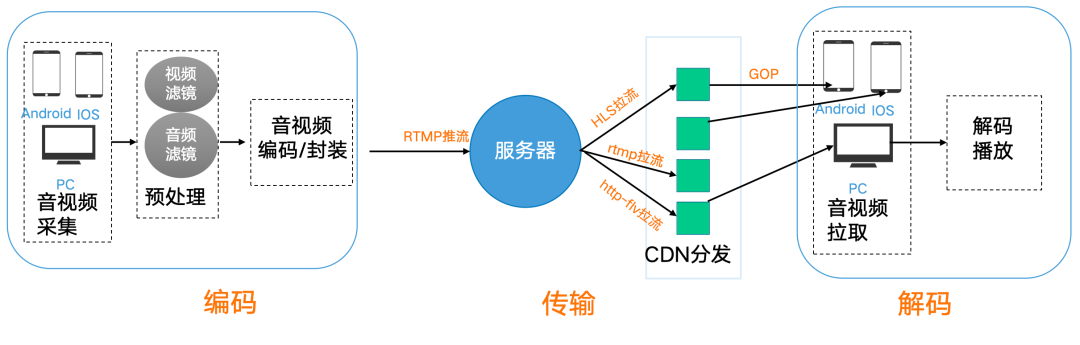
众所周知,直播就像电视台实时转播:主播是”前方记者”把画面传回电视台(推流),电视台接收处理后播出(直播服务),观众打开电视收看(拉流);技术上推流是将音视频数据压缩编码后通过网络协议上传到服务器,直播服务负责转码、分发和调度,拉流则是观众端从服务器请求数据流并解码播放,三者构成了从内容生产到消费的全链路实时传输系统。
1.1 直播系统选型
基于通用的直播架构,通常包含三个部分:推流、直播服务、拉流。
下面我们将详细介绍下我们的直播架构是如何选型的。
1.1.1 编码推流选型
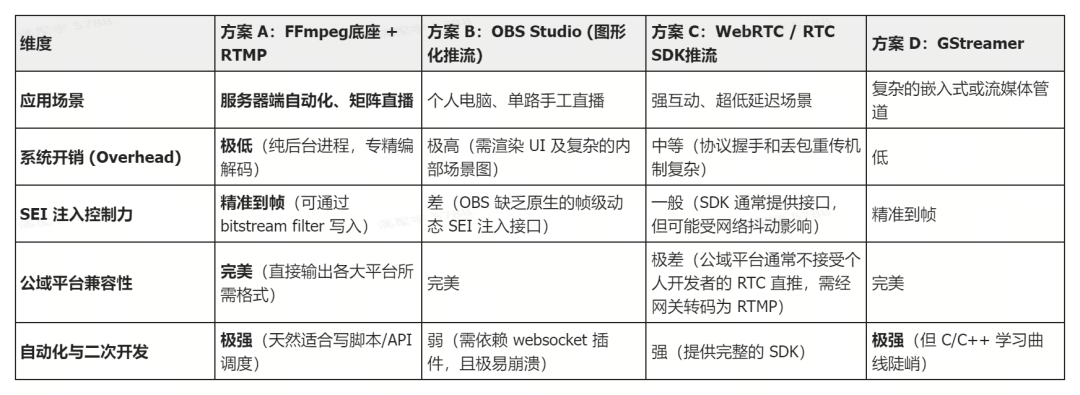
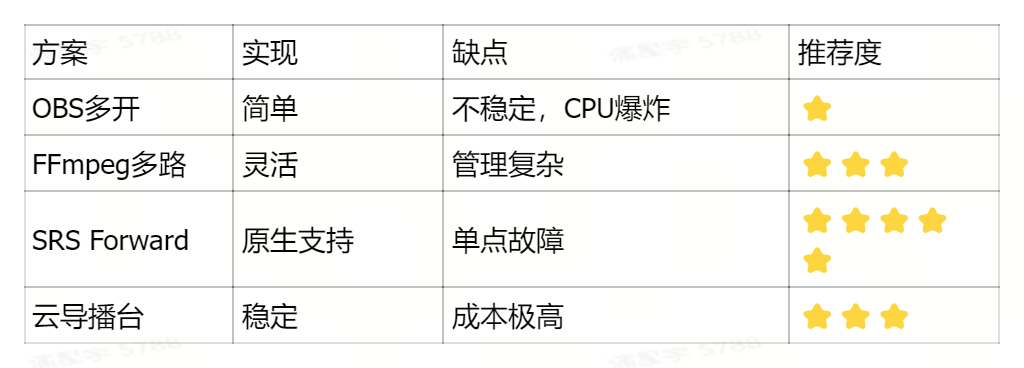
我们知道真人直播大多使用带界面的 OBS 推流。但面对几百个 7×24 小时运行的数字人矩阵,OBS 高昂的资源开销和极差的自动化支持简直是灾难。
我们需要的是无头化、免人工干预的底层进程。因此,我们果断选择了 FFmpeg + RTMP。它就像个没有感情的“后台打工人”,资源占用极低,天生适合脚本批量调度;更能像手术刀一样,将商品弹出数据精准到帧(SEI)注入视频流,完美满足数字人自动化带货的严苛诉求。
以下为常用方案对比:
1.1.2 直播服务选型
如果直接买大厂的商用云直播,500 个直播间 7×24 小时跑满的账单堪称天价;如果用老牌开源的 Nginx-RTMP,它的并发能力和多协议转换(特别是对 WebRTC 的原生支持)又显得力不从心。
最终,我们锁定了开源流媒体神器——SRS。它不仅免费,更是个单进程就能扛住数千路并发的“性能怪兽”,完美契合我们的低成本、云原生(Docker)部署。最绝的是它极强的“翻译”能力:稳稳接住推来的流后,能瞬间分发出 RTMP、HLS 和 WebRTC 等多种信号,成了我们直播底座的定海神针。
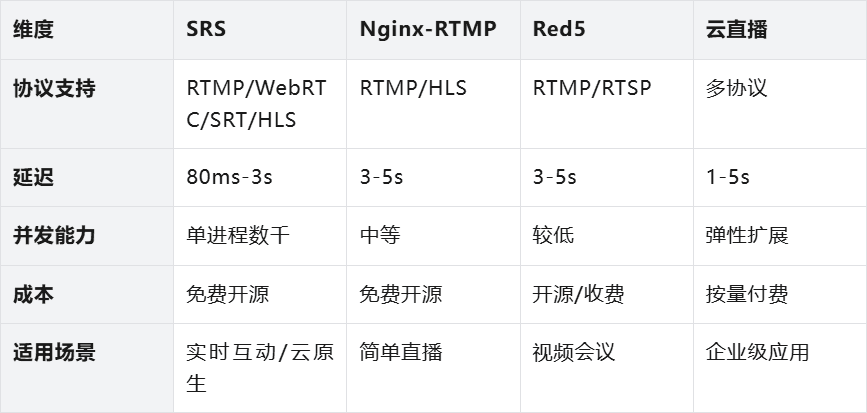
结论:SRS是当前开源流媒体服务器的首选方案,特别适合需要低延迟、多协议、云原生部署且预算有限的场景。
1.1.3 拉流协议栈选型
提到拉流,技术圈言必称 WebRTC 的毫秒级零延迟。但数字人是按产品脚本单向播报的,根本不存在真人互动的“物理延迟”,晚个两三秒观众完全无感。
因此我们没有盲从,而是打出了一套分场景组合拳:对外,主推稳定抗造的 RTMP + 兼容性极佳的 HLS,确保观众端流畅不卡顿;对内,我们将 WebRTC 作为内部巡查的“特供路线”——运营人员需同屏监看 50 个直播间,利用 WebRTC 原生 <video> 标签拉流,能省下海量的浏览器内存,直接拯救了随时可能崩溃的监控大屏。

关键决策
-
推流用RTMP:数字人画面是程序化生成,不存在”摄像头采集延迟”,RTMP的1秒延迟可接受,但稳定性远超WebRTC
-
WebRTC仅用于监看:运营人员需要同时看50个直播间画面,用WebRTC的
<video>标签比FLV更省浏览器资源 -
HLS: 直播脚本本身是基于产品介绍,需要完整播完,本身就会有延迟,整合文字回复+视频回复,保证用户体验。
1.2 落地架构拓扑设计
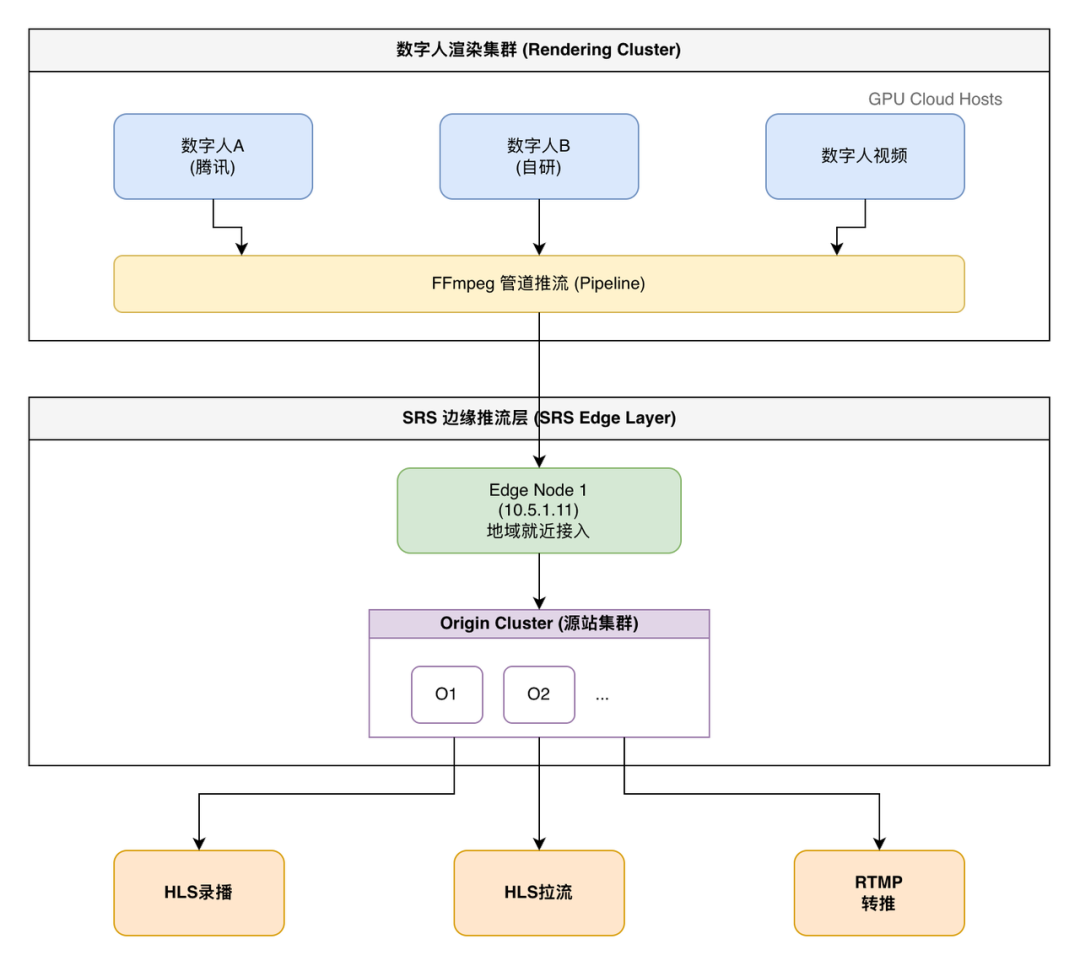
分层逻辑
-
源:数字人引擎推流、数字人视频
-
Edge层:地域就近接入,降低公网传输延迟
-
Origin层:源站集群汇聚,统一转推,提供拉流
-
分发层:通过SRS Forward功能转推
二、数字人推流端对接
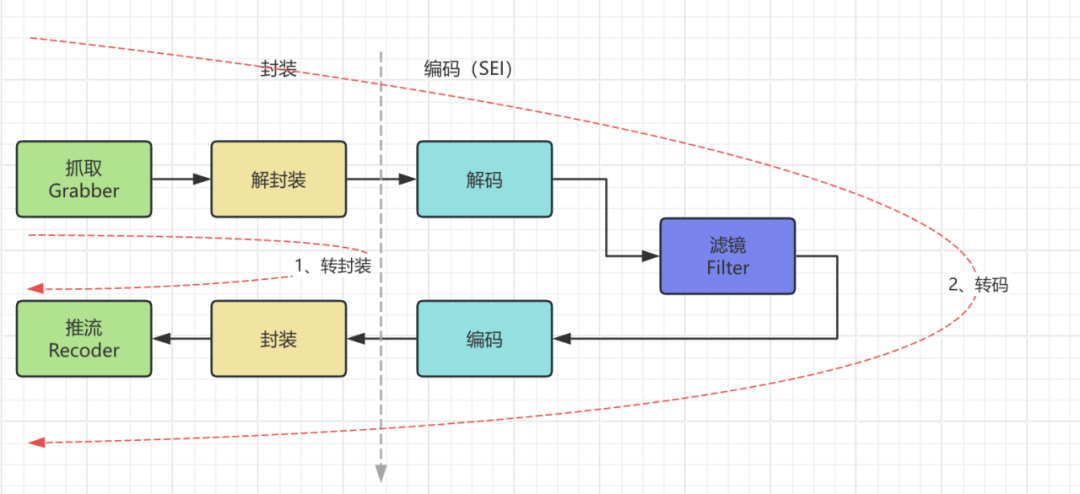
首先是编码推流(”前方记者”把画面传回电视台),数字人渲染引擎需要把画面推送到SRS,最稳定的方式是FFmpeg管道推流。我们使用了以下配置:
2.1 编码推流
-
编码器选择:
-
libx264:CPU编码,质量好,适合云主机(GPU留给渲染) -
h264_nvenc:如果渲染节点GPU有剩余算力,可用硬件编码 -
GOP设置:
-
数字人画面变化小,设置
-g 50(2秒一个关键帧) -
平台通常要求2-4秒GOP,太短浪费带宽,太长延迟高
-
断线重连:
-
FFmpeg遇到网络抖动会直接退出,需要外层脚本监控重启:
//javawhile(true)exec ffmpeg
2.2 实时、合规信息添加(SEI)
通常需要在直播间实时显示合规、商品信息(准确、及时)。
SEI实现动态信息嵌入
SRS支持SEI(Supplemental Enhancement Information)插入:
ffmpeg ... -c:v libx264 -sei_side_data on -metadata comment="ProductId=1" -f flv rtmp://srs/live/stream
直播商品信息嵌入
通过javacv实现sei的动态编码,保证当前播放的视频与商品信息强一致。
三、SRS生产环境搭建与调优
接下来处理的是我们的直播服务(电视台);搭建SRS集群不是”复制粘贴配置文件”那么简单。我们在前几次部署中踩过的坑包括:直播延迟高、多路推流时系统崩溃。这一章我会详细解释每一个关键决策背后的技术权衡。
3.1 基础环境准备
服务器配置
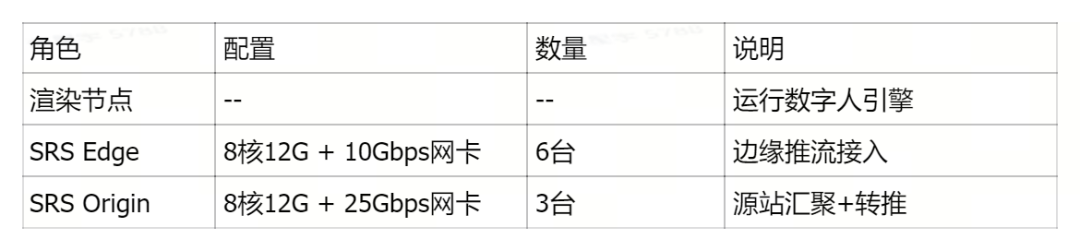
针对I/O密集型 且 大流量 专项配置(/etc/sysctl.conf):
-
高吞吐量,针对网络缓冲区大小设置(128MB,非常大的缓冲区)
-
实时性,使用bbr协议实现拥塞控制
-
突发流量,调高backlog值,避免瞬间爆发的流量导致的数据包丢失
-
高并发,设置文件句柄,系统级、进程级限制均提升到200w左右
#网络缓冲区大小(针对高吞吐量)net.core.rmem_max = 134217728net.core.wmem_max = 134217728#单个连接在高延迟网络上也能维持高吞吐量,最大128MBnet.ipv4.tcp_rmem = 4096 87380 134217728net.ipv4.tcp_wmem = 4096 65536 134217728net.core.netdev_max_backlog = 5000#BBR是Google开发的算法,通过实时估算网络的瓶颈带宽和往返延迟来决定发送速度。当网络出现短暂抖动时,BBR能保持更稳定的发送速率,从而减少视频卡顿,降低延迟。net.ipv4.tcp_congestion_control = bbr#文件句柄限制(应对高并发连接)fs.file-max = 2097152fs.nr_open = 2097152
3.2 SRS Edge节点配置(边缘推流接入)
-
边缘节点rtmp推流到origin节点,配置origin节点地址(核心能力)
-
配置flv、WebRTC 协议实现实时监控(实时监控)
-
配置快速失败超时时间(可用性、防止阻塞)
edge.conf:
# RTMP推流转发到源站vhost __defaultVhost__ {mode remote;origin *:1935 *:1935; # Origin集群地址# 快速失败forward_timeout 5s;# flvhttp_remux {enabled on;mount [vhost]/[app]/[stream].flv;hstrs on;}# WebRTC播放rtc {enabled on;rtmp_to_rtc on;}}
3.3 SRS Origin节点配置(源站汇聚+转推)
-
play配置主要用于rtmp协议降低延迟、增强抗抖动能力
-
hls为主要的拉流协议,保存1小时,2s切片(实时性)
-
forward转推其他平台,例如抖音、b站等(第三方平台)
origin.conf(核心配置):
# SRS Originlisten 1935;max_connections 5000;worker_threads 8; # 绑定8核CPUplay {# 关闭GOP缓存gop_cache off;# 队列长度控制(缓冲10帧)queue_length 10;# 减少发送间隔抖动reduce_sharp_duration 100;}vhost __defaultVhost__ {# HLShls {enabled on;hls_path /data/recordings;hls_fragment 2; # 2秒切片hls_window 3600; # 保留1小时}# 转推其他平台forward {enabled on;destination rtmp://xxxxxx/live/stream_key;}}
3.4 SRS性能调优:从10秒延迟到3秒的实战
3.4.1 延迟优化三板斧
第一斧:推流gop设置 50,2s一个关键帧
gop设置不合理,播放器就需要等待下一个Idr帧才能播放.默认10s会导致前端基本打开就卡住。
影响:首屏加载从10s变为毫秒级,基本实现秒开
第二斧:启用低延迟模式
# srs.conf全局配置publish {mr off; # 合并写关闭,立即转发min_latency on; # 启用最低延迟模式srt_to_rtmp on; # SRT转RTMP低延迟路径}
第三斧:前端播放器配合
提前预加载拉流地址,进入后直接拉流,避免进入直播页面才获取直播拉流地址。
3.4.2 高并发下的srs优化
# srs.conflisten 1935;max_connections 10000; # 理论最大值worker_threads 8; # 等于CPU核心数# 日志控制(高并发时日志是性能杀手)srs_log_level warn; # 警告srs_log_tank console; # 直接输出,不写文件(或关闭)
3.4.3 监控指标与告警
SRS自带统计API
# 查看当前推流统计curl http://srs-origin:1985/api/v1/summaries# 关键指标:# - system.cpu_percent: CPU占用(>80%告警)# - system.mem_ram_kbyte: 内存占用# - system.net_sockets: 当前连接数# - system.net_recv_bytes/ send_bytes: 带宽
Prometheus + Grafana监控+飞书报警
# 部署srs-exporter采集指标scrape_configs:- job_name: 'srs'static_configs:- targets: ['srs-origin:1985']metrics_path: '/api/v1/metrics'
关键告警规则:
-
推流断开:某路流
active状态变为false -
延迟过高:帧率<20fps持续30秒
-
带宽打满:出网流量>阈值(如8Gbps)
四、多平台分发与合规接入
4.1 SRS Forward多路转推
核心需求:一路数字人流,同时推送到抖音、视频号、淘宝。
方案对比:
4.2 SRS Forward配置
vhost __defaultVhost__ {# 动态转推(通过HTTP API控制)forward {enabled on;# 目标平台地址(实际需通过脚本动态获取推流码)destination rtmp://push.example.douyin.com/live/xxx;destination rtmp://push.example.shipinhao.com/live/xxx;}}
4.3 动态推流码管理
各平台推流码有有效期,需要中间服务动态获取:
# Python示例:获取平台推流地址后更新SRS配置import requestsdef update_srs_forward(stream_key, platform_urls):"""通过SRS HTTP API动态添加转推目标"""srs_api = "http://srs-origin:1985/api/v1/clients"# 先查询当前流IDr = requests.get(f"{srs_api}?count=100")clients = r.json()['clients']# 找到对应stream_id,发送forward命令for client in clients:if client['name'] == stream_key:# 通过publish命令触发forward(SRS 6.0+支持)requests.post(f"{srs_api}/{client['id']}/forward", json={"destinations": platform_urls})
五、容灾架构与成本控制
5.1 高可用设计
推流端双活
# 数字人端同时推两路流到不同Edge节点#Stream_001 → SRS-Edge-A (10.0.1.10)Stream_001 → SRS-Edge-B (10.0.1.11)# Origin层根据健康检查选择主源
SRS热升级
# SRS支持SIGUSR2信号热重启(不中断连接)# 验证新版本正常后,优雅关闭旧进程killall -s SIGUSR2 srs
降级预案
当SRS集群故障时,关闭直播入口。
5.2 成本优化
单路数字人直播成本对比:

节省关键点
-
带宽成本:使用cdn一次回源,减少机房宽带费用
-
计算成本:K8s HPA根据推流数自动扩缩容
-
存储成本:录制文件直接转存冷存储(华为云对象存储低频访问)
六、避坑指南
6.1 离线视频动态切换推流ffmpeg
-
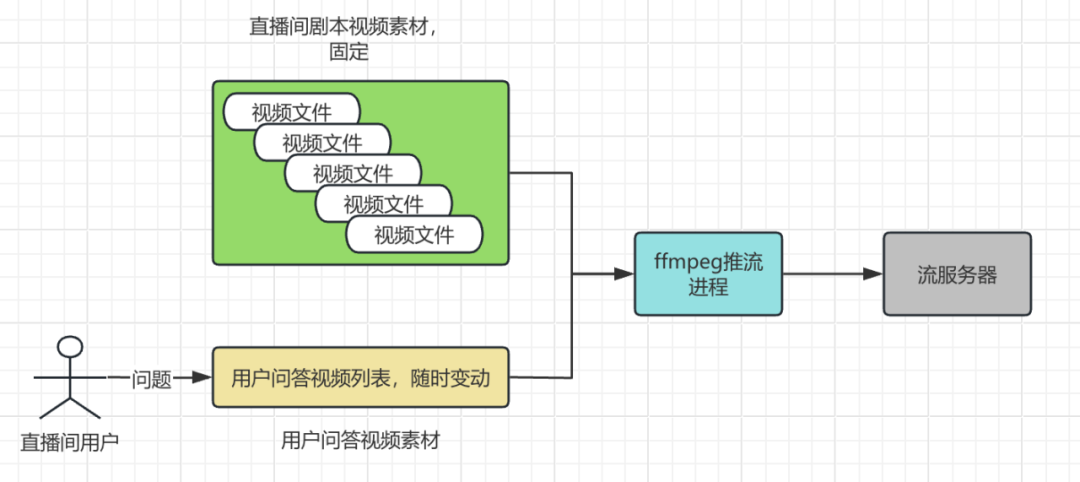
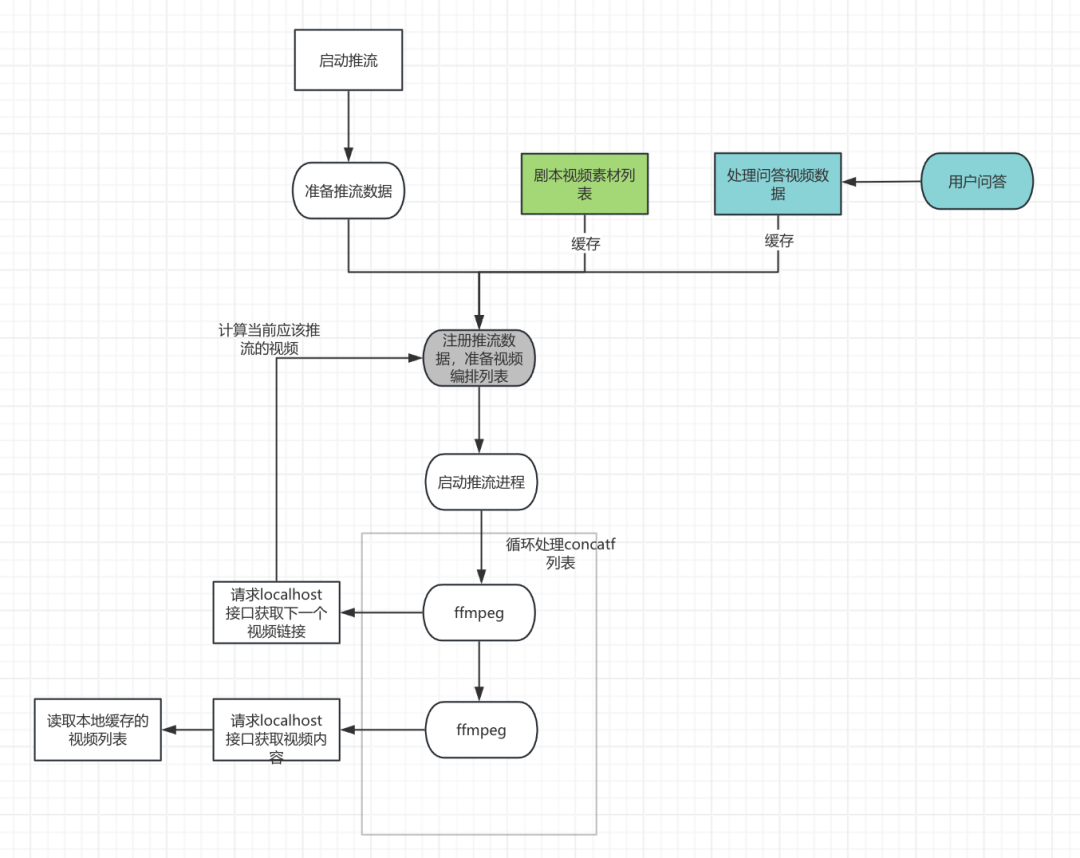
目标:7*24h直播,推送视频列表需要动态可调整,支持用户问答与商品视频动态插播。
-
现状与冲突:concat基于本地文件协议实现动态插入视频比较复杂,需要自己监控推流进度,动态更改下一个推流文件,滤镜、管道等也需要自己感知推流进度,实现不精准。
-
解决与结论:化被动为主动,基于Javacv 使用http实现下一个文件动态切换
-
结果:使用简单方案实现动态推流,感知上一个视频是否推完,并可以动态监控异常视频,同时记录并报警。
6.2 srs流服务器的一些坑
坑1:WebRTC播放黑屏
-
现象:数字人画面在WebRTC播放器黑屏,但RTMP正常
-
原因:编码Profile为High,浏览器解码器不支持
-
解决:FFmpeg强制
-profile:v baseline -level 3.1
坑2:长时间推流内存泄漏
-
现象:SRS运行48小时后内存占用从2G涨到20G
-
原因:SRS 5.0以下版本的DVR模块有泄漏
-
解决:每日定时
SIGUSR2重启
坑3:多路推流卡顿
-
现象:单节点推50路流,后半段出现卡顿
-
原因:SRS默认
chunk_size60000太小,TCP包碎片化 -
解决:srs.conf中设置
chunk_size 128000
坑4:音视频不同步
-
现象:数字人说话口型对不上
-
原因:Unity渲染帧率波动,音频固定44.1kHz采样
-
解决:SRS端配置
aac_sync on,或使用-async 1强制同步
结语:数字人直播的下一站
基于SRS自建直播服务,让我们在数字人赛道上获得了成本、延迟、可控性的三重优势。但技术永远在演进:
-
协议层:SRT正在替代RTMP成为推流标准,SRS 6.0已原生支持
-
编码层:AV1编码比H.264省30%带宽,但编解码延迟仍需优化
-
架构层:WebTransport over HTTP/3可能重塑低延迟直播架构
技术栈清单:
-
流媒体服务器:SRS 6.0
-
容器编排:K8s
-
监控:Prometheus + Grafana
-
推流端:FFmpeg 6.0 + Unity/Unreal
-
平台接入:SRS Forward + 动态推流码服务