

引言:AI Coding 提升代码质量的关键
——知识库的深度建设
-
Spec 知识库:基于规范驱动开发(Spec-Driven Development, SDD)沉淀的项目级契约与规则;
-
RAG(Retrieval-Augmented Generation)知识库:动态接入外部文档、历史方案、最佳实践等非结构化或半结构化知识。

前置知识调研
-
什么是Spec?
-
规范即契约:SPEC 是开发者、AI Agent 与系统之间达成的共识性“契约”,清晰界定“做什么”(What)、“为什么做”(Why)以及“如何做”(How)。 -
AI 的指令集:为大语言模型(LLM)提供明确、结构化的上下文,显著减少幻觉(hallucination),提升生成代码的准确性与一致性。
-
Spec Coding VS Vibe Coding
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
什么是RAG?
-
Retrieve(检索):根据用户查询,从外部知识库(如文档、数据库)中检索最相关的文本片段; -
Augment(增强):将检索结果拼接到原始 Prompt 中,形成增强上下文; -
Generate(生成):LLM 基于增强后的上下文生成最终回答。
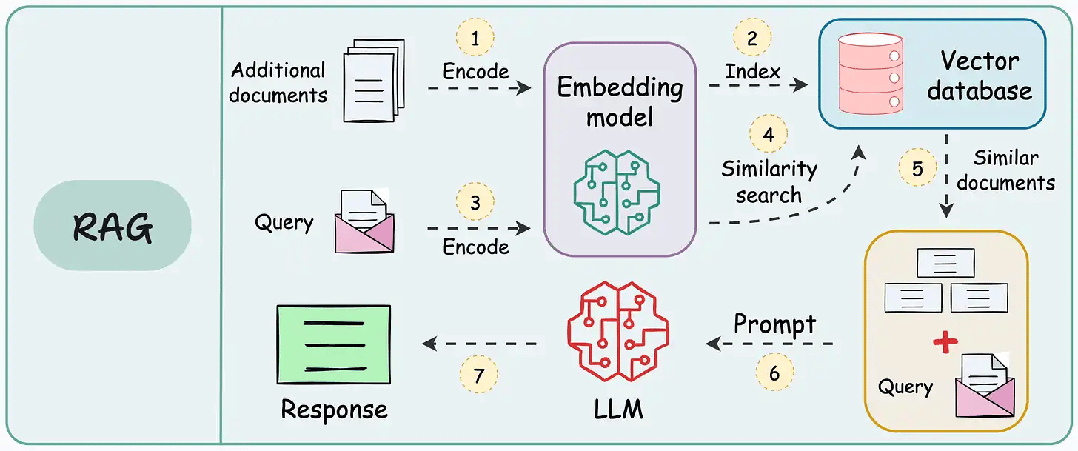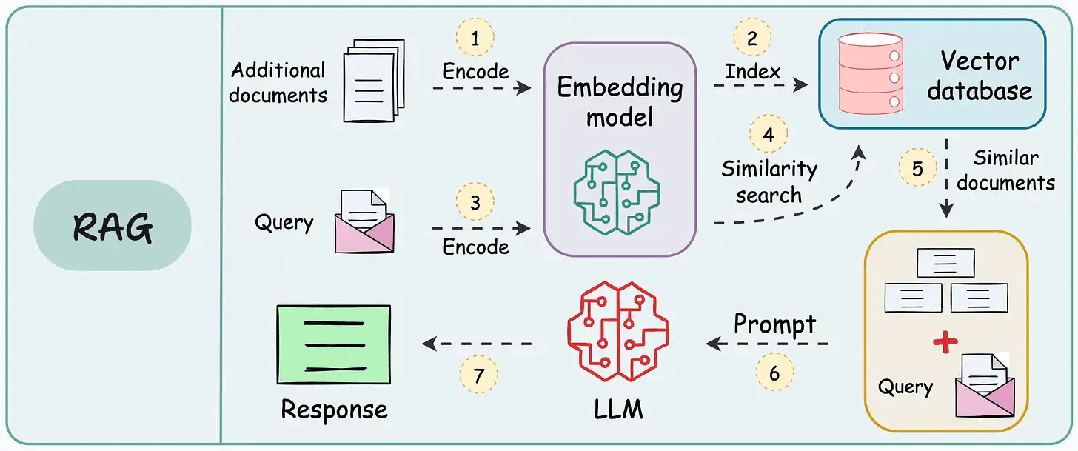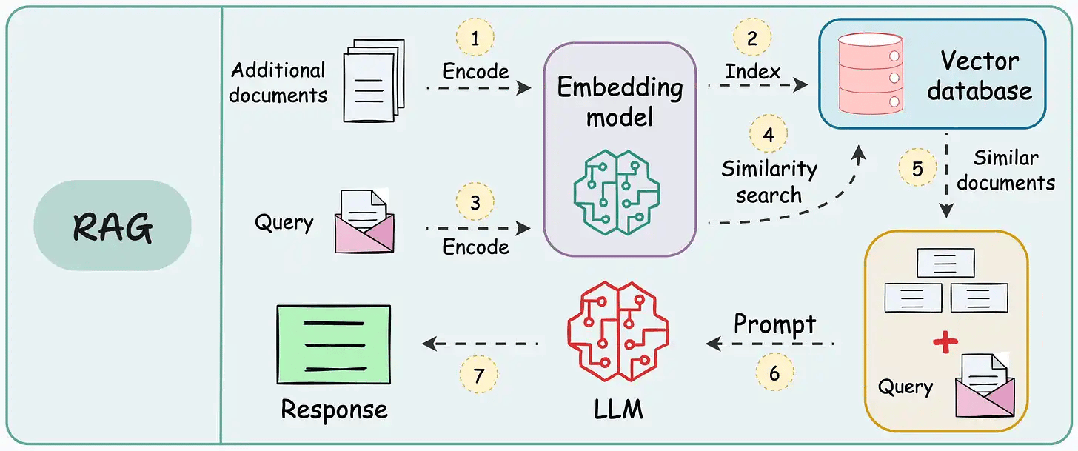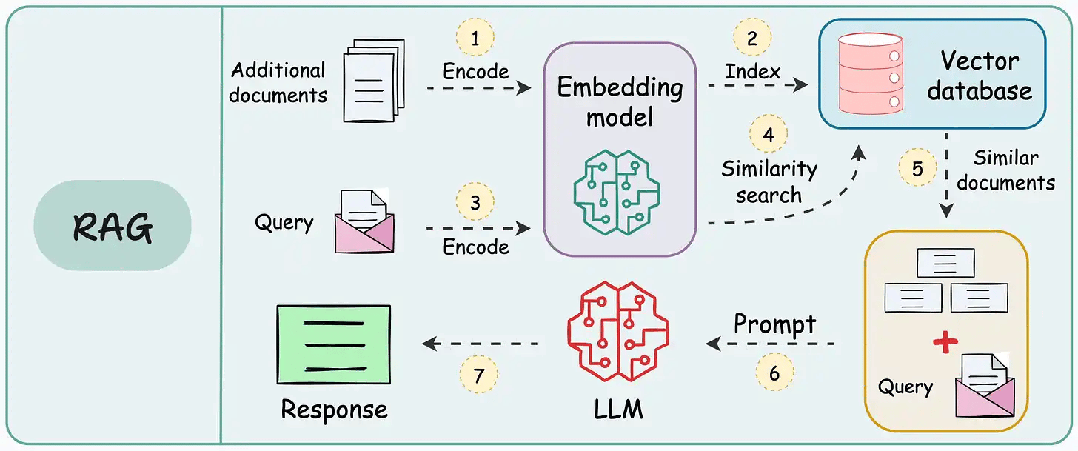
-
为什么需要 RAG?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
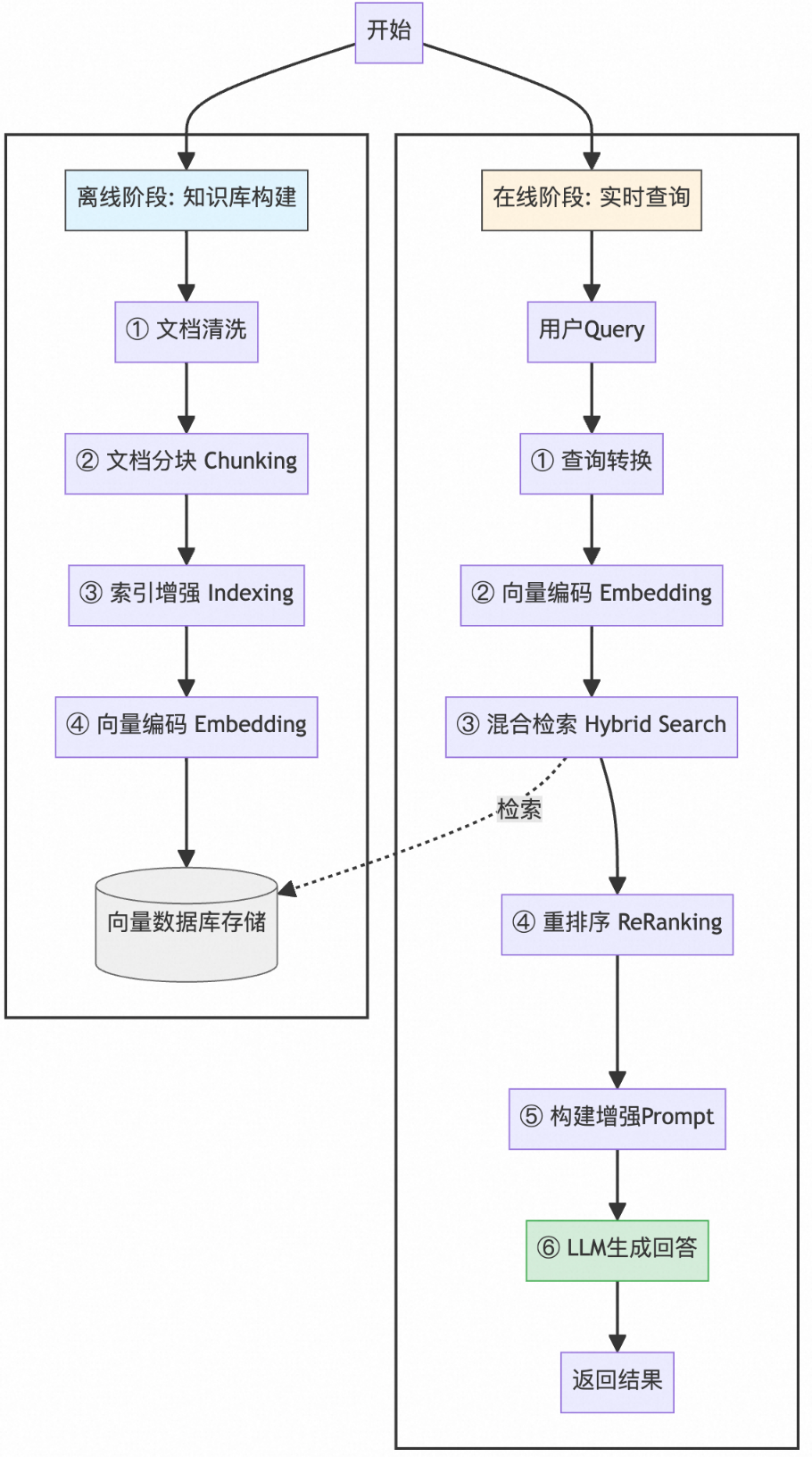
RAG工作流程
-
离线阶段:知识库构建
-
文档预处理:对原始文档进行清洗,去除噪声和无关信息 -
智能分块:将长文档切分成语义完整、大小适中的文本片段 -
索引增强:为文本片段添加元数据(如来源、时间、分类)和关键词标签 -
向量化编码:使用嵌入模型将文本转换为向量表示 -
数据入库:将向量与原文一同存储到向量数据库中,构建完整的检索索引
-
在线阶段:实时查询
-
查询优化:对用户问题进行改写、扩展和消歧,提升查询表达的准确性 -
向量化检索:将优化后的查询转换为向量表示 -
混合召回:在向量数据库中执行语义检索与关键词匹配的混合检索策略,召回候选文档集 -
重排序:使用精排模型对候选文档进行相关性打分与重新排序 -
结果返回:将最相关的文档片段提供给大模型用于答案生成
-
RAG关键技术

-
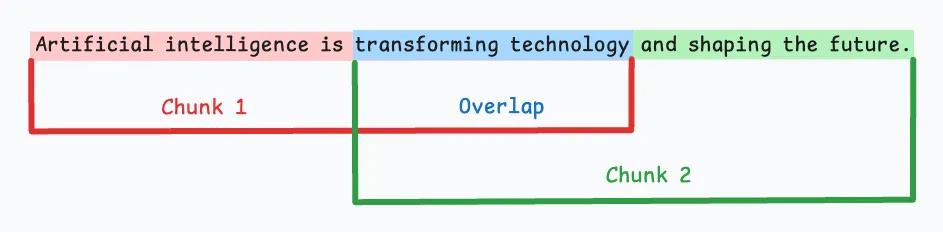
实现简单,易于自动化; -
所有块大小一致,便于批量处理和向量化; -
可通过设置重叠区域(overlap)部分缓解上下文断裂问题。
-
容易在句子或语义单元中间切断,破坏语义完整性; -
关键信息可能被拆分到多个块中,降低检索相关性和生成质量;
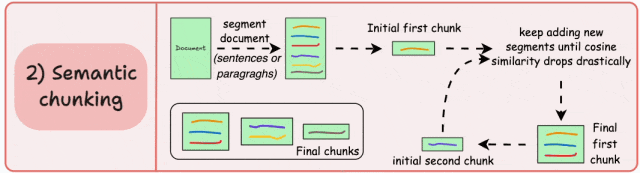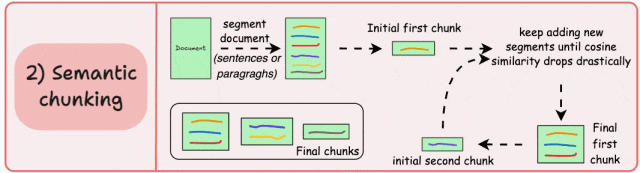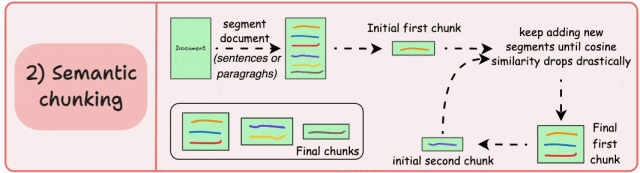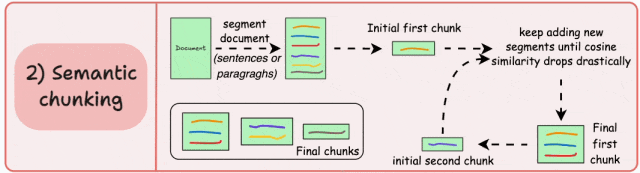
-
保留完整的语义单元和语言逻辑,避免信息割裂; -
每个块包含更连贯、更丰富的上下文信息,显著提升检索准确性和生成质量;
-
依赖相似度阈值来判断语义边界,而该阈值难以统一,需针对不同文档调整;
3. 递归分块(Recursive Chunking)
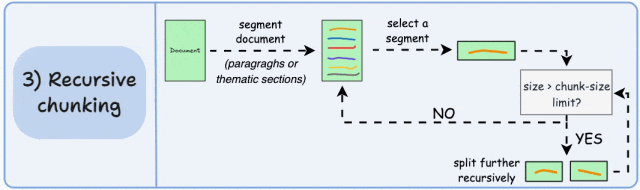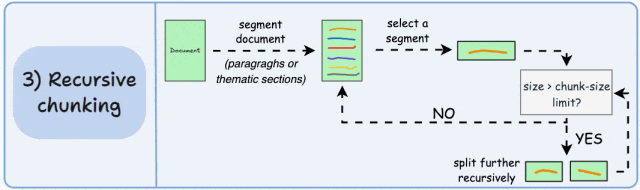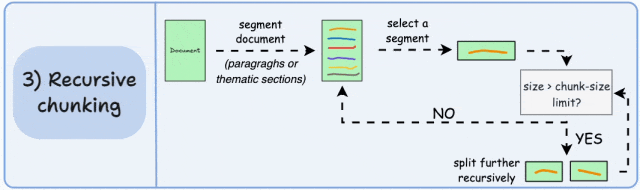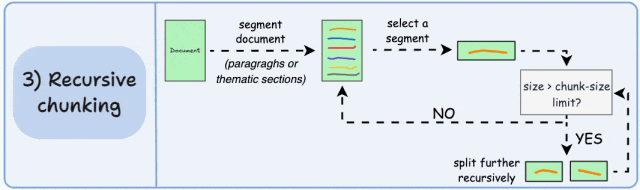
-
相比固定大小分块,能更好地保留完整句子和上下文逻辑,助于保持语义完整性;
-
计算开销略高,尤其在深层递归时;
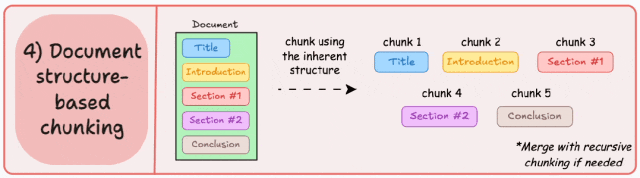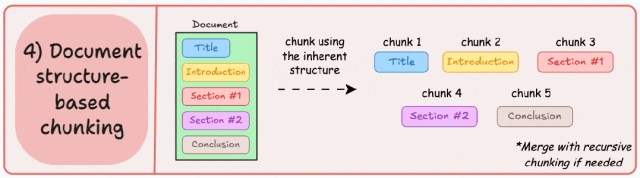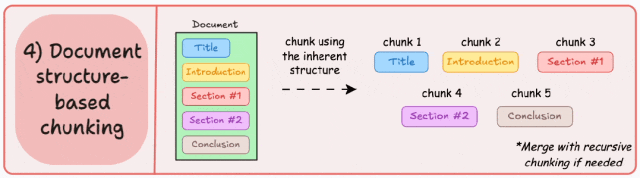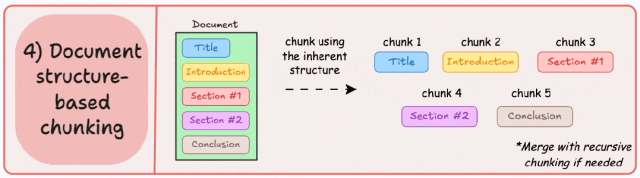

-
紧密贴合文档的原始逻辑结构,块内信息高度相关; -
对结构化文档(如技术文档、论文、说明书)效果尤佳。
-
依赖文档具备清晰、规范的结构,对格式混乱或无结构的文本(如纯文本日志、网页抓取内容)效果有限; -
生成的块长度可能差异很大,部分块可能超出嵌入模型或LLM的token限制;

-
LLM 能深入理解上下文和逻辑关系,生成的文本块语义完整、边界合理
-
计算成本最高,需对全文调用 LLM,推理开销大; -
受限于 LLM 自身的上下文窗口长度,处理超长文档时需额外分段策略;
-
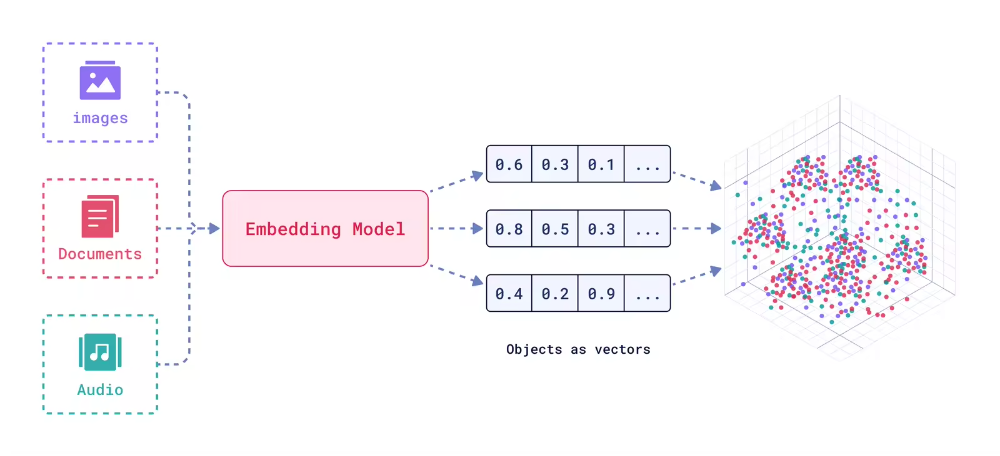
向量编码(Embedding)
-
向量空间映射:将用户查询与知识库中的文档统一映射到同一个连续的向量空间中,使语义相近的内容在该空间中彼此靠近; -
语义相似度计算:基于向量之间的相似度度量(如余弦相似度),快速检索出与用户查询在语义上最相关的文档片段。
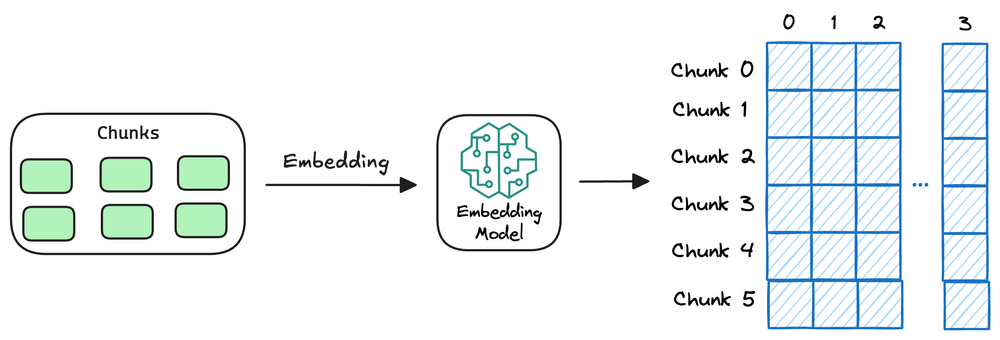
-
文本 Embedding:专门用于处理纯文本数据,通过模型(如 Sentence-BERT、DPR、BGE 等)将句子或段落编码为固定维度的句向量。这是当前 RAG 系统中最广泛采用的嵌入形式; 
-
多模态Enmedding:能够联合编码多种模态的信息(如文本、图像、音频等),将不同模态的内容映射到一个共享的语义向量空间,适用于图文检索、跨模态问答等更复杂的应用场景。
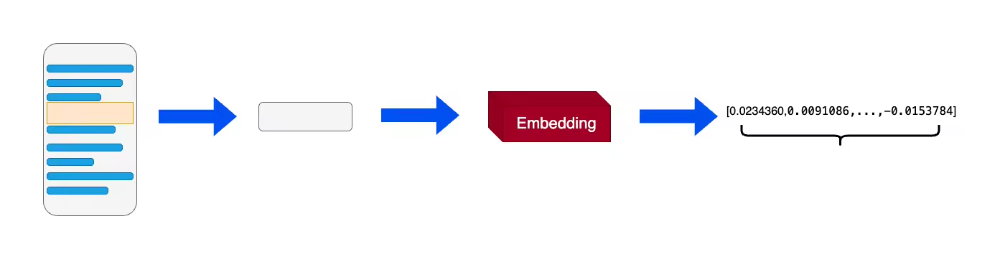
-
查询转换(Query Transformation)
-
用户原问题:“怎么学Python?” -
重写后的问题:“零基础初学者如何系统学习Python编程语言?推荐的学习路径和资源有哪些?”
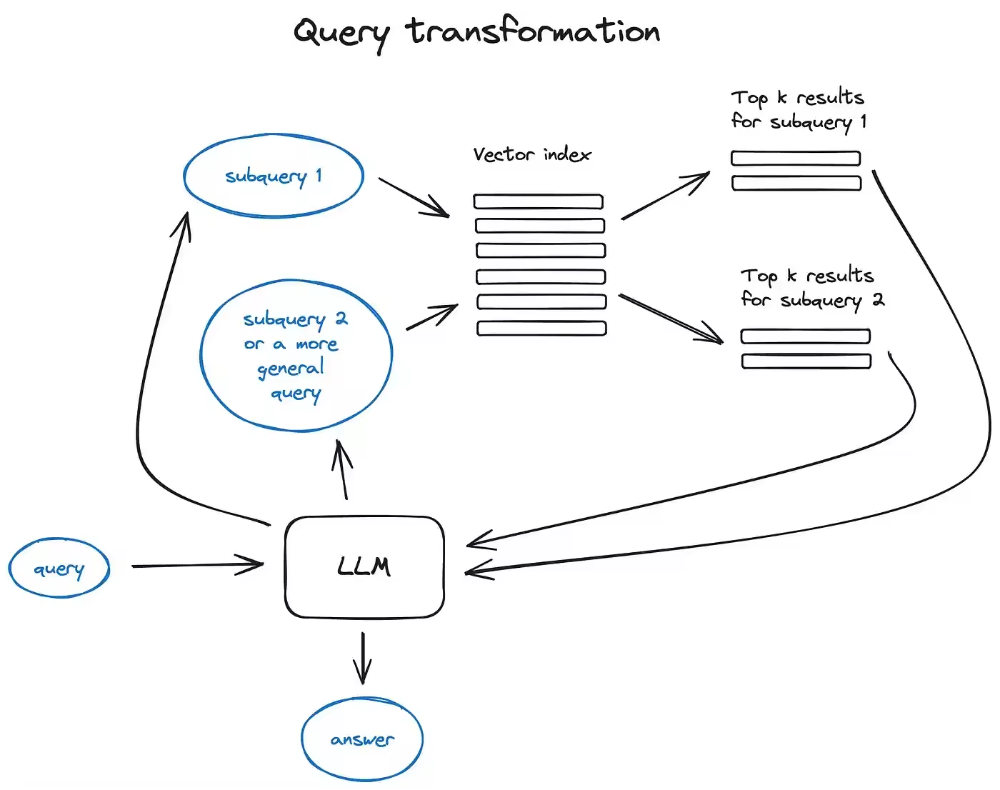
-
用户原问题:“购买新能源汽车时需要考虑哪些因素?补贴政策和充电设施是否完善?”
-
拆解为:
-
“选购新能源汽车时应重点关注哪些参数和配置?” -
“当前国家和地方对新能源汽车有哪些购车补贴政策?” -
“家用充电桩安装条件和流程是什么?”
-
用户原问题:“为什么我的手机电池掉电特别快?” -
回退问题:“影响智能手机电池续航的主要因素有哪些?”
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
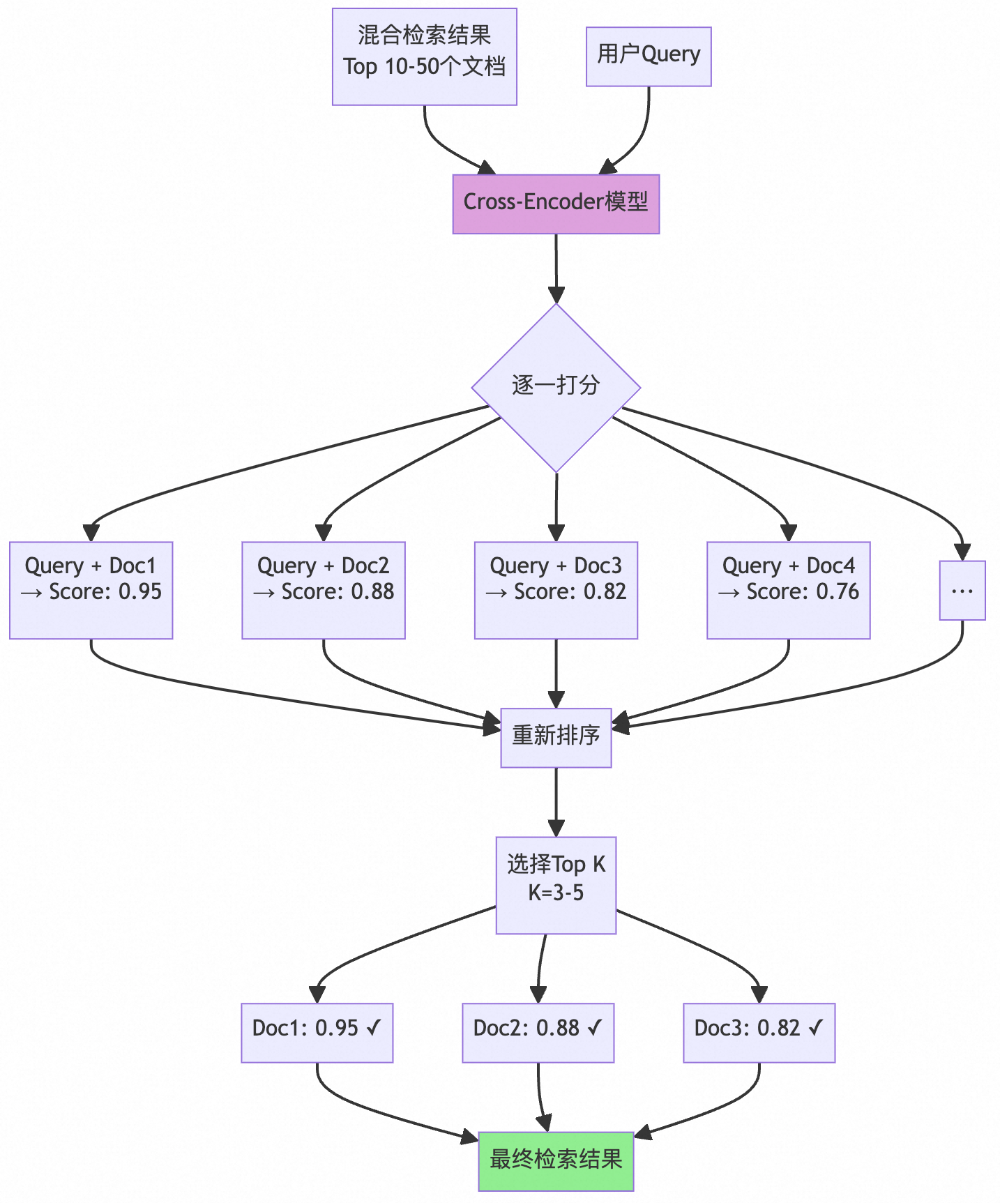
重排序(ReRanking)
-
获取初筛候选:从前期检索阶段(例如 BM25、稠密向量或稀疏向量召回)的结果中合并并选取 Top-K 个候选文档。 -
构造查询-文档对:将用户的问题与每个候选文档拼接成一个完整的输入文本,便于模型整体理解两者关系。 -
计算相关性得分:把每个拼接后的文本对输入 Cross-Encoder 模型。模型会通读整个句子,综合判断问题和文档在语义上是否匹配,并输出一个 0 到 1 之间的相关性分数——比如 0.9 表示高度相关,0.2 表示基本无关。 -
重排序并筛选:根据得分对所有候选文档从高到低重新排序,最终只保留 Top-N 个最相关的段落(如 N = 5~10),作为上下文送入大语言模型生成答案。
-
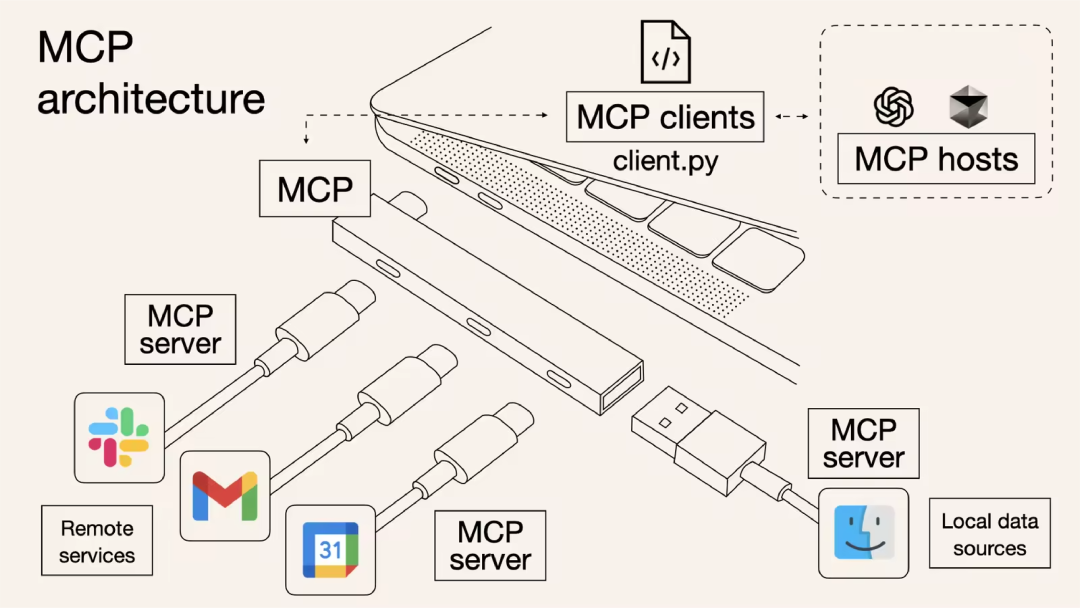
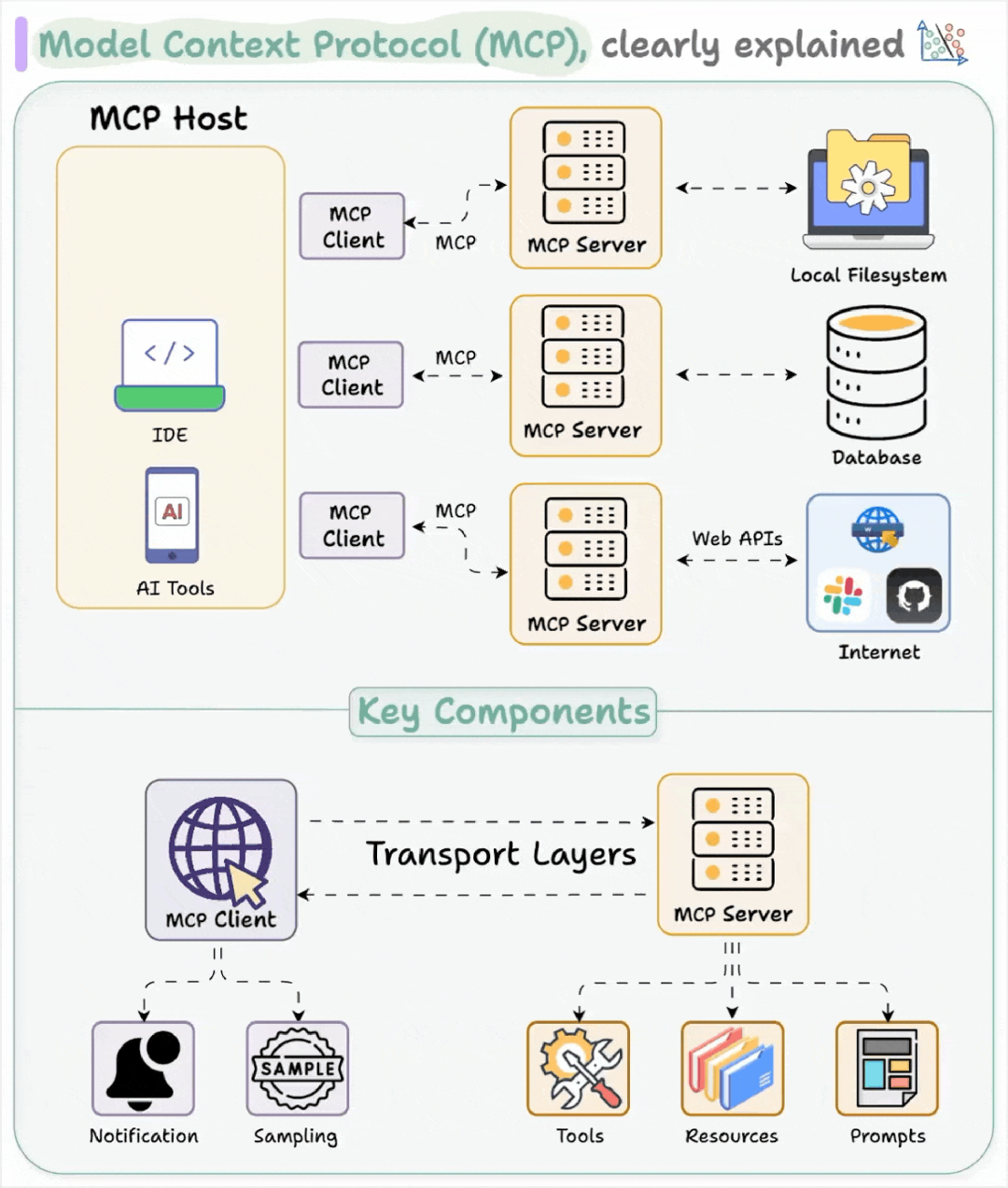
什么是MCP?
类比理解:如果把传统 API 比作“专用充电线”(每台设备需要特定接口),那么 MCP 就是“Type-C”——一个统一、即插即用、支持热插拔和能力协商的智能接口标准。
-
核心架构
-
主机(Host):运行 MCP 客户端的 AI 应用。 -
客户端(Client):在主机内运行,使其能与 MCP 服务器通信。 -
服务器(Server):暴露特定功能并提供数据访问
-
工具(Tools):使 LLM 能够执行具体操作的可调用函数。比如天气查询工具 get_weather可以获取指定地点天气 -
资源(Resources):向 LLM 公开服务器中的数据和内容。比如知识库文档、数据库记录、配置文件等 -
提示 (Prompts):提供可复用的提示词模板。比如翻译提示词模版、数据分析提示词模版等
-
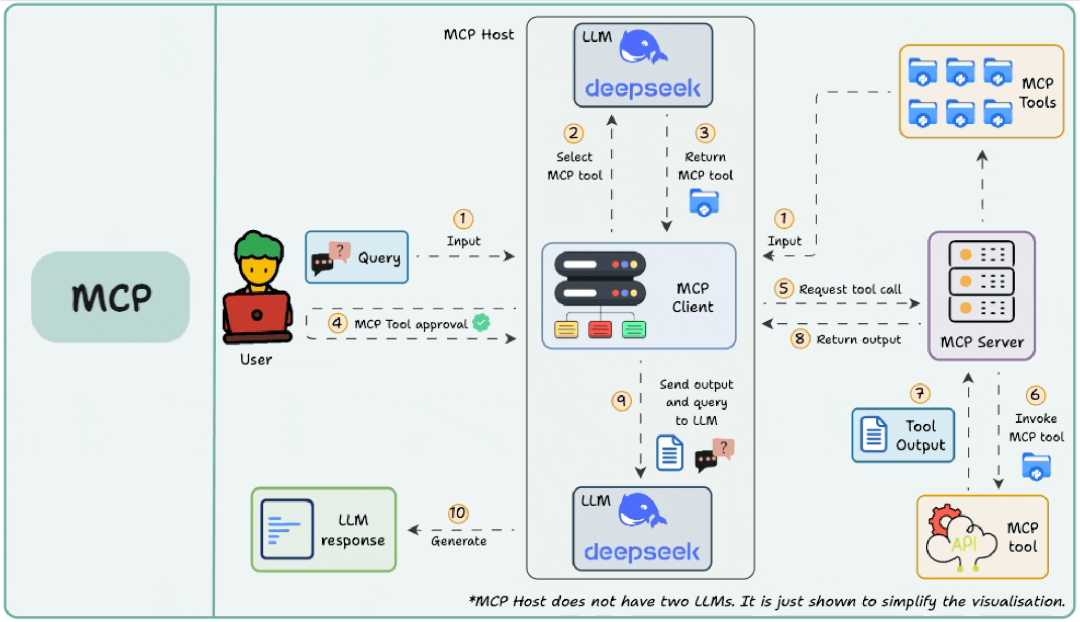
通信流程
-
Host 启动 MCP Client 并连接 MCP Server
-
用户在 AI 应用中启用了某个插件(例如“天气助手”)。 -
Host 启动内置的 MCP Client,并通过预配置的方式(如本地进程、WebSocket URL)连接到对应的 MCP Server(例如一个运行在 localhost:8080/weather-mcp 的服务)。
-
Client 发送初始化请求
-
MCP Client 向 Server 发送 initialize 请求
{"method": "initialize","params": {"clientInfo": { "name": "Claude Desktop", "version": "1.5" },"capabilities": { "supportsPrompts": true }}}
-
Server 返回自身能力清单
-
MCP Server 响应,声明它能提供哪些 Tools(工具)、Resources(资源) 和 Prompts(提示模板),每个都附带结构化元数据(如参数 schema、描述、权限等级):
{"result": {"serverInfo": { "name": "Weather MCP Server", "version": "2.1" },"capabilities": {"tools": [{"name": "get_weather","description": "获取指定城市和日期的天气预报","parameters": {"type": "object","properties": {"location": { "type": "string", "description": "城市名称" },"date": { "type": "string", "format": "date", "description": "查询日期,格式 YYYY-MM-DD" }},"required": ["location"]},"requiresUserConsent": false // 可配置是否需要用户确认}],"resources": [],"prompts": []}}}
-
Client 注册能力并完成握手
-
MCP Client 解析响应,将 get_weather 工具注册到当前会话的“可用工具集”中。 -
后续 LLM 在生成回复时,即可“知道”自己可以调用这个工具。
-
LLM 分析问题并选择工具
-
Host 将用户输入传递给 LLM。 -
LLM 根据上下文和已注册的工具列表,决定调用 get_weather,并生成工具调用指令:
{"tool_name": "get_weather","arguments": {"location": "北京","date": "2025-06-15"}}
-
MCP Client 检查并请求用户授权(可选)
-
MCP Client 查看该工具的元数据:
-
若 requiresUserConsent: true → 弹出确认框:“AI 想查询北京天气,是否允许?” -
若为 false(如本例),或用户已设置“自动同意”,则跳过确认。
-
Client 向 Server 发起工具调用
-
MCP Client 通过协议通道发送 call 请求:
{"method": "call","params": {"name": "get_weather","arguments": { "location": "北京", "date": "2025-06-15" }}}
-
Server 执行工具并返回结果
{"result": {"temperature": 28,"unit": "°C","condition": "Sunny","summary": "北京明天晴,气温 28°C"}}
-
Client 将结果注入 LLM 上下文
-
MCP Client 收到结果后,将其与原始用户问题一起提交给 LLM -
工具返回:“北京明天晴,气温 28°C”
-
LLM 生成自然语言回答
-
LLM 综合信息,输出流畅回答 -
LLM返回:“明天北京天气晴朗,最高气温 28 摄氏度,适合外出!”

落地实践
-
本地 SPEC 知识库
-
优势:提供强约束、机器可读的契约规范,确保生成代码在接口、数据格式、异常处理等方面严格符合业务要求;支持自动化验证,行为可预期、可审计。 -
适用场景:接口定义、代码流程描述、扩展点契约、编码规范、兜底策略等必须遵守的确定性规则。 -
集成方式:直接嵌入 IDE 上下文,无需 MCP 检索,作为 LLM 的基础约束条件实时生效。
-
RAG 知识库
-
优势:动态检索非结构化/半结构化私有知识(如业务领域知识、术语、历史经验),提供语境感知的“软上下文”;按需召回,避免上下文过载;支持低成本持续更新。 -
适用场景:需求背景解释、最佳实践参考、隐性规则说明、跨域联调上下文等辅助信息。 -
集成方式:通过 MCP 协议封装为标准工具服务,按需调用,避免上下文膨胀。
-
所有 Solution 与通用组件均配套
.spec/目录,明确定义输入输出、实验开关、兜底逻辑等关键要素; -
团队沉淀的通用 Rules(如日志规范 GuideLog、参数校验模板、稳定性兜底策略)已嵌入 Prompt Rules工程,作为系统级约束;
-
agent平台在代码生成前自动加载相关 SPEC 文件,将其转化为内部约束条件,确保产出符合业务语义与系统架构。
-
将猫超闪购系统文档体系划分为三大类
-
功能规范:整体划分为主流程、解决方案、通用组件和描述性规范四类。
-
需求生命周期管理:围绕具体需求,集中管理从需求拆解到技术方案的全过程文档,确保需求实现可追溯。
-
项目级规则:统一定义编码规范、目录结构及导购架构等项目级工程标准。
-
-
统一托管与知识整合:已将部分核心业务文档导入 RAG 知识库; -
智能检索能力建设:基于 RAG 提供的向量检索与重排序能力,实现关键词+语义混合召回;该机制能在用户提问时自动理解意图,从海量文档中精准召回最相关的片段; -
轻量集成与 MCP 封装:通过 MCP 协议将 RAG 检索能力封装为标准化工具,以“即插即用”的方式嵌入 agent平台工作流; -
试点场景验证:在“需求澄清”“错误诊断”“方案参考”等场景中初步验证,能有效补充 SPEC 未覆盖的上下文。
-
RAG知识库构建
-
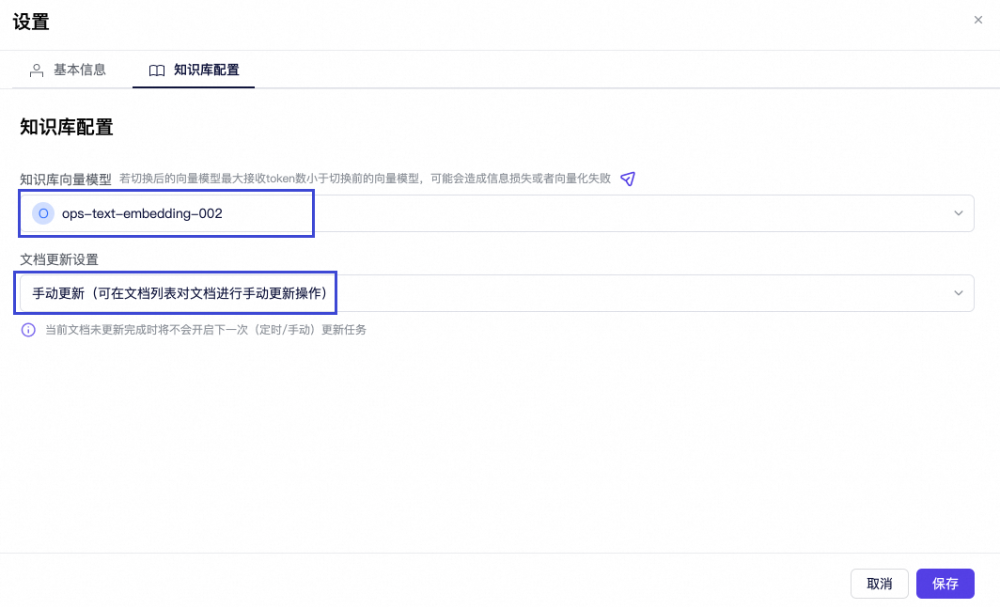
向量模型选择:选择适合业务场景的向量化模型 -
文档更新策略:设置文档的自动更新和同步机制
-
MCP服务器构建
-
获取知识库ID:在知识库详情页面复制知识库唯一标识ID
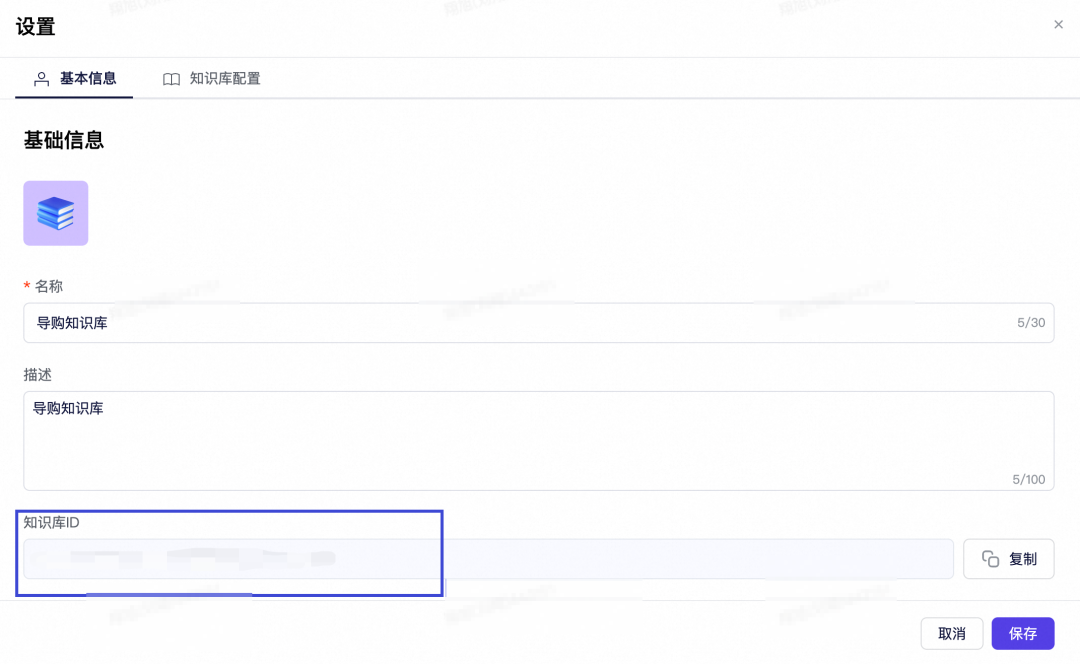
-
知识库AK绑定
-
申请知识库AK(免费体验)
-
AK绑定:在知识库设置中完成AK绑定配置
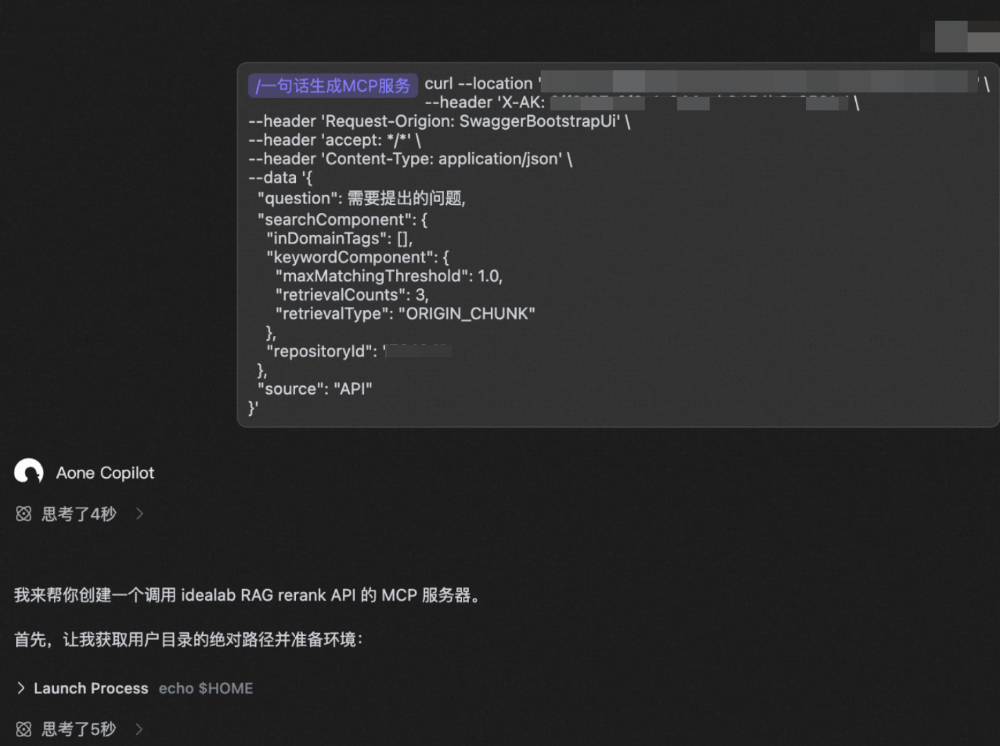
curl --location '检索地址'--header 'X-AK: AK'--header 'Request-Origion: SwaggerBootstrapUi'--header 'accept: */*'--header 'Content-Type: application/json'--data '{"question": 需要提出的问题,"searchComponent": {"inDomainTags": [],"keywordComponent": {"maxMatchingThreshold": 1.0,"retrievalCounts": 3,"retrievalType": "ORIGIN_CHUNK"},"repositoryId": "知识库ID"},"source": "API"}'
-
通过“一句话生成MCP服务”prompt,快速构建本地MCP服务
-
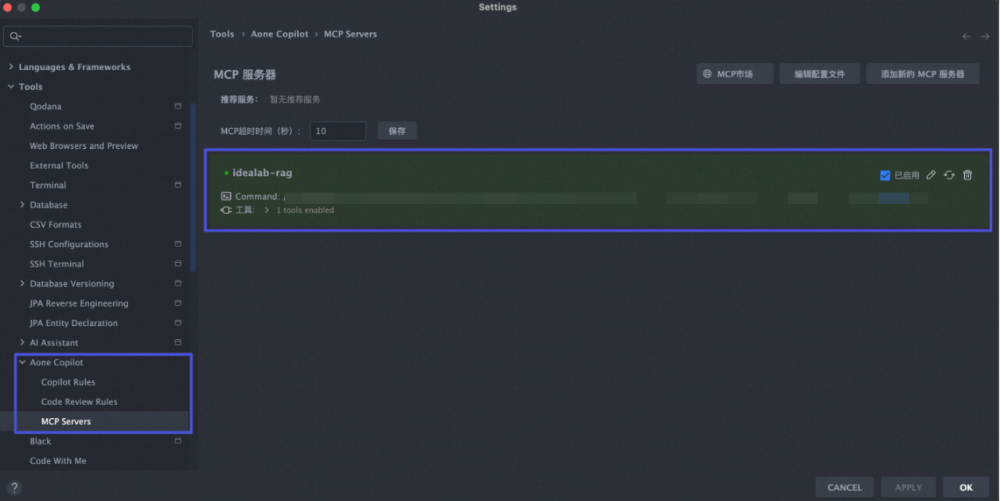
agent平台集成验证
-
agent平台实战应用



后续规划
-
SPEC 知识库将持续完善:进一步优化spec目录的分层结构,提升规范的可发现性与复用性;探索建立自动保鲜机制,通过代码变更感知等方式,确保 SPEC 与实现同步演进,避免“规范滞后于代码”。进一步夯实 AI Coding 的“硬规则”基础。
-
RAG 知识库将重点优化以下方向,以提升动态上下文的质量与覆盖:
-
向量模型调优:评估并引入更契合技术文档语义的嵌入模型,提升语义匹配精度与跨文档关联能力; -
检索效果增强:支持关键词与向量混合检索,引入重排序(re-ranking)等机制,提高召回结果的相关性与实用性; -
业务知识库持续建设:在现有基础上,逐步丰富各业务域的核心文档(如导购、推荐、渲染等领域的规范、流程),朝着覆盖全面、结构清晰、易于维护的领域知识体系演进。 -
MCP 服务云端化:若本地验证顺利,将把当前基于本地部署的 MCP 检索服务迁移至云端平台。

团队介绍