

前言

Harness 并不是 AI 圈子凭空发明的新概念。作者在此前的 AI 实践中,一直在尝试总结一套完整的方法论,但发现无论是 Prompt Engineering 还是 Context Engineering,都无法很好地囊括全部实践。于是,作为前端工程师,索性自己造了个新词:“AI 工程化”或“AI 基建设计”。
Harness Engineering 这个词的出现,不过是用一个更形象、更生动的词语,对这类现有实践做了一次系统性的汇总和命名。
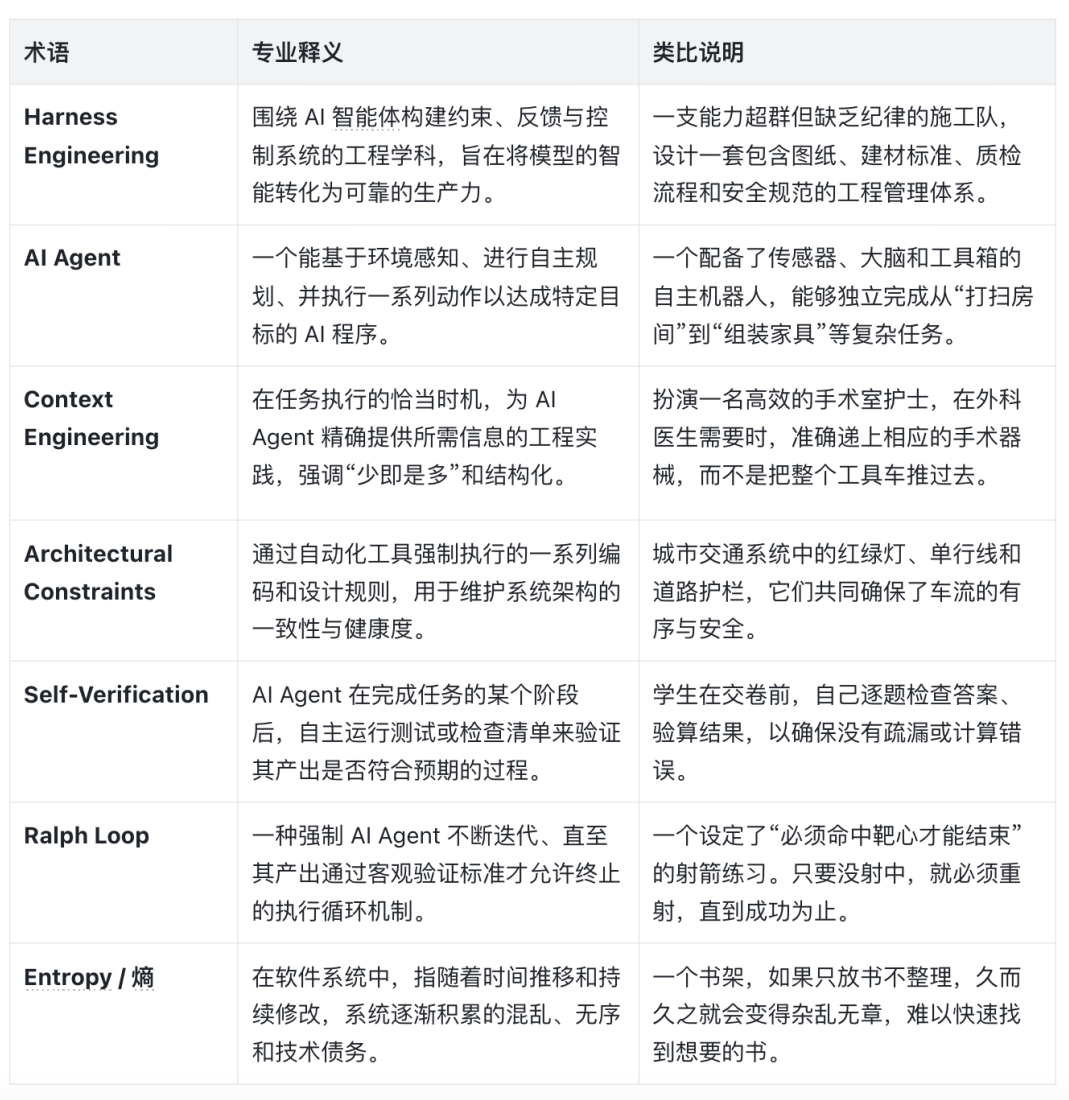
本文的部分内容来源于作者多次模型评测和工程实践中的思考,行文风格可能与常见的技术文章有所不同。如有不当之处,还请大家不吝指正。在正式阅读这篇文章之前,我也给大家准备了一份术语说明,如果你在阅读过程中有任何不清楚的地方,欢迎随时查看。
废话不多说,正文开始~

Harness Engineering 是什么?

2026 年,继提示词工程(Prompt Engineering)与上下文工程(Context Engineering)之后,软件工程领域迎来了一个新的关键词:Harness Engineering。这个概念由 HashiCorp 联合创始人 Mitchell Hashimoto 提出,并因 OpenAI 的一篇报告而广为人知。
其核心隐喻:“马与缰绳”:生动地描绘了它的使命:为强大但方向不定的“野马”(例如 AI Agent 或任何复杂的软件系统)套上名为“Harness”的“缰绳”,通过约束、引导并纠正其行为,确保它能沿着预设的轨道稳定、可靠地前行。
我们通过一个形象的比喻,相信你会更加清楚:AI Agent = SOTA 的模型 (野马) + Harness (驾驭系统) = 千里马
AI Agent 如同一匹潜力无限的“野马”,而 Harness Engineering 则是那套能将其驯化为“千里马”的完整驾驭体系。它不是去改变马的基因(模型本身),而是为它设计一套专业的马具和训练方法。
再次明确这一点:Harness Engineering 不是一个需要焦虑追捧的全新发明,而是对一系列现有工程实践的系统性总结与命名。正如本文开篇所说,它更像是一套“AI 工程化的驾驭体系”,旨在解决一个核心问题:当 AI 成为我们团队的一员时,我们该如何管理这位“超级实习生”?
概念已经明晰,那么下一个自然而然的问题是:我们为什么需要它?

为什么需要 Harness Engineering?
随着 AI 从单一的”应答机器”向能够自主规划和执行复杂任务的智能体(AI Agent)演进,工程师的角色正在发生根本性的转变。Harness Engineering 的出现,正是为了应对这一转变带来的全新挑战。其必要性主要体现在以下几个方面:
构建更可靠的 Agent 系统
为了让 Agent 从“有趣的玩具”变为“可靠的工具”,它必须满足四个核心目标,我们可以将其概括为 R.E.S.T 模型:
可靠性 (Reliability)
-
定义:系统在面对各种预期和非预期的输入、环境变化和内部故障时,能够持续、稳定地提供服务,并完成其既定任务的能力。
-
关键要求:
-
失败可恢复:任务中断后能自动从检查点恢复。
-
操作幂等性:关键的写操作可安全重试,不会弄脏状态。
-
行为一致性:在相同输入下,行为应是可预测的。
效率 (Efficiency)
-
定义:在满足功能和可靠性的前提下,系统使用计算、存储、网络等资源的有效性,直接关系到服务的成本和可扩展性。
-
关键要求:
-
资源可控:对 Token 消耗、API 调用、计算时间有精确的预算控制。
-
低延迟响应:在交互式场景中,快速给出有意义的反馈。
-
高吞吐量:在批处理场景中,单位时间内能处理更多任务。
安全性 (Security)
-
定义:保护系统及其数据免受未经授权的访问、使用、泄露或破坏的能力。对于能自主行动的 Agent,安全性是不可逾越的红线。
-
关键要求:
-
最小权限:仅授予完成当前子任务所必需的权限。
-
沙盒执行:所有不授信的代码或指令必须在严格隔离的沙盒中执行。
-
输入/输出过滤:防止指令注入、敏感信息泄露和有害内容生成。
可观测性 (Traceability / 可追溯性)
-
定义:系统提供足够的数据(日志、指标、追踪),使开发和运维人员能够理解其内部状态、决策过程和行为轨迹的能力。
-
关键要求:
-
全链路追踪:从请求到结果,每一个环节的调用链都清晰可追溯。
-
决策可解释:Agent 的每一个关键决策(如选择哪个工具)都应有明确的归因记录。
-
状态可审计:系统在任意历史时间点的完整状态都应可查询和审计。
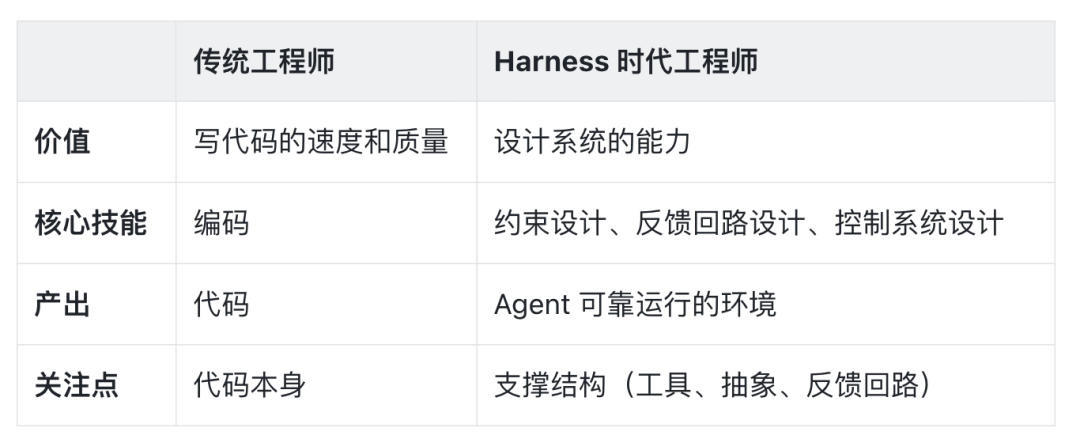
Agent-First 时代对工程师的必然要求
-
工程复杂性持续攀升:随着 AI 能力的不断增强,人们对应用场景的复杂度和预期也水涨船高。编程场景早已不再是贪吃蛇、俄罗斯方块等 Vibe Coding 小 Demo,而是从简单的程序跃迁为复杂的工程实践。
-
从“执行者”到“设计者”的角色跃迁:当 AI 承担起代码编写等具体任务时,人类工程师的核心价值便从“动手执行”转向“系统设计”。我们不再是逐行编码的工人,而是设计蓝图、定义规则、验收最终成果的架构师:正如系列文章前文提到的 Spec Coding 理念。当然,仅靠给 AI 制定 Prompt 规则这种“软约束”是远远不够的。
也是 Harness Engineering 爆火的起因:
https://openai.com/zh-Hans-CN/index/harness-engineering/
仅通过提示词(Prompt)下达指令这种“软约束”远远不够,我们需要一套“硬约束”的工程体系”来保障最终产物的质量、可靠性与可维护性:这正是 Harness Engineering 的用武之地。
简而言之,Harness Engineering 的核心理念是:当模型遇到问题时,通过一套工程化的 Harness 机制,从根本上避免同类问题再次发生。
它是这个时代的产物:随着模型的持续迭代,更多基础能力将被内化至模型本身,部分 Harness 也将随之退出历史舞台;与此同时,新的应用场景不断涌现,也必将催生新的 Harness 实践。
明确了“为什么”之后,让我们进一步拆解 Harness Engineering 到底包含哪些具体内容。

Harness Engineering 包含什么
在当前基于 Transformer 和自回归的 LLM 架构下,模型的原始输出本质上是随机且无序的。
而 Harness Engineering 的作用,正是通过有序的约束来驾驭无序的算力,从而完成更加复杂的工程实践。
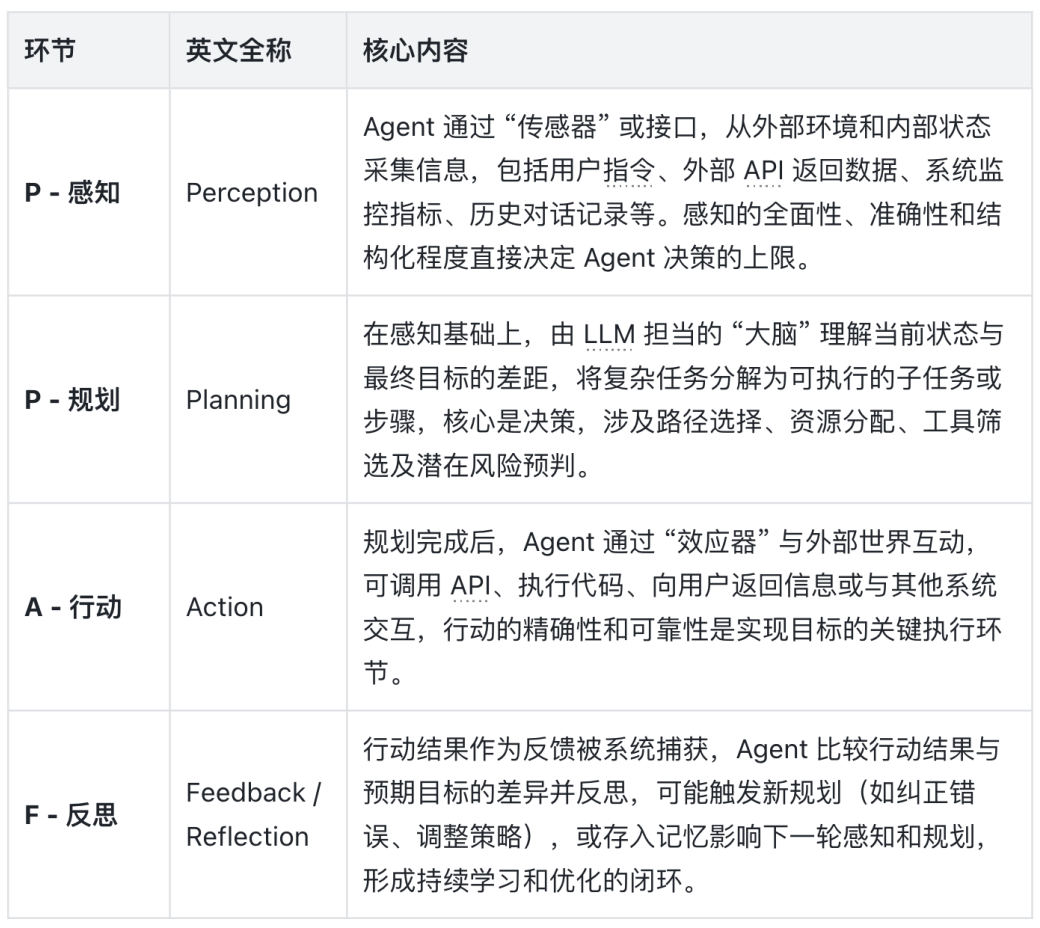
要理解它“包含什么”,我们首先需要理解 Agent 是如何运作的。一个完备的 Agent 系统,其核心运行机制可抽象为一个持续循环的四阶段过程:感知(Perception)、规划(Planning)、行动(Action)、以及反思(Feedback / Reflection)。
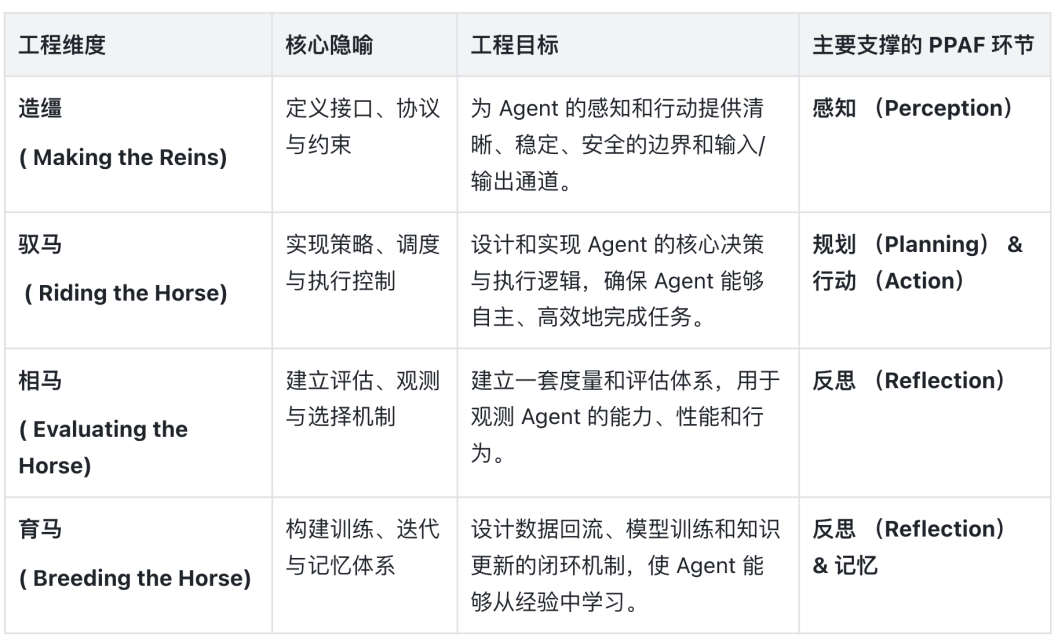
Harness Engineering 将 Agent 的工程化体系解构为四个核心维度,每个维度都与 PPAF 闭环的一个或多个环节紧密耦合。这四个维度共同构成了一个完整的 Agent “马具”(Harness),用于驾驭、约束和提升 Agent 这匹“智能之马”。
为了更系统地理解不同类型 Agent 的能力边界和工程挑战,我们可以构建一个二维的战略分析矩阵。该模型从“认知循环”和“上下文效率”两个维度对 Agent 应用进行划分。
-
横轴:AI 认知循环 (Cognitive Loop)
-
被动响应 (React):Agent 的行为主要由外部单次触发驱动,执行预定义的、确定性的任务,缺乏自主规划和反思能力。
-
主动规划与反思 (Proactive Plan & Reflect):Agent 能够基于长期目标,自主进行多步规划、执行、并根据结果进行反思和动态调整。
-
纵轴:环境系统上下文处理效率 (Context Efficiency)
-
低效 (人工/单点投喂):Agent 运行所需的大部分上下文依赖人工手动提供,或只能通过有限的、低效的接口获取。
-
高效 (沙盒化/全自动注入):Agent 运行在一个高度集成和自动化的环境中,所需上下文能够通过系统级接口(如文件系统、API 网关、状态引擎)被高效、全面地自动捕获和注入。

这个矩阵清晰地揭示了 Harness Engineering 的价值所在:Harness 的成熟度,直接决定了 Agent 应用能否从低效的、被动的第三、四象限,跃迁至高效的、主动的第一、二象限。
理解了 Harness Engineering 的组成部分后,下一步自然要问:它是如何被设计出来的?

Harness Engineering 是如何设计的
理论框架为我们指明了方向,现在让我们深入工程实践,探讨如何一步步构建起一个稳健的 Harness 系统。
4.1. 顶层抽象:Harness 作为带边界控制的 REPL 容器
在架构层面,Harness 的本质可以被抽象为一个带有边界控制、工具路由与确定性反馈的 REPL (Read-Eval-Print Loop) 容器。它包裹在 LLM 这个非确定性的“大脑”之外,负责管理从“感知”到“行动”再到“反思”的完整生命周期,从而将 LLM 的推理能力接入到确定性的工程世界。
4.2. 底层转换机制:在无限状态与有限 Token 间架起桥梁
Agent 的智能涌现,建立在对海量状态信息的理解之上。然而,LLM 的核心,也就是 Transformer 架构:操作的是一个有限的、线性的 Token 序列。
4.2.1. 上下文管理:从“无限状态”到“有限 Token”
Agent 的上下文(Context)是其感知的全部来源,它包含了任务目标、历史交互、工具定义、当前状态等海量信息。如何将这些信息有效“压缩”到 LLM 的 Token 窗口内,是规划质量的生命线。
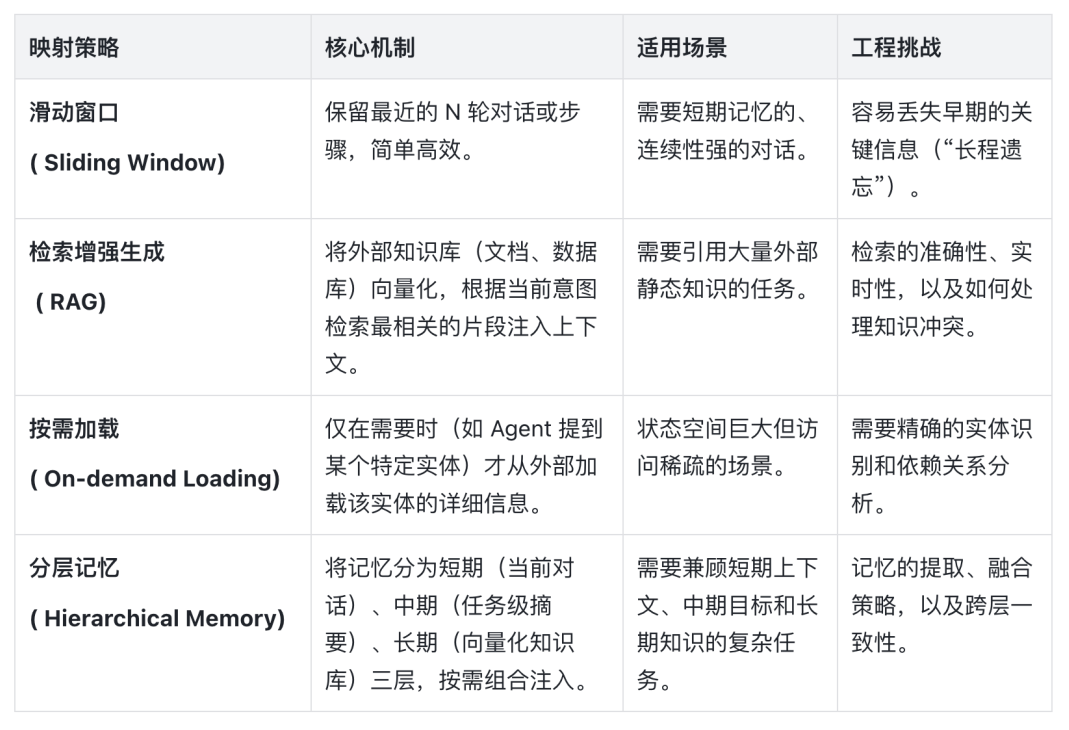
4.2.2. Function Calling:从“文本预测”到“物理执行”
Function Calling (FC) 是连接 LLM 规划与物理世界行动的桥梁。这个过程看似简单,实则包含了一个严密且脆弱的生命周期闭环:
-
Schema 序列化:Harness 将可用的工具(函数)列表及其参数定义(JSON Schema)序列化为特定格式的文本,注入到 Prompt 中。这是 LLM 理解其“能力边界”的唯一途径。
-
触发生成:LLM 在其庞大的参数空间中进行“模式匹配”,当它认为某个工具能满足当前规划步骤时,会生成一段遵循特定语法的文本,其中包含工具名称和参数值。
-
确定性反序列化:Harness 捕获这段文本,并尝试将其反序列化为一个结构化的调用请求。这是最脆弱的环节,因为 LLM 的生成可能不完全符合语法(如 JSON 格式错误、参数类型错误)。
-
观测注入:Harness 执行该调用,并将执行结果(成功或失败)封装成一段“观测”文本,再次注入 Prompt,完成闭环。
失败面与降级路径
由于 LLM 生成的非确定性,Function Calling 的每一步都可能失败。稳健的 Harness 必须为这些失败设计降级路径:
-
反序列化失败:
-
重试:向 LLM 提供错误信息(如 “Invalid JSON format”),并要求其重新生成。
-
回退到文本:放弃 FC,转而要求 LLM 生成自然语言指令,由更传统的解析器处理。
-
执行失败:
-
交互式补充:若因参数缺失导致失败,可向用户请求补充信息。
-
反思与重规划:将详细的错误信息注入上下文,引导 Agent 在下一轮反思失败原因并选择其他路径。
核心架构决策:状态分离原则
-
必须将 LLM 严格视为一个无状态的计算单元 (CPU),而将所有需要跨轮次保持一致性的状态(如用户会话、任务进度)存储在 Harness 控制的外部上下文状态管理器或其他持久化引擎(内存/硬盘)中。
-
反模式:试图通过 Prompt Engineering 让 LLM 在长对话中自行维护复杂状态,这会导致系统行为混乱、不可预测且难以调试。
4.3. 核心约束与设计原则
在构建 Harness 时,我们必须直面三大核心约束,并以六大设计原则作为应对之道。
三大核心约束

六大设计原则
-
为失败而设计 (Design for Failure):将异常和失败视为系统运行的常态,而非个例。所有组件和服务都应具备容错、重试和优雅降级的能力。
-
契约优先 (Contract-First):所有系统内外的交互都必须由明确的、机器可读的契约(Schema, API, Event)来定义,这是实现模块化、可测试性和系统演进的基石。
-
默认安全 (Secure by Default):安全不是事后添加的功能,而是系统设计的出发点。遵循最小权限、零信任和纵深防御原则。
-
决策与执行分离 (Separation of Concerns: Decision vs。 Execution):将“决定做什么”(规划)与“如何做”(执行)在逻辑和物理上解耦,提升系统的灵活性和可扩展性。
-
万物皆可度量 (Everything is Measurable):系统的每一个行为、每一次决策、每一次资源消耗都应该是可度量的。没有度量,就没有分析和优化。
-
数据驱动进化 (Data-driven Evolution):将 Agent 的每一次运行都视为一次学习机会。建立从数据采集、标注、回流到模型/知识更新的闭环,是实现系统长期智能增长的唯一路径。
4.4. 关键工程位点
为了实现上述 REPL 闭环并落地设计原则,Harness 需要在架构中部署一系列关键组件(或称“工程位点”)。
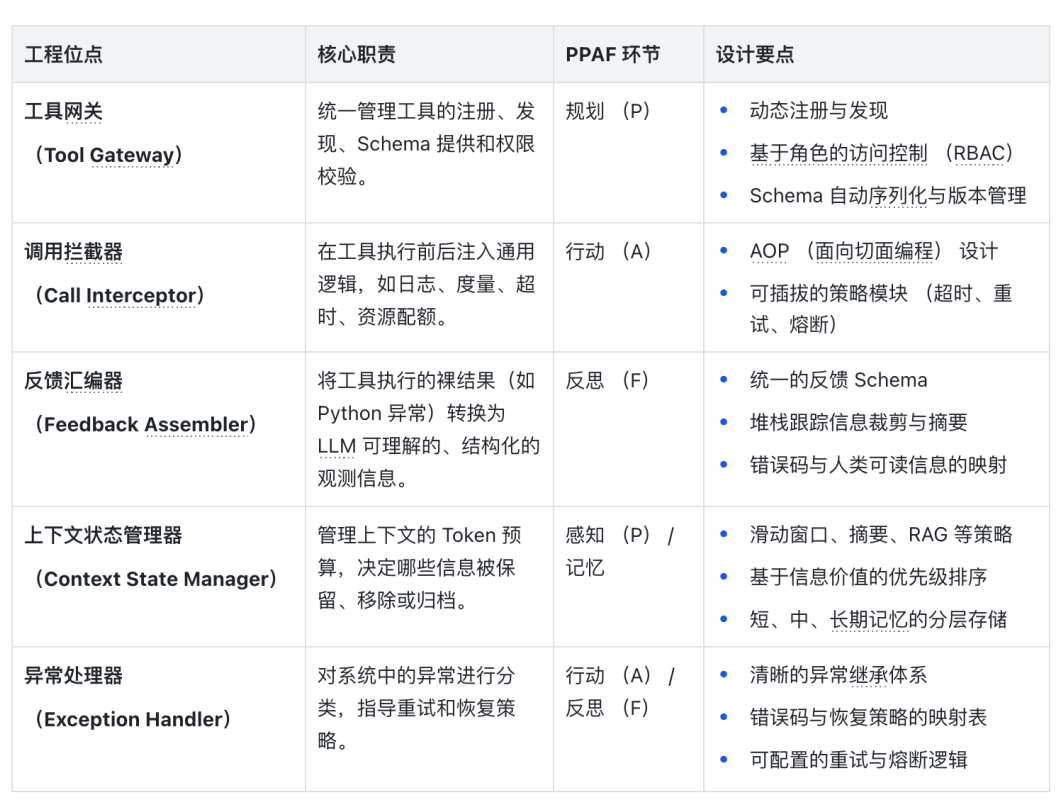
Harness Engineering 本身只是大模型工程的工程手段的总称不管是 AI SDK、Agent 实现、还是应用方的 skill 以及各种插件,本身就是尝试约束模型不在同一个问题反复摔跤,随着模型能力的逐渐提升和相关工程化的演进,各种 Harness 也在被不断内化或不断更替,讲明白了 Harness 是如何设计的,我们来聊聊具体是如何实现的。

Harness Engineering 是如何实现的
上文更多站在“概念 + 框架”的层面理解 Harness Engineering。对于负责落地平台和基础设施的工程同学,还可以把 Harness 进一步视作一个完整的运行系统,从架构分层、关键机制、运行治理和度量演进四个角度来审视。
5.1 系统架构总览:控制平面与数据平面
一个成熟的 Harness 通常会拆分为 控制平面(Control Plane) 与 数据平面(Data Plane):
-
控制平面负责“决定做什么”:任务调度、资源配额、行为规划、策略与权限。
-
数据平面负责“如何去做”:实际的 Agent 运行实例、状态存储、记忆存储和沙盒执行环境。
在此之上,可以进一步抽象出四个功能层级:

在具体落地时,你可以把 Harness 看成是对现有 AI 环境的一层“智能胶水”:上接模型 API Gateway ,下接沙盒和各类服务,以工程的方式串联各个基建。
5.2 核心运行机制:循环、记忆与 Token 转化
5.2.1 Agent 核心循环
原始材料中将 Agent 的行为抽象为一个持续的“观察 → 思考 → 行动”循环:
-
观察(Observe):感知当前世界状态,包括用户输入、工具结果、历史对话、任务进度等。
-
思考(Think):基于观察信息,由规划器更新目标、拆解任务、选择下一步行动。
-
行动(Act):执行内部操作(更新记忆、结束任务)或外部操作(调用工具、发出回复),行动结果反过来进入下一轮观察。
5.2.2 记忆分层与 Token 转化
为了在有限的上下文窗口内承载尽可能多的有效信息,多数 Agent 通过各种外挂 memory 的方式进行实现。

在三层记忆之上,Harness 还需要一条 Token 转化流水线(Token Transformation Pipeline),在每轮调用前,把多源信息规约成一个可控的 Prompt:
-
信息源收集:聚合用户问题、短期记忆、长期知识检索结果等。
-
相关性排序:基于时间、语义相似度等指标,对候选信息打分。
-
压缩与摘要:对冗长低密度内容做摘要或结构化提炼。
-
预算分配:按照预设 Token 预算,为不同信息类别分配额度。
-
模板组装:使用结构化模板(例如显式标注 [user_request]、[tool_output] 等)拼装最终 Prompt。
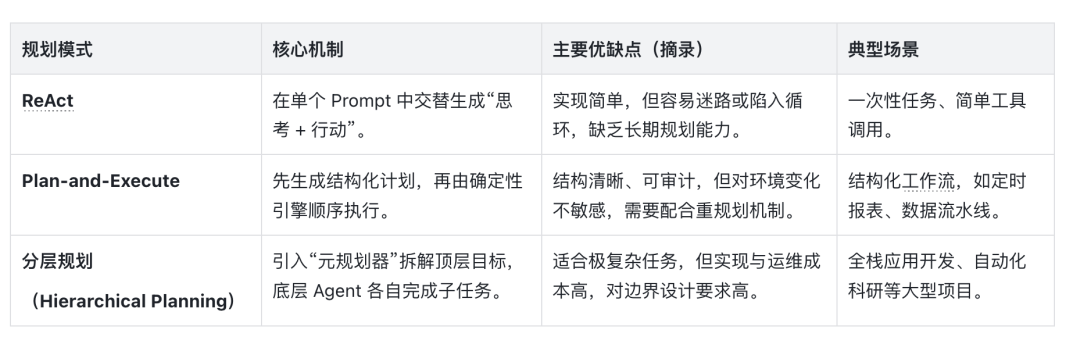
5.3 规划模式与执行策略
在“行为规划器”这一层,通常实践中根据复杂程度包含以下几种
5.4 运行与治理:沙盒、安全与成本
5.4.1 沙盒执行框架
为了让 Agent 可以“动手做事”而不破坏系统,因此需要给 Agent 一个安全的环境让他独立运行。
-
Level 1 进程级隔离:使用 chroot / Linux namespaces / seccomp-bpf 限制系统调用,启动快但仍共享内核,适用于可信内部工具。
-
Level 2 容器级隔离:Docker / containerd 等,生态成熟,是大多数工具执行的默认选择。
-
Level 3 轻量级虚拟机:如 Firecracker 等提供独立虚拟内核,适合多租户或执行不可信代码。
-
Level 4 完整虚拟机:KVM / QEMU,安全性最高但成本最大,只在极少数特殊任务中使用。
5.4.2 资源管理与弹性策略
在资源与成本控制方面,原始材料强调了几类关键机制:
-
预算与配额:为 Token、外部 API 调用次数、CPU 时间分别设置配额,并支持按“平台 / 租户 / Agent / 单任务”多层级配置。
-
超时控制:所有网络请求和工具执行都必须设置合理超时时间,避免因下游卡死拖垮整个 Agent。
-
重试策略:对可恢复的临时错误使用带退避的重试,对明显的永久性错误快速失败并上报。
-
熔断机制:当某个依赖连续失败时暂时熔断,防止出现级联故障。
-
优雅降级:关键能力不可用时,自动降级为“弱但安全”的模式,例如从“可执行代码”退回到“只读 + 建议”。
5.4.3 安全与合规:策略门控
除了沙盒本身,Harness 还需要一个位于“规划器 → 执行层”之间的 策略门控(Policy Gateway),负责在每一次行动前做最后的安全与合规检查,包括:
-
权限检查:基于 RBAC/ABAC 判定某个 Agent 是否有权访问目标资源或执行敏感操作。
-
敏感数据过滤:对参数和返回结果做 PII/密钥检测与脱敏。
-
指令注入防御:识别潜在恶意的 Prompt/命令拼接,禁止危险模式进入执行层。
-
审计日志:记录每一次“谁在何时尝试做什么、结果如何”,便于事后追溯和合规审计。
5.5 度量与演进:让 Harness 在数据中成长
最后,有效合理的评测用来衡量 Agent 系统是否“跑在正确的轨道上”:
-
任务效能(Task Effectiveness)
-
任务成功率(Task Success Rate)
-
指令遵循度(Instruction Following Rate)
-
工具使用有效性(Tool Use Effectiveness)
-
服务质量(Quality of Service)
-
端到端延迟(End‑to‑End Latency)
-
首次响应延迟(Time to First Action)
-
错误率(Error Rate)
-
资源效率(Resource Efficiency)
-
平均 Token 消耗(Avg。 Token Consumption)
-
平均工具调用次数(Avg。 Tool Calls)
-
安全与合规(Security & Compliance)
-
策略拒绝率(Policy Denial Rate)
-
安全事件数(Number of Security Incidents)
这些指标不是为了“凑一张大表”,而是用来反向驱动 Harness 的演进:当你发现任务成功率上不去时,很可能需要回到规划器和上下文策略;当错误率和成本居高不下时,多半需要反查沙盒、资源配额和熔断策略是否设计合理。
写在最后

Harness Engineering 从来不是又一个需要顶礼膜拜的“银弹”,而是一套生于实践、归于实践的工程哲学。
构建一套可靠的 Harness 系统,本质上是在软件世界的“混沌”与“秩序”之间寻找那个微妙的平衡点。我们从不奢望 AI 永远正确,正如我们从不指望人类永不犯错。真正的工程智慧,在于构建一个能够从错误中持续学习、在不确定性中稳健前行的系统。
这套“缰绳”的终极目的,从来不是束缚,而是为了更安全、更彻底地释放,或许不远的将来,模型会逐渐挣脱一层层基础束缚。
本文转载自@TRAE.AI公众号,原文地址:https://mp.weixin.qq.com/s/MzB8-B00GVdJy22j42CRgg