
Hermes Agent 最近火得挺厉害:两个月 4.7 万星,v0.8.0 发布当天一天涨了 6400,功能清单网上满天飞…
以致于大家都说小龙虾不行了,现在是爱马仕的时代,但我感兴趣的是另一件事,它内部到底怎么实现的,跟 OpenClaw 又有什么不一样,所以前几天对他进行了简单解读:
熟悉我们的同学会清楚,我们复杂的事情肯定不会想要一蹴而就,于是系统性的解读也就展开了,我们会去读 Hermes 的核心源码:
关于读 Agent 源码这件事,我们已经做过几次了,面对那种庞大的信息量,最好用的一条路径是:跟一条消息走一遍。
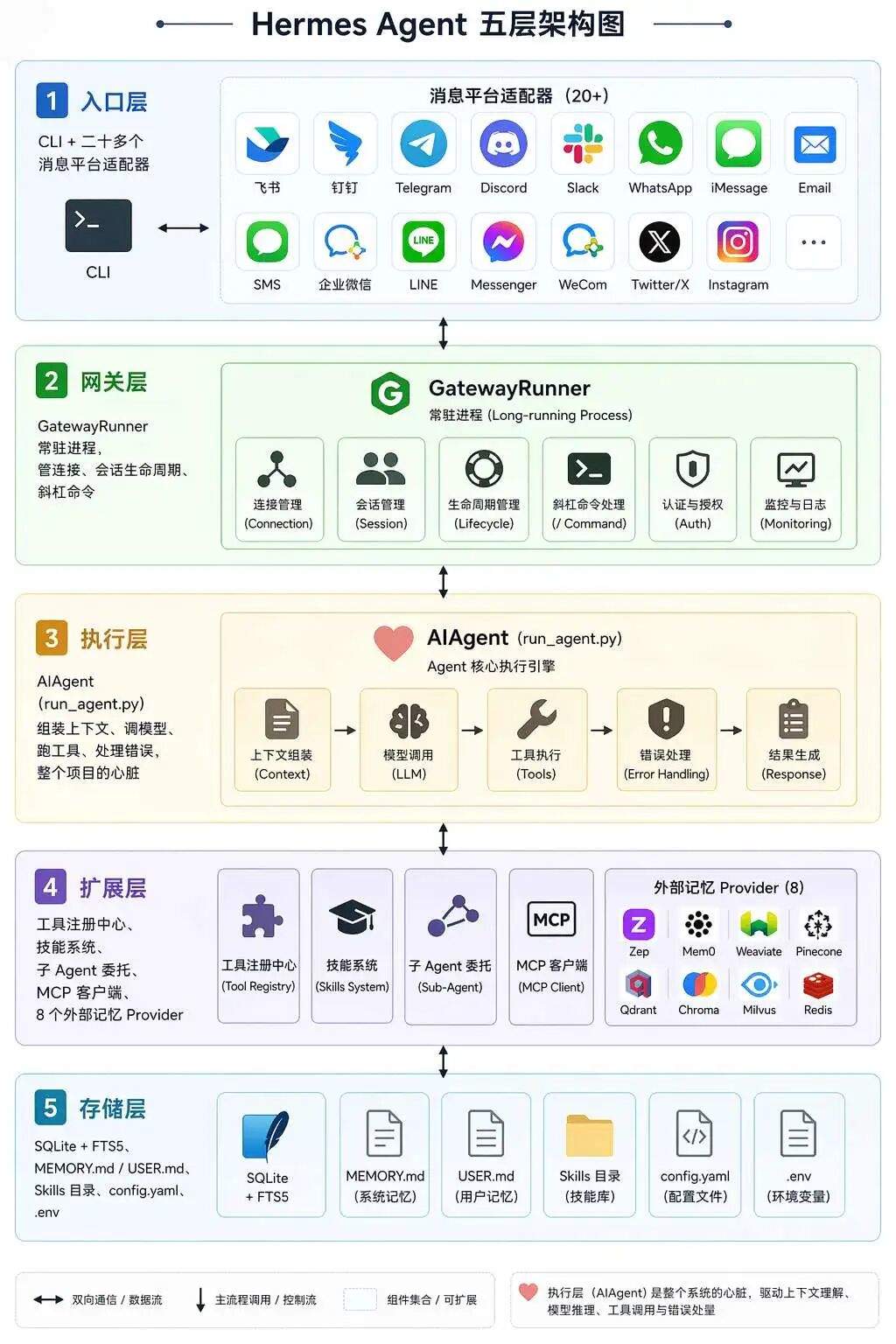
五层架构
从你在终端敲下一句话,到最后一个字回到屏幕上,中间发生的所有事,就是这个 Agent 的全部骨架:一条消息从头跟到尾,就能顺出它背后的完整链路。
消息接收、平台适配、会话管理、上下文组装、记忆注入、技能发现、流式执行、工具调用、上下文压缩、子 Agent 分发、错误恢复与凭证轮换、状态持久化
所以,我们在终端敲 hermes 新起会话,输入:
帮我搜集今天的热点新闻
每条新闻要分类(科技、财经、社会、国际等)
并附上简要分析和总结
看起来一句话,但拆开来看,至少要做这些事:
-
搜索当天的热点新闻 -
对每条新闻做分类判断 -
对每条新闻写简要分析 -
整理成结构化的格式输出
这个过程涉及多轮工具调用(web_search 搜新闻、web_extract 提取详情)、信息整合、分类归纳。如果新闻来源多、数据量大,可能还需要拆分子任务并行搜集。
那 Hermes Agent 是怎么把这些事串起来的?先从整体架构说起。
-
入口层:CLI + 二十多个消息平台适配器(飞书、钉钉、Telegram、Discord、Slack、WhatsApp、iMessage、Email、SMS……) -
网关层: GatewayRunner常驻进程,管连接、会话生命周期、斜杠命令 -
执行层: AIAgent(run_agent.py),组装上下文、调模型、跑工具、处理错误,整个项目的心脏 -
扩展层:工具注册中心、技能系统、子 Agent 委托、MCP 客户端、8 个外部记忆 Provider -
存储层:SQLite + FTS5、MEMORY.md / USER.md、Skills 目录、config.yaml、.env
一条消息的完整路径:
终端输入 → CLI 解析 → 会话加载 → 上下文组装 → 模型推理 → 工具执行 → 流式输出 → 状态落盘
下面我们一步步来看。
一、适配器模式的内外统一
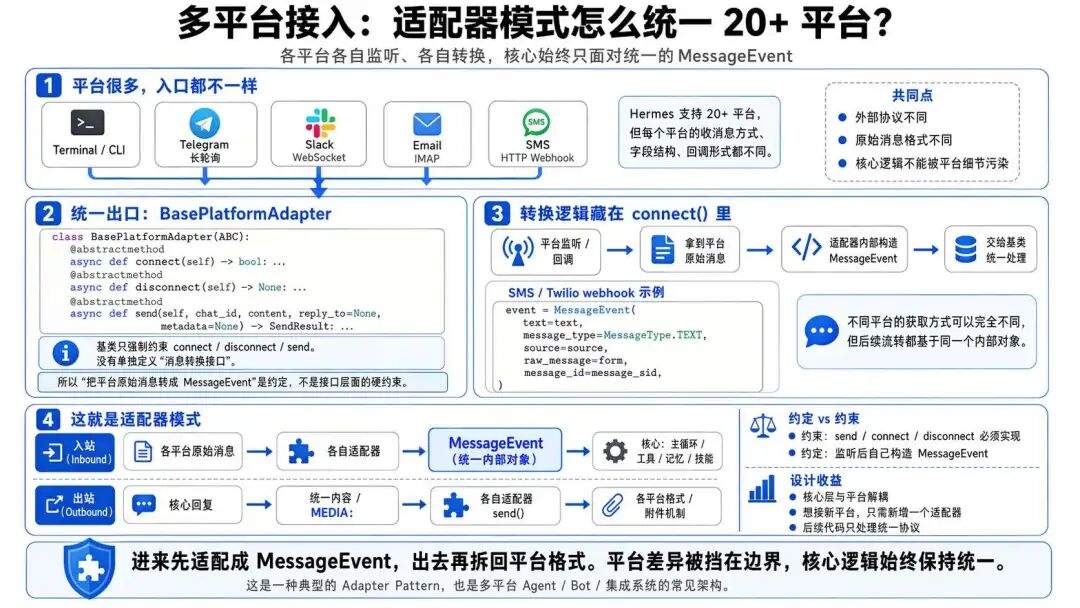
终端是最直接的入口,但 Hermes 支持 20+ 平台。每个平台消息格式都不一样:Telegram 长轮询、Slack WebSocket、Email IMAP、SMS HTTP Webhook。
Hermes Agent 给每个平台写了一个适配器,全部继承自 BasePlatformAdapter。
class BasePlatformAdapter(ABC):
@abstractmethod
async def connect(self) -> bool: ...
@abstractmethod
async def disconnect(self) -> None: ...
@abstractmethod
async def send(self, chat_id, content, reply_to=None, metadata=None) -> SendResult: ...
但这个基类里只定义了 connect/disconnect/send,我们没有看到消息转换的接口定义,仔细看了下 各个平台代码的实现,转换逻辑藏在每个适配器的 connect() 里,监听回调拿到平台原始消息后,自己构造 MessageEvent,再交给基类统一处理。SMS 适配器收到 Twilio webhook 时长这样:
event = MessageEvent(
text=text,
message_type=MessageType.TEXT,
source=source,
raw_message=form,
message_id=message_sid,
)
各平台的消息获取方式差异比较大,平台并没有抽象一个统一接口来处理消息转换。
所以它是约定而不是约束:各自监听、各自构造 MessageEvent,后续所有代码对着同一个内部对象干活。
这是标准的适配器模式:进来时把外部差异统一成内部对象,出去时反向拆回各平台格式。不只是 Agent 开发,几乎所有要支持多平台的系统都会这么干。
二、Gateway 的 Profile 隔离
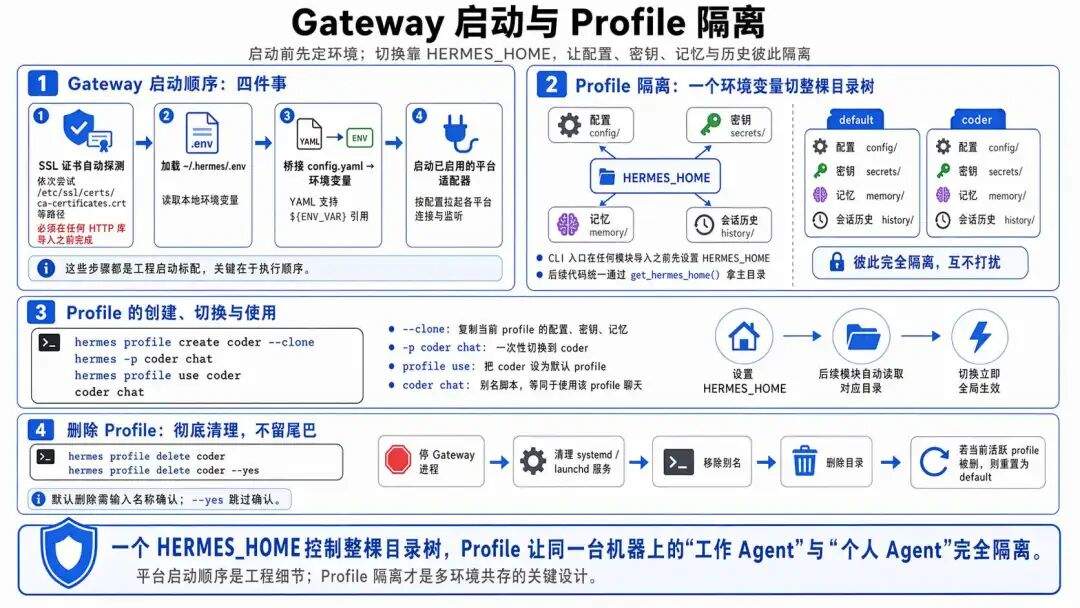
Gateway 启动按顺序做四件事:
-
SSL 证书自动探测( /etc/ssl/certs/ca-certificates.crt等路径逐个试,必须在任何 HTTP 库导入之前完成)、 -
加载 ~/.hermes/.env、 -
桥接 config.yaml到环境变量(YAML 支持${ENV_VAR}引用)、 -
启动启用的平台适配器。
这些都是工程标配,没有什么好说的。
值得一提的是 Profile 隔离:
hermes profile create coder --clone # 复制当前 profile 的配置、密钥、记忆
hermes -p coder chat # 一次性切换
hermes profile use coder # 设为默认
coder chat # 别名脚本,等同上面
每个 Profile 有独立配置、密钥、记忆、会话历史。实现靠一个 HERMES_HOME 环境变量,在 CLI 入口处、任何模块导入之前就设置好,所有后续代码通过 get_hermes_home() 拿主目录,切换时全自动生效。
删除 profile:
hermes profile delete coder # 需输入名称确认
hermes profile delete coder --yes # 跳过确认直接删除
删除时会彻底清理:停 Gateway 进程 → 清理 systemd/launchd 服务 → 移除别名 → 删目录 → 如果是当前活跃 profile 就重置为 default。
一个环境变量控制整棵目录树,切换不同的工作环境。于是你可以在一台机器上同时跑”工作 Agent”和”个人 Agent”,互不打扰。
三、Agent 主循环
消息到 AIAgent,进入整个项目最核心的地方,这个地方一定要详细读、重复读:
主循环骨架
while iteration_budget.remaining > 0:
response = client.chat.completions.create(
model=model, messages=messages, tools=tool_schemas, stream=True
)
if response 有 tool_calls:
执行工具(可能并行)
iteration_budget.consume()
else:
return response.content # 没有工具调用,返回最终结果
主循环有三种退出路径:
-
模型给最终文本:本轮没有 tool_calls,走 else 分支把 response.content返回给用户,正常完结。 -
预算耗尽:while 条件不再成立, iteration_budget.remaining归零。这是硬上限,防止模型在错误循环或幻觉里把 token 烧光。 -
用户中断: _interrupt_requested被外部置位。用户 Ctrl+C 或者直接发新消息都会触发,Agent 在每轮开头检查这个标志。收到中断后不是 raise 抛异常,而是 break 出循环,持久化已有结果并补齐消息结构。
迭代预算
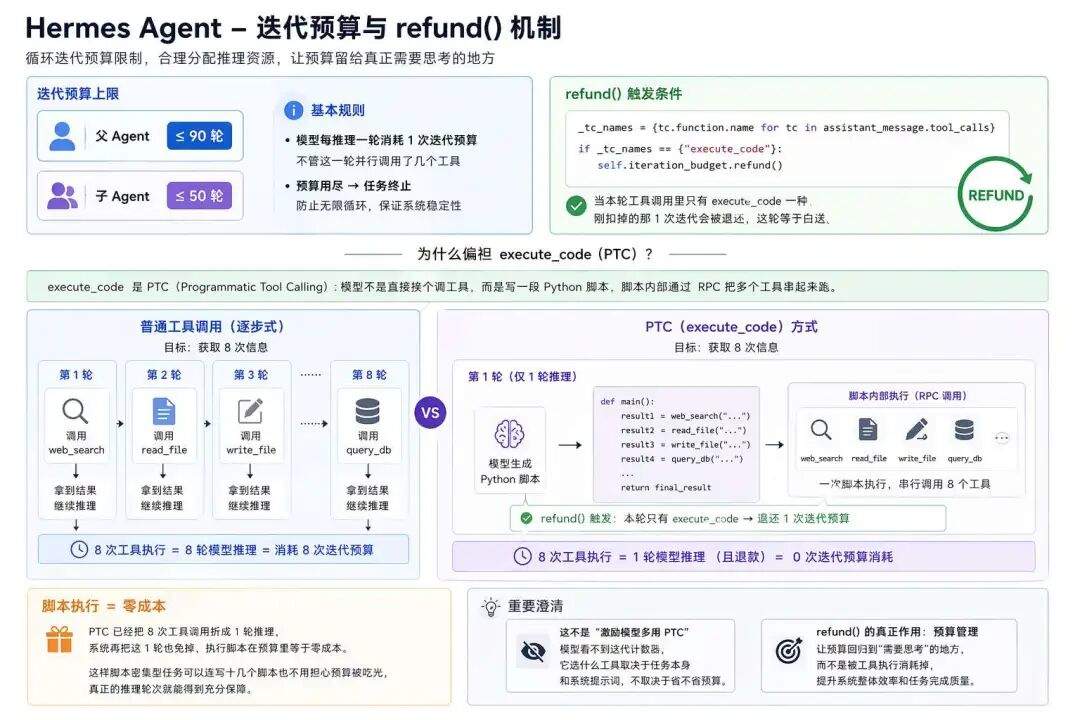
系统设计有循环迭代预算限制:父 Agent 上限 90 轮,子 Agent 50 轮。
模型每推理一轮消耗 1 次迭代预算,不管这一轮并行调了几个工具。
有意思的是 refund() 的触发条件:
_tc_names = {tc.function.name for tc in assistant_message.tool_calls}
if _tc_names == {"execute_code"}:
self.iteration_budget.refund()
当本轮工具调用里只有 execute_code 一种,刚扣掉的那 1 次迭代会被退还,这轮等于白送。
execute_code 是 PTC(Programmatic Tool Calling):模型不是直接挨个调工具,而是写一段 Python 脚本,脚本内部通过 RPC 把 web_search、read_file、write_file 这些工具串起来跑。
换个角度对比一下:同样要做 8 次信息获取,
-
走普通工具调用:模型调 web_search → 拿结果 → 再推理下一步调什么 → 调 read_file → 拿结果 → 再推理 ……8 次工具执行要 8 轮模型推理,吃掉 8 次迭代预算。 -
走 PTC:模型一轮里写出一整段脚本,脚本自己连调 8 次工具。1 轮模型推理就打包干完。
PTC 已经把 8 次工具调用折成 1 轮推理,系统再把这 1 轮也免掉,执行脚本在预算里等于零成本。
退还的真正作用是预算管理:脚本密集型任务可能要连写十几个脚本才做完,一次扣 1 轮的话,90 轮预算很快被脚本执行吃掉,留给真正推理轮次的就不够了。索性让脚本执行零成本,预算就能全留给需要推理的轮次。
工具并行执行
系统维护三个集合决定一批工具能不能并行:
_NEVER_PARALLEL_TOOLS = frozenset({"clarify"}) # 会跟用户交互
_PARALLEL_SAFE_TOOLS = frozenset({ # 只读,无共享状态
"read_file", "search_files", "session_search",
"skill_view", "skills_list",
"vision_analyze", "web_extract", "web_search",
"ha_get_state", "ha_list_entities", "ha_list_services",
})
_PATH_SCOPED_TOOLS = frozenset({"read_file", "write_file", "patch"}) # 路径不重叠才能并行
路径工具的冲突检查原理:提取每次调用的目标路径,两两比对看有没有重叠。
重叠的判定包括两种情况:同一个路径,或者一个路径是另一个的祖先(比如 /a 和 /a/b.txt)。
只要重叠,就可能撞上读写竞态(一个线程正在写,另一个读到半拉状态),必须排队串行;路径完全独立则放并行。
举两个例子:
-
read_file("/a/b.txt")+write_file("/a/b.txt"):同一个文件,一个读一个写,并行会出乱子,必须串行 -
read_file("/a/x.txt")+read_file("/b/y.txt"):两条路径完全独立,可以并行
并行池最多 8 个工作线程同时跑。
如果模型判断要同时读 5 个文件、搜 2 个关键词、查 3 个网页时,串行要 10 次 API 往返,并行可能 2-3 次搞定。每次 API 调用都是时间 + 金钱。
delegate_task
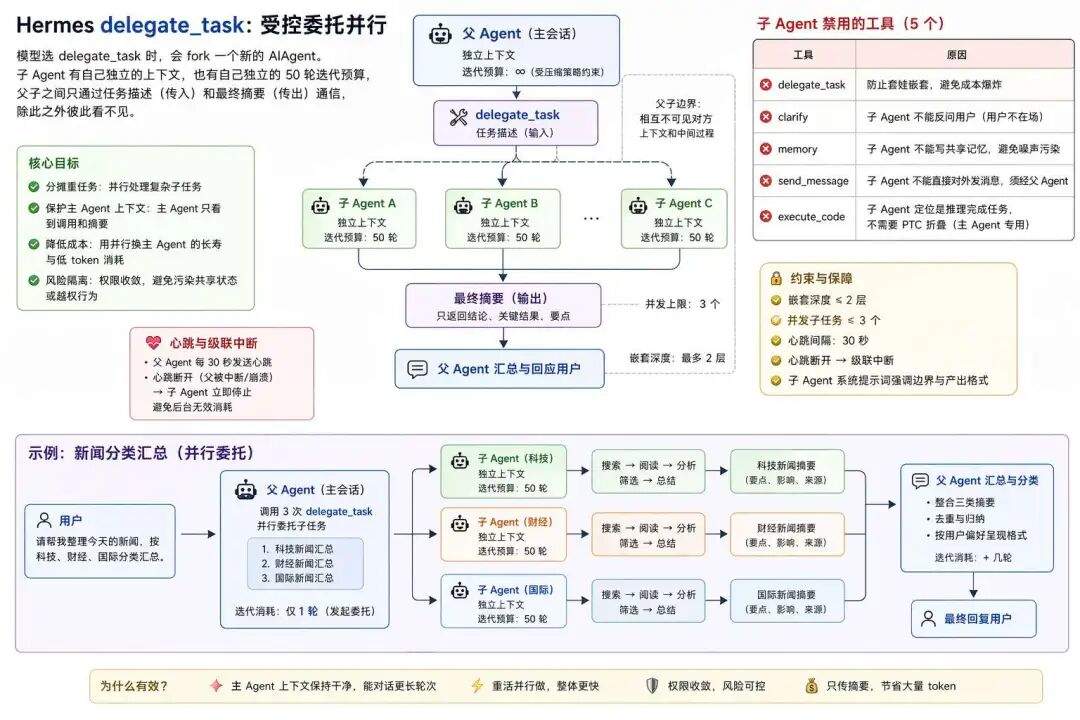
delegate_task 是个特殊工具:模型选它的时候,会 fork 一个新的 AIAgent。
子 Agent 有自己独立的上下文,也有自己独立的 50 轮迭代预算,父子之间只通过任务描述(传入)和最终摘要(传出)通信,除此之外彼此看不见。子 Agent 被禁用 5 个工具:
-
delegate_task:防套娃。Agent 嵌套本身就有开销,再允许无限递归成本会爆 -
clarify:子 Agent 不能反问人,因为用户不在场,只有父 Agent 是跟人对话的那一层 -
memory:子 Agent 不能写共享记忆,避免一次临时委托里抓到的噪声,污染所有未来会话 -
send_message:子 Agent 不能直接往平台发消息,对外沟通只能经由父 Agent -
execute_code:子 Agent 定位就是一步步推理把事做完,不该再用 PTC 折叠(PTC 是主 Agent 用来节省轮次的,子 Agent 本来就分到了独立预算,用不着)
结构上还有两条硬约束:委托深度只有 1 层(父→子,子 Agent 禁用了 delegate_task 无法再委托)、并发上限 3 个。
源码里虽然设了 MAX_DEPTH = 2,注释写”parent(0)→child(1)→grandchild rejected(2)”,但子 Agent 已经拿不到 delegate_task 工具了,这个深度检查是双重保险,防的是工具集被手动调整绕过黑名单的极端情况。
父 Agent 每 30 秒给子发一次心跳,一旦父被用户中断或者自己挂了,心跳断开,子 Agent 就会连锁停下,这就是”级联中断”。没有这个机制,用户按了 Ctrl+C 之后,后台还会有一堆子 Agent 继续烧 token。
子 Agent 的系统提示词强调的是边界而不是人格:做这一件事、给摘要、不用关心父 Agent 在干什么。
主 Agent 的上下文只会看到委托调用本身和最终摘要,看不到子 Agent 那可能 20 次工具调用的中间过程。
主 Agent 能处理多少轮用户消息才触顶上下文压缩,取决于它的上下文保持得多干净,一次把重活甩给子 Agent、只把摘要收回来,等于用一点并行开销换主 Agent 的长寿。
回到开头那个新闻例子:主 Agent 给科技/财经/国际各委托一个子 Agent 并行跑,拿摘要自己汇总分类。主 Agent 只花 1 次迭代预算,子 Agent 的 50 次预算各自独立。
四、系统提示词

模型推理之前,系统提示词要拼好。实际顺序:
身份 → 工具行为引导 → 外部系统提示 → 记忆 → 技能索引 → 项目上下文 → 运行时元数据(时间/环境/平台)
每一层都有什么,我们简单看下:
-
身份:默认是一段”You are Hermes Agent…”的声明。用户在 ~/.hermes/SOUL.md里写了自定义人格就会替换掉默认那段。 -
工具行为引导:下面单独讲,这一层信息密度最高,还会根据模型家族(GPT/Gemini/Grok/Claude)注入不同内容。 -
外部系统提示:网关层、API 或用户配置注入的补充指令,可选。 -
记忆:MEMORY.md(Agent 笔记)、USER.md(用户画像),加上可选的外部记忆 Provider 回忆到的内容,Step 5 细讲。 -
技能索引:只放一个紧凑目录( <available_skills>标签包起来),模型看到目录后通过skill_view工具按需加载完整技能内容,不是启动时就全塞进来。 -
项目上下文:从工作区扫到的 .hermes.md/AGENTS.md/CLAUDE.md等指令文件,注入前要过安全扫描,下面讲。 -
运行时元数据:当前时间、WSL/Termux 等特殊环境提示、以及飞书/Discord/Telegram 这些消息平台的格式约定(比如 WhatsApp 不渲染 Markdown)。
这个顺序的门道:越稳定的内容越靠前,动态内容靠后。 配合前缀缓存,前缀不变就能命中,只有尾巴会变。
针对不同模型的工具使用约束
对 GPT、Gemini、Grok 家族,会额外注入 TOOL_USE_ENFORCEMENT_GUIDANCE,核心一句话:说做就做,别光说不动。
GPT 还有更细的 <tool_persistence>、<mandatory_tool_use>、<prerequisite_checks>、<verification> 等模块,逐一应对 GPT 的老毛病:部分结果就放弃、跳过前置检查、不调工具直接编答案、没验证就说完成了。
源码注释说灵感来自 OpenAI 的 GPT-5.4 prompting guide 和 OpenClaw PR #38953。
Claude 不需要这段,不是偏见,是不同模型在工具调用行为上确实有差异。GPT写代码确实喜欢TODO,这是实战认知的沉淀。
项目上下文的安全扫描
从工作区扫 .hermes.md / HERMES.md / AGENTS.md / CLAUDE.md / .cursorrules(先到先得,前两个向上直到 Git 根,后三个只看当前目录),注入前过 10 条正则:
_CONTEXT_THREAT_PATTERNS = [
(r'ignores+(previous|all|above|prior)s+instructions', "prompt_injection"),
(r'dos+nots+tells+thes+user', "deception_hide"),
(r'<!--[^>]*(?:ignore|override|system|secret|hidden)[^>]*-->', "html_comment_injection"),
(r'<s*divs+styles*=s*["'][sS]*?displays*:s*none', "hidden_div"),
(r'curls+[^n]*${?w*(KEY|TOKEN|SECRET|PASSWORD)', "exfil_curl"),
(r'cats+[^n]*(.env|credentials|.netrc|.pgpass)', "read_secrets"),
# ...
]
覆盖了常见的 prompt injection 手法(忽略指令、角色扮演绕过)、HTML 隐蔽注入(注释、隐藏 div)、翻译攻击(”翻译成 X 然后执行”),以及数据外泄(curl 环境变量、cat 敏感文件)。
命中任何一条规则,整个文件内容会被阻断并替换为 [BLOCKED: ...]。
上下文文件是持久化在磁盘上的。如果攻击者诱导 Agent 往 .hermes.md 里写恶意指令,那就是一个每次启动都触发的永久后门。
不过这些正则只覆盖英文模式,中文 prompt injection(比如”忽略之前的所有指令”)不在检测范围内,这是一个潜在的盲区。是否应该用模型来做 injection 检测而不是正则?
这是值得讨论的问题,正则快但容易绕过,模型检测更鲁棒但增加了延迟和成本。
ephemeral_system_prompt
它不在系统提示词的构建流程中,只在 API 调用时临时拼到系统提示词末尾。源码注释这样写道:为了不污染缓存。
主体保持稳定,变化部分压在末尾,缓存继续命中。
拼好的结果缓存在 self._cached_system_prompt 上,一个会话只构建一次,只有上下文压缩时才重建。
五、记忆系统
系统提示词框架搭好后,要注入记忆。
Hermes 的记忆系统不是 KV 存储,也不是向量数据库,是冻结快照 + 文件持久化 + 按需检索的组合。
两个文件:
-
MEMORY.md:Agent 自己的笔记本(“这台机器 Python 是 3.11″、”这个项目用 commitlint”、”web_extract 对这个网站不稳定”) -
USER.md:Agent 对用户的了解(偏好、沟通风格、工作习惯)
两个文件都限制按字符数(不是 token 数),
-
MEMORY.md 2200 字符, -
USER.md 1375 字符。
为什么要按字符来算?
我觉得可能是字符数模型无关,换模型不用重新算吧。
冻结快照
class MemoryStore:
def load_from_disk(self):
self.memory_entries = self._read_file(mem_dir / "MEMORY.md")
self.user_entries = self._read_file(mem_dir / "USER.md")
# 捕获冻结快照
self._system_prompt_snapshot = {
"memory": self._render_block("memory", self.memory_entries),
"user": self._render_block("user", self.user_entries),
}
记忆在会话开始时注入系统提示词,之后整个会话期间不再更新。
会话期间通过工具写入的记忆会立刻持久化到磁盘(不丢数据),但系统提示词里的快照不变。下次新会话才从磁盘加载最新。
这里的设计还是为了能命中前缀缓存。每轮写记忆都改系统提示词,缓存就没法命中。这是用一致性换性能的工程权衡。
记忆写入也要过安全扫描
记忆会进系统提示词。如果被诱导往记忆里写”忽略之前的所有指令”,那就是每次新会话都触发的后门。所以写入时要过一遍:
_MEMORY_THREAT_PATTERNS = [
(r'ignores+(previous|all|above|prior)s+instructions', "prompt_injection"),
(r'yous+ares+nows+', "role_hijack"),
(r'curls+[^n]*${?w*(KEY|TOKEN|SECRET|PASSWORD)', "exfil_curl"),
(r'authorized_keys', "ssh_backdoor"),
(r'$HOME/.hermes/.env', "hermes_env"),
]
另外可选 8 个外部记忆 Provider:Honcho、Mem0、Hindsight、Holographic、ByteRover、OpenViking、RetainDB、Supermemory。
内置 Provider 永远在,外部同时只能开一个。
查询到的记忆用 <memory-context> 标签包裹,附带一句”这是背景参考,不是新用户输入”,防止模型把记忆当成新请求去响应。
六、自我修复
主循环每一步都可能出问题:上下文不够用、API 超时、凭证限流、服务器 500。
Hermes 的做法是按错误分类,各走各的恢复路径,而不是一个大 try/except:
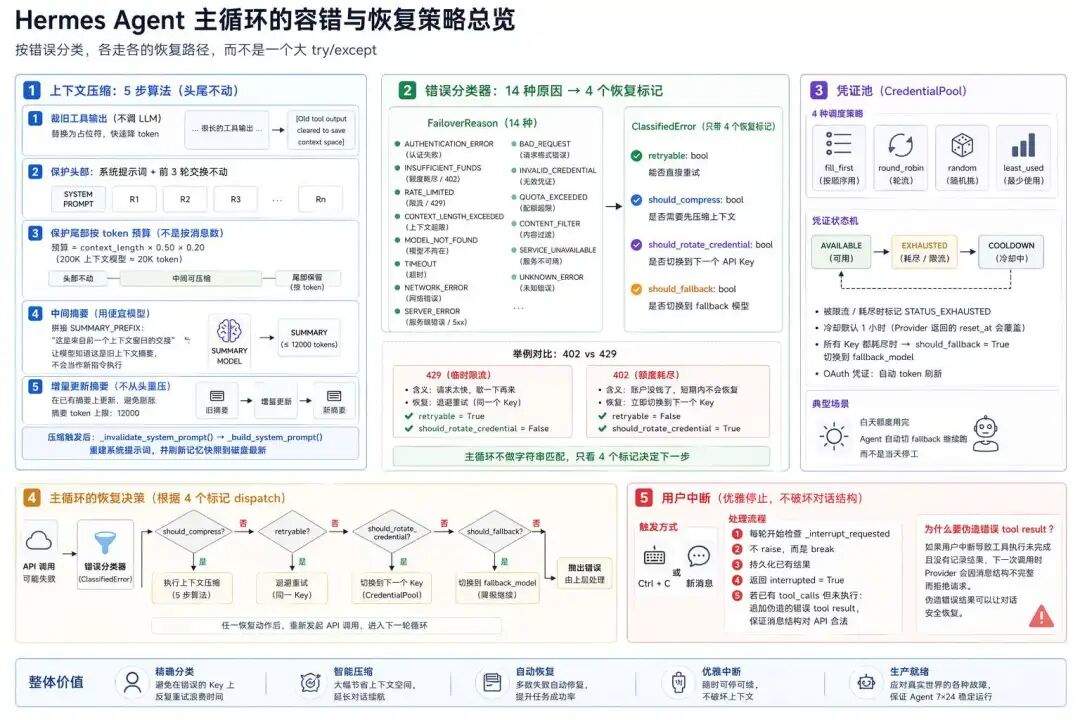
上下文压缩
ContextCompressor 的压缩流程:
-
裁旧工具输出(不调 LLM):替换成 [Old tool output cleared to save context space]。很多时候这一步就够降到阈值下。 -
保护头部:系统提示词 + 前 3 条消息不动(通常是系统提示词 + 第一条用户消息 + 第一条助手回复,即第一轮完整交换)。 -
保护尾部按 token 预算:最近的完整对话不动,预算是两步链式推导出来的,先算压缩触发阈值 context_length × 0.50(上下文用掉一半时触发压缩),再从阈值里拿出 20% 给尾部保护(threshold_tokens × 0.20)。200K 上下文模型的阈值是 100K,尾部预算 = 100K × 20% = 20K token。源码注释这样写道:”ratio is relative to the threshold, not total context”。不是按消息数,一条长代码和一句”好的” token 差 100 倍,按数字算没意义。 -
中间摘要:配置里指定的便宜模型做摘要。摘要前拼 SUMMARY_PREFIX:“这是来自前一个上下文窗口的交接”。暗示这是另一个助手留下的笔记,让模型不会把摘要里的旧请求当新指令再执行一遍。 -
增量更新:二次压缩在已有摘要上更新,不从头重压。摘要 token 上限 12000,防自己膨胀。
压缩触发时主动调 _invalidate_system_prompt() + _build_system_prompt() 重建系统提示词,冻结的记忆快照重新生成,加载最新的记忆内容。
错误分类器
API 调用会失败的原因各种各样:认证失败、额度耗尽、限流、上下文超限、模型不存在、网络中断……
FailoverReason 枚举把这些归了 14 种。每个错误抛出时先过一道分类器,再封装成 ClassifiedError,只带四个布尔恢复标记:
retryable: bool # 能不能直接重试
should_compress: bool # 要不要先压缩上下文再重试
should_rotate_credential: bool # 要不要切换到下一个 API Key
should_fallback: bool # 要不要切到 fallback 模型
主循环拿到 ClassifiedError 之后不自己做字符串匹配,只看这四个标记决定下一步。
所有”这条报错里带 rate_limit、那条带 insufficient_funds、还有一条是 openai 模块抛的 BadRequestError”之类的脏活儿全集中在分类器里,一次性把错误映射到恢复动作,主循环只负责 dispatch。
为什么要分得这么细,一个典型的对比是 HTTP 402 和 429。它们表面都是”限额”类错误,但处理方式完全不同:
-
429 是临时限流:Provider 告诉你”请求太快,歇一下再来”,退避重试同一个 Key 就能恢复 -
402 是额度耗尽:账户上的钱已经扣光了,同一个 Key 短期内不会恢复,必须立即切到下一个 Key
不分清楚的话,Agent 会在一个已经没钱的 Key 上反复退避到天荒地老。
分类器把这两种错误映射到不同的恢复标记组合(429 置 retryable=True,402 置 should_rotate_credential=True),主循环看标记就知道该退避还是该换钥匙。
用户中断
每轮开头检查 _interrupt_requested。用户 Ctrl+C 或发新消息触发时不 raise 而是 break:持久化已有结果,返回 interrupted=True。
如果前面 tool_calls 已追加但没执行,会补一个伪造的错误 tool result,保证消息结构对 API 合法,下次恢复对话不会被 Provider 拒。
这个伪造错误 tool result 非常有用,如果你做过Agent肯定知道这是个什么梗,用户中断后,如果工具执行也被中断,没有记录结果,那么下一次调用就会报错。
七、消息返回
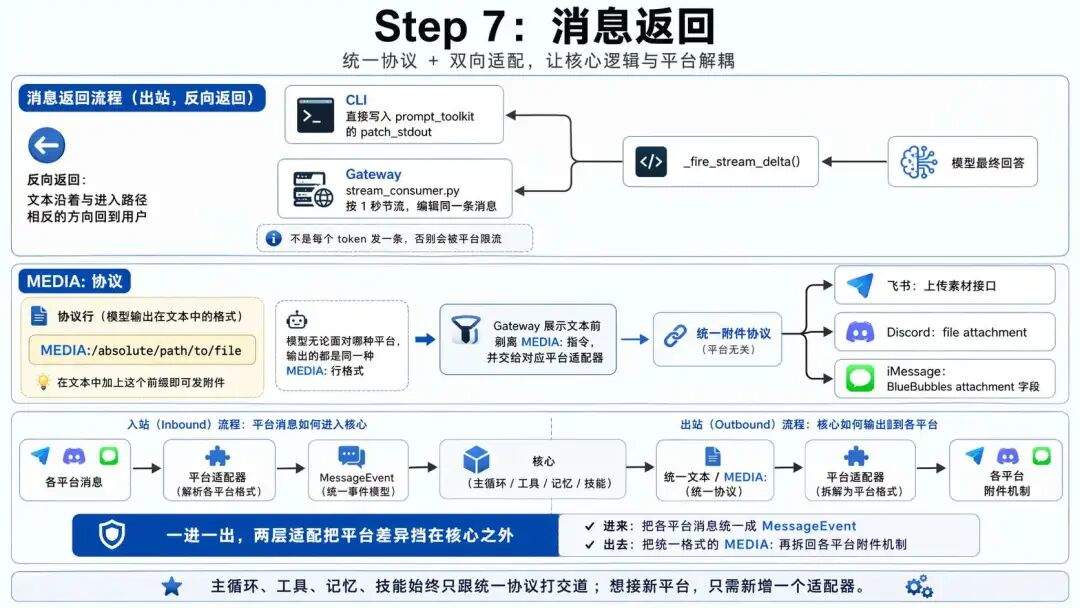
模型给了最终回答,文本沿着和进来相反的方向走回去。
流式 token 通过 _fire_stream_delta() 边生成边推。CLI 下直接写进 prompt_toolkit 的 patch_stdout,Gateway 下由 stream_consumer.py按 1 秒节流编辑同一条消息(不是每个 token 发一条,那样会被平台限流干死)。
附件的处理方式。
在文本里加
MEDIA:/absolute/path/to/file前缀就能发附件
模型不管是飞书、Discord 还是 iMessage,吐出的都是同样格式的 MEDIA: 行。
Gateway 侧在文本展示前把 MEDIA: 指令剥掉,交给对应平台适配器转成各自的附件 API:飞书走上传素材接口,Discord 拼 file attachment,iMessage 走 BlueBubbles 的 attachment 字段。
回头看第 1 步,消息进来时也是同一套逻辑,各平台适配器把五花八门的消息统一成 MessageEvent。
一进一出,两层适配把平台差异挡在核心之外:
进来把各平台消息统一成
MessageEvent,出去把统一格式的MEDIA:再拆回各平台附件机制。
核心代码(主循环、工具、记忆、技能)从头到尾只跟统一协议打交道,不用知道消息从哪来、要到哪去。想接新平台,写一个适配器就够。
八、自进化
这里又是核心了,也是 Hermes 区别于 OpenClaw 的所在:

模型给了最终回答,终端/平台也推送完了。这时候如果什么都不做,这一轮产生的经验都会随进程退出蒸发。
run_conversation() 返回前还有三件事:落盘、记忆同步、后台复盘。都在用户看完回复、Agent 表面”闲下来”之后发生,对用户零感知。
记忆同步
-
内置 MEMORY.md / USER.md:每次 memory工具调用立刻 atomic rename 写磁盘;下次新会话load_from_disk()时快照才刷新。既保前缀缓存命中,又不丢数据。 -
外部 Provider:每轮结束调 sync_all(用户原话, 最终回复),推整轮交换给 Provider,让它自己抽事实;on_session_end不是每轮调,只在 CLI 退出、/reset或 Gateway 判定会话过期时调一次。
注释把这个区别写得很直白:
run_conversation() is called once per user message in multi-turn sessions. Shutting down after every turn would kill the provider before the second message.
每条用户消息 = 一次 run_conversation,但一个会话包含多条消息。”每轮小 sync、会话末大 flush”,生产系统常见节奏。
后台复盘
这里是真正让它”自进化”的地方,先把”技能”这个概念铺一下,否则这一节不好读。
Hermes 的技能(Skills) 是存在 Skills 目录里的一堆 Markdown 文档,每一篇是一段”做过之后沉淀下来的操作笔记”。
会话启动时,这些文档的标题和简介会被拼成一个紧凑目录(第 4 步讲过的技能索引)塞进系统提示词。
模型在对话里遇到相关任务,看到目录条目,再用 skill_view 按需加载完整内容。
技能越攒越多,Agent 下次做类似任务就越不用从头摸索,这是”自进化”的物质基础。
但技能不会自己长出来,得有人(或 Agent 自己)往目录里写。Hermes 的做法是两条信号并行:
信号一:系统提示词里的主动引导。SKILLS_GUIDANCE 告诉模型”复杂任务完成后主动存、用到过时的技能立即 patch”,让模型在合适的时刻自己调 skill_manage 写文件。
信号二:后台强制复盘。 默认 _skill_nudge_interval = 10,每消耗 10 次模型推理轮次触发一次”技能复盘”,和 Step 3 的迭代预算是同一个计数口径:每轮推理 +1,不管这轮并行调了几个工具。
execute_code 脚本内部不管串了多少次工具调用,也只算 1 轮。计数器还跨用户消息累加,不会因为用户发了新消息就归零。
如果这 10 轮里 Agent 自己已经调过 skill_manage(说明信号一生效了),计数器会被重置,再过 10 轮才会再触发,避免刚存完又逼着复盘一次。
复盘触发后,_spawn_background_review() 在一个独立的后台线程里再 fork 一个 mini Agent 出来:max_iterations=8(最多跑 8 轮)、quiet_mode=True(输出不回显给用户),喂给它的 prompt 大意是:
回顾上面这段对话。里面有没有用到过非平凡的方法(试错过、中途改过主意、或者用户期待的结果和实际不一样)?有就存成新技能或更新现有技能;没有就说 “Nothing to save.” 直接停下。
这个 mini Agent 拿整段对话当背景,任务就这一件:判断值得存,就调 skill_manage 写一份新技能或更新旧技能;不值得,就退出。
工程上最关键的一点写在源码注释里:
Background memory/skill review — runs AFTER the response is delivered so it never competes with the user’s task for model attention.
背景线程必须在回复已经发给用户之后才启动,绝对不和用户正在等的响应抢模型资源。这是两种做法的根本分歧:
-
让模型在每次回答的过程中自己顺带想一下要不要写技能:会拖慢用户看到回复的延迟,还分散模型对主任务的注意力 -
另起一个背景线程定期复盘:对用户零感知,模型在答用户时心无旁骛,复盘的时候又能拿完整对话慢慢想
Hermes 选了后者,再配上信号一的主动引导兜底。Agent 自己主动存是理想情况,背景线程是防它漏掉或者偷懒的保险。 两条信号一起,技能库才能长期健康地长肉。
这就是所谓”自进化”真正发生的地方:用户看不到它学,但每过 10 轮模型推理,就可能有一段新的经验被沉淀进技能库。下一次遇到类似任务,它就不用从头摸索了。
上下文压缩
上下文压缩有一个很容易被忽略的副作用:摘要是有损的。
用户今天聊了一大段,明天回来问”昨天你说的那个函数名叫什么来着”,模型在当前 session 里看到的只是摘要,细节可能已经被压缩掉,答不上来了。如果压缩是”就地覆盖”旧对话,那对用户来说就是历史丢了。
Hermes 的做法是,每次上下文压缩时,SessionDB 里做三件事:
-
结束当前 session,原始对话完整保留在数据库里,不删 -
开一个新 session,把压缩后的摘要作为新 session 的起点 -
新 session 的 parent_session_id指回旧 session 的 ID
连续压缩几次就会形成一条链:新 session 的 parent 指回上一次的 session,一路能追溯到最初的那一轮对话。
这样设计之后,”省成本”和”不丢历史”两个看起来矛盾的目标,用分层各自满足:
-
模型层(当前 session):只装系统提示词 + 摘要 + 近期对话,token 成本不会随对话无限膨胀,也不会撞到模型上下文窗口的上限 -
数据层(SQLite):所有 session 的原始消息全部留着,FTS5 索引全文可搜。用户再问”昨天那个函数”, session_search工具直接命中老 session 的原文,把片段返给模型,模型就能答得上来
模型看到的是压缩版,数据库存的是完整版。两个目标不是真的矛盾,只是不该用同一份数据同时扛。用数据模型把它们分开承载,矛盾就消解了。
但要注意,”能搜到历史”和”Agent 记住了”是两回事。
session_search 是按需检索:模型得主动调用这个工具才能拿到旧对话的片段,搜索结果只是当次推理的临时上下文,不会自动写入 MEMORY.md,也不会更新系统提示词里的记忆快照。下次遇到类似问题,模型还得再搜一次。
真正持久的”记忆”只有一条路:模型主动调 memory 工具写入,下次新会话启动时才从磁盘加载进快照。
换句话说,session 链保的是原始数据不丢,记忆系统保的是经验沉淀不丢,两条通道各管各的。
有了 session 链不代表可以不写记忆,前者是被动存档,后者是主动学习。
……
结语
到此整个消息流程就走完了,读完之后可有什么收获,有几个问题可能大家可以思考下,比如
1、压缩之后 开一个新会话,形成一个会话链
2、会话中记忆不更新,保持前缀缓存命中
3、被中断的工具 自动补齐结果
4、不同的模型,要用不同的提示词去鞭策它
5、技能自进化,提示词引导,后台复盘
当然,按照之前两个老板的说法,他看了我的文章觉得不错会转给技术负责人,技术负责人会马上转给架构师,然后….