


前言|新范式下 Agent 如何参与开发
在传统开发中,git 的工作单元是「一个开发者的一次有意图的决策」,但是 Agentic coding 打破了这个假设:
-
自主执行:agent 可以在无人监督的情况下连续修改数十个文件,跨越数分钟到数小时
-
并发协作:多个 agent 实例可以同时在同一个 repo 中工作
-
任务粒度不匹配:一个自然语言描述的任务可能对应上百次文件操作,agent 对如何切分 commit 没有天然感知
-
决策黑盒:agent 的中间推理过程不会留在 git 历史中,只有最终代码变更可见
以上这些特征催生了一系列传统 Git 工作流难以应对的新挑战。那我们应该如何应对这些调整,我们将从核心痛点出发,为大家推荐更好的实践技巧。
核心痛点
2.1 Git 只记录 diff,不记录意图与推理过程

Git commit 可以精确告诉你「改了什么」,却很难说清 agent 为什么这样改、它依据了哪个 prompt、是否误解了需求。传统开发中,commit message 往往能补充一部分上下文;但 agent 的执行过程完全不同:它可能跨多个模块探索、试错、改写、回滚,最终留下一个看似合理但意图不清的 diff。
这带来的典型问题是:PR 看起来完整,实际解决的却是一些相关的问题而非原始需求;或者 agent 在修 bug 时顺手重构、改依赖、改配置,导致 reviewer 很难判断哪些变更是必要的,哪些只是副作用。
Agent 倾向于产生两种极端的提交模式,进一步加剧了这一问题:
-
巨型单一 commit:将整个任务的所有修改压成一个 commit,diff 动辄数千行,code review 形同虚设
-
无意义碎片 commit:为每一步操作单独提交,历史变成流水账(fix typo、update file、try again),失去语义
「为什么这样做」「权衡了哪些方案」「有哪些已知限制」,这些对未来维护至关重要的信息,agent 不会主动写进提交历史。
2.2 脏工作区难以管控,变更噪声大
Agent 的探索过程比人类更快、更分散,很容易造成工作区混乱。未提交的临时文件、格式化变更、测试 fixture 和真实业务修改混在一起,脏工作区(dirty worktree)一旦累积,审查和回滚都会变得困难。
常见问题包括:
-
Agent 覆盖了开发者尚未提交的本地 WIP
-
git diff 里混入格式化、依赖锁文件、生成代码等噪声,掩盖真实变更
-
Agent 误删文件,或将临时调试代码提交进去
-
多个 agent 在同一 working tree 里互相踩到对方的改动
-
无意中将 API key、数据库连接串等敏感信息写入代码并提交
2.3 Git merge 只是文本校验,但不保证语义正确
LLM agent 会做跨文件、跨抽象层的修改。Git 的 merge 机制是文本层面的:只要没有行级冲突,就认为合并成功。但「无冲突合并」并不等于「语义正确」。
典型场景是:一个 agent 修改了某个接口的语义,另一个 agent 同时在旧语义下新增了调用点。两个 branch 各自通过测试,合并时也没有冲突,但运行时行为已经被破坏。多 agent 并发时,这种问题还会因为彼此不了解对方的修改意图而加剧:
-
Agent 不理解「代码所有权」,不会像人类一样在动公共模块前先沟通
-
自动冲突解决(auto-merge)可能悄悄引入语义错误,没有测试覆盖时很难发现
不能把「分支能 merge」等同于「可以发布」,这一点在 agent 并发开发场景中尤为重要。
2.4 巨型提交让审查、回滚与定位全部失效
Agent 一次性产出「巨型 diff」是最常见的问题之一:功能实现、测试、重构、格式化、文档、依赖升级全混在一起,几十个文件同时改动。这会导致一系列连锁问题:
-
审查者无法快速判断每个变更是否必要,review 质量随 diff 体量的增大急剧下降
-
出问题时 git revert 会撤掉太多无关改动,修复成本高
-
git bisect 找到问题 commit 后,commit 的内部仍然是个大杂烩,根因难以定位
-
Agent 后续修错时又在原有基础上叠加更多噪音,形成恶性循环
git bisect 的价值在于用二分搜索快速找到引入问题的提交节点,但如果每个 commit 本身都包含大量无关变更,即便定位到了问题 commit,排查工作仍然没有彻底完成。
最佳实践
3.1 建立 Agent-Aware 的 Commit 规范
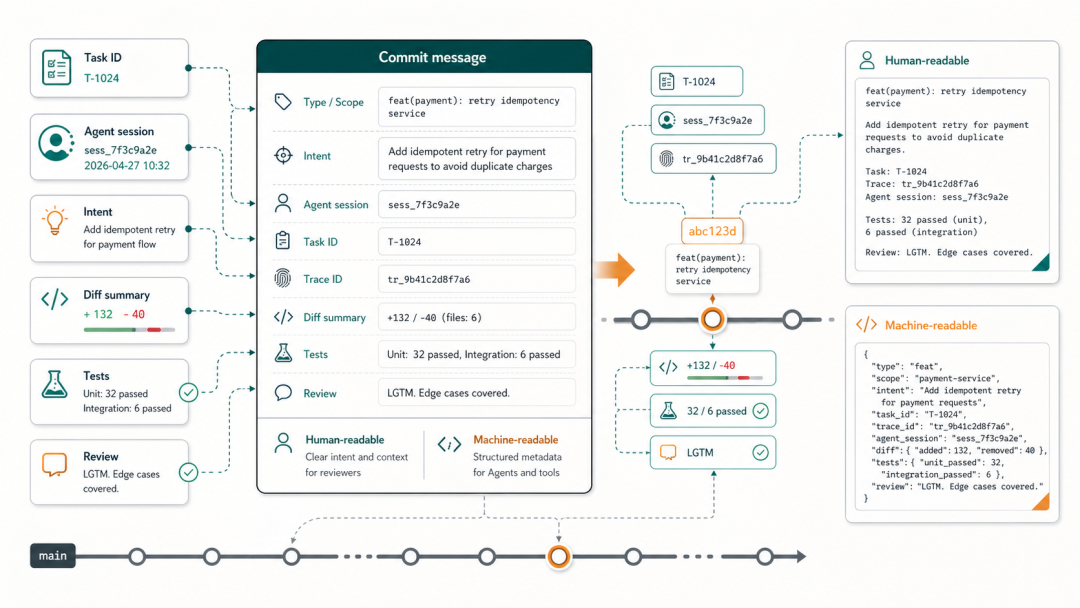
核心原则:每个 commit 应当能独立描述「做了什么、为什么、上下文是什么」。
推荐的 commit message 格式:
示例:<type>(<scope>): <summary>
<正文:描述本次变更的背景与动机>
Agent-Task: <原始任务描述或任务 ID>Agent-Model: <使用的模型,如 gpt-4o、gemini-2.5-pro>Agent-Decision: <关键设计决策及理由>Agent-Limitation: <已知局限或后续 TODO>
feat(auth): implement JWT refresh token rotation
Add sliding-window refresh token support to reduce re-login frictionwhile maintaining session security.
Agent-Task: PROJ-234 - Add refresh token support to auth serviceAgent-Model: gpt-4oAgent-Decision: Used 7-day sliding window over fixed expiry for better UX; refresh tokens stored in httpOnly cookie to prevent XSS accessAgent-Limitation: Redis TTL not yet aligned with token expiry on logout
关于 Git Commit Trailer
上述 Agent-Task:、Agent-Model: 等字段使用的是 Git 内置的 commit trailer 机制。Trailer 是附加在 commit message 末尾(与正文之间有一个空行)的结构化键值对,格式为 Key: Value,由 git 原生解析,无需额外工具。
Git 生态中已有大量使用 trailer 的先例,例如:
Signed-off-by: Alice <alice@example.com>Co-authored-by: Bob <bob@example.com>Fixes: #1234
你可以用标准 git 命令查询 trailer:
# 列出所有包含 Agent-Task trailer 的提交git log --format='%(trailers:key=Agent-Task,valueonly)'# 按 trailer 过滤提交历史git log --grep="^Agent-Task:" --all
工程实施建议:
-
在 agent 的系统提示(system prompt)或 AGENT.md 中明确要求上述格式
-
使用 commit-msg hook 校验 agent commit 是否包含必要的 trailer 字段
-
用类型前缀区分来源:feat / fix / refactor 等遵循 Conventional Commits,agent 生成的提交可额外加 [AI] 标签便于过滤
3.2 小步提交:Checkpoint Commit 策略
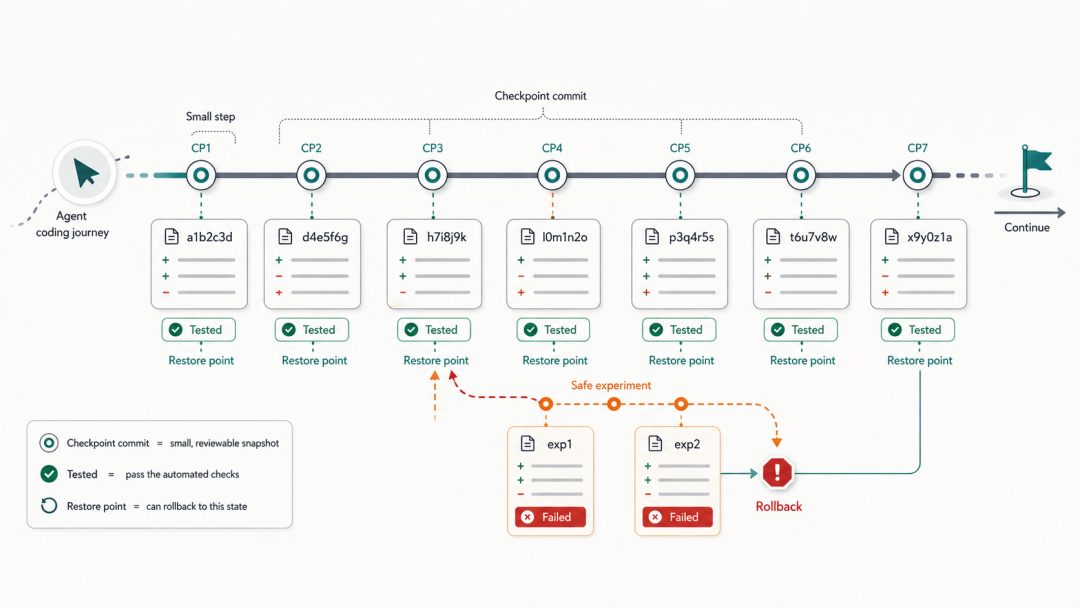
对于耗时较长的 agent 任务,应要求 agent 在关键节点进行「检查点提交」,而不是等任务全部完成再提交。
指令示例:在完成以下关键节点时,执行一次 git commit:1. 完成数据模型/接口定义2. 完成核心逻辑实现3. 完成测试编写4. 完成文档更新
每个 checkpoint commit 的 message 以 [WIP] 开头,最终完成后执行 git commit --amend 或通过 rebase 整理历史。
好处:
-
任务中断时可以从最近的 checkpoint 恢复,而非从头开始
-
Checkpoint commit 天然成为 code review 的切分点,reviewer 可以分段审查
-
便于 git bisect 定位引入问题的具体阶段
3.3 使用 Interactive Rebase 整理 Agent 历史
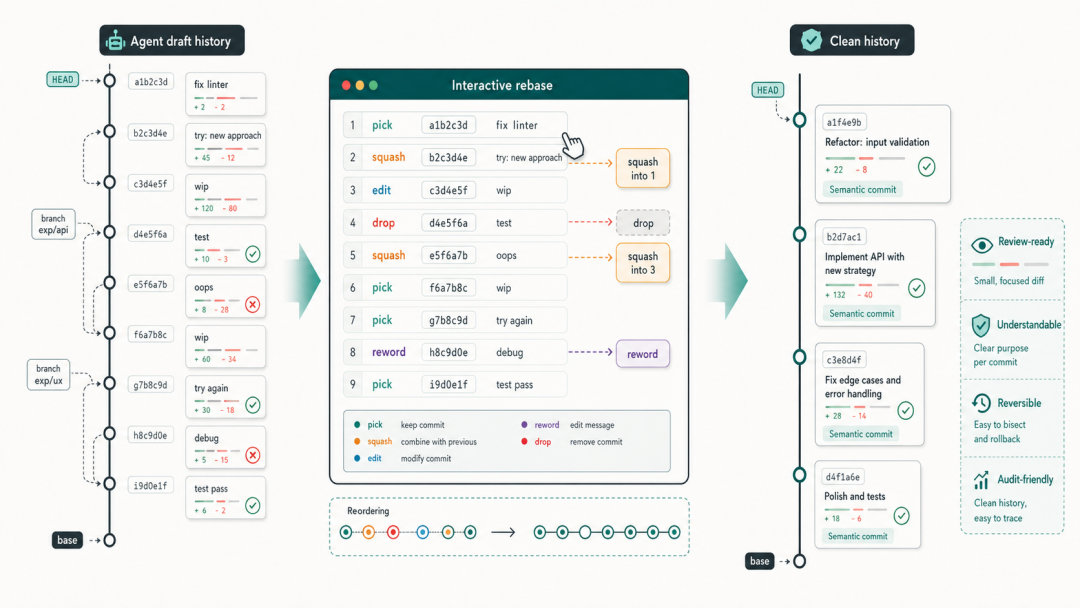
Agent 工作完成后,在合并前对 branch 历史进行整理是一个良好习惯。
建议的整理策略: 查看当前 branch 的提交历史git log --oneline main..HEAD
# 交互式 rebase 整理最近 N 个提交git rebase -i main
# 常用操作: pick - 保留该提交 squash/s - 合并到上一个提交 reword/r - 修改 commit message drop/d - 删除该提交 fixup/f - 合并到上一个提交,丢弃本提交 message
-
将 [WIP] checkpoint commits 合并(squash)为有意义的语义 commit
-
确保最终历史中每个 commit 都能独立理解和回滚
-
不要对已经推送到远程的分支做 force push(除非团队有明确约定)
让 Agent 辅助完成历史整理 整理提交历史这件事本身也可以交给 agent 来做,以下是一个简洁的 prompt,可以在任务完成后直接发给 agent:
请帮我整理当前分支相对于 main 的提交历史,准备开 PR。
步骤:运行 git log --oneline main..HEAD 查看当前所有提交分析哪些提交属于同一个逻辑变更(尤其是 [WIP] 前缀的检查点提交)给我一份整理方案:哪些应该 squash、哪些保留、message 应该改成什么等我确认方案后,执行 git rebase -i main 完成整理整理完成后再次运行 git log --oneline main..HEAD 展示最终结果
要求:每个保留的 commit 需符合 Conventional Commits 格式,并包含 Agent-Task、Agent-Decision trailer。
3.4 Atomic Commit:以原子粒度组织变更
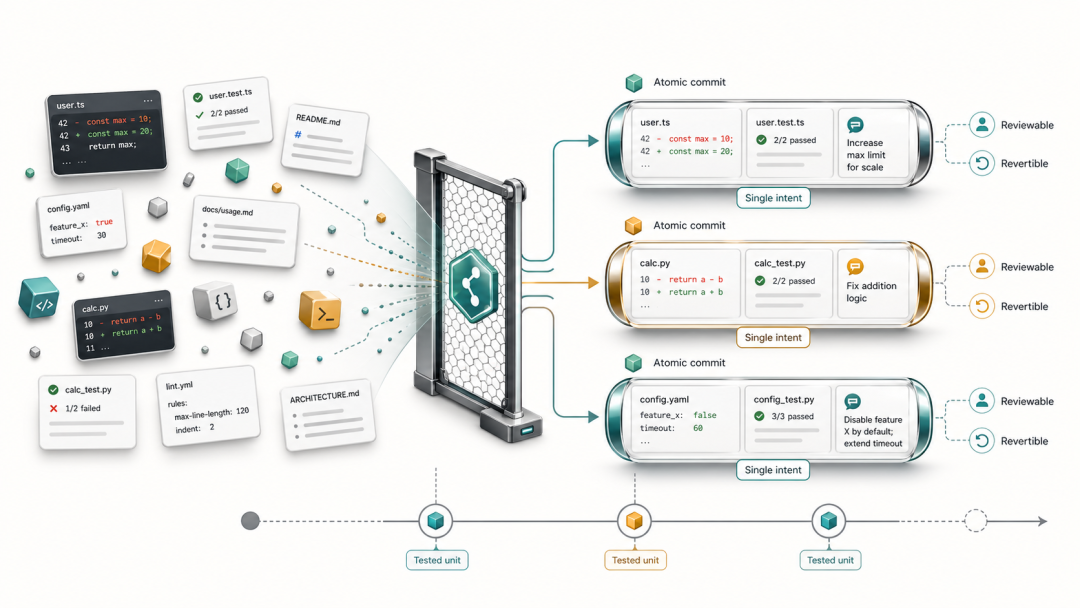
Atomic commit 的核心定义是:一个 commit 只表达一个可解释、可回滚、可验证的语义变化,且在该 commit 节点上代码可以编译、测试可以通过。这一原则在人工开发中已被广泛推崇,在 agentic coding 中更显关键。
为什么 agent 场景更需要 atomic commit:
-
Agent 执行长任务时,往往将多个不相关的修改混入同一次提交,atomic commit 是对抗这种熵增的直接手段
-
保持每个 commit 可独立回滚,是降低 agent 引入问题时修复成本的核心保障
-
Reviewer 可以按 commit 逐步理解变更,而不必面对一个包含所有修改的巨型 diff
-
git bisect 的定位精度直接取决于每个 commit 的粒度,atomic commit 让二分搜索真正有效
实践指南: 这里的 atomic 不是「一行一提交」,而是按逻辑关注点切分。以 refresh token 功能为例:
而不是:
在系统提示中引导 agent 遵守 atomic commit:
与 Checkpoint Commit 的关系: Atomic commit 关注的是语义边界(一个 commit 做一件事),Checkpoint commit(见 3.3 小节)关注的是进度记录(长任务中的阶段性存档)。两者互补:checkpoint commit 在任务进行中保存现场,最终通过 interactive rebase 整理为一组语义清晰的 atomic commit 再合并。# 好的切分:每个 commit 对应一个独立关注点feat(auth): add RefreshToken domain model and repository interfacefeat(auth): implement JWT refresh token issuance in AuthServicefeat(auth): expose POST /auth/refresh endpointtest(auth): add unit tests for refresh token rotation logic# 反例:所有改动压成一个 commitfeat(auth): implement refresh tokenWhen implementing a feature, break your work into atomic commits:- Each commit must represent exactly one logical change- Each commit must leave the codebase in a buildable, testable state- Do not mix refactoring with feature changes in the same commit- Do not mix changes to multiple unrelated modules in the same commit
3.5 强制使用 Feature Branch,禁止直接 push main 分支
这是最基础也最重要的保护:任何 agent 都不应该有权限直接推送到 main 或 master。
分支命名规范:
配置 branch protection rules(以 GitHub 为例): 操作规范:agent/<task-id>-<brief-description>
# 示例agent/PROJ-234-refresh-token-rotationagent/PROJ-301-migrate-postgres-schema- Require pull request before merging: ✅
- Require approvals: 1(至少一个人工审查通过)
- Dismiss stale pull request approvals when new commits are pushed: ✅
- Require status checks to pass before merging: ✅
- Restrict who can push to matching branches: 仅允许 CI bot 和指定人员
-
Agent 每次执行新任务前,从最新的 main 切出新分支
-
任务完成后由 agent 开 PR,但 merge 动作由人工触发
-
避免在同一分支上执行多个不相关的 agent 任务
3.6 使用 git worktree 隔离并发 Agent
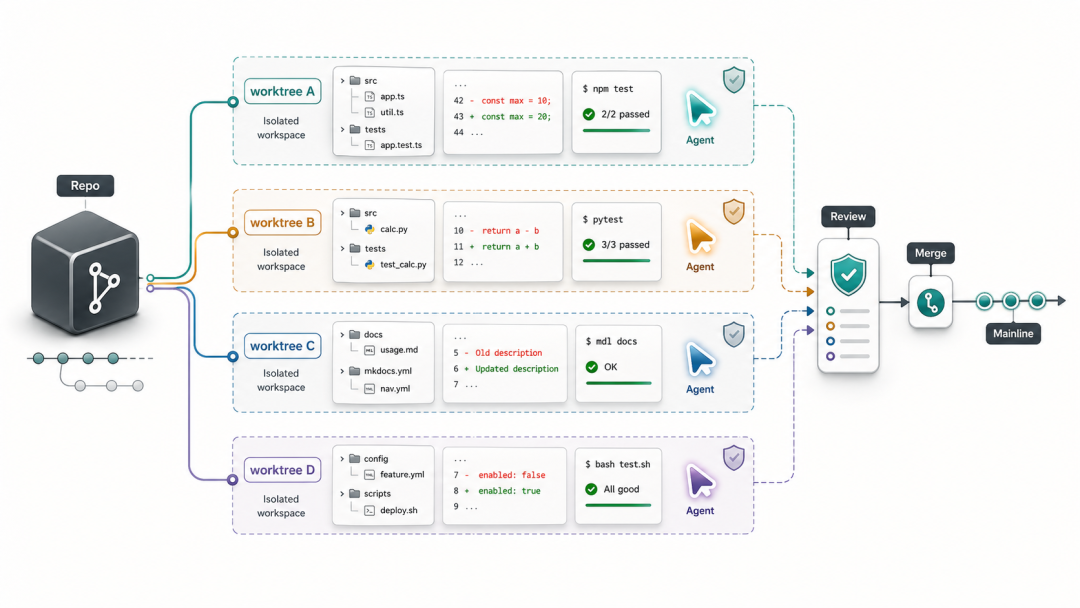
当多个 agent 并行工作时,git worktree 是比多个 clone 更轻量的隔离手段。每个 agent 获得独立的工作目录,脏工作区的问题被天然隔离,同时所有 worktree 共享同一个 .git 目录,分支管理统一。
优势:# 为每个 agent 任务创建独立 worktreegit worktree add ../agent-task-234 -b agent/PROJ-234-refresh-tokengit worktree add ../agent-task-301 -b agent/PROJ-301-pg-migration
# 查看当前所有 worktreegit worktree list
# 任务完成后清理git worktree remove ../agent-task-234
-
每个 agent 有独立的工作目录,不会相互干扰工作区状态
-
共享同一个 .git 目录,分支管理统一,无需多次 clone
-
与 CI/CD 结合时,可以为每个 worktree 独立运行测试
在多 agent 编排脚本中,为每个子任务指定工作目录参数指向对应 worktree 路径,确保 agent 的文件操作被限制在隔离目录内。
3.7 结构化 PR 模板,补充 Agent 上下文
PR 是人机交接的关键界面。应为 agent 生成的 PR 设计专用模板,要求其填写人类 reviewer 需要的上下文。
.github/pull_request_template/agent.md 示例:
工程实施建议:## Task Description<!-- 原始任务描述 -->
## What Changed<!-- 核心变更摘要,聚焦「做了什么」而非「改了哪些文件」 -->
## Key Design Decisions<!-- Agent 做出的关键设计决策及理由 -->- Decision 1: ... because ...- Decision 2: ... because ...
## Alternatives Considered<!-- 考虑过但未采用的方案 -->
## Test Coverage- [ ] Unit tests added/updated- [ ] Integration tests added/updated- [ ] Manual testing performed: <描述>
## Known Limitations / Follow-up Tasks<!-- 当前实现的局限,后续需要跟进的工作 -->
## Review Guidance<!-- 建议 reviewer 重点关注的部分 -->
-
在 AGENT.md 或 agent 系统提示中要求 agent 开 PR 时使用此模板并认真填写
-
使用 GitHub Actions 校验 PR description 是否包含必要章节(可用简单的正则检查)
3.8 维护 AGENT.md:Agent 的「团队规范手册」
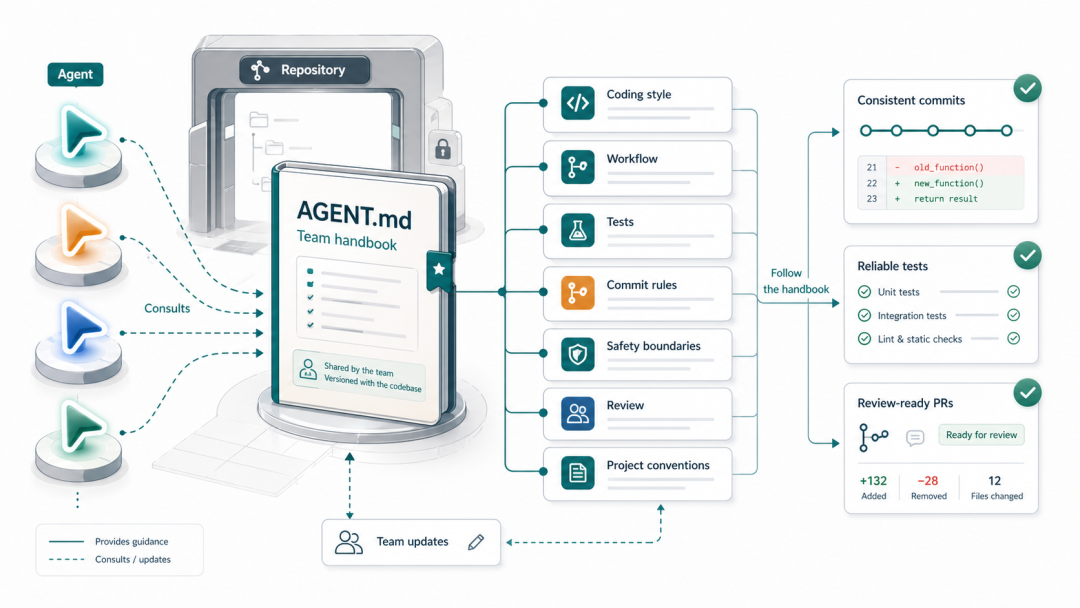
AGENT.md是 agent 的行为规范入口,应当包含所有 VCS 相关约定。将规范写入 AGENT.md,agent 在每次任务开始时都会读取并遵循,是让团队规范真正生效的最低成本方式。
推荐包含的 Git 相关内容:## Git Workflow
### Branch Naming- Use `agent/<task-id>-<description>` for all agent-initiated branches- Never commit directly to `main` or `develop`
### Commit Guidelines- Follow Conventional Commits: https://www.conventionalcommits.org- Each commit must be atomic: one logical change, buildable and testable in isolation- Include Agent-Task, Agent-Decision trailers in commit body
### PR Process- Open PR against `main` using the agent PR template- Ensure all CI checks pass before requesting review- Do not merge your own PRs
### What NOT to Commit- API keys, tokens, passwords (use environment variables)- Build artifacts, `node_modules`, `__pycache__`- Local config files(`.env`, `*.local`)- Large binary files(use Git LFS if necessary)
### Checkpoint CommitsFor tasks expected to take more than 15 minutes:- Commit after completing each major logical unit- Use `[WIP]` prefix in message- Clean up history with interactive rebase before opening PR
3.9 建立 Agent 任务的可追溯性链路
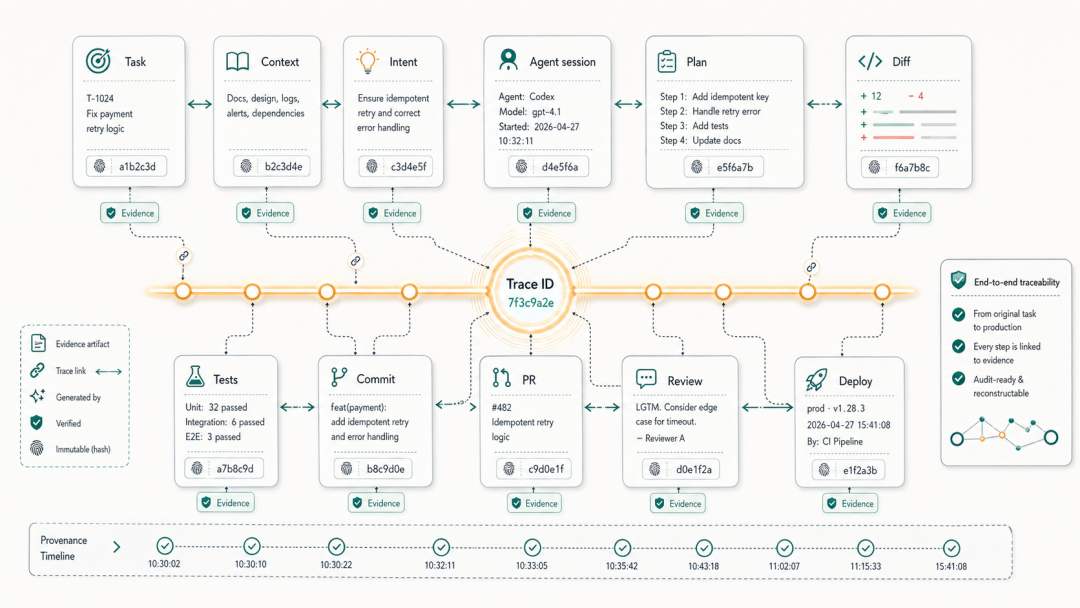
当出现问题时,需要能够追溯「是哪个任务、用什么 prompt、在什么时候」产生了这段代码。
追溯链路设计:
实践建议:任务系统(Jira/Linear) ↓ task-idGit Branch / PR ↓ commit message 中的 Agent-Task trailerAgent Session Log(可选:存储在 .agent-logs/ 目录,加入 .gitignore) ↓ 包含完整的 prompt 和 agent reasoning代码变更
-
在任务管理系统中为 agent 任务打标签(如 ai-generated),便于统计和追踪
-
对于高风险变更(核心业务逻辑、安全相关代码),在 PR 中附上关键的 agent 推理过程截图或摘要
-
定期审计 git log –grep=”^Agent-Task:” 的产出,评估 agent 任务的质量趋势
现有工具 上述链路目前需要靠规范和手动维护来保证,已有一些专门针对这一痛点的产品出现:
git-ai 是一个开源的 Git 扩展(Rust 实现,Apache-2.0 授权),定位为追踪 AI 生成代码的开放标准。它的核心机制是行级归因:支持的编码 agent 在写入代码时调用 git-ai 的 hook,将每一行代码标记为 AI 生成并关联到具体的 prompt 和模型。提交时,归因信息以 Git Notes 的形式附加到 commit 对象上,在 rebase、squash、cherry-pick 等操作后仍能保持正确追踪。整个过程不改变现有的提交工作流,.git/ai 目录存储的临时 checkpoint 在提交完成后自动清理,不会污染提交历史。
Entire 由前 GitHub CEO Thomas Dohmke 创立,定位更为激进:它不替换 Git,而是在 Git 之上构建一个语义推理层,将 agent 的完整决策过程(prompt、推理链、上下文)作为一等公民纳入版本控制。其核心机制是 Shadow Branch:每次 agent 提交时,Entire CLI 将结构化的 checkpoint 对象推送到一个独立的影子分支(entire/checkpoints/v1),主分支完全不受影响。这条影子分支构成一份只追加不修改的审计日志,可以追溯任意提交背后的完整 agent 推理过程,并通过 entire rewind 命令快速回滚到任意 checkpoint 节点。
3.10 关于 Monorepo
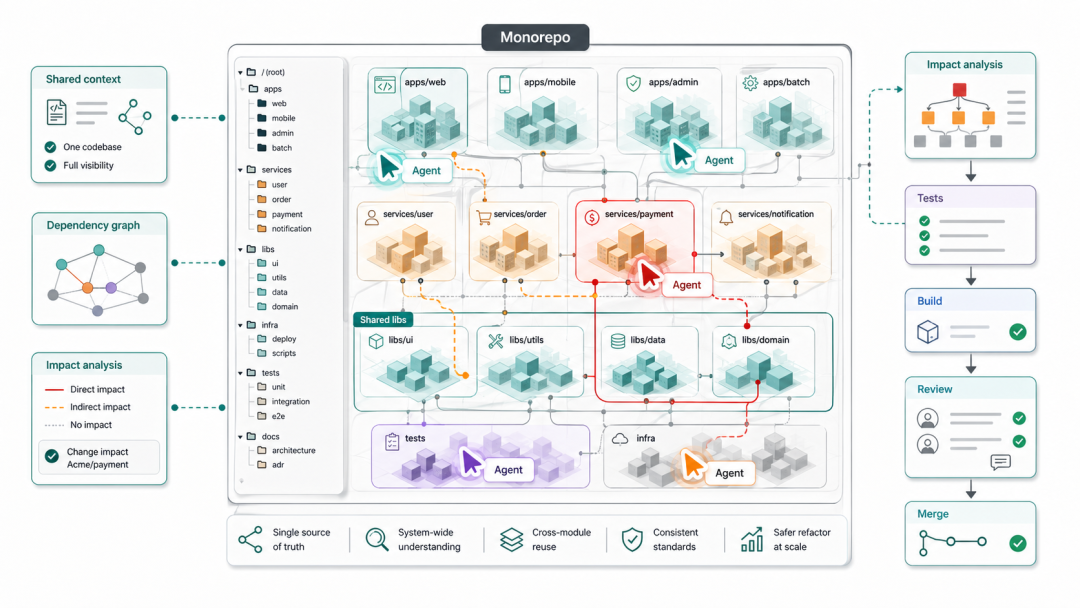
为什么 Monorepo 更适合 Agent
当 agent 实现一个跨越前后端的功能时,它需要同时理解 React 组件如何调用 API 接口、API 接口对应的数据库 schema 是什么、共享类型定义在哪里。在 polyrepo 架构下,这些信息散落在多个仓库中,agent 要么依赖开发者手动把相关代码粘贴进 context,要么在跨仓库调用中做出错误假设,导致接口不匹配或重复实现。
Monorepo 将所有代码放在同一个仓库中,agent 可以在单次 context 窗口内完整追踪一个用户动作从 UI 到数据库的完整链路。这不只是方便,更是 agent 能否可靠执行跨服务任务的基础条件。
具体来说,monorepo 在 agentic coding 场景下有以下优势:
完整的跨服务上下文:agent 无需在多个仓库之间跳转,可以在一次任务中同步修改 API 定义和对应的客户端调用,保证接口一致性。这类修改在 polyrepo 中需要多个协调的 PR,agent 往往无法独立完成。
大规模重构与迁移:monorepo 让 agent 能够可靠地执行影响范围广的重构,例如将一个共享 utility 函数的签名改变后,同时更新所有调用方。在 polyrepo 中,这类任务需要跨仓库协调,而 agent 当前的能力边界还难以可靠处理这种情况。
依赖图可见性:monorepo 工具(如 Nx、Turborepo)通常提供结构化的项目依赖图。Agent 可以查询「修改了 package A 之后,哪些 package 受到影响」,从而精确决定需要运行哪些测试,而不是盲目运行所有测试套件。
Monorepo 下的 VCS 挑战与应对
Monorepo 并不是没有代价的,在 agentic coding 场景下,它引入了一些额外的 VCS 挑战:
并发冲突风险更高:所有 agent 共享同一个仓库,在 monorepo 中同时运行多个 agent 时,公共文件(如 package.json、共享类型定义、配置文件)的冲突概率远高于 polyrepo。git worktree 或 GitButler 虚拟分支是应对这个问题的关键手段,每个 agent 任务需要有独立的隔离工作区。
PR diff 更容易变大:即使是聚焦的功能开发,也可能因为涉及共享 package 的修改而产生较大的 diff 范围。Stacked PR(见 3.7 节)在 monorepo 中尤为有价值:将「修改共享 package」和「更新各消费方」拆成独立的 PR 层,可以显著降低每层的审查复杂度。
CI 范围界定:monorepo 中的全量 CI 成本高昂,需要配合依赖图工具实现「只跑受影响 package 的测试」,代码增量编译的能力和稳定性也非常重要。可以在 AGENT.md 中明确说明哪些 CI 命令适合 agent 在本地运行:
### CI Commands for Agents# 只运行受当前变更影响的 package 的测试(需要 Nx 或 Turborepo)nx affected --target=testturbo run test --filter='[HEAD^1]'
# 全量检查(在 PR 合并前由 CI 执行,不建议 agent 本地全量运行)# npm run test:all
Atomic commit 的边界:在 monorepo 中,atomic commit 的「一件事」需要更明确的定义。修改共享 library 的同时必须同步更新消费方,这算一个 commit 还是多个?推荐的做法是:一个 commit 表达一个完整的语义变化,即使它涉及多个 package,只要这些修改在逻辑上是不可分割的(例如接口变更加上对应的调用方更新),就可以放在同一个 commit 中。
3.11 Stacked PR:将大任务拆解为可审查的层叠单元
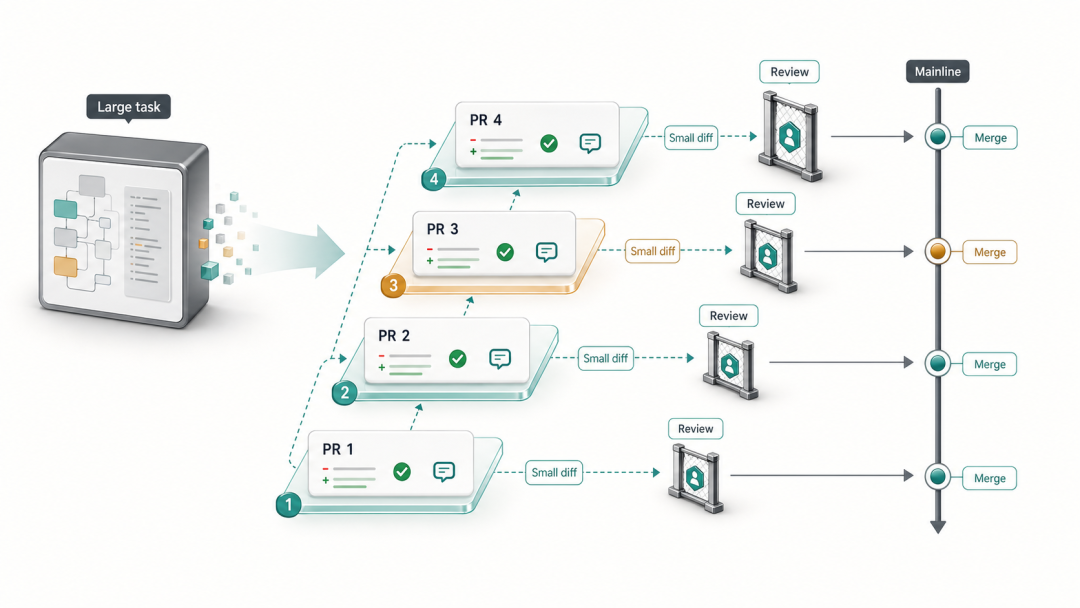
问题背景
Agent 往往能在一次任务中完成数量可观的工作:实现新接口、补充测试、更新文档、升级依赖,这些变更从语义上属于不同关注点,却全部堆进同一个 PR。巨型 PR 的审查质量很低,而简单地「多拆几个 PR」又面临依赖管理的麻烦:PR B 依赖 PR A,PR A 还没合并,reviewer 需要同时理解两个 PR 的上下文。
Stacked PR(堆叠 PR)是解决这一矛盾的工作流:每个 PR 针对前一个 PR 的分支而非 main,形成有序的依赖链。每层 PR 只展示当前层的 diff,reviewer 可以独立审查每一层,合并时按顺序从底部开始依次合入。
main └── PR #1:feat(auth): add RefreshToken domain model └── PR #2:feat(auth): implement token rotation in AuthService └── PR #3:feat(auth): expose POST /auth/refresh endpoint └── PR #4:test(auth): add integration tests
GitHub Stacked PRs(gh-stack)
GitHub 正在以 gh-stack 的形式将 Stacked PR 作为原生特性引入(目前处于 private preview)。它的核心体验包括:
-
PR 头部的 Stack Navigator:reviewer 可以在 PR 页面直接看到整条依赖链,并在各层之间跳转
-
聚焦 diff:每个 PR 只展示本层相对于下一层的变更,不包含下层的内容
-
按层运行 CI:每个 PR 的 CI 针对其实际目标分支运行,而非全量
-
一键合并整个 stack:从最底层开始按序合并,所有 PR 的 branch protection 规则均被独立校验
jj 和 GitButler 对 Stacked PR 的原生支持
使用原生 Git + gh-stack 的主要阻力在于:手动维护分支层叠关系、底层分支变化后需要逐层 rebase、以及在多个 branch 之间频繁切换。后续会介绍的 jj 和 GitButler 从设计上消除了这些摩擦:
Jujutsu:jj 的提交链天然就是 stacked PR 的工作单元。在 jj 中,你只需按顺序创建提交,每个提交对应一个 PR 层;修改任意一层后,jj 自动 rebase 所有后代,无需手动维护级联关系。配合 jj git push 和 gh-stack,可以做到本地改一层、远端整条 stack 自动更新:
GitButler:Stacked Branches 是 GitButler 的核心功能之一。通过 but branch -a 可以将新分支堆叠在现有分支之上,修改底层分支后上层自动 rebase,整个过程无需任何 rebase 命令:jj new -A ywnkulko jj describe -m "feat(auth): add token revocation endpoint"jj git push --all gh stack submit
GitButler 的 GUI 提供可视化的 stack 视图,可以通过拖拽在层之间移动 commit,是管理依赖性较强的多层 PR 的最低阻力路径。# 创建 stack 结构but branch -a feat/refresh-token feat/token-revocationbut branch -a feat/token-revocation feat/token-audit-log
# 修改底层分支的某个 commit 后,GitButler 自动级联 rebase 上层分支# 无需手动执行任何 rebase 操作
# 推送并创建 PRgh stack submit
更适合 Agentic Coding 的 VCS 工具
上面所讨论的最佳实践,本质上是在 Git 现有约束内打补丁:通过规范、模板和 CI 来弥补工具本身的不足。但 Git 的部分局限性根植于其设计哲学,很难从外部彻底解决。
下面给大家介绍两个以不同心智模型重新设计版本控制体验的新兴工具,它们在 agentic coding 场景下更具优势。这些新工具对 Git 保持着不错的兼容性,同时 agent 也很擅长使用这些工具进行版本控制,你只需要对它们的核心概念和心智模型有一定的了解。
4.1 Jujutsu(jj):以变更为中心的版本控制
工具简介
Jujutsu(命令行工具为 jj)是由 Google 工程师 Martin von Zweigbergk 开发的版本控制系统,目前已在 Google 内部大规模使用。它以 Git 仓库作为存储后端,完全兼容 Git 生态,可以通过 jj git init –colocate 在已有 Git 仓库中启用,无需迁移。
心智模型
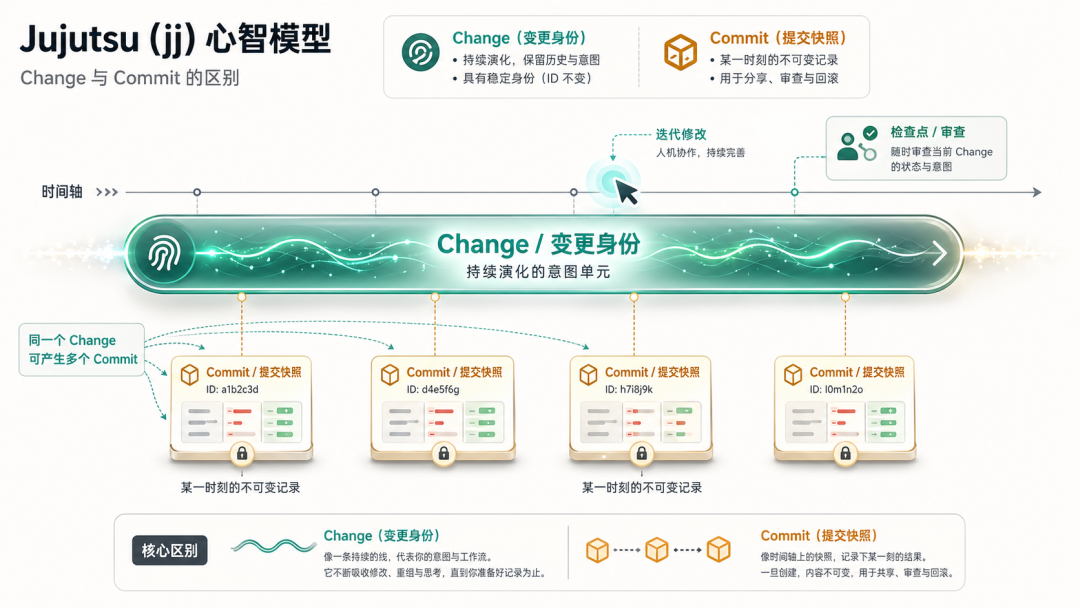
jj 和 Git 最根本的差异在于工作区即提交(working copy as a commit)。
在 Git 中,你需要手动 add 再 commit,工作区是一个独立的「暂存缓冲区」,未提交的内容随时可能丢失。在 jj 中,工作区本身始终是一个提交(标记为 @),任何文件改动都实时反映到这个提交上,永远不会丢失未保存的工作。
由此衍生出几个关键概念:
Change ID vs Commit ID:jj 为每个变更同时维护两种标识符,这是理解 jj 的关键。
-
Commit ID:内容哈希,与 Git 的 commit hash 相同。只要内容有任何改动,哈希就会变化——git commit –amend 之后你会得到一个全新的 commit hash,原来的 hash 就消失了。
-
Change ID:稳定的字母标识符(如 qpvuntsm)。无论你修改这个变更多少次,change ID 始终不变。
用一个熟悉的类比来理解:change ID 就像 GitHub PR 的编号,commit ID 就像 PR 里每次 push 后的具体 commit SHA。当你对 PR #234 追加了新的提交,PR 编号还是 #234,但 commit SHA 已经变了。jj 用同样的逻辑管理本地变更:你可以反复修改一个变更的内容,change ID 始终是你引用它的稳定句柄。
在 jj log 的输出中,两种 ID 同时可见:
左侧较短的字母串(qpvuntsm)是 change ID,右侧的十六进制串(8f3a2b1c)是 commit ID。当你用 jj describe 修改提交信息或用 jj squash 整理内容后,commit ID 会变为新值,但 change ID qpvuntsm 保持不变,jj 借此追踪「这是同一个变更的新版本」并自动 rebase 所有后代,无需手动维护依赖链。
冲突是一等公民:jj 把冲突存储在提交对象中,而不是阻塞操作。jj rebase 在遇到冲突时不会中止,而是把冲突记录到提交里继续推进,你可以随时回来解决,也不需要 git rebase –continue 这类中间状态命令。
操作日志:每条 jj 命令都会在操作日志中留下记录,jj op undo 可以撤销任意操作,相当于整个工作流的无限 undo。
与 Git 的主要差异$ jj log@ qpvuntsm 8f3a2b1c user@example.com 2025-04-2716:42:11│ feat(auth): implement JWT refresh token issuance○ ywnkulko 3d91cc4a user@example.com 2025-04-2714:10:00│ feat(auth): add RefreshToken domain model

解决的 Git 局限性
-
脏工作区问题:工作区始终是已提交状态,agent 的探索过程被自动记录,不存在「未提交的临时文件」丢失的风险
-
巨型提交难以拆分:jj split 和 jj absorb 让拆分和重新归类变更变得极其低成本
-
历史改写的连锁代价:自动 rebase 后代,agent 修改任意历史提交不再需要手动维护提交链
功能示例
jj log:直观的提交图
jj split:将混杂的工作区拆分为独立提交 agent 常见情形:在修 bug 的同时顺手改了格式和配置,全混在一个工作区里。jj split 打开交互式 diff 编辑器,让你选择哪些 hunk 归入第一个提交,剩余的自动成为第二个:
jj absorb:将改动自动归并到最合适的历史提交 agent 对多个功能同时做了少量修改,散落在工作区中。jj absorb 会分析每个 hunk 的 git blame 信息,自动将其归入最合适的祖先提交,无需手动指定:$ jj log@ qpvuntsm 9c1e4f2a user@example.com 2025-04-2716:42:11│ (no description set) ← 工作区当前提交,随时可 describe○ mrzxpkqs 7b30dc81 user@example.com 2025-04-2715:30:00│ feat(auth): expose POST /auth/refresh endpoint○ ywnkulko 3d91cc4a user@example.com 2025-04-2714:10:00│ feat(auth): implement JWT refresh token issuance◆ zzzzzzzz main@origin # ◆ 表示该提交已推送到远端,不可本地改写
jj split 交互式选择 hunk,将 bugfix 和格式化变更拆入两个独立提交 jj 自动将后代提交 rebase 到新的提交链上 jj absorb 自动将 @ 中的改动分发到各个合适的祖先提交 等价于手动做多次 jj squash -i,但完全自动
jj op undo:撤销任意操作 jj op log 查看操作历史@ abc123 (2025-04-2716:45) rebase abc onto main○ def456 (2025-04-2716:40) squash xyz into parent○ ghi789 (2025-04-2716:30) describe commit "feat: add refresh token"
$ jj op undo 撤销上一个操作,回到 rebase 之前的状态
4.2 GitButler:虚拟分支与并发 Agent 工作流
工具简介
GitButler 是一个构建在 Git 之上的版本控制客户端,提供桌面 GUI 和命令行工具 but。它最近获得 a16z 领投的 2200 万美元融资,明确定位为为 AI 驱动开发重新设计的版本控制界面。GitButler 不替换 Git,底层仍是标准 Git 仓库,兼容所有现有 Git 工具链。
心智模型
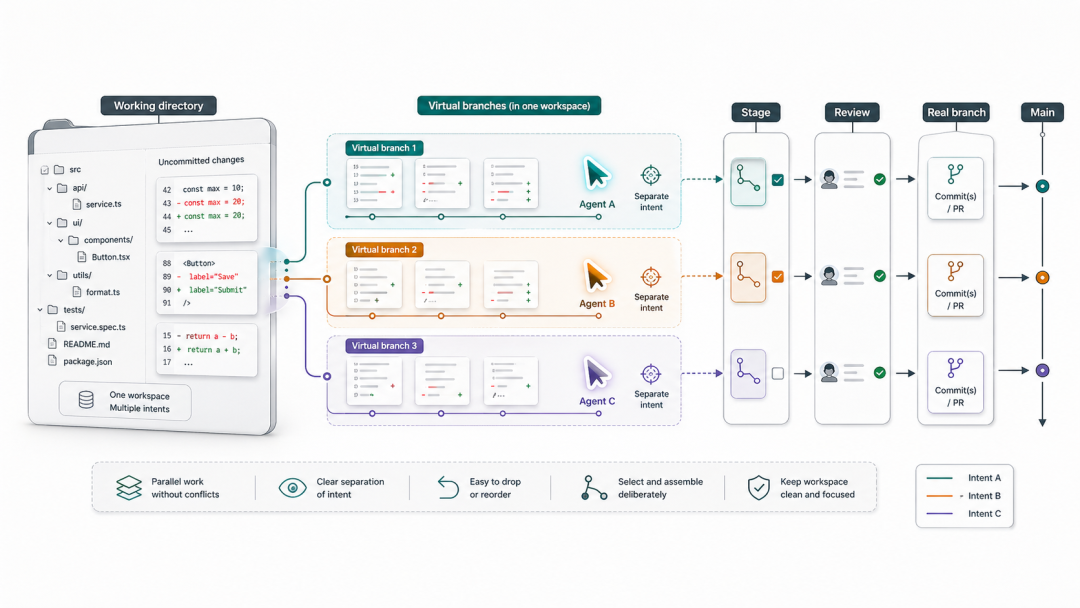
GitButler 最核心的创新是虚拟分支(Virtual Branches):多个分支可以同时处于活跃状态,共享同一个工作目录,而不需要 worktree。
传统 Git 的工作方式是「先切分支再做事」:你必须决定要在哪个分支上工作,然后 checkout,然后修改。GitButler 的工作方式是「先做事再分类」:你直接修改文件,然后将每个 hunk(代码块)分配给对应的虚拟分支。
这对 agentic coding 的意义是:多个 agent 可以同时向同一个工作目录写入,GitButler 按 hunk 粒度将变更归类到不同分支,避免了为每个 agent 单独维护 worktree 的运维负担。
与 Git 的主要差异
解决的 Git 局限性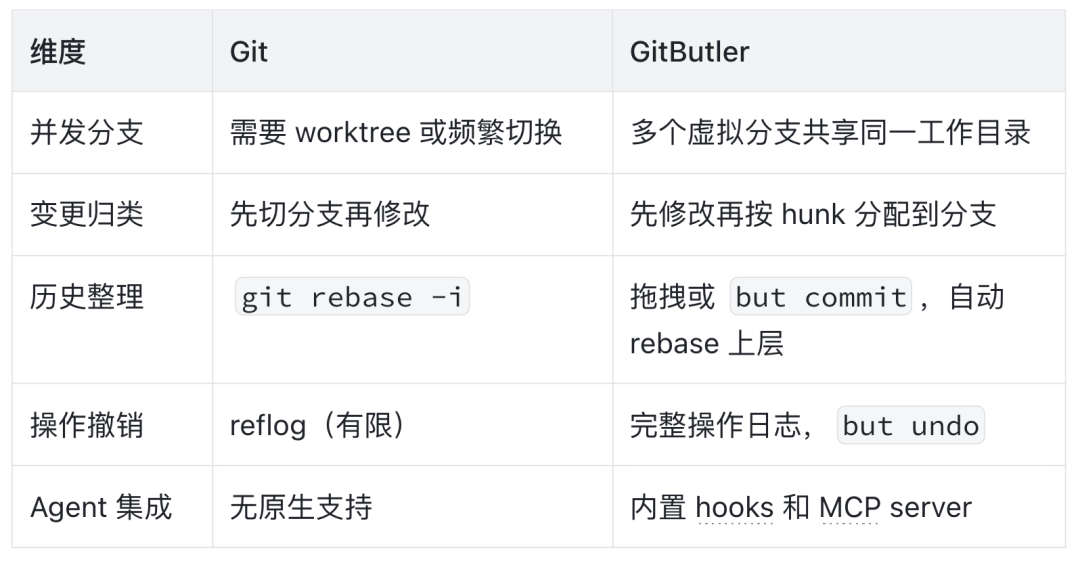
-
脏工作区难以管控:虚拟分支让不同关注点的变更在同一工作目录中保持分离,git diff 中的噪声问题从根源上被消除
-
多 agent 并发冲突:每个 agent 会话绑定一个虚拟分支,互斥的 hunk 自动归类,无需 worktree 隔离
-
大提交审查困难:hunk 级别的分配机制天然产生小而聚焦的提交,stacked branches 支持按依赖关系拆分 PR
功能示例
查看当前工作区状态(JSON 输出,适合 agent 消费)
GitButler 为每个分支、文件、hunk 生成短 ID(如 fe、g0、j1),agent 可以直接通过这些 ID 操作,无需解析完整路径。
将特定文件/hunk 提交到指定分支
but absorb:自动归并到最合适的提交
Stacked Branches:按依赖关系堆叠 PR
修改底层分支时,GitButler 自动 rebase 上层所有分支,无需手动操作。
Agent Hook 集成 GitButler 提供内置 hooks,可以在 agent 工具调用前后自动触发提交管理。通过 MCP server 或者 Skill + CLI,agent 也可以直接调用 GitButler 的能力:读取当前虚拟分支状态、分配 hunk、创建提交,将 VCS 管理完全纳入 agent 的自动化流程。$ but status --json{ "branches": [ { "id": "fe", "name": "feat/refresh-token" }, { "id": "do", "name": "fix/login-redirect" } ], "uncommitted": [ { "id": "g0", "file": "src/auth/service.ts", "hunks": ["j0", "j1"] }, { "id": "h0", "file": "src/auth/controller.ts", "hunks": ["k0"] } ]}
将 service.ts 提交到 refresh-token 分支 but commit fe -m "feat(auth): implement token rotation logic" --changes g0
# 将 controller.ts 提交到另一个分支 but commit do -m "fix(auth): redirect to original URL after login" --changes h0 but absorb 分析每个 hunk 的上下文,自动吸收到最合适的现有提交中 类似 jj absorb,但在虚拟分支体系内操作 创建一个堆叠在 feat/refresh-token 之上的新分支 but branch -a feat/refresh-token feat/token-revocation
# 堆叠结构: main └── feat/refresh-token (PR #1) └── feat/token-revocation (PR #2,依赖 PR #1)
4.3 工具选择建议
值得注意的是,Jujutsu 和 GitButler 并不互斥,也不取代 Git 生态:它们都以 Git 仓库作为后端,与 GitHub、GitLab 及现有 CI/CD 管道完全兼容。在团队中,可以让更熟悉这些工具的成员选择使用,其他成员继续使用 Git,不会产生协作障碍。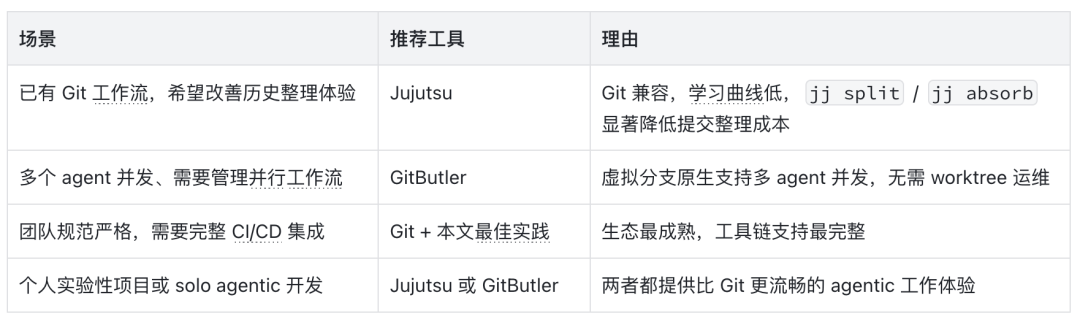
总结
LLM coding agent 带来的不是 git 的终结,而是对 git 使用纪律的更高要求。传统工作流中,版本控制的规范可以靠工程师的经验和团队文化来维持;在 agentic coding 中,这些规范必须被显式化、工具化、自动化,才能真正生效。
核心原则可以归纳为三点:
-
隔离:Branch protection + worktree,为每个 agent 任务提供独立、受保护的工作空间
-
透明:Atomic commit + commit trailer + PR 模板,让 agent 的决策过程在版本历史中可见
-
自动化:CI guardrails + branch protection required checks,用工具而非人工来守住质量底线
随着 agentic coding 工具的快速演进,具体的最佳实践也会持续更新,但「让版本历史成为可信的知识库」这一核心目标不会改变,无论代码是人写的还是 agent 写的。
本文转载自trade.ai公众号,原文链接 https://mp.weixin.qq.com/s/70hz6sYNwxErRkP7dkY8-Q