
有位做企业级SaaS的后端工程师的朋友,被GPT-5.5的定价吓到,输出30美元/百万Token,一个小项目跑下来API账单比服务器还贵。正当他准备砍掉AI功能时,DeepSeek-V4在4月24号突然开源发布,1.6T参数的Pro版定价只有GPT-5.5的十分之一,Flash版更是便宜到离谱。这篇文章就是想搞清楚:便宜归便宜,它到底能不能扛住真实业务场景?
DeepSeek-V4是啥
DeepSeek-V4是深度求索公司在2026年4月24号发布的旗舰大模型,和OpenAI的GPT-5.5选了同一天登场,明显是要正面硬刚。深度求索这家公司2023年才成立,但之前靠DeepSeek-V3已经在国内开发者圈子攒了不少口碑,特点是开源、便宜、参数大得吓人。
这次V4直接扔出两个版本:V4-Pro是1.6万亿参数、激活490亿的MoE架构,主打复杂推理和长文本;V4-Flash是2840亿参数、激活130亿,面向高频轻量任务。两个版本都支持100万Token的上下文窗口,用MIT许可证完全开源。技术上最大的看点是一个叫mHC的超连接机制,据说能让不同专家模块之间的信息流动更高效,具体原理我查了半天论文也没完全看懂,但实测效果是上下文长了之后响应速度并没有明显崩。
官网:https://www.deepseek.com | 项目地址:https://github.com/deepseek-ai/DeepSeek-V4

到底强在哪
知道了它是干嘛的,接下来瞧瞧实际功能硬不硬。
第一个让我眼前一亮的是代码生成能力。某位做金融量化系统的开发者朋友跟我吐槽,他用V4-Pro重构了一个2000行的Python数据处理管道,模型不仅一次性生成了可运行的代码,还主动指出了原代码里三个内存泄漏风险点。更夸张的是,当他说”把这段改成异步协程”,V4直接给出了带错误处理的完整改写方案,而不是只给一个函数骨架。这种”能看懂上下文并且主动补全周边逻辑”的能力,比很多只能按提示词机械输出的模型强不少。
第二个是Agent推理。DeepSeek-V4原生支持工具调用和任务分解,不是那种简单封装个搜索插件就号称Agent的半吊子产品。我实测让它分析一份上市公司的财报PDF,它自动拆解成了数据提取、异常项标注、同比计算、风险提示四个子任务,中途还调用了计算器工具验证财务比率。整个链路在本地用vLLM跑下来,100页左右的文档处理时间不到两分钟。
第三个是长文本处理。100万Token上下文是什么概念?大概能一次性塞进一本300页的书,或者一个中型项目的完整代码库。某位做法律科技产品的创业者说,他们用V4-Flash做合同比对,以前要拆成十几段分批处理,现在直接把两份合同全文丢进去,模型能自己定位差异条款并给出风险等级评估,省去了大量的分段和拼接工作。
注册体验一波
功能听起来不错,那实际用起来顺不顺手?
注册流程倒是简单,去deepseek.com用邮箱或者GitHub账号直接登录,不需要手机号验证。首页就是一个对话窗口,没有花里胡哨的引导页。我第一次测试用的是V4-Flash,输入了一个简单的需求:“写一个Python脚本,把CSV里的日期统一转成ISO格式,顺便处理一下时区”。大概8秒左右返回结果,代码带了注释和三个异常处理分支,比我预期中要快。
几个隐藏技巧
基础操作熟悉了,有几个隐藏技巧能让效率翻倍。
很多人不知道V4的system prompt对输出质量影响极大。官方文档里其实藏了一个”深度思考模式”的开关,在system prompt里加上”请逐步推理并展示思考过程”,复杂数学题的准确率能提升一大截。我试了一道组合数学题,普通模式下给了错误答案,开启深度思考后不仅对了,还展示了三种解法路径。
另一个技巧是缓存复用。V4-Flash的输入缓存命中价格只要0.02元/百万Token,什么意思?如果你有一个固定的system prompt或者重复引用的上下文,第二次调用时只要前面内容没变,就只收这个缓存价而不是全价。某位做客服机器人的开发者算过一笔账,固定知识库加上动态用户query的场景下,开启缓存后整体成本降到了原来的三分之一。
还有一个冷门但实用的功能是批量推理。通过API的batch接口,你可以一次性提交上千条请求,DeepSeek会在后台异步处理,价格还能再便宜25%。适合那种需要大批量生成内容但又不赶时间的场景,比如给商品库批量写描述文案。
和同类比怎么样
单看产品本身不够,得放竞品里比一比才知道水平。
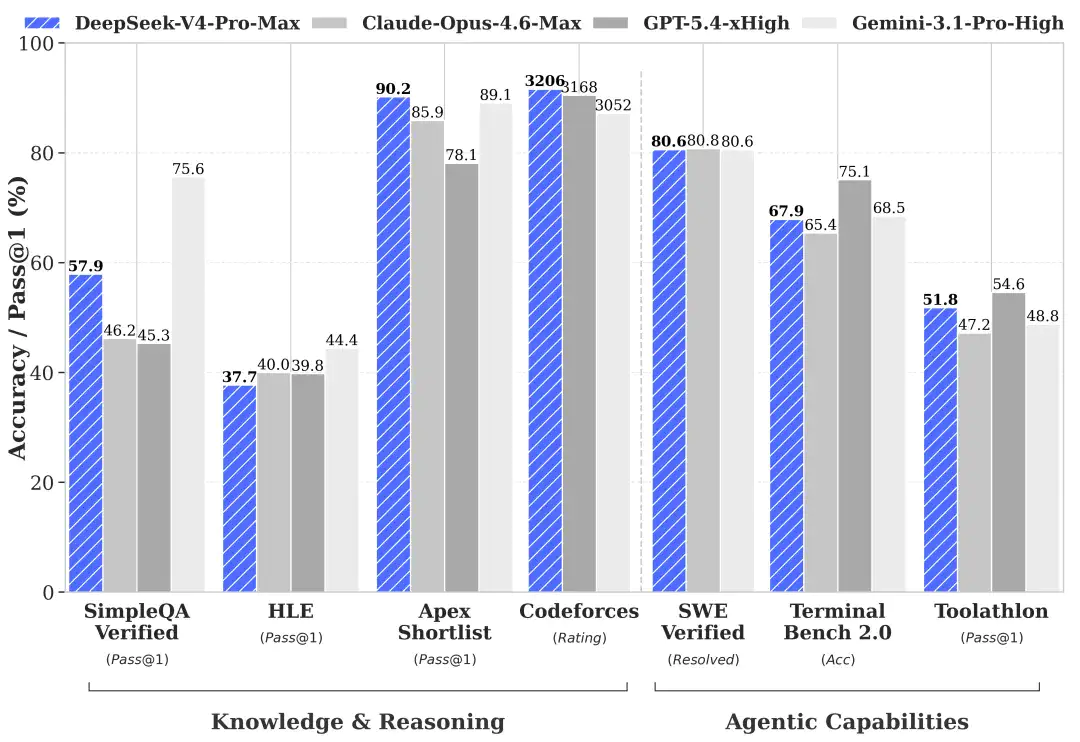
| 对比维度 | DeepSeek-V4-Pro | GPT-5.5 | Claude Opus 4.6 |
|---|---|---|---|
| 参数规模 | 1.6T/49B激活 | 未公开 | 未公开 |
| 上下文长度 | 100万Token | 20万Token | 20万Token |
| 输入价格(/百万Token) | $0.87 | $15 | $3 |
| 输出价格(/百万Token) | $3.48 | $30 | $15 |
| 许可证 | MIT开源 | 闭源 | 闭源 |
| 代码能力 | 接近Opus 4.6 | 最强 | 极强 |
| 长文本 | 原生100万 | 20万 | 20万 |
从表格里能看出一个明显的策略差异。GPT-5.5在性能上依然是标杆,但价格涨到了前代的三倍,输出30美元/百万Token的定价让很多中小团队望而却步。Claude Opus 4.6在代码和推理上依然很强,但上下文只到20万Token,处理长文档时不得不拆分。DeepSeek-V4-Pro的定位很清晰:不追求每项都拿第一,但在”够用”的前提下把价格打到对手的五分之一甚至十分之一,同时用开源和百万上下文建立差异化。
真实用户怎么说
官方宣传是一回事,真实用户怎么评价是另一回事。
开发者社区里的反馈挺两极的。称赞的声音主要集中在性价比和开源自由度上:“终于不用看OpenAI脸色调额度了”、“自己用vLLM在本地部署,数据不用出内网”。一位做跨境电商独立站的创业者说,他把商品描述的生成从GPT-4o切到V4-Flash后,每个月的AI成本从800多美元降到了不到80美元,生成质量他感觉差别不大。
吐槽的点也很集中。排在头一位的是V4-Pro的推理速度,虽然比V3快了不少,但和GPT-5.5相比还是有差距,复杂任务上响应时间大概是对手的两倍。另一个让人头大的是中文语境下偶尔会出现”翻译腔”,比如把英文文档里的惯用表达直译过来,读起来有点别扭。还有用户反馈Tool Calling的稳定性不够理想,偶尔会遇到模型调用了不存在的工具名或者参数格式不对的情况,需要自己加一层容错兜底。
值不值得用
聊了这么多,给一个综合打分可能会更直观。
| 维度 | 星级 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 代码+Agent+长文本全覆盖,缺多模态 |
| 易用性 | ⭐⭐⭐⭐☆ | OpenAI兼容迁移零成本,网页端有限流 |
| 性价比 | ⭐⭐⭐⭐⭐ | 价格仅为GPT-5.5的十分之一,Flash版更便宜 |
| 创新性 | ⭐⭐⭐⭐☆ | mHC超连接+million上下文,开源策略大胆 |
| 稳定性 | ⭐⭐⭐☆☆ | Pro版偶发排队,Tool Calling有小概率出错 |
| 推荐度 | ⭐⭐⭐⭐☆ | 成本敏感型团队首选,追求极致性能另说 |
综合评分:⭐⭐⭐⭐☆(7.9分)
好用的地方和坑
好用的地方:
-
百万Token上下文处理长文档不用拆分,法律科技和学术研究场景直接受益 -
价格优势太明显,V4-Flash的缓存命中价低到几乎可以忽略不计 -
MIT开源意味着可以完全私有化部署,数据敏感行业的合规门槛大幅降低 -
代码生成不是给骨架而是给完整可运行版本,还附带异常处理
需要注意的坑:
-
V4-Pro高峰期需要排队,生产环境建议配个降级方案到Flash版 -
Tool Calling稳定性不如Claude,关键链路需要自己加参数校验 -
中文表达偶尔有翻译腔,对文案质量要求高的场景需要人工润色 -
网页端单文件20MB限制对大文件处理不友好,API端才能放开
适合谁用
说到这,可能有人还在犹豫自己适不适合用。
DeepSeek-V4不是给所有人准备的。基于产品特性和真实用户反馈,这几类人是最对味的:中小型技术团队和独立开发者,API成本低到可以大胆试错,不用担心跑个实验就把预算烧光;需要处理长文档的行业用户,比如法律、金融、科研,100万Token上下文直接省去了分段拼接的麻烦;对数据隐私有要求的企业,MIT开源+本地部署,敏感数据不用出内网;做成本优化的成熟产品团队,已经在用GPT-4o或Claude的,可以考虑把非核心链路迁移到V4-Flash,成本砍半甚至更多。
不太适合的也有:追求极致推理速度的实时交互场景,V4-Pro的延迟还追不上GPT-5.5;对多模态有强需求的团队,目前V4只支持文本,图像和视频处理还没有;完全零基础的非技术用户,虽然网页端能用,但要把API潜力发挥出来还是需要一定的工程能力。
多少钱
功能了解了,钱的事也得说清楚,毕竟模型再强账单扛不住也白搭。
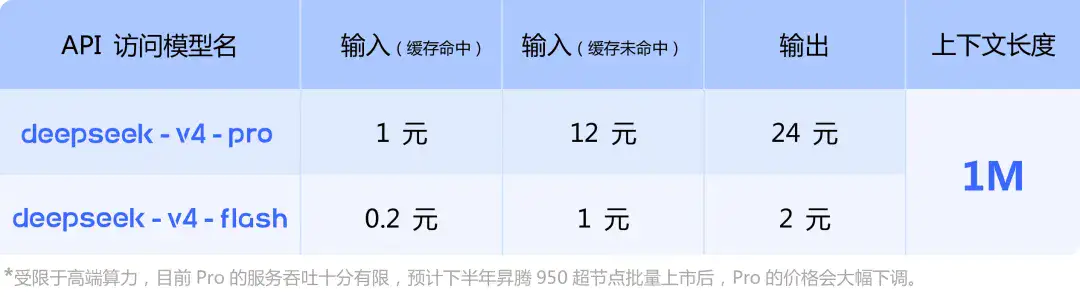
DeepSeek-V4的定价分两个版本。V4-Pro是主力版,输入12元/百万Token,输出24元/百万Token;V4-Flash是轻量版,输入1元/百万Token,输出2元/百万Token。更夸张的是缓存命中价。Flash版输入缓存只要0.2元/百万Token,Pro版也只有1元。如果你有一个固定的大段上下文反复引用,成本几乎可以忽略不计。
隐藏费用要注意:API调用按Token计费,中英文混合内容建议先用tokenizer估算,避免账单超出预期;V4-Pro在2026年5月31日前有2.5折限时优惠,折后输入只要0.22美元/百万Token,但这个窗口期不长。和GPT-5.5(输入15美元/输出30美元)比,V4-Pro日常价就已经便宜了近9倍,打折期间差距拉到将近40倍。Claude Opus 4.6(输入3美元/输出15美元)也在价格上被甩开几条街。
你可能还想问
顺手整理几个大家问得最多的问题,快速扫一遍。
Q:V4-Flash和V4-Pro该怎么选?
A:日常任务选Flash,复杂推理选Pro。 Flash版处理常规对话、文案生成、简单代码完全够用,速度还更快;Pro版留给数学推理、深度代码重构、长文档分析这些吃算力的场景。成本上Flash大约是Pro的五分之一。
Q:开源模型自己部署难吗?
A:取决于你的硬件条件。 V4-Flash用单卡A100就能跑,个人开发者和小团队完全可行;V4-Pro需要多卡集群,推荐直接用官方API或者第三方云平台。寒武纪已经做了vLLM的Day 0适配,部署文档还算清楚。
Q:和DeepSeek-V3比提升大吗?
A:代码和Agent能力是质变,日常对话是量变。 V4在编程基准测试上的分数比V3高了将近15个百分点,Agent任务的成功率从V3的六成左右提升到了八成以上。普通聊天场景差异没那么明显。
Q:中文能力怎么样?
A:能看懂但偶尔有翻译腔。 处理中文文档和对话没问题,但生成中文内容时偶尔会冒出英文思维直译过来的表达,比如把”run the script”说成”运行脚本”虽然没错,但语境里显得生硬。对文案要求高的建议人工过一遍。
Q:可以商用吗?
A:MIT许可证,完全可以。 包括私有化部署、二次开发、集成进商业产品都没问题,没有使用场景限制。这也是很多人从闭源模型转过来的核心原因之一。
Q:API兼容性具体到什么程度?
A:OpenAI SDK改两行代码就能跑。 base_url换成DeepSeek的地址,api_key换成你的DeepSeek key,模型名改成deepseek-v4-pro或deepseek-v4-flash,其余代码基本不用动。连streaming响应的格式都保持一致。
Q:百万Token上下文在实际用的时候有什么限制?
A:长度支持到位,但上传通道有限制。 API端可以充分发挥100万Token的优势,但网页端目前单文件限制20MB,如果你的文档很大建议走API分片上传。而且上下文越长,首Token延迟也会相应增加,这是所有长上下文模型的通病。
Q:Tool Calling的稳定性能不能用于生产环境?
A:建议加一层容错,不建议裸奔。 目前偶发会出现工具名拼写错误或参数格式不对的情况,自己包一层校验和重试逻辑之后可用性会高很多。官方在更新日志里说这块正在优化,可以期待后续版本。
最后说一嘴
用了几天下来,DeepSeek-V4给我的感觉不像是在追GPT-5.5的尾巴,而是选择了一条完全不同的路。它不否认自己在某些单项上还有差距,但用开源+极致性价比+百万上下文这三张牌,硬生生在高端模型和廉价模型之间切出了一个新赛道。对于那些”想用大模型但付不起GPT-5.5账单”的团队而言,这可能就是他们等了很久的选项。如果你已经在用V3,升级到V4几乎没有任何迁移成本;如果你还在观望,Flash版的价格低到值得一试。