

写代码到一半突然要切去调音频、看文档、分析视频,一个模型搞定所有模态,这事以前是奢望。小米 MiMo-V2.5 系列,310B MoE 架构、1M 上下文、全系开源,Pro 版在 SWE-bench Pro 上跑到 57.2%。实测用它接 Claude Code 写了一套公众号数据分析平台,一次部署成功。API 价格比 Claude 便宜六成,V2.5 版本每百万 token 输入才 7 块钱。到底值不值得上车,上手试了才知道。
这是个什么模型
小米大模型团队在 2026 年 4 月突然甩出的 MiMo-V2.5 系列,距离上一代 V2 发布才 36 天。带队的是原 DeepSeek 核心成员罗福莉,团队水平肉眼可见在往上窜。全系列包含四个版本:V2.5 基础版、V2.5-Pro 旗舰版、V2.5-TTS 语音合成和 V2.5-ASR 语音识别,覆盖从多模态理解到语音生成的全链路。
和传统大模型不同,MiMo-V2.5 的核心定位是全模态 Agent。它不是单纯的对话模型或写代码工具,而是把看图像、听音频、读文档、写代码、调用工具这几件事打包成了一个统一模型。
310B 参数但只激活 15B,训练了 48T token,用五阶段训练流程把上下文从 32K 一路撑到 1M。更关键的是,全系开源,权重和分词器都在 HuggingFace 上挂着,不用等内测邀请。
官网:https://aistudio.xiaomimimo.com/#/c
核心功能实测
搞清楚这系列是干啥的了,来看看它到底有哪些拿得出手的本事。
先说全模态能力。V2.5 基础版原生支持图像、视频、音频和文档理解,单一模型就能处理各种输入类型。你上传一段产品演示视频,它能分析画面内容和语音,输出带时间戳的文字摘要。上传冰箱照片让它推荐菜谱?可以。录了会议音频丢进去提取待办事项?也可以。这种跨模态融合在实际工作流里非常实用,不用在多模态和文本模型之间来回切换。
再说 Agent 能力,这是 Pro 版的主场。V2.5-Pro 单次可稳定完成近千轮工具调用,长程任务中能保持逻辑一致和自我修正。
有一个很夸张的数据:它用 Rust 从零写了一个 SysY 编译器,4.3 小时、672 次工具调用,233/233 满分通过隐藏测试集。另一个项目是多轨道视频编辑器 Web 应用,11.5 小时写了 8192 行代码。这种级别的自主项目交付能力,确实够得上”Agent”这个称号。
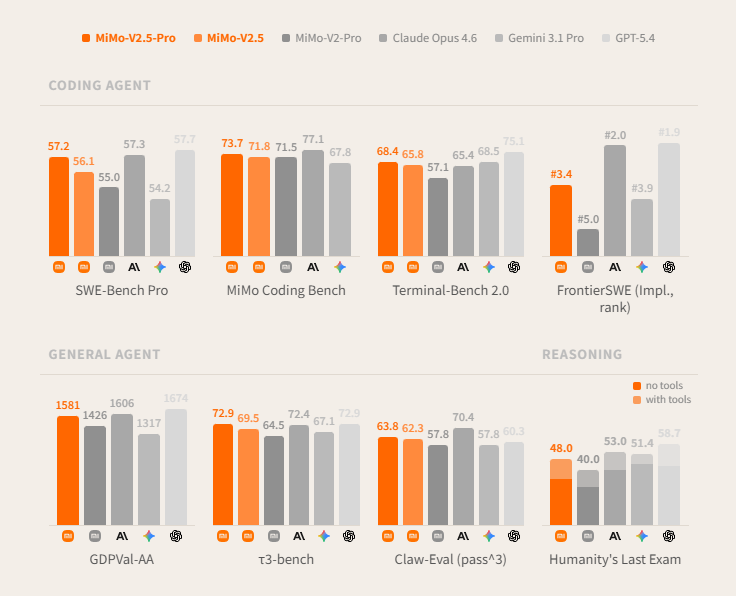
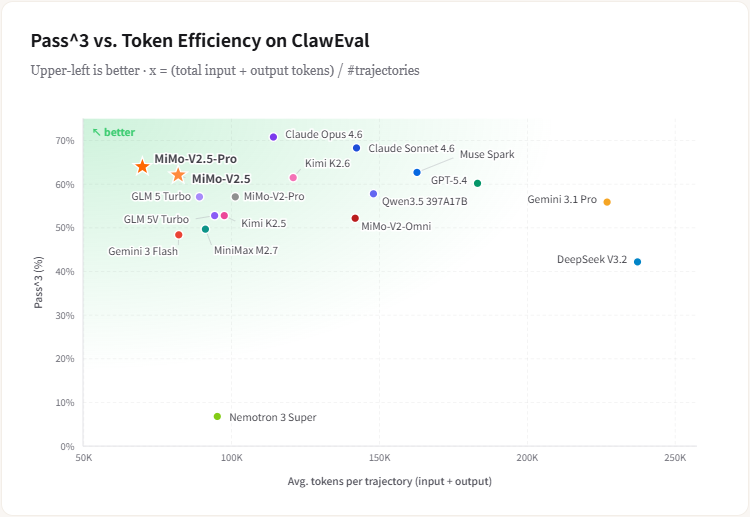
Token 效率是另一个大亮点。同等任务下,V2.5-Pro 比 Kimi K2.6 节省 42% 的 Token 消耗,V2.5 比 Muse Spark 节省 50%。这意味着花同样的钱能跑更多的任务,对大规模部署场景影响巨大。推理速度也够看:V2.5 跑 100-150 tokens/s 适合时延敏感场景,Pro 版 60-80 tokens/s 主打精度。
最后提一下语音能力。TTS 版支持多语种和多种音色,ASR 版的准确率和实时性都有明显提升。虽然单论语音可能不如专门的语音模型,但在全模态链路里作为标配能力,实用度很高。
怎么用
功能参数摆在那,上手才知道实际体验如何。
MiMo-V2.5 的使用路径分两种:普通用户直接去 MiMo Studio(aistudio.xiaomimimo.com)注册登录,选模型就能开聊,不需要写一行代码。开发者走 API 接入,在 platform.xiaomimimo.com 注册开发者账号,创建应用拿 API Key,按官方文档接进来就行。
实测中用 Claude Code 接 MiMo-V2.5-Pro 做了一套公众号数据分析平台。用 cc-switch 工具切换到 Xiaomi MiMo,填 API Key,模型名直接写 mimo-v2.5-pro,一键启用。整个配置过程不到两分钟。
方案设计阶段,V2.5-Pro 输出了完整的架构设计:技术栈、指标体系、转发加速曲线、对比基线、项目结构。定时脚本对接飞书数据库、可视化分析、统一登录中台接入,一次性全部成功,之前用其他模型测的时候这里总是翻车。
说说速度。当前用户还没完全涌进来,API 响应非常快,没有有些国产模型那种”延迟好几秒”的窒息感。整趟测试输出 157.1K token,缓存命中 29.6M,总体消耗意外的少。不过这种窗口期应该不会太长,等大家都反应过来,速度可能就没这么快了。
几个隐藏技巧
很多人不知道还有这些进阶用法:
-
Claude Code + MiMo-V2.5-Pro 组合拳:在 Claude Code 里配置 MiMo 供应商,既能享受 Claude 的交互体验,又能蹭到 MiMo 的高性价比和快速度。这是目前国内最好的 Agent 开发组合之一。 -
用长上下文做全量代码库分析:1M token 窗口足够把中等规模项目的核心代码一次性喂进去,让模型做架构分析、依赖梳理或质量审计。实测《甄嬛传》160 万字全文都能直接处理,普通代码库更是绰绰有余。 -
缓存策略省 Token:V2.5 的缓存目前在限时免费期,反复调用同一段上下文时自动命中,实测一次就能省近 30M 的重复计算。高频 API 调用场景下,这个策略能省出相当可观的成本。 -
全模态 Debug:前端 Bug 截图丢过去,后台报错日志一起贴,它能跨模态关联问题根因。一个朋友说用这个方式排查了一个困扰三天的样式兼容问题,十分钟定位到是 CSS 变量覆盖顺序错了。
横向对比
全模态 Agent 赛道现在挤满了狠角色,Claude Opus 4.6、GPT-5.4、Kimi K2.6 都是绕不开的对手。
| 对比维度 | MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 | Kimi K2.6 |
|---|---|---|---|---|
| 架构参数 | 310B MoE 活跃 15B | 闭源 | 闭源 | 开源 MoE |
| 上下文窗口 | 1M | 200K | 1M | 1M |
| SWE-bench Pro | 57.2% | 领先 | 领先 | — |
| 原生全模态 | V2.5 支持,Pro 专注代码 | 支持 | 支持 | 支持 |
| 定价(输入/百万token) | ¥7 | ~¥36 | ~¥36 | — |
| 开源状态 | 已开源 | 闭源 | 闭源 | 已开源 |
核心差异在于性价比和 Token 效率。Claude Opus 4.6 的能力确实还在第一排,但价格贵了五六倍。MiMo-V2.5-Pro 以三分之一的成本跑出了接近的编码和 Agent 表现,对预算敏感的团队来说是实实在在的诱惑。
跟 Kimi K2.6 比,V2.5-Pro 在 ClawEval 上的 Token 效率高了 42%,同等表现花更少钱。短板在于前端审美,生成的网页”能用但谈不上设计感”,这一点和 GPT-5.4/5.5 类似。如果你对视觉输出有要求,需要配合专门的前端设计工具来弥补。
大家的使用感受
社交媒体上关于 MiMo-V2.5 的讨论热度很高,态度明显分两派。
喜欢的人集中在开发者和全模态场景用户群体。“Claude Code + MiMo-V2.5-Pro 是目前国内最好的 Agent 组合”,这句话在好几个群里都被转发。
有人用它修好了之前搁置的项目的 Bug,顺手还加了打标签和头像功能。”说人话,给图表”是不少人对它对谈风格的共同评价,觉得有股 Claude Opus 的调调。实测 160 万字《甄嬛传》全文分析生成可交互网页的案例在社区里传得很广。
吐槽的点集中在两个地方:一是前端审美能力偏弱,生成的内容在功能上没问题,但视觉效果比较朴素。有人直接说”这个界面跟我十年前写的个人博客一个水平”。二是当前窗口期用户少所以速度快,大家担心用户多了之后速度会降下来。还有部分用户反映文档不够中文友好,上手需要一点英文阅读能力。
多维评分
反馈看完了,下面从这几个方面看看表现
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 全模态+Agent 双强,语音场景稍弱 |
| 易用性 | ⭐⭐⭐⭐⭐ | 网页端即开即用,API 文档清晰 |
| 性价比 | ⭐⭐⭐⭐⭐ | 比 Claude 便宜 60%,还开源 |
| 创新性 | ⭐⭐⭐⭐☆ | 全模态融合在开源里算独一档 |
| 稳定性 | ⭐⭐⭐⭐☆ | 长程任务表现稳定,窗口期速度好 |
| 推荐度 | ⭐⭐⭐⭐☆ | 开发者和开源爱好者非常值得试 |
| 综合评分:8.2 / 10 |
优点和槽点
优势
-
全模态融合:单一模型同时处理文本、图像、音频、视频,不用在多模型间切换 -
超长上下文高 Token 效率:1M 窗口不限场景,同等任务 Token 消耗比竞品低 42% -
开源可自部署:权重和 tokenizer 全部公开,不用依赖第三方 API -
价格优势明显:API 输入 ¥7/百万token 起,比一线闭源模型便宜 60% 以上
不足
-
前端审美偏弱:生成的网页和界面可用但缺乏设计感,需要配合专门工具 -
窗口期红利有限:当前用户少所以速度快,用户增多后速度可能下降 -
文档中文支持一般:部分英文文档对国内开发者不够友好
适合谁用
-
AI 应用开发者:全模态 Agent 能力搭配开源权重,可以自托管做私有化部署,适合需要定制化 Agent 工作流的团队。API 价格低,规模化部署成本可控。 -
预算敏感的创业团队:用不起 Claude Opus 也不想被单一厂商锁定的团队,MiMo-V2.5 是不错的替代方案。性能接近第一梯队,价格只有三分之一。 -
开源模型爱好者:310B 的 MoE 架构权重完全公开,可以做微调、部署和研究,社区生态正在形成。 -
全链路 Agent 需求者:需要图像+音频+文本多种模态同时处理的企业用户,不用在多个模型间切来切去。 -
不太适合的人:对前端视觉效果有极高要求的设计师可能失望,生成界面确实不够精致。
价格贵不贵
功能心动了?看看价格
| 模型 | 上下文 | 输入(每百万token) | 输出(每百万token) |
|---|---|---|---|
| MiMo-V2.5 | 0-256K | ¥7 | ¥21 |
| MiMo-V2.5 | 256K-1M | ¥14 | ¥42 |
| MiMo-V2.5-Pro | 0-256K | ¥14 | ¥42 |
| MiMo-V2.5-Pro | 256K-1M | ¥28 | ¥84 |
和竞品一比就很直观了。Claude Opus 4.6 输入约 ¥36、输出约 ¥180 每百万 token,MiMo-V2.5 直接打到 ¥7 和 ¥21。即使 Pro 版翻倍,整体还是比 Claude 便宜 60% 以上。更别说 1M 上下文不加额外计费乘数,这在同规格模型里很有诚意。
性价比核心在于 Token 效率。V2.5-Pro 在 ClawEval 上比 Kimi K2.6 省 42% 的 Token 消耗,这意味着实际使用成本比单纯看定价更划算。对于每天跑百万级 Token 的开发者来说,一个月能省下可观的预算。
常见问题
Q1:MiMo-V2.5 和 V2.5-Pro 有什么区别?
A1:V2.5 是全模态基础版,V2.5-Pro 是编码和 Agent 旗舰版。 V2.5 支持图像、音频、视频理解,日常通用场景够用;Pro 版专注复杂软件工程和长程任务,适合写代码和开发工具链。
Q2:MiMo-V2.5 开源了吗?在哪里下载?
A2:已全面开源,模型权重和分词器在 HuggingFace 可下载。 访问 XiaomiMiMo 组织下的 mimo-v25 集合,V2.5-Base 和 V2.5 两个模型均已公开。
Q3:API 怎么调用,对开发者友好吗?
A3:注册 platform.xiaomimimo.com 获取 API Key 即可调用。 文档清晰,支持 OpenAPI 兼容格式,可以在 Claude Code、OpenAI SDK 等工具里直接切换供应商使用。
Q4:1M 上下文的计费方式是什么?
A4:1M 上下文不额外加价,按实际 Token 量计费。 V2.5 输入 ¥7/百万token,输出 ¥21/百万token,256K 以上翻倍。对比竞品同等规格的定价相当有竞争力。
Q5:能不能商用 MiMo-V2.5 生成的内容?
A5:API 调用生成的内容归属用户,可商用。 开源权重部署的场景需遵循开源协议,详见 HuggingFace 上的模型卡许可说明。
Q6:MiMo-V2.5 支持中文吗?效果如何?
A6:原生支持中文,中文理解能力在国产模型中处于第一梯队。 训练数据包含大量中文语料,对中文代码注释、文档、对话的自然度都很好。
Q7:MiMo Studio 是什么?需要下载安装吗?
A7:MiMo Studio 是官方网页端对话平台,无需下载。 打开 aistudio.xiaomimimo.com 注册即用,选模型直接聊天,适合想先体验再接入 API 的用户。
Q8:V2.5-TTS 和 V2.5-ASR 和主模型关系?
A8:是独立的语音专用模型,与 V2.5 主模型互补。 TTS 做语音合成,ASR 做语音识别,在需要语音交互的场景下搭配旗舰版使用。
Q9:MiMo-V2.5 和 Claude Opus 4.6 比怎么样?
A9:编码和 Agent 能力接近,价格便宜 60%,前端审美是短板。 如果你主要编码和做 Agent 开发,V2.5-Pro 有性价比优势;对设计质量有高要求则需要额外工具辅助。
Q10:Pro 版真的能写完整项目吗?
A10:实测中完成了编译器开发和视频编辑器两个完整项目。 SysY 编译器 4.3 小时满分通过,视频编辑器 11.5 小时 8192 行代码,单次近千轮工具调用保持稳定。
Q11:MiMo-V2.5 有免费额度吗?
A11:注册后有一定免费额度供体验。 具体额度以 platform.xiaomimimo.com 的最新政策为准,足够完成小规模测试和原型验证。
Q12:V2.5-Pro 的推理速度够快吗?
A12:目前使用人数少,API 响应非常快,实测零等待。 官方标称 60-80 tokens/s,V2.5 基础版可达 100-150 tokens/s。用户增多后可能略有下降,但目前体验极佳。
最后说下
MiMo-V2.5 系列是小米在大模型领域少有的硬仗。310B MoE、全模态融合、1M 上下文、全系开源,参数和理念都拉满了。Pro 版的编码和 Agent 能力确实能跟 Claude Opus 掰手腕,价格却只要三分之一。加上 Token 效率的加成,对预算有限的团队来说吸引力极大。
谁该上车?做 AI 应用的开发者、想自托管开源模型的企业、对 Claude 定价皱眉头的创业团队,都值得一试。谁该观望?对前端视觉效果有强迫症的设计师,以及已经深度绑定 Claude/GPT 生态、对切换成本敏感的用户。建议先试用免费额度跑几个真实场景,体验之后再决定,又不花钱。