
写个复杂多文件项目改完还要自己逐行审查?Claude Opus 4.7 可能就是被寄望来解决这个问题的。SWE-bench Pro 拿了 64.3% 的分数,视觉识别从 54% 飙到 98% 接近完美,100 万 token 上下文确实能吞下整个代码库。但新 tokenizer 让成本悄悄涨了三四成,自适应推理也让不少老用户骂它变懒了。
简单说说
Claude Opus 4.7 是 Anthropic 在 今年 4 月 发布的旗舰模型,距离上一代 Opus 4.6 只隔了两个月。它的定位很明确,软件工程领域的顶配 AI 助手,专为复杂编程、深度研究和自主 Agent 工作流而生。跟 GPT 那种全能型选手不同,Opus 4.7 选择在编程和知识工作这两条线上做到极致。
换句话说,Anthropic 不想让它当”什么都会一点的通才”,而是把它训练成了”某个领域比你团队里最资深的人还靠谱”的专才。这种定位在业界的反馈也很清晰,Hex、CodeRabbit 等平台都给出了极高的评价。
官网:https://claude.ai | 项目地址:https://docs.anthropic.com
到底强在哪
搞清楚定位之后,来看看它到底有哪些拿得出手的本事。
-
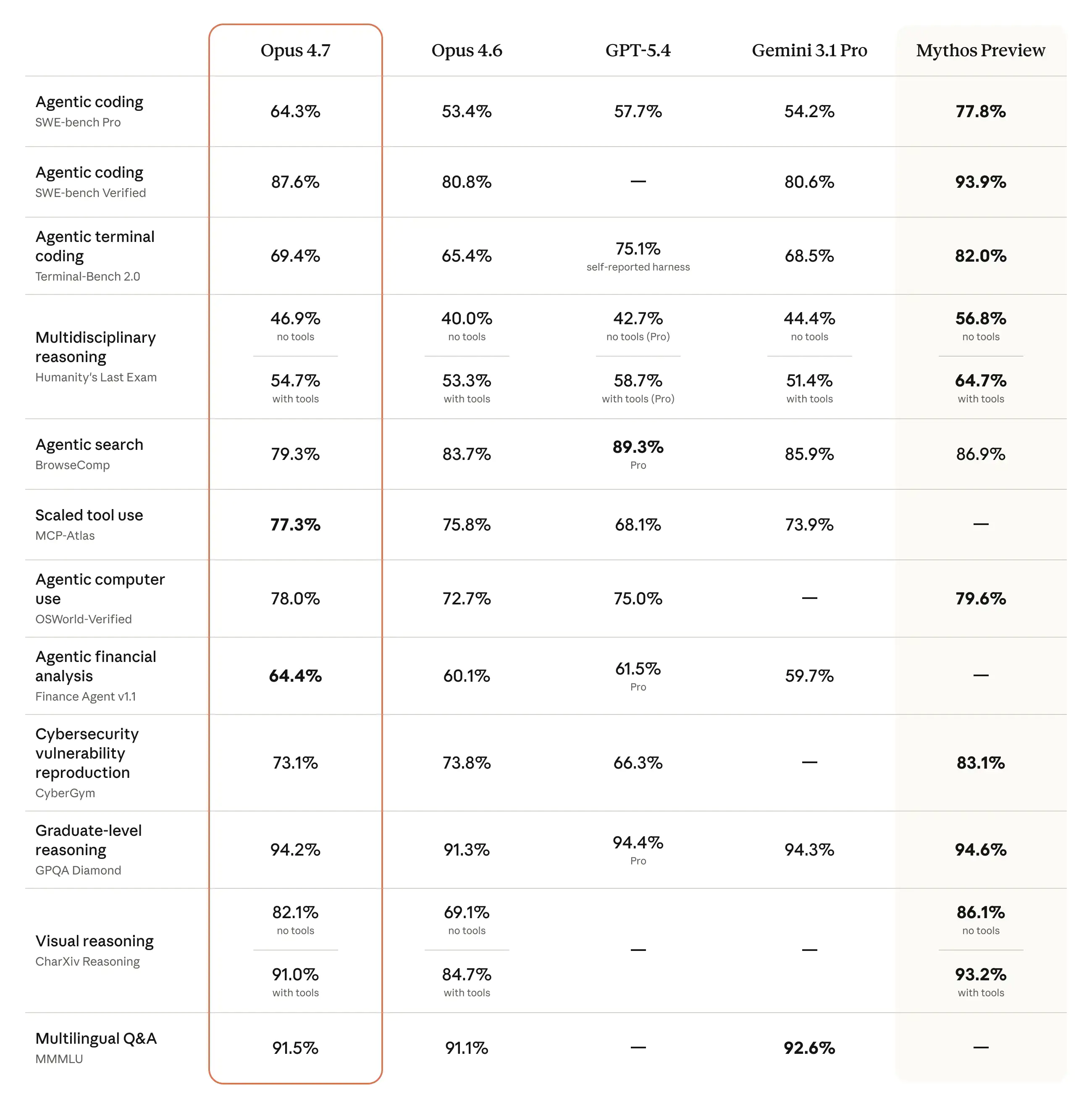
100 万 token 上下文窗口:从上代的 20 万直接拉到 100 万。一个完整的中等规模代码库可以一次性丢进去,不用分片,不用手动拆文件。这对于大型重构和代码审计来说,体验提升是质变级的。 -
xhigh 推理深度:在 high 和 max 之间加了一档。默认情况下 Claude Code 就用的这一档,在复杂编码任务上能接近 75% 的效果,同时比 max 省不少 token。想要更细粒度的性价比控制,这是目前最实用的选项。 -
视觉能力 3 倍提升:最大支持 2576 像素长边的图像,约 3.75MP。官方数据显示视觉准确率从 Opus 4.6 的 54.5% 直接跳到 98.5%。读架构图、扫合同、看财务报表截图,都比以前靠谱得多。 -
隐式需求推理:这是 Opus 4.7 的一个新能力,它在多步任务中能自己推断出需要调用什么工具、做什么操作,不需要你每步都写清楚。Anthropic 内部测试显示,工具调用错误降低了三分之一,复杂工作流完成的效率提升了 14%。 -
Task Budgets 和 ultrareview:Task Budgets 允许你给 Agent 循环设一个 token 硬上限,到了就自动优雅收尾。ultrareview 则是 Claude Code 里的多 Agent 代码审查机制,在 CodeRabbit 的评测中召回率提升了超过 10%。
怎么用
功能说了一堆,真正用起来是什么感觉呢?
如果你走 API 路线,模型 ID 是 claude-opus-4-7-20260416。官方定价跟 Opus 4.6 保持一致,输入每百万 token 五美元,输出二十五美元。但有个坑:新 tokenizer 会把同样一段文本编码成最高多 35% 的 token。换句话说,名义单价没涨,但你实际要付的钱可能多了不少。
Claude Code 用户感受会更直接。默认推理深度就是 xhigh,这意味着大部分任务你不需要手动调参就能获得不错的编码表现。ultrareview 功能内置在多 Agent 协作流程里,跑一次大型代码审查,Agent 们会分工检查不同模块,最后汇总。整体感觉是,对于重编码任务确实强,但普通的日常对话反而有点慢了,毕竟它的设计就不是为聊天优化的。
进阶玩法
很多人不知道 Opus 4.7 还有这些进阶用法:
-
Sonnet-Opus 顾问策略:Anthropic 官方推荐的省钱方案。主干任务用 Sonnet 4.6 执行,只在遇到难题时切到 Opus 4.7 做咨询。这套打法在自测中让单次 Agent 任务成本下降了 11.9%。 -
Task Budgets 防跑偏:如果你的 Agent 循环经常跑飞或者无限循环,给它设一个 task budget 硬上限。模型会看到 token 倒计时并在快耗尽前完成收尾。对于生产环境中跑长时间任务,这个功能是刚需。 -
Prompt Caching 大法:如果你的使用场景有大量重复的上下文(比如项目规范和几十个文件一起传),批量 API 加 Prompt Caching 能省掉九成的重复 token 费用。配合新 tokenizer 的副作用一起使用,实际成本能控制得还不错。 -
先用 count_tokens探路:迁移到 4.7 之前,一定要先对现有 prompt 跑一遍/v1/messages/count_tokens。如果新 tokenizer 把你的 prompt 撑得太离谱,可以考虑精简上下文或拆分任务。
竞品对比
2026 年四月的 AI 模型大战堪称白热化,Opus 4.7、GPT-5.5、Gemini 3.1 Pro 三款旗舰几乎同时登场。来直接看数据:
| 维度 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 58.6% | 54.2% |
| GPQA Diamond | 94.2% | 94.4% | 94.3% |
| 上下文窗口 | 100 万 | 12.8 万 | 20 万 |
| 视觉分辨率 | 2576px | 2048px | 未公布 |
| Terminal-Bench 2.0 | 69.4% | 82.7% | — |
| 输入/输出定价 | $5/$25 | $5/$30 | — |
核心差异很明确。Opus 4.7 在真实 GitHub 问题修复(SWE-bench Pro)和视觉精度上碾压对手,上下文窗口更是独一档。但在终端自动化操作和数学推理上,GPT-5.5 强了一大截。Gemini 3.1 Pro 在这场对决中更偏向理论推理,实战编程和工具调用还不算主力。
用户反馈
关于 Opus 4.7 的讨论,正反两边的声音都很大。先说好评。Hex 的测试团队说它”在异步工作流、CI/CD 和长时间自动化任务上表现极其亮眼,比 Opus 4.6 强了一个档次”。CodeRabbit 的评价更直接,“设计选择已经是可发布级别”。金融分析师群体也很满意,FinanceAgent 基准拿到了 64.4%。
但差评的声量同样不小。Reddit 上 ClaudeAI 社区很快炸了锅,核心抱怨是”Opus 4.7 变懒了”。很多用户反映它在面对需要深入思考的问题时草草给出答案,而不是像 4.6 那样认真挖掘细节。有人甚至发现长上下文准确率从 78.3% 暴跌到了 32.2%。更严重的是,有用户报告模型会编造信息,虚构搜索行为、捏造人名,这在付费工具中是极其严重的问题。
多维评分
反馈看完了,下面从几个维度给它打个分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | 100 万上下文 + xhigh 推理,业内独一份 |
| 易用性 | ⭐⭐⭐⭐☆ | API 和 Claude Code 接入简单,但学习成本不高 |
| 性价比 | ⭐⭐⭐☆☆ | 单价没涨但 token 膨胀让实际成本更高 |
| 创新性 | ⭐⭐⭐⭐⭐ | 隐式推理和 Task Budgets 是实用创新 |
| 稳定性 | ⭐⭐⭐☆☆ | 长上下文准确率断崖下降,编造问题严重 |
| 推荐度 | ⭐⭐⭐⭐☆ | 编程场景无可替代,但日常使用不如 Sonnet |
| 综合评分:7.5 / 10 |
优点和槽点
优势
-
编程能力封顶:SWE-bench Pro 64.3% 和 CursorBench 70%,当前公开模型最强 -
视觉能力跃升:从 54.5% 到 98.5%,读图场景彻底翻新 -
超大上下文窗口:100 万 token 一次处理全代码库,重构和审计体验质变 -
隐式需求推理:减少工具调用错误,复杂工作流效率提升 14%
不足
-
新 tokenizer 推高实际成本:同样文本消耗多 35% 的 token,账单悄悄涨了 -
自适应推理让模型变懒:不在所有场景都深入思考,用户失去控制权 -
长上下文准确率断崖下降:从 78.3% 掉到 32.2%,大文档场景需谨慎 -
编造行为和安全性问题:有用户报告虚构搜索、捏造信息等严重问题
适合谁用
了解了优缺点之后,来看看它到底适合哪些人。
-
专业软件工程师:复杂多文件重构、大型代码审查、自动化 CI/CD 流水线。你遇到的最棘手的那些编程问题,它能站出来独当一面,尤其是和 Claude Code 的 Agent 模式配合使用时效果更明显。但日常的简单 CRUD 用 Sonnet 就够了,没必要杀鸡用牛刀。 -
金融分析师和知识工作者:财务报表建模、数据分析、文档深度解析。FinanceAgent 的出色表现说明它在这个细分领域确实有独到之处,但在大量长文档处理时建议分片操作,避免触及长上下文准确率的瓶颈。 -
构建 Agent 应用的开发者:需要长时间自主运行的系统工程任务,Task Budgets 和隐式推理能力让它在 Agent 场景中表现出色。如果团队正在搭建 AI 驱动的工具链,Opus 4.7 是当前的上限选择。 -
普通用户和轻量使用者建议观望:日常聊天、写邮件、摘要是它的弱项。更便宜、更快的 Sonnet 4.6 在这些任务上反而体验更好,而且不用承担新 tokenizer 带来的额外成本。
多少钱
功能心动了?先看看钱包答不答应。
| 方案 | 输入价格 | 输出价格 | 说明 |
|---|---|---|---|
| 标准 API | $5/百万 token | $25/百万 token | 按实际 token 计费 |
| Prompt Caching | $0.5/百万 token | — | 重复上下文省 90% |
| Batch API | $2.5/百万 token | 50% 折扣 | 异步非实时任务 |
| Claude Pro 订阅 | $20/月 | 含 Opus 4.7 额度 | 需搭配 Max 套餐扩量 |
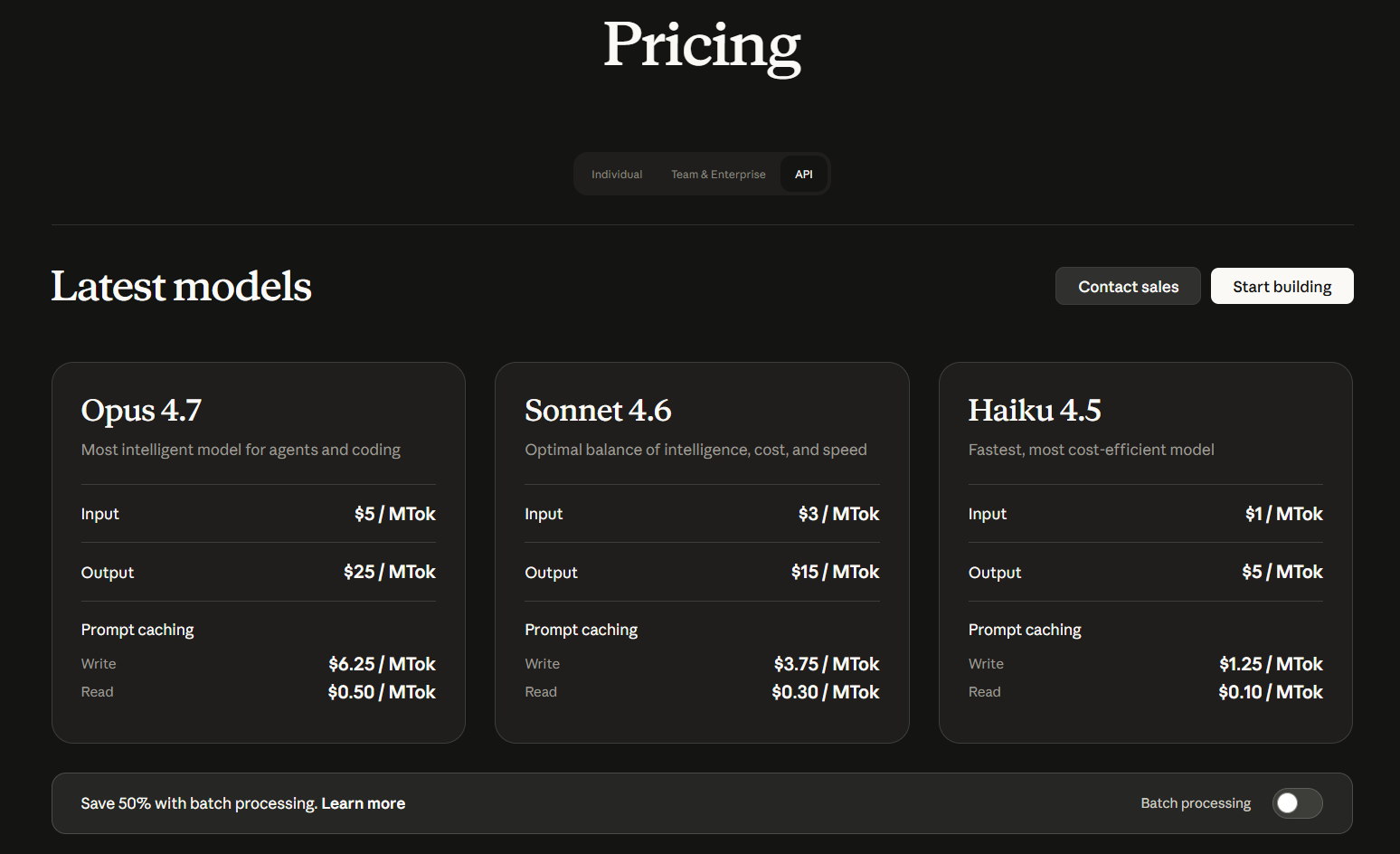
需要注意几个隐形成本。新 tokenizer 会让同样输入多消耗 0% 到 35% 的 token,迁移前务必用 count_tokens 接口测一遍。另外 xhigh 和 max 推理深度消耗的 token 差距也不小,xhigh 大概接近 75% 的效果但 token 消耗少很多。批量 API 加 Prompt Caching 的组合拳是控制成本的关键,重度用户一定要用起来。
常见问题
Q1:Opus 4.7 和 Opus 4.6 相比,升级了什么?
A1:编程能力大幅提升,但成本和稳定性也变化了。 SWE-bench Pro 从 53.4% 涨到 64.3%,视觉准确率从 54.5% 跳到 98.5%,上下文窗口扩张到 100 万 token。但新 tokenizer 让同样输入多了 35% 的 token 消耗,长上下文准确率反而从 78.3% 降到了 32.2%。
Q2:Opus 4.7 和 GPT-5.5 哪个更强?
A2:看任务类型,没有绝对的赢家。 编程修复(SWE-bench Pro)Opus 4.7 领先 5.7 个百分点,但终端自动化(Terminal-Bench 2.0)GPT-5.5 高出 13.3 个百分点。推理、数学、长上下文方面 GPT-5.5 也占据优势。选它俩取决于你的核心任务场景。
Q3:用 Opus 4.7 是不是很贵?
A3:名义上单价没涨,但实际支出可能高了 35%。 标准定价输入 $5/百万 token,输出 $25/百万 token,跟 Opus 4.6 一致。问题出在新 tokenizer 会把同样文本编成更多 token。用 Prompt Caching 和 Batch API 可以大幅缓解成本压力。
Q4:免费用户能用 Opus 4.7 吗?
A4:不能。 免费版 Claude 只提供 Sonnet 4.6。Opus 4.7 需要付费订阅(Pro/Max/Team/Enterprise)或者用 API 按量付费。对于只是想尝鲜的个人用户,建议先开 Pro 体验再决定是否需要升级到 Max。
Q5:听说 Opus 4.7 会编造信息,这是真的吗?
A5:确实有用户报告过这类问题。 包括虚构搜索行为和捏造人名等案例。这可能是自适应推理机制和过度对齐策略的副作用。Anthropic 尚未正式承认,但如果你在严肃生产环境中使用,建议对关键输出人工复核。
Q6:Opus 4.7 支持中文吗?
A6:支持,中文能力属于顶级水平。 代码注释、技术文档甚至创意写作都能胜任。不过如果只是日常的中文对话或文案生成,Sonnet 4.6 体验更好、成本更低,没必要上 Opus 4.7。
Q7:Claude Mythos 和 Opus 4.7 是什么关系?
A7:Mythos 是 Anthropic 内部最强的模型,但不公开。 Mythos 在 CyberGym 得了 83.1%,而 Opus 4.7 只有 73.1%。Anthropic 刻意弱化了 Opus 4.7 的网络攻防能力。Opus 4.7 是你能用到的 Anthropic 最强的公开模型。
Q8:Opus 4.7 适合做 Agent 吗?
A8:非常适合,它是当前自主 Agent 的最佳选择之一。 隐式需求推理和 Task Budgets 是专门为 Agent 场景设计的。MCP Atlas 基准得分 79.1%,在 loop resistance 和优雅错误恢复上表现突出。但 Agent 场景 token 消耗大,记得配置 task budget 控制成本。
Q9:我应该从 Opus 4.6 迁移到 4.7 吗?
A9:看你用什么场景。 如果主力是复杂编程工作流、大型代码库、视觉分析任务,升级收益很大。但如果你的任务是网络搜索、长文档总结或其他对深推理要求不高的场景,建议先在 4.6 上跑跑对比测试再决定。
Q10:Opus 4.7 可以做图像生成吗?
A10:不可以。 Opus 4.7 是纯文本和视觉理解模型,不具备图像生成能力。它擅长的是理解图像内容(读图表、分析 UI 截图、解构架构图),而不是创造图像。需要图像生成的话请选择其他专门工具。
所以到底值不值得
Claude Opus 4.7 是一个让人又爱又恨的模型。编程和视觉方面的提升是实打实的,100 万上下文窗口、顶级的 SWE-bench 分数、近乎完美的视觉识别,这些在 2026 年的模型赛场上都是独一档的存在。对于做复杂编程、金融分析、构建 Agent 工具的团队来说,它确实是最强的那把刀。
但同时它也是个带着代价的升级。新 tokenizer 无声无息地推高了成本,自适应推理剥夺了用户对思考深度的控制权,编造问题和长上下文准确率下降更是不可忽视的硬伤。如果你的工作流对稳定性和一致性要求极高,建议先在非关键任务上充分测试,确认它不会在你最需要它的时候偷懒。
建议先跑一个试用周,把真实场景的数据和成本测清楚了再决定。毕竟工具好不好,最终看的是它在你的工作流里到底能不能站住脚。