

传统导航系统主要依赖”方向-距离-动作”范式生成抽象导航指令(如”向西行驶200米后左转”)。然而,随着城市路网日趋复杂,这种动作指令式导航范式在骑行与步行场景中暴露出以下瓶颈:
-
空间定位模糊:在隧道、高架桥下、密集楼宇等GPS信号遮蔽或多径效应严重的环境中,卫星定位精度显著下降,易导致路口混淆与错误引导。
-
距离感知偏差:基于距离量化的播报指令(如”100米后左转”)依赖用户对物理距离的主观估算,而人类对距离的感知受速度、环境参照物等因素影响,常产生显著误差。
-
认知负荷过高:用户需在手机屏幕的二维地图与现实世界的三维视觉场景之间反复进行视线切换与空间方位对齐,这一过程消耗大量认知资源,尤其在复杂路口或陌生环境中极易造成决策延迟与导航失误。
上述问题的本质在于:传统导航的指令空间与用户的感知空间存在鸿沟——系统输出的是抽象的空间-动作指令,而用户认知世界的方式是基于视觉场景中的显著性参照物(即”地标”)。认知心理学研究表明,地标是人类空间认知与路径记忆的核心锚点[1],以地标为中介的路径描述更符合人类自然的寻路认知模式[2,3]。
基于此,本文提出面向骑步行导航”地标视觉引导”新范式(如图1所示):借助海量街景图和多模态大模型强大的视觉理解能力,构建基于显著性地标的离线视觉参考系及实时引导系统,将导航指令与用户的真实视野深度绑定,变”执行抽象动作”为”跟随视觉地标”,旨在打造面向骑步行场景沉浸式、低认知成本的高效导航体验。
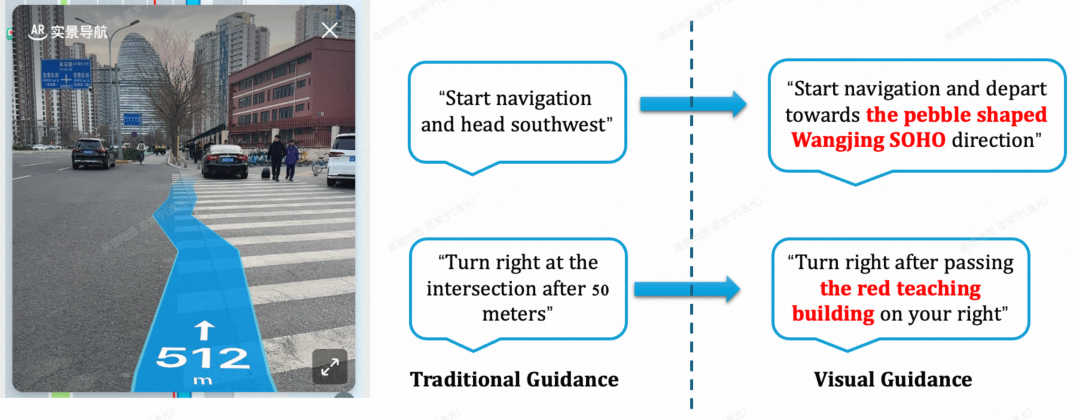
图1 视觉引导范式转变
本文提出的地标视觉引导系统由四个核心环节组成(如图2所示),形成从地标发现到用户导航体验的完整闭环:
-
地标发现与显著性评价(Landmark Discovery):面向骑步行场景定义四类视觉地标——挂牌POI、地标建筑、交通设施与自然地物,并建立融合可见性、视觉显著性与知名度的三维评价体系,为候选地标的优先级排序提供量化依据。
-
离线视觉参考系构建(Offline Reference Building):基于海量街景图像,通过三条并行技术路线——外观描述生成、视觉位置识别与自然地物挖掘,构建统一的地标参考数据库,回答”地标长什么样”与”地标在哪可见”两个关键问题。
-
智能引导指令生成(Smart Instruction Generation):以导航路径决策点为驱动,将街景图像、空间关系视觉图与视觉参考点信息组装为多模态Prompt,输入经LoRA监督微调与GRPO强化学习优化的MLLM,生成基于地标的自然语言引导指令。
-
用户导航体验(User Navigation Experience):系统实时输出地标视觉引导指令(如”看到前方左侧红色招牌’星巴克’后右转”),用户无需在地图与现实之间反复切换视线,即可依据视野中的显著地标完成导航决策。
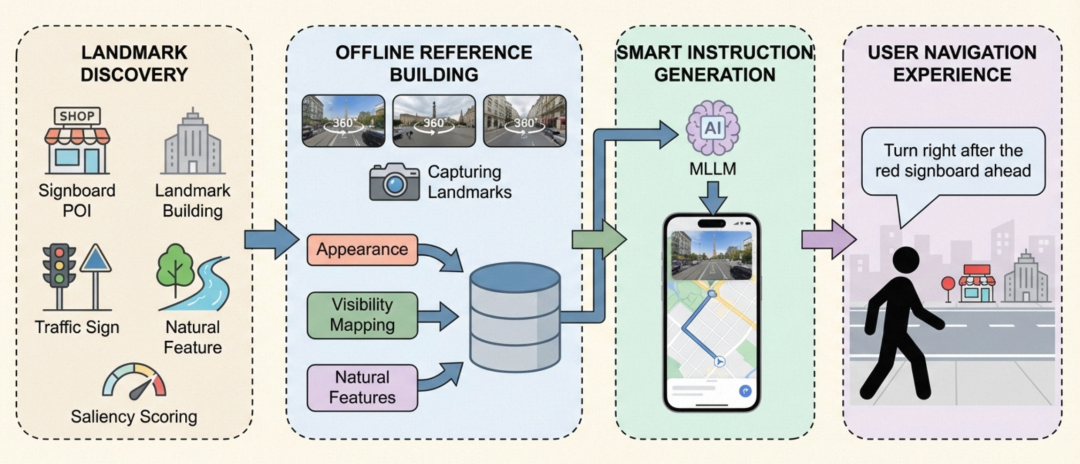
图2 地标视觉引导系统整体框架
围绕上述四大环节,本文后续章节按”定义—构建—生成”的递进逻辑展开:第3章建立面向骑步行场景的地标定义与显著性评价体系,明确”什么样的物体可作地标、何种地标更适合用于引导”;第4章在此基础上依托海量街景图、POI数据与自然地物数据底座,构建可直接用于引导播报的离线视觉参考系;第5章阐述以路径决策点为驱动,融合离线参考系所提供的周边视觉环境信息,形成面向用户的实时地标引导指令生成能力。
3.1 骑步行场景特征分析
骑步行导航场景与驾车导航场景存在显著差异,这些差异直接影响地标的选取策略与引导方式设计:
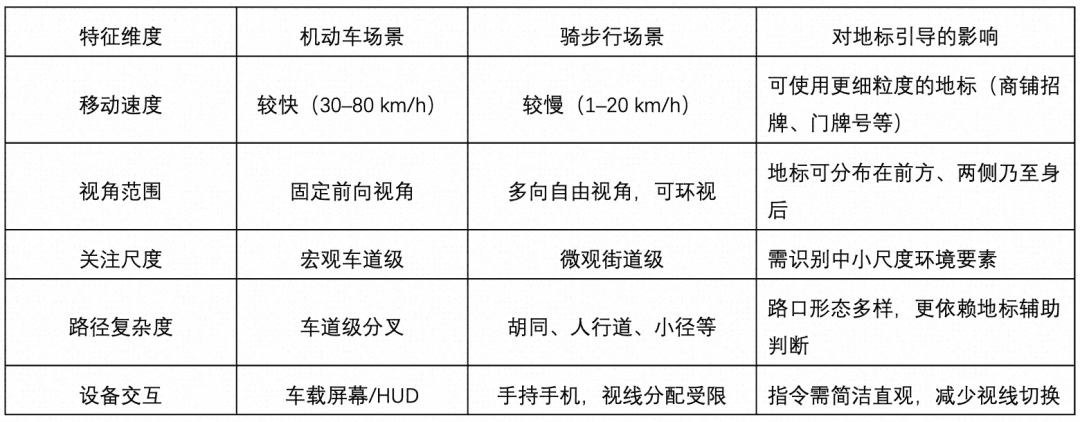
上述特征表明,骑步行场景对地标的类型多样性、检测粒度与方位覆盖范围提出了更高要求,也为地标视觉引导提供了更大的发挥空间。
3.2 骑步行地标分类体系
基于场景特征分析,构建面向骑步行导航的四类场景地标分类体系:
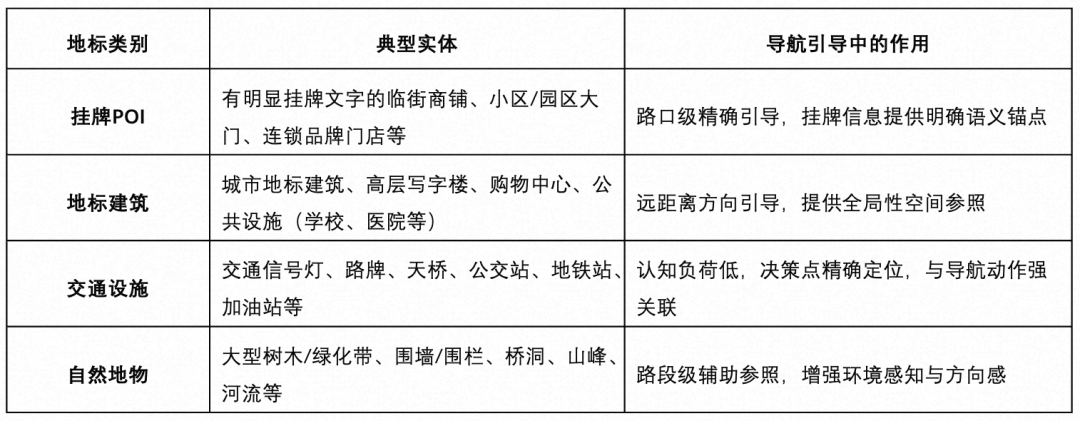
该分类体系从”人工设施→自然环境”递进,覆盖了骑步行场景中从精确路口引导到宏观方向参照的完整地标谱系。各类别地标在引导中承担不同层次的角色,可根据决策点类型与用户场景灵活组合。
3.3 地标显著性评价指标
在实际导航路径中,每个决策点周围往往存在大量候选地标,然而这些地标在视觉显著性、用户注意力捕获能力以及认知理解成本上存在显著差异。为从众多候选中筛选出视觉上最为突出、语义上易于理解的最佳引导地标,需要建立一套科学的评价体系对候选地标进行量化评分与优先级排序。本文提出从”可见性””显著性”与”知名度”三个维度综合评估地标作为视觉引导节点的有效性:
-
可见性: 地标能否被用户在引导时机实际看到
-
视角可见性:地标在用户正常行进方向的视角范围内是否可见
-
可见距离:地标从多远处开始可被识别,距离越远则提前量越充裕
-
遮挡抗性:地标是否容易被行人、车辆、绿化等动态物体遮挡
-
-
视觉显著性: 地标能否在环境中被快速注意到并正确识别
-
视觉独特性:地标与周围环境的视觉对比度(颜色、形状、尺度)
-
语义明确性:地标是否具有明确的名称或文字标识(如招牌、路牌),便于在指令中精确描述
-
时空稳定性:地标是否在不同时间、季节、天气条件下保持稳定存在
-
-
知名度: 地标是否为用户所熟知,能否以低认知负荷被理解
-
公众认知度:地标是否为大多数人所知晓(如连锁品牌、知名地标),知名度越高则用户理解成本越低
-
语义直觉性:地标名称或功能是否一目了然(如”邮局””加油站”比”XX大厦B座”更易理解)
-
文化普适性:地标能否被不同文化背景的用户(包括外地游客、外籍用户)普遍识别
-
其中视觉可见性和显著性基于MLLM视觉理解生成,知名度结合点击热度、联网搜索评分等生成。三维指标通过综合加权为地标引导适宜性评分,用于第5章引导指令生成时的地标优先级排序与筛选。该评价体系的设计参考了认知地理学关于地标显著性(landmark salience)的相关研究[4,5],综合考虑了视觉、语义与结构三类显著性。
本章针对3.2中定义的四大类视觉地标(挂牌POI、地标建筑、交通设施、自然地物)进行挖掘,为每个地标生成引导友好的具象化文本描述。POI类地标基于挂接的图像数据底座,结合MLLM进行锚点图像筛选、外观描述生成和视觉位置挖掘等分别进行外观描述生成、视觉位置识别等环节完成;非POI表达的自然地物直接基于街景图端到端识别生成,”所见即所得”;基于以上流程构建一套可直接用于引导播报的离线地标参考体系,为实时引导指令生成提供数据支撑。
4.1 外观描述生成
导航引导指令需要以用户可感知的视觉特征描述地标(如颜色、形状、挂牌文字等),而非POI名称等抽象文本。本节设计两阶段流水线生成引导友好的具象化描述,示例如图3所示:
-
锚点图像筛选: 基于多模态rerank模型对地标相册中的图像进行质量排序,优先挑选白天拍摄、轮廓完整、拍摄视角良好的图像作为描述生成的锚点图像
-
分类描述生成: 基于MLLM[6,7]对筛选出的锚点图像进行描述生成,根据地标类别采用差异化的描述策略:
-
小型视觉目标(挂牌POI、园区大门、交通设施等):侧重挂牌颜色、文字内容、门店类型等要素,例如:“绿色招牌的链家地产门店”
-
大型视觉目标(地标建筑、商务写字楼等):侧重建筑整体颜色、外观形态、墙体文字等特征,例如:“黄色竖条纹状的写字楼”
-

图3 外观描述示例
4.2 视觉位置识别
外观描述解决了”地标长什么样”的问题,本节进一步解决”地标在哪些位置可见”的问题——即确定地标在周边路网中的可视范围,为引导指令的触发时机与方位描述提供依据。整体流程如图4所示,分为三个步骤:
-
周边路网召回: 基于S2空间索引[8]等方法,对地标可视范围内的道路进行空间召回,确定候选观测路段
-
街景图采样与预处理: 对候选路段上采集的街景图进行去噪、采样、朝向角筛选等预处理,保留朝向地标方向的有效视角图像,该流程可视为一种面向广域街景检索的视觉位置识别(Visual Place Recognition)任务[9]
-
多模态融合推理: 融合街景图、锚点图以及BEV视角[10]下的拍摄视角与位置关系,通过多模态融合推理判断视觉目标的可视路段集合
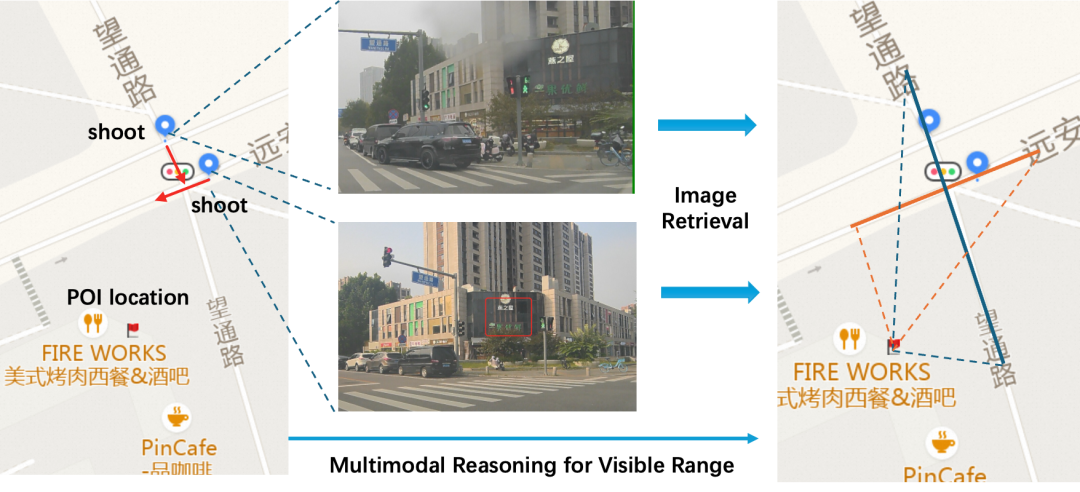
图4 视觉位置识别过程
4.3 基于街景图的自然地物识别
4.1与4.2讨论了以POI数据底座为基础的挂牌商铺、地标建筑、交通设施等视觉地标的构建方法。然而,现实环境中还存在大量缺乏POI结构化表达的自然地物(如山峰、河流、围墙、围栏、桥洞、大型路牌等),这些地物在骑步行场景中同样具有高视觉显著性,可作为有效的导航参照物。本节采用”所见即所得”的端到端思路,基于MLLM直接从街景图序列中识别与挖掘非POI自然地物。整体算法流程如图5所示:
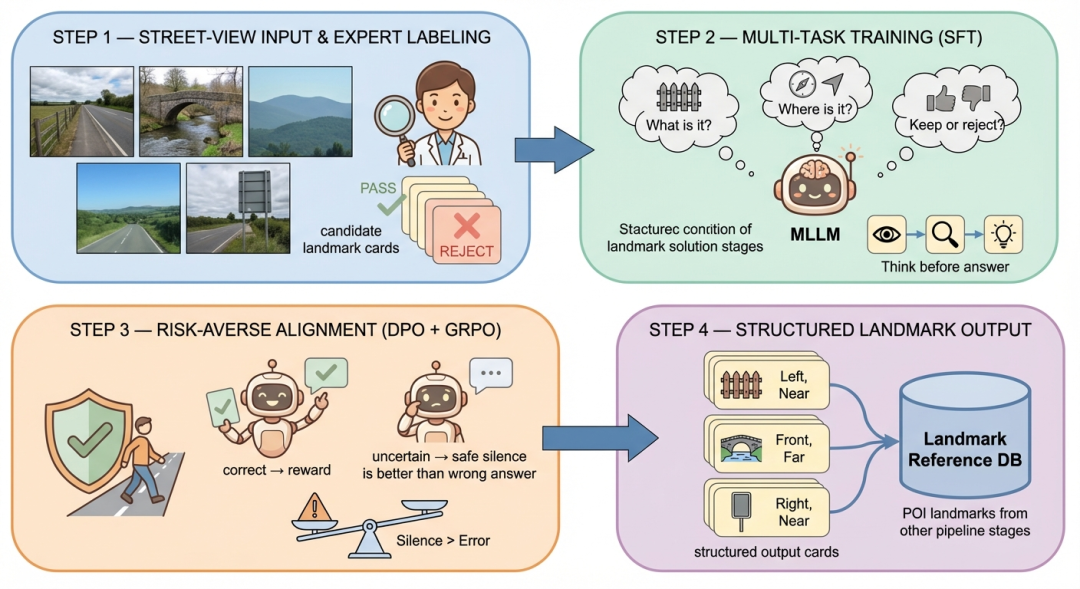
图5 基于街景图的自然地物识别流程
-
任务定义与标注协议:定义无坐标框的结构化预测任务——给定连续多帧街景图序列,模型直接输出每个地物的外观描述、类别(围墙/围栏、桥洞、大型路牌等)、相对方位(左/右/前方)、距离(近/远)及可见帧范围。标注采用迭代式人机协同流程:先由零样本MLLM生成候选提案,再由专家对每个候选进行通过或拒绝标注(拒绝标注需注明具体原因,如”显著性不足””外观描述不清”等),并补充遗漏的显著地物,以最大化有限标注的数据效用
-
三阶段渐进式强化训练:
-
第一阶段——多任务SFT:将端到端识别任务分解为地物识别、拒绝判别、属性预测等多个子任务联合训练,并引入伪思维链(pseudo Chain-of-Thought)[11]迫使模型在输出前完成”感知→验证→决策”的完整推理过程,同时通过时序裁剪增强(Multi-crop Augmentation)生成包含零地物样本的训练数据,教会模型在无合适地物时主动沉默
-
第二阶段——DPO对比偏好优化[12]:构造多维度对比偏好对(如方位翻转、描述篡改、遗漏拒绝等),显式强化模型对通过与拒绝地物的判别边界及属性精度
-
第三阶段——GRPO强化学习[13]:设计导航感知的风险敏感奖励函数(NARF),将模型输出划分为”全对””沉默””含误”三个质量层级,通过非对称奖惩确保”沉默优于犯错”——在模棱两可的场景中模型会自发选择不输出,而非冒险给出可能误导用户的错误预测
-
-
评估指标定义
定义以下五项评估指标刻画模型在感知覆盖、判别精度与结构化表达上的综合能力:
-
Recall & Prec.:召回率 & 准确率
-
JSON:表示模型输出结构化格式的正确率
-
Dir.:方向精度,衡量模型对地物相对方位准确性
-
Dist.:距离精度,衡量模型对地物远近判断的准确性
-
-
实验分析
基于以上三阶段模型训练与基线模型指标对标如下表所示:
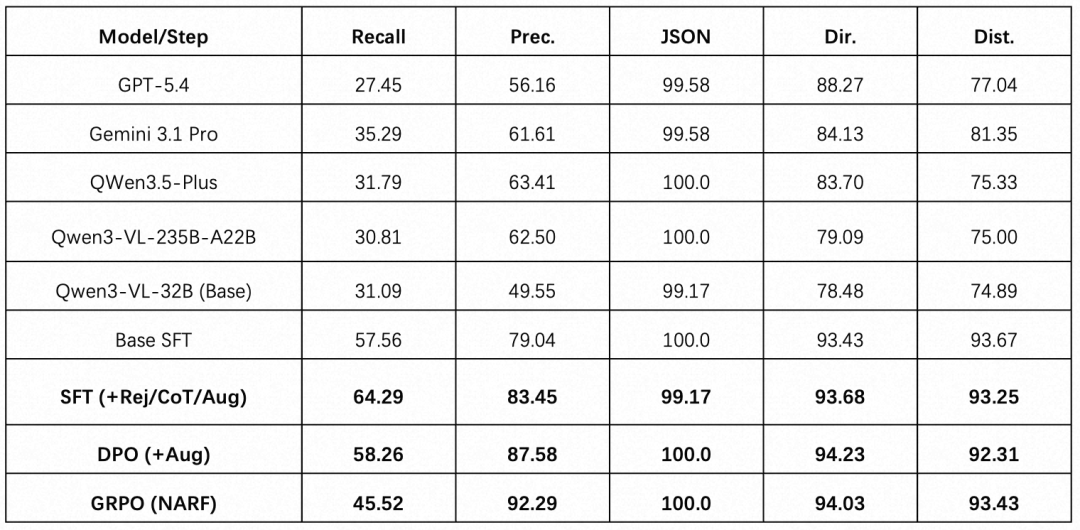
上表从五个维度展示了各模型的量化表现,可见通用MLLM(GPT-5、Gemini3.1-pro、Qwen3.5-plus)在各维度表现均比较低,难以满足导航场景对结构化输出可靠性的要求。一阶段经多任务SFT引入SFT (+Rej/CoT/Aug)后,准召率和方向距离精度均有较大幅度提升,领域知识注入效果显著;二阶段DPO (+Aug) 召回略降,其他指标均进一步提升,呈现典型的精度–召回权衡;三阶段GRPO(NARF)在精确率(92%)、JSON正确率(100%)、方向精度(94%)与距离精度(93%)上均达最优,受”沉默优于犯错”机制影响,召回率降至45.5%,在抑制误报与保持检出间取得了最佳平衡。
综上所述,经过”SFT→DPO→GRPO”三阶段策略使Qwen3-VL-32B模型全面超越商用闭源大模型,为构建高可靠性的离线地标视觉参考系提供了有力支撑。
5.1 总体思路
第4章构建的离线地标视觉参考系提供了”哪些地标可用、在哪可见”的结构化知识,但尚未解决”如何用地标引导用户”的最后一公里问题。本章提出基于多模态大语言模型的导航指令生成(Navigation Instruction Generation, NIG)方案:以导航路径上的决策点(路口、分叉等)为驱动,将该点位的街景图像、空间关系视觉图与视觉参考点标注信息组装为多模态Prompt,输入经领域微调的MLLM生成基于地标的自然语言引导指令(如”看到前方左侧红色招牌’星巴克’后右转”)。
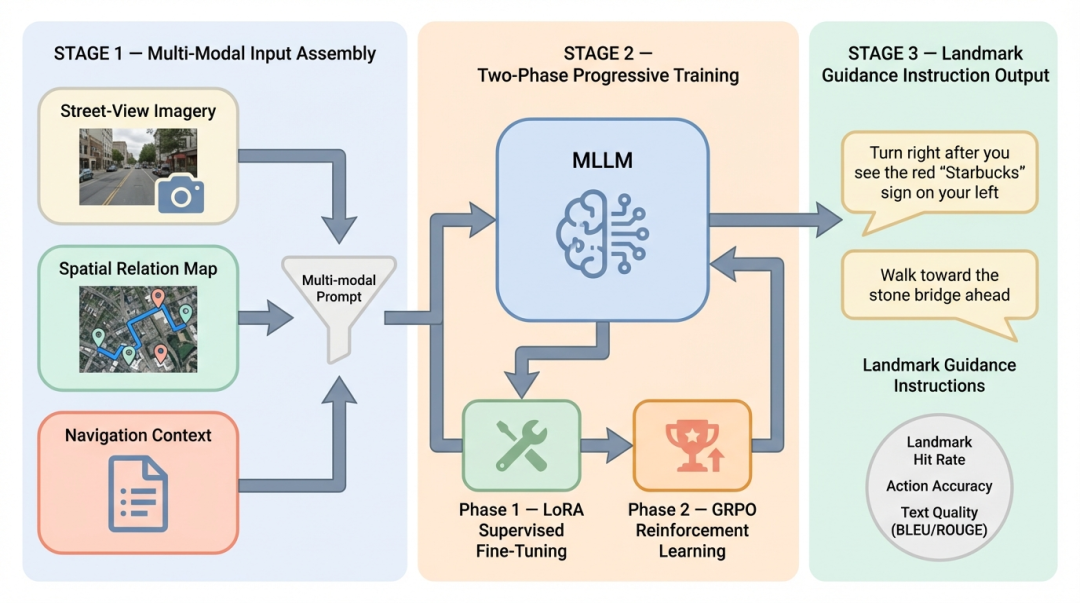
图6 基于MLLM的地标视觉引导指令生成流程
整体流程如图6所示,分为三个阶段:
-
多模态输入组装 —— 将街景图像、卫星地图、视觉参考点信息与导航上下文融合为结构化多模态Prompt
-
模型微调与强化训练 —— 构建导航场景数据集,通过监督微调与强化学习训练MLLM生成地标引导指令
-
指令生成效果评价 —— 从地标命中率、动作准确率与文本生成质量等维度构建专项评价体系
5.2 多模态输入组装
本节解决”给模型看什么”的问题——如何将离散的视觉与空间信息组装为模型可理解的统一输入。
-
空间关系视觉图绘制: 在卫星地图上绘制用户BEV视角的导航规划路线,标注途经视觉参考点的位置与属性信息,并嵌入决策点处的街景图像,使模型获取用户在特定路线与位置上的全局空间上下文
-
导航上下文结构化描述: 将当前决策点的导航信息(待执行动作、剩余距离、下一决策点等)编码为结构化文本,作为Prompt的文本输入部分
-
Prompt模板设计: 借鉴大模型 in-context learning 范式[14],设计面向导航地标引导的系统Prompt模板,包含角色定义、输出格式约束(如指令长度限制、必须包含地标名称与方位词)以及骑行/步行场景的差异化提示策略
5.3 模型微调与强化训练
本节解决”如何让通用模型学会导航地标引导”的问题,采用”监督微调 + 强化学习”两阶段渐进式训练策略。
-
基座模型选型: 对比主流开源MLLM(如Qwen3-VL、InternVL3等)在街景场景理解、空间方位描述与导航指令生成等维度的基线能力,选取最优基座模型Qwen3-VL
-
训练数据构建: 基于导航路径决策点的空间关系视觉图,首先利用当前SOTA多模态模型(如Gemini 3 Pro等)生成初版引导描述;在此基础上开发专用标注系统进行人工校正与精标,获得高质量的监督训练样本,如图7所示。

图7 导航指令生成多模态训练样本示例
-
两阶段训练策略:
-
第一阶段——LoRA监督微调[15]:采用参数高效微调方法向模型注入导航地标引导的领域知识,设计多任务训练目标(地标描述 + 方位判断 + 指令生成),提升模型的空间语义理解能力
-
第二阶段——GRPO强化学习:设计针对性的奖励函数,对转向动作正确性、地标引用准确性等关键指标进行显式奖惩,采用GRPO策略进行强化学习训练,进一步提升动作准确率与地标命中率
-
5.4 指令生成效果评价
本节建立面向导航地标引导指令的专项评价体系,包括以下核心指标:
-
地标命中率(landmark_hit_rate):生成指令中提及的地标是否与场景中实际可见的视觉参考点一致
-
动作准确率(action_accuracy):指令中的转向动作(直行/左转/右转)与实际导航动作的吻合度
-
文本生成质量:采用BLEU[16]、ROUGE[17]、BERTScore[18]等指标衡量生成指令与人工参考指令的语义相似度
基于以上指标在测试集合上对比强化基线模型(Gemini-3-flash、qwen3.5-plus)和强化微调后的模型表现如图8所示:
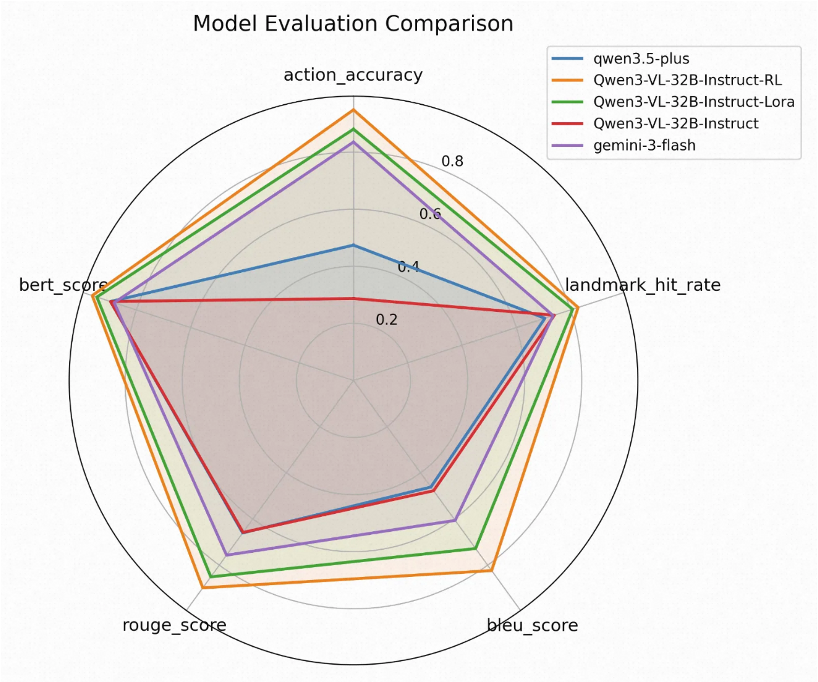
图8 导航指令生成模型与基线模型指标对比
可见,经过LoRA监督微调和GRPO强化学习之后的模型在各项指标均有提升,相比SOTA闭源模型(Gemini-3-Flash)各维度指标均提升超过10%。以上离线指标验证了模型在地标命中、动作判断与文本生成等维度的能力增益,但其能否真正改善用户的导航体验仍需在真实业务场景中加以检验。下一章通过线上A/B实验从用户行为视角进一步评估视觉引导的实际收益。
6.1 业务指标定义
为量化地标视觉引导对导航体验的实际提升效果,定义如下核心业务指标:
-
播报完成至稳定步行时长(起点找方向耗时): 从用户发起导航到进入稳态步行的时间中位数。该指标直接反映用户在起点处辨别方向的效率——时长越短,表明用户越快确认行进方向并迈出第一步,是衡量导航引导有效性的关键指标。
6.2 实验设计与指标评估
采用线上A/B实验验证视觉引导的效果增益,实验分组设计如下:
-
A组(对照组): 传统动作指令引导模式,全量用户
-
B组(实验组): 地标视觉引导模式,可进一步拆分为起点命中视觉播报与未命中视觉播报两个子群体(二者合计为全量)
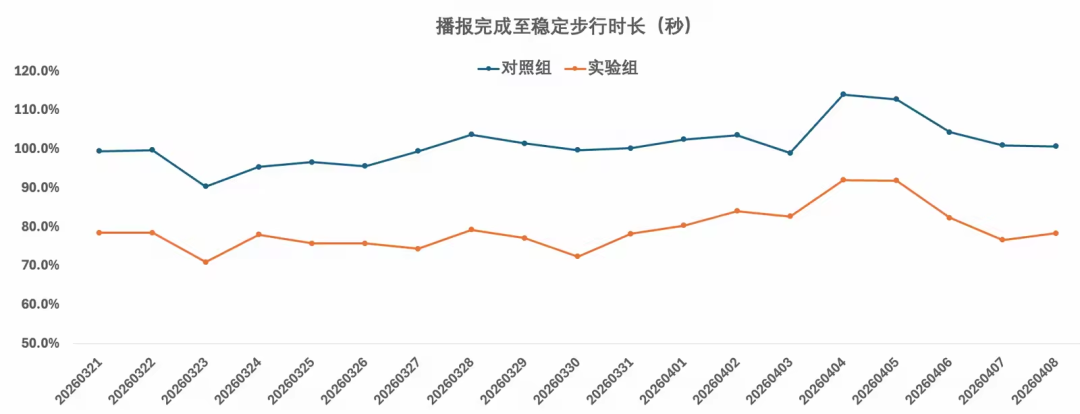
图9 业务指标评估
指标对比结果如图9所示。实验数据表明,命中视觉引导播报的用户起点找方向耗时中位相比传统引导模式基线减少20%以上(业务敏感数据, 已归一化)。这一结果验证了地标视觉引导”所见即所得”的引导方式在起点找方向场景中的显著效率增益。
6.3 实际应用案例
图10展示了地标视觉引导系统在实际导航场景中的应用案例,涵盖了挂牌POI、地标建筑、交通设施及自然地物等多类视觉地标的引导效果。
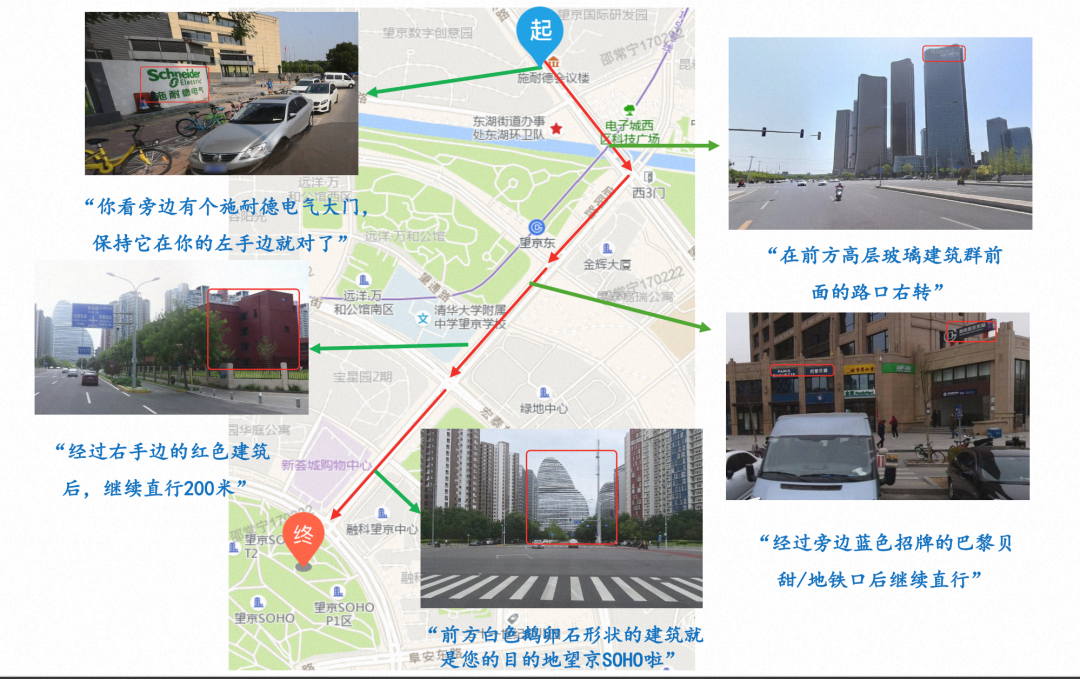
图10 实际应用案例展示
针对传统导航在骑步行场景中定位模糊、距离感知偏差、认知负荷过高等痛点,本文提出”地标视觉引导”新范式:定义四类视觉地标与三维显著性评价体系,通过外观描述生成、视觉位置识别与端到端自然地物识别三条技术路线构建离线地标参考系,并基于MLLM的LoRA微调与GRPO强化学习实现决策点级的地标引导指令生成,形成从地标发现到用户导航体验的完整闭环。
实验表明,地标视觉引导”所见即所得”的方式更符合人类空间认知与路径记忆的自然模式,相较于传统动作指令式导航,在用户起点找方向的效率上取得了明显提升,有效降低了视线切换频率与认知负荷。当前的工作只是起点,我们判断未来还有很多值得探索的方向:
智能播报时机与内容规划:当前播报时机仍沿用基于距离阈值的业务规则,未能充分考虑路线全局上下文与用户实时状态。未来可引入AI Agent架构,基于用户行进速度、路线复杂度与地标分布密度,动态规划全局播报策略,实现”何时说、说什么”的自适应决策。
多模态实时感知融合:现有系统主要依赖离线街景图构建参考系,尚未充分利用用户端实时视觉信号。未来可探索将手机摄像头实时画面与离线地标参考进行在线匹配,结合AR增强现实导航技术[19],实现地标的实时视觉叠加与动态引导。
参考文献
[1] Lynch K. The Image of the City[M]. Cambridge, MA: MIT Press, 1960.
[2] Denis M, Pazzaglia F, Cornoldi C, et al. Spatial Discourse and Navigation: An Analysis of Route Directions in the City of Venice[J]. Applied Cognitive Psychology, 1999, 13(2): 145-174.
[3] Raubal M, Winter S. Enriching Wayfinding Instructions with Local Landmarks[C]//International Conference on Geographic Information Science. Springer, 2002: 243-259.
[4] Caduff D, Timpf S. On the Assessment of Landmark Salience for Human Navigation[J]. Cognitive Processing, 2008, 9(4): 249-267.
[5] Klippel A, Winter S. Structural Salience of Landmarks for Route Directions[C]//International Conference on Spatial Information Theory (COSIT). Springer, 2005: 347-362.
[6] Bai J, Bai S, Yang S, et al. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond[EB/OL]. arXiv:2308.12966, 2023[2024-09-01]. https://arxiv.org/abs/2308.12966.
[7] Chen Z, Wu J, Wang W, et al. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024: 24185-24198.
[8] Google Inc. S2 Geometry Library[EB/OL]. (2023)[2024-09-01]. https://s2geometry.io/.
[9] Garg S, Fischer T, Milford M. Where Is Your Place, Visual Place Recognition?[C]//Proceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI), 2021: 4416-4425.
[10] Li Z, Wang W, Li H, et al. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers[C]//European Conference on Computer Vision (ECCV). Springer, 2022: 1-18.
[11] Wei J, Wang X, Schuurmans D, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models[C]//Advances in Neural Information Processing Systems (NeurIPS), 2022, 35: 24824-24837.
[12] Rafailov R, Sharma A, Mitchell E, et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model[C]//Advances in Neural Information Processing Systems (NeurIPS), 2023, 36: 53728-53741.
[13] Shao Z, Wang P, Zhu Q, et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models[EB/OL]. arXiv:2402.03300, 2024[2024-09-01]. https://arxiv.org/abs/2402.03300.
[14] Brown T B, Mann B, Ryder N, et al. Language Models are Few-Shot Learners[C]//Advances in Neural Information Processing Systems (NeurIPS), 2020, 33: 1877-1901.
[15] Hu E J, Shen Y, Wallis P, et al. LoRA: Low-Rank Adaptation of Large Language Models[C]//International Conference on Learning Representations (ICLR), 2022.
[16] Papineni K, Roukos S, Ward T, et al. BLEU: A Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), 2002: 311-318.
[17] Lin C Y. ROUGE: A Package for Automatic Evaluation of Summaries[C]//Text Summarization Branches Out. 2004: 74-81.
[18] Zhang T, Kishore V, Wu F, et al. BERTScore: Evaluating Text Generation with BERT[C]//International Conference on Learning Representations (ICLR), 2020.
[19] Mulloni A, Seichter H, Schmalstieg D. Handheld Augmented Reality Indoor Navigation with Activity-Based Instructions[C]//Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services (MobileHCI), 2011: 211-220.