
最近刷几个模型厂牌的招聘信息(定期刷可以提前预知这些公司的动作),发现 DeepSeek 和 Kimi 都上了 Harness 产品经理岗位。
是的,DeepSeek 要推出桌面 Agent 客户端了!
一个叫”Agent Harness 产品经理”,一个叫”Harness Product Engineer”。
这篇文章就从这两份 JD 出发,借着专业团队对 Harness 这个概念的定义,把里面提到的概念一个个拆开讲清楚。
回答本文标题的问题:天天嚷着要做 Agent Harness,到底要做什么?
先看 DeepSeek 的定义:Model + Harness = Agent

DeepSeek 在 JD 开头写了一句话,非常精确:
Model + Harness = Agent
我们正在把 DeepSeek 的前沿模型能力,转化为领先的 Agent 产品。
这其中除模型本身以外的所有工作,都属于 Harness 的范畴。
这句话值得反复读。
它说的是:模型本身(训练、推理、参数优化)不是 Harness。
模型之外的一切——怎么给模型喂信息、怎么管理工具、怎么设计交互、怎么处理错误、怎么让 Agent 在真实环境中跑起来——才是 Harness。
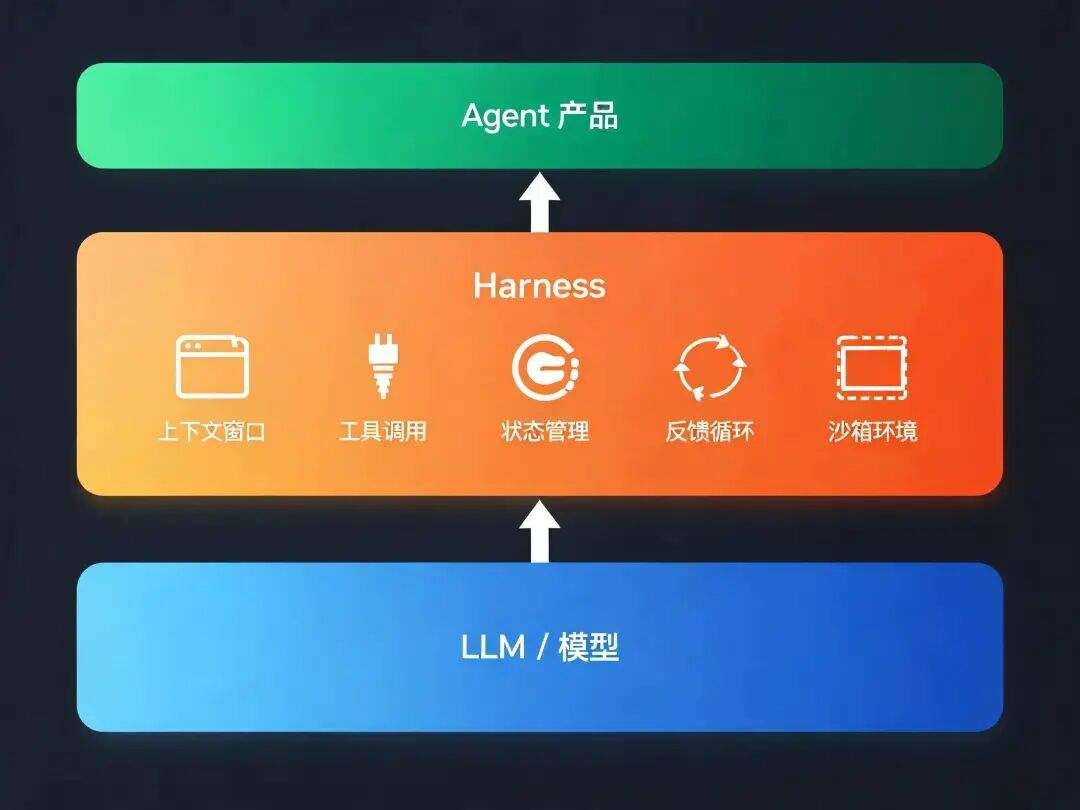
如果把 Agent 比作一辆自动驾驶汽车,模型是发动机,那 Harness 就是底盘、转向、刹车、传感器融合、路径规划、人机交互……发动机再强,没有这些东西,车也开不起来。
Kimi 的视角:Harness 决定 Agent 能走多远

Kimi 的 JD 开头用了另一种表述:
当 Agent 开始在真实世界中长时间调用工具、穿梭于浏览器、终端、桌面和移动端环境,并持续完成复杂任务时,真正决定它能走多远的,往往不只是模型本身,而是 harness 与 LLM 的共同优化结果。
Harness 决定状态如何被管理、上下文如何被交接、反馈如何被闭环,也决定 Agent 在长时间、高复杂度执行中能否保持稳定、清醒与可控。
这段话信息量很大。它点出了 Harness 需要解决的四个核心问题:
这四个问题,就是 Harness 产品经理每天要面对的战场。
拆解 JD 中的关键概念
接下来我们把两份 JD 中反复出现的技术概念逐个拆开。每个概念我会回答三个问题:它是什么?它为什么重要?PM 需要做什么?
1. Agent Loop
是什么: Agent 的基本运行模式。
Agent 不是”问一句答一句”,而是一个持续运转的循环——接收任务 → 推理思考 → 调用工具 → 获取结果 → 更新状态 → 继续下一步,直到任务完成。
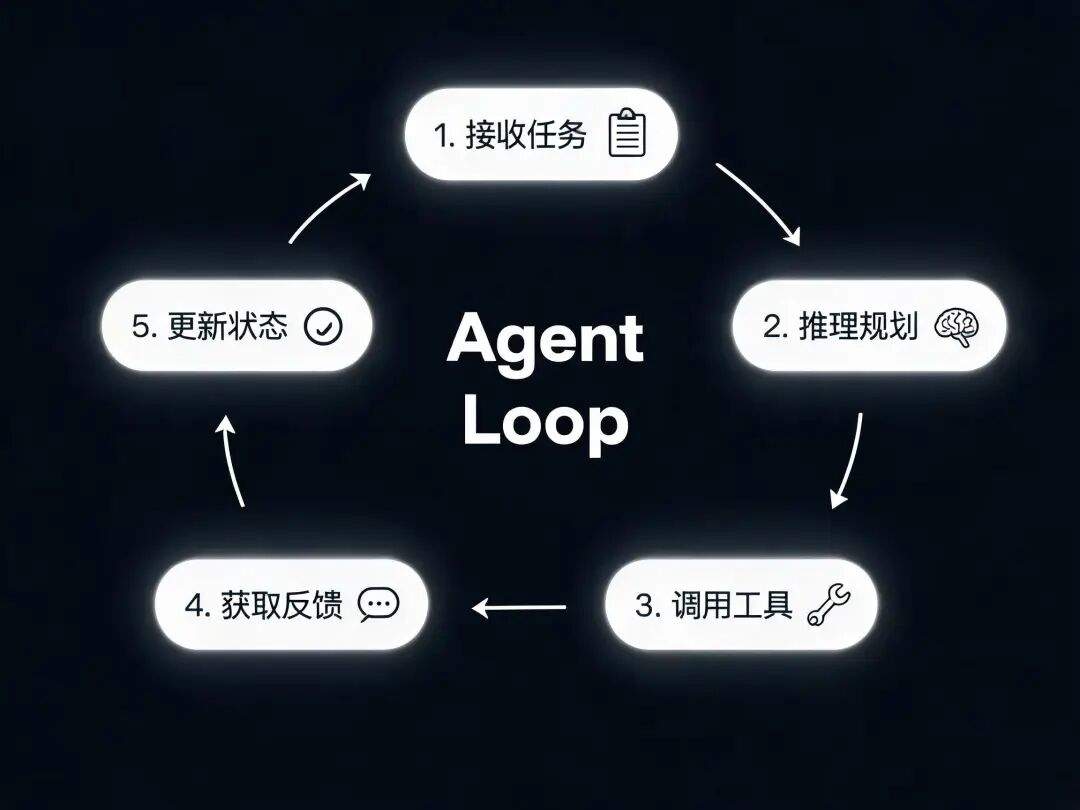
为什么重要: 传统的 Chatbot 是”一问一答”,而 Agent 是”给它一个任务,它自己跑完”。
这个”自己跑”的过程就是 Agent Loop。Harness 的核心工作就是设计这个循环的每一步。
PM 要做什么: 定义循环的边界——什么时候该停下来问人?什么时候该自主决策?循环最多跑多少步?每一步之间的信息怎么传递?
2. Context Engineering(上下文工程)
是什么: 管理 Agent 每次调用模型时”喂进去”的信息。
LLM 有一个上下文窗口(Context Window),就像一个工作台,空间有限。Context Engineering 就是决定工作台上放什么、不放什么、什么该压缩、什么必须保留。
这个概念是 Prompt Engineering 的进化版:
-
• Prompt Engineering:怎么写好一句提示词 -
• Context Engineering:怎么管理 Agent 运行过程中所有的上下文信息 -
• Harness Engineering:怎么设计整套系统让 Agent 稳定运行(Context Engineering 是其中的一部分)
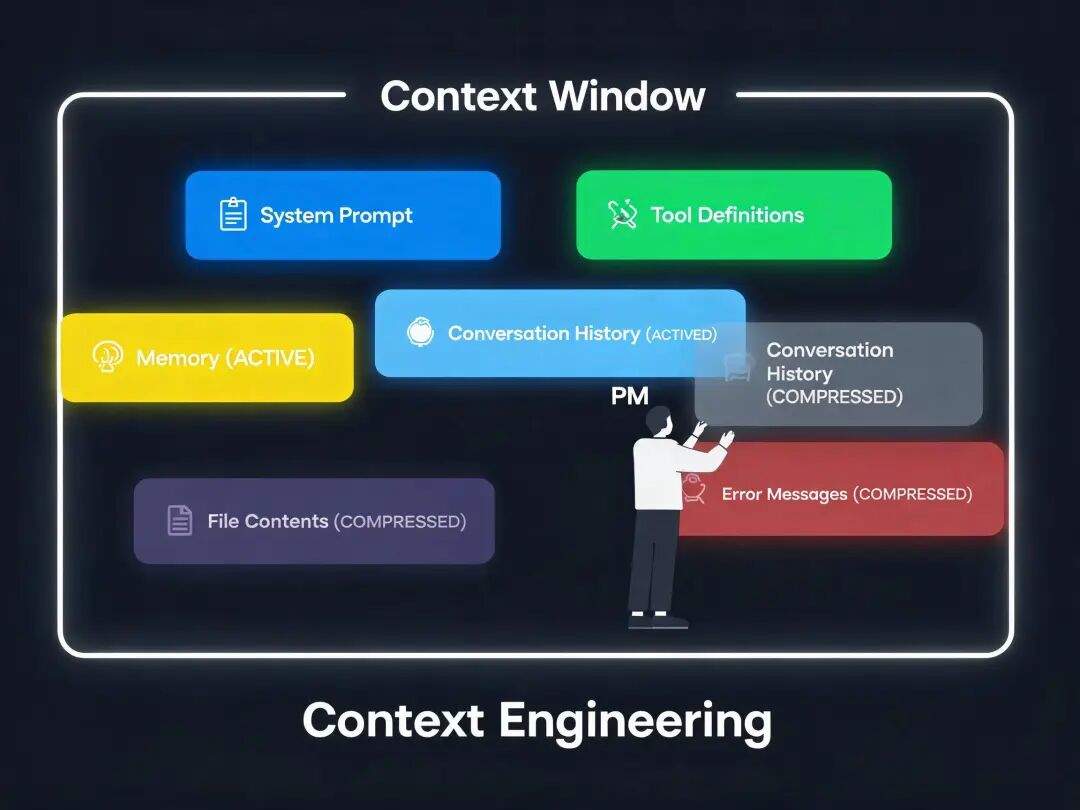
为什么重要: 上下文窗口是有限的。
一个长任务可能跑几百步,但上下文窗口装不下所有历史。哪些信息该保留?哪些该压缩(compaction)?压缩后会不会丢失关键信息?这些直接决定 Agent 的表现。
Kimi 的 JD 里有一句话特别精准: “你关心 Agent 在每一个 step 中获得的 context,在意 error message 是否给了 Agent 足够直接的引导,希望优化每一次 compaction 后留下的关键信息。”
PM 要做什么: 设计信息优先级策略——系统提示词占多少空间?工具定义占多少?对话历史保留多少轮?文件内容怎么截断?错误信息怎么精简但不失关键信息?
3. Tool Use 与 MCP(工具调用)
是什么: Agent 不只是”说话”,它要”做事”。
Tool Use 就是让 Agent 调用外部工具的能力——读写文件、执行代码、搜索网页、操作数据库、调用 API 等。
MCP 是 Tool Use 的子集,是 Anthropic 提出的一个开放协议,标准化了 Agent 与工具之间的通信方式。也就是按照统一的规范写 Tool Use 的代码。
为什么重要: 工具是 Agent 的”手脚”。
没有工具,Agent 只是一个聊天机器人。工具的质量直接影响 Agent 能完成什么任务。DeepSeek 的 JD 明确要求 PM 熟悉 MCP 协议。
PM 要做什么: 决定 Agent 需要哪些工具、工具的优先级、工具调用的权限控制(哪些操作需要用户确认)、工具失败时的降级策略。
4. State Management(状态管理)
是什么: 跟踪 Agent 在执行任务过程中的”当前状态”。
包括:任务进度、已完成的步骤、待处理的事项、中间结果、错误记录等。
为什么重要: 长任务执行中,Agent 需要知道”我做到哪了”。
如果状态管理混乱,Agent 可能重复做同一件事,或者遗漏关键步骤。Kimi 的 JD 把状态管理列为 Harness 的核心职责之一。
PM 要做什么: 设计状态的可视化方案(让用户能看到 Agent 的执行进度)、状态持久化策略(Agent 中断后能否恢复)、状态异常的检测和处理机制。
5. Sandbox(沙箱)与环境设计
是什么: Agent 执行代码和操作的隔离环境。
沙箱确保 Agent 的操作不会影响真实系统——比如 Agent 写了一段有 bug 的代码,沙箱可以防止它删掉你的系统文件。
为什么重要: Agent 需要在浏览器、终端、桌面、移动端等多种环境中工作。
每种环境都有不同的能力和限制。
Kimi 的 JD 明确提到了”面向长时复杂任务的 long-running agent harness,让 Agent 能在浏览器、终端、桌面、移动端等环境中持续推进工作“。
PM 要做什么: 定义 Agent 的环境边界(能访问什么、不能访问什么)、权限模型(哪些操作需要授权)、环境异常的处理策略。
6. KV Cache
是什么: LLM 推理时的性能优化技术。
模型在处理 token 时会生成中间计算结果(Key-Value 对),缓存这些结果可以避免重复计算,大幅提升推理速度。
大模型定价策略了,“缓存命中”和“缓存未命中”的价值,相差几十倍。
为什么重要: Agent 需要频繁调用模型(每一步都可能调一次),如果每次都从头计算,速度和成本都不可接受。
KV Cache 直接影响 Agent 的响应速度和运行成本。
DeepSeek 的 JD 明确要求 PM 理解 KV Cache。
PM 要做什么: 不需要自己实现 KV Cache,但需要理解它的原理和限制(比如缓存命中率、上下文长度对缓存效率的影响),以便在产品设计中做出合理权衡。
7. Reasoning 与 Planning(推理与规划)
是什么: Agent 的”思考能力”。Reasoning 是对当前情况的分析和推理,Planning 是对任务的整体规划和步骤拆解。
为什么重要: 简单任务可以一步一步做,但复杂任务需要先规划再执行。
Planning 能力决定了 Agent 能处理多复杂的任务。
DeepSeek 的 JD 提到了 Reasoning 和 Planning,Kimi 的 JD 则强调了”从 agent trace、失败案例和长任务运行日志中反推出系统真正的结构性问题“
—— 这意味着 PM 需要理解 Agent 的推理过程,才能判断问题出在哪里。
PM 要做什么: 设计 Planning 的展示方式(用户能否看到 Agent 的计划?能否修改计划?)、规划失败时的降级策略。
8. Memory(记忆)
是什么: Agent 跨会话、跨任务的信息持久化能力。
包括短期记忆(当前任务内的信息)和长期记忆(跨任务积累的知识和偏好)。
为什么重要: 没有 Memory 的 Agent 每次对话都是从零开始。
有了 Memory,Agent 可以记住用户的偏好、历史决策、常用工具和工作模式,越用越好用。
PM 要做什么: 设计记忆的存储、检索和遗忘策略——什么信息值得记住?记忆怎么检索?用户能不能查看和编辑 Agent 的记忆?隐私怎么保障?
9. Subagent 与 Multi-Agent(子智能体与多智能体)
是什么: 一个 Agent 可以拆分出多个子 Agent 来并行处理不同任务,或者多个 Agent 之间协作完成复杂任务。
为什么重要: 复杂任务往往包含多个独立子任务。
与其让一个 Agent 串行处理所有事情,不如让多个 Agent 各司其职、并行推进。
DeepSeek 的 JD 提到了 Subagent 和 Multi-Agent,OpenClaw、Hermes 等主流 Agent 产品都有非常棒的自动激活子 Agent 加速任务的设计。
PM 要做什么: 设计任务拆分和分配策略、子 Agent 之间的通信机制、结果汇总和冲突解决方案。
汇总:两份 JD 的关键词全景
把两份 JD 中出现的所有技术关键词整理成一张表:
两份 JD 的异同:两个视角看同一件事
DeepSeek 和 Kimi 对 Harness 产品经理的理解高度一致,但侧重点不同:
简单说:DeepSeek 招的是”懂技术的产品经理”,Kimi 招的是”懂产品的工程师”。
PM 到底要会什么?从 JD 提炼的能力模型
综合两份 JD,Agent Harness 产品经理需要具备以下能力:
必备能力
1. Agent 产品的深度使用经验
这是两份 JD 共同的硬性要求。
DeepSeek 列了一串产品清单:Claude Code、Codex、Cursor、OpenCode、GitHub Copilot、Manus、OpenClaw、Hermes 等。
不是”用过”就行,是要深度使用、融入工作和生活。
为什么这么重要?
因为 Harness 的设计决策极其依赖直觉——“这个 error message 够不够清晰?”“compaction 之后信息丢没丢?”“这个工具调用的反馈够不够及时?”
——这些判断只能来自大量真实使用经验。
2. 理解 LLM 和 Agent 的技术原理
不需要会写模型训练代码,但需要理解:
-
• LLM API 的输入输出机制 -
• Agent Loop 的运行逻辑 -
• 工具调用的协议和流程 -
• 上下文窗口的限制和管理策略 -
• KV Cache 对性能的影响
DeepSeek 明确说”能够使用 vibe coding 写代码,不一定需要技术背景“。
这说明岗位不要求你是工程师出身,但要求你能用 AI 辅助写代码,有动手验证想法的能力。
3. 系统性的用户研究能力
DeepSeek 要求”设计系统性的收集数据的方法(包括问卷、访谈、A/B 测试、灰度测试等),并使用统计学的工具严谨科学的分析数据“。
Kimi 则要求”从 agent trace、失败案例和长任务运行日志中反推出系统真正的结构性问题“。
两个视角合在一起:你需要既能从 用户侧 获取反馈(问卷、访谈),也能从 系统侧 提取信号(日志、trace、失败案例),然后用科学的方法分析这些数据。
最后啰嗦一段
Agent Harness 是一个全新的产品领域。
它不是传统意义上的”画原型、写 PRD、跟开发”,而是一个需要你深度使用产品、理解技术原理、与研究员协作、从数据中提取信号的综合性角色。
DeepSeek 和 Kimi 同时放出这类岗位,说明行业已经走到了”模型能力足够强,但产品化跟不上”的阶段。
谁能先把 Harness 做好,谁就能先把模型能力真正转化为用户价值。
如果你是一个对 Agent 产品有热情的产品经理,现在可能是最好的入局时机。
补一句,这些概念,我去年 9 月就已经开始在 AI 产品经理转岗特训营课程和日常直播里一遍一遍的讲了。
机会是留给有准备的人,现在开始准备依然不晚。