
如果你不懂 Harness,面试 AI 产品经理的时候肯定会被刷掉了。
虽然面试官可能也不懂,但是你有没有说到点子上对方是可以听出来的。
可能你了解过 Harness 的概念,但如果有没有真正下手做过,回答时是能被看出来的。
不止 AI,很多其他领域也都是这样的:没有在真实场景下通过解决真实的问题掌握的技能,就一定会有浓浓的“纸上谈兵”感。
但 AI 行业这么新,真正落地了的 AI 产品本身就没多少,怎么才能没做过但也能回答出那种实操感呢?
今天用这篇超长的文章,教大家怎么“驾驭”一个新概念。
核心思路很简单:模拟场景 → 盘点场景问题 → 用技能解决问题
我们以 Harness 这个新词为例,通过模拟“我如何在设计写作 Agent 时应用 Harness 工程策略一步一步优化产品”这个流程,解决三个问题:
-
1. 帮助还不了解 Harness 的 PM 掌握这个新概念 -
2. 帮助了解了 Harness 但不知道咋用的 PM 掌握实战能力 -
3. 演示如何在面试时回答出“实操感”
以下是把一个“裸奔”的写作 Agent,逐步通过一系列 Harness 策略“武装”成像 Claude Code 一样稳定的真·Agent 的过程。
其中关于当前阶段存在问题剖析、如何应用 Harness 策略的论述,就是你要在面试的时候讲出来的“实操感”。
从零到一:一个写作 Agent 的 Harness 工程迭代
模拟场景:开发一个「写作 Agent」——用户提供写作主题和风格参考文章,Agent 联网调研后在指定路径下输出文稿。
核心思路:以这个写作 Agent 为例,演示如何从一个「出厂配置」的基本 Agent 描述,逐层叠加 Harness 策略,最终形成一份可靠的开发规格。每一层都解决上一层暴露的问题,循序渐进。
第零章:需求背景
用户是谁?
一位内容创作者。他想写一篇关于某个主题的深度文章,手头有几篇风格参考文章,希望 AI 帮他完成「调研 → 构思 → 撰写 → 修改」的全流程,最终在指定文件夹里输出成品。
我们要造什么?
一个写作 Agent。它具备以下工具:

用户输入:写作主题 + 风格参考文章(文件路径)+ 输出路径。
Agent 在输出路径下生成最终文稿。
为什么要用这个场景演示?
写作任务有一个好特性:它天然是一条链路(调研 → 大纲 → 初稿 → 润色),步骤明确但不琐碎,适合展示 Agent 如何规划、如何执行、如何从错误中恢复。而且它不需要复杂的代码工具链,方便产品经理理解每一个 Harness 环节的意图。
v0.1:出厂配置 —— 最基础的 Agent 描述
「模型 + 循环 + 工具 = 一个能动的 Agent。就像新手机出厂设置,能打电话,但还没装 App。」
核心思路
一个 Agent 的最小构成只需要三样东西:
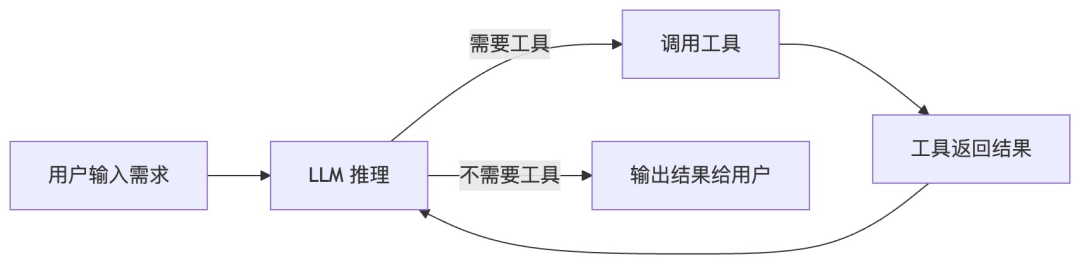
-
1. 循环(Loop):接收需求 → 推理 → 调用工具 → 拿到结果 → 继续推理,直到模型认为任务完成。 -
2. 工具(Tools):让模型能和真实世界交互——读写文件、搜索网页。 -
3. 规划(Planning):让模型在动手前先想清楚「要分几步做」。
V0.1 描述
这是面向 Coding Agent 的提示词版本,毕竟现在产品经理的工作流程已经不再是 PRD → 原型图 → 开发协(si)作(bi)了。

这个描述能跑吗?
能。但大概率会遇到这些问题:
-
• 🔴 Agent 搜了 20 条搜索结果,上下文直接撑爆,后边什么都干不了了。 -
• 🔴 写到一半跑偏了,开始写跟主题无关的内容,但自己不知道。 -
• 🔴 中途断了(比如工具调用报错),整个任务就废了,没有恢复机制。 -
• 🔴 Agent 觉得自己写完了,其实才写了个开头就停了(或者反过来,写完了还不停)。
Agent 怎么知道「我做到哪一步了」?
它不知道。因为我们的产品描述里只定义了「Agent 需要做哪些事」,但没有定义「做到哪了算哪」。一个没有任务清单的 Agent,就像一个没有清单的装修队——干到哪算哪,重复干活、遗漏步骤是家常便饭。
v0.2:任务规划与状态管理 —— 让 Agent 知道自己在干嘛
没有计划的 Agent 走哪算哪。先列步骤再动手,完成率翻倍。
上一轮的问题
v0.1 的 Agent 有两个致命缺陷:
-
1. 没有任务清单:模型不知道自己完成了什么、还剩什么。在长任务中,前面做的事会被后面的信息挤出注意力,导致重复干活或遗漏步骤。 -
2. 没有「完成」的判断标准:模型凭感觉决定什么时候停。有时任务没完成就停了(「我觉得差不多了」),有时完成了还在那磨蹭。
Harness 策略
策略一:强制任务规划(TodoWrite)
在循环开始前,要求 Agent 先生成一份结构化的任务清单。这份清单会作为上下文的一部分,在每一轮循环中持续呈现给模型。
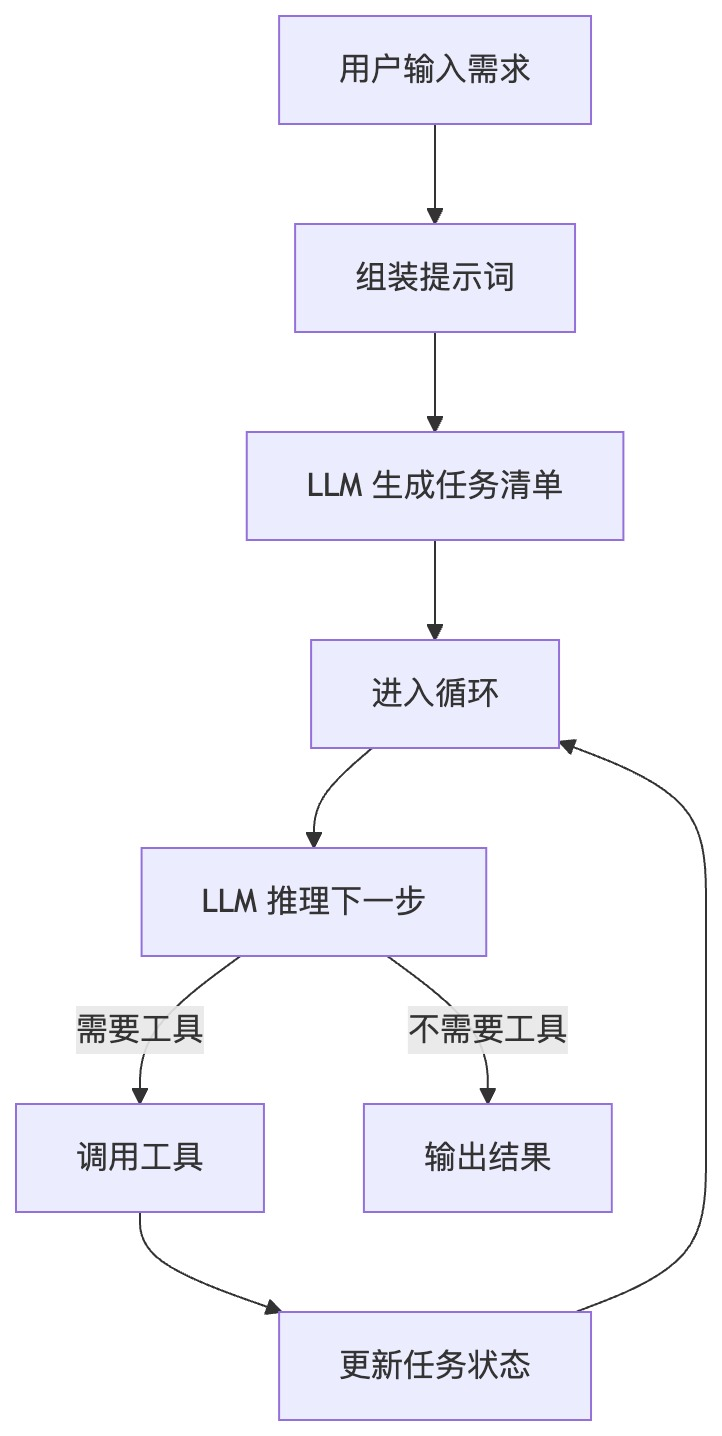
策略二:状态追踪与强制回顾
通过 Hooks(自动脚本),每轮循环结束时,自动把任务清单重新拼接到上下文末尾。利用「近因效应」——越靠后的内容对模型注意力影响越大——确保模型每轮都能看到「我做到哪了」。
策略三:熔断机制
设置最大循环轮次(如 50 轮)。同时,如果连续 3 轮模型没有更新任务状态,强制注入提示要求模型审视进度。
v0.2 描述

这样就好了吗?
好多了。Agent 现在有清单了,知道自己做到哪了,有「完成」的判断标准了。
但新问题来了:
-
• 🟡 写作任务需要搜索大量资料,每条搜索结果几千字。搜 10 条,上下文就满了。Agent 读了参考文章(可能 5000 字)又搜了几轮资料后,上下文窗口已经撑到极限,后面写大纲、写初稿的空间不够了。 -
• 🟡 Agent 搜资料时搜到了太多无关内容(比如搜「气候变化」结果出来一堆广告),这些垃圾信息占着上下文不走。
上下文窗口是有限的,怎么让 Agent 在有限空间里「无限」地工作?
v0.3:上下文管理 —— 在有限空间里「无限」工作
上下文窗口是 Agent 的工作台。台面就这么大,你得决定放什么、不放什么、什么该收起来。
上一轮的问题
上下文窗口(Context Window)就像一个工作台,空间有限。
一个 1000 行的文件约 4000 token,搜索结果可能上万 token。
写作 Agent 的完整工作流——搜资料 × 多轮 + 读参考文章 + 写大纲 + 写初稿 + 润色——轻松突破 100K token。
如果不做管理,要么上下文撑爆导致任务中断,要么旧信息被挤出导致模型「失忆」。
Harness 策略
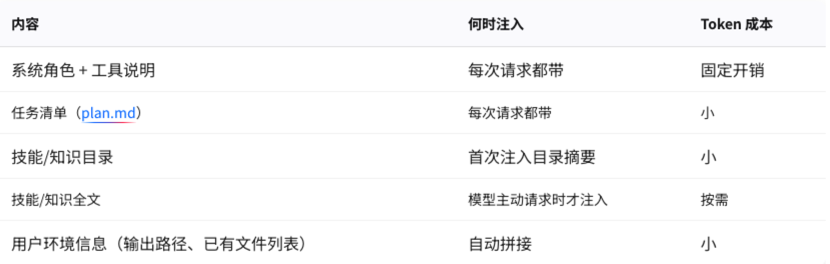
策略一:首轮上下文精准组装
系统提示词不是「一股脑全塞进去」,而是分层组装:
策略二:消息历史滚动压缩
每轮工具调用的结果不会永远留在上下文中。当消息列表增长到一定程度,早期的工具调用结果会被「归档」——替换为一条摘要 + 指向原始文件的路径。模型如果需要回顾,可以主动读取文件。
这就像浏览器标签页:你看完一个网页就关掉它,释放内存;需要时从历史记录里重新打开。

策略三:Subagent 分流
搜索环节特别适合用 Subagent(子代理)。主 Agent 发出指令「帮我搜一下 XX 主题的最新进展」,Subagent 用自己的独立上下文去搜索、筛选,只把结论摘要返回给主 Agent。
好处:主 Agent 的上下文里不包含搜索结果的原始全文,只有一句话摘要。10 条搜索 × 每条 3000 字 = 30000 字的原始结果,压缩成 10 条 × 每条 50 字 = 500 字的摘要。
策略四:技能列表(Skills)按需加载
如果 Agent 有多种「写作技能」(如学术写作、公众号写作、商业文案),不需要在系统提示词里塞入全部技能的完整说明。只需放一个技能目录(名称 + 一句话描述),当模型判断需要某种技能时,再加载完整说明。
V0.3 描述

上下文管理好了,然后呢?
Agent 现在能在有限的上下文空间里把任务执行完了。但有一个新风险:
-
• 🔴 Agent 在搜索资料时,执行了 bash命令curl下载了一个网页到本地,但写入路径时搞错了,把文件写到了输出路径之外的某个目录。 -
• 或者更糟——它执行了 rm命令,删掉了不该删的东西。
Agent 有执行 shell 命令的能力,万一它做了危险操作怎么办?
v0.4:沙箱与权限管理 —— 给 Agent 画一个安全围栏
不是不信任模型,而是不能无条件信任。每一次工具执行都必须经过安检。
上一轮的问题
Agent 能执行 bash 命令,意味着它理论上可以做任何事:读写任意文件、执行任意程序、访问网络。
即使模型没有恶意,也可能因为推理错误导致破坏性操作——比如把 write_file 的路径参数拼错,写到了系统目录。
Harness 策略
策略一:工作空间沙箱
为 Agent 定义一个「工作空间」(即输出路径)。所有文件操作的路径都必须解析为绝对路径后,校验是否在工作空间内。
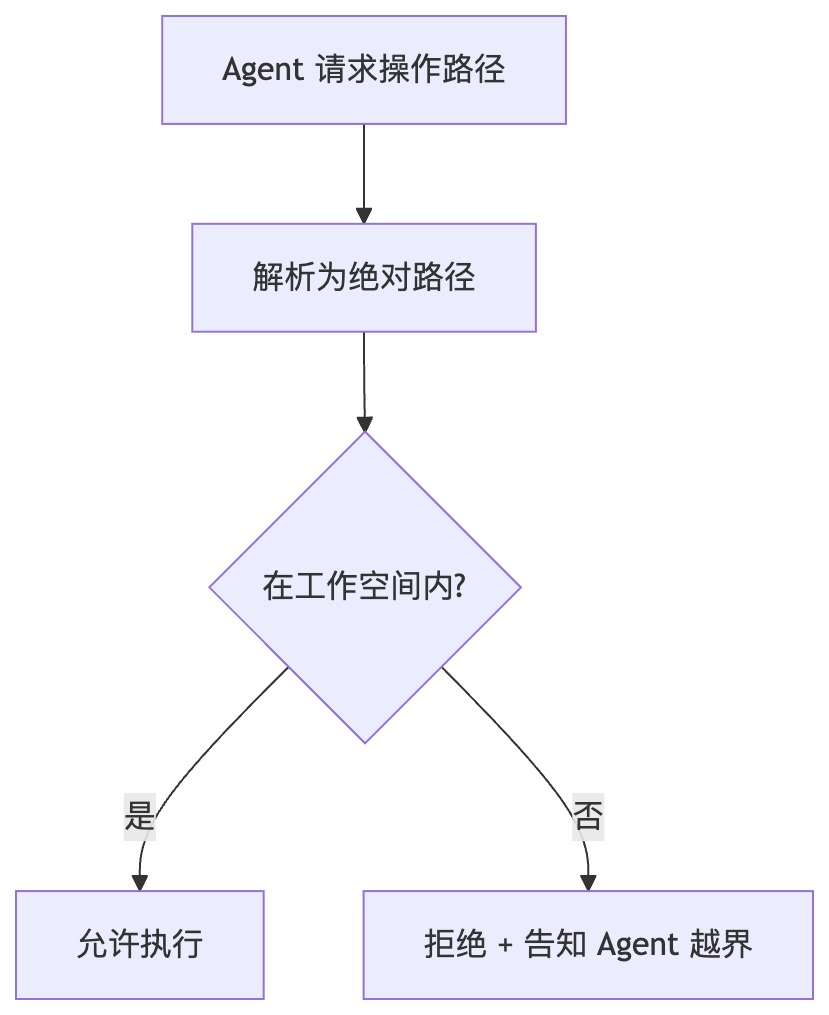
这就是「沙箱隔离」的本质:不是限制 Agent 的能力,而是限制它的活动范围。就像幼儿园的围栏——孩子可以在院子里随便跑,但跑不出去。
策略二:命令分层权限
不是所有命令都应该被同等对待:
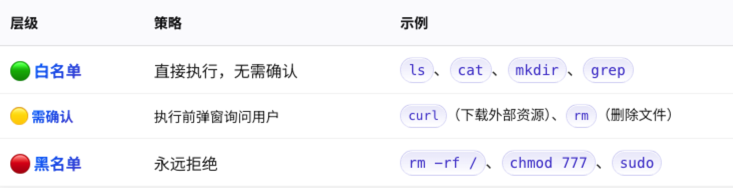
策略三:路径逃逸防护
Agent 在多次目录跳转后,可能拼接出 ../../ 这样的路径意外逃出工作空间。每次执行文件操作前,必须将路径规范化(resolve),然后校验是否仍在工作空间内。
V0.4 描述

安全问题解决了,但还有个效率问题
Agent 现在安全了。但我们在 v0.3 版本里提到的「每轮都更新 plan.md」「每轮都检查路径」这些操作——谁来执行?
如果全靠模型主动调用工具去做,那就是在浪费模型的注意力。
模型应该把注意力集中在「写作」这件事上,而不是每轮都要想起来「我是不是该更新一下 plan.md」。
有些操作是机械性的、应该自动执行的,不需要模型操心。怎么实现?
v0.5:Hooks —— 不需要模型操心的自动化
能用程序做的,就别浪费模型的注意力。Hooks 是 Agent 的后台管家。
上一轮的问题
到目前为止,很多操作都依赖模型「主动记得去做」:
-
• 更新任务清单 -
• 检查路径是否安全 -
• 拼接上下文信息
但模型不是人,它每轮都是一个全新的请求。它不记得「我上一轮是不是忘了更新 plan.md」。
如果靠提示词要求它做,它可能会忘;如果靠代码强制它做,它就永远不会忘。
Harness 策略
Hooks 是在 Agent 循环的关键节点自动执行的脚本,不需要模型参与:

常见的 Hooks 设计:
V0.5 描述

Hooks 是不是万能的?
不是。Hooks 解决了「机械性操作自动化」的问题,但有些事不是自动化能解决的——比如用户偏好。
假设这个写作 Agent 是一个长期使用的个人助理。
用户用了三个月,每次都说「我想要简洁风格」「不要用太多比喻」「开头要直入主题」。每次新会话都要重复这些。
Agent 怎么记住「上一次」和「用户的习惯」?
v0.6:记忆管理 —— 让 Agent 越用越好
没有记忆的 Agent,每次对话都是初次见面。
上一轮的问题
当前的 Agent 每次启动都是「白纸一张」。它不记得:
-
• 用户偏好的写作风格(简洁?华丽?学术?) -
• 之前写过什么主题(避免重复) -
• 用户纠正过哪些错误(「不要用这种开头方式」) -
• 之前任务的产出(方便复用或引用)
Harness 策略
策略一:自动记忆提取
每次任务结束后,通过一个自动 Hook 调用 LLM,从对话中提取值得记忆的信息:

这些记忆以结构化文本存储,在每次新会话的首轮上下文组装时自动注入。
策略二:跨会话检索
当用户说「上次我们写过一篇关于 XX 的文章,帮我引用一下那篇的观点」,Agent 需要能检索历史会话。但不是把历史会话全部塞入上下文,而是通过关键词检索,只拉取相关片段。

V0.6 描述

记忆有了,但还有个大问题
一切看起来不错了。但让我们回到一个基本问题:
如果工具调用失败了怎么办?
-
• 搜索 API 超时了。 -
• write_file因为权限问题写入失败了。 -
• read_file读到了一个二进制文件,返回了一堆乱码。 -
• 网络断了, web_search直接报错。
在 V0.1 里,如果工具调用失败,错误信息直接塞进上下文,模型可能会困惑、重复尝试、甚至直接放弃。
在长任务中,一次未处理的错误可能导致整个后续流程崩掉。
错误发生了,Agent 怎么体面地恢复,而不是直接崩溃?
v0.7:错误恢复 —— 小错不崩,大错可控
做 Harness 的第一性原理:小错不跳循环,让模型自己处理;大错尽量别犯。
上一轮的问题
在没有错误恢复机制的情况下:
-
• 一个搜索 API 超时 → Agent 不知道怎么办 → 可能无限重试,浪费轮次。 -
• write_file失败 → Agent 没有意识到文件没写成功 → 继续下一步,结果最终输出缺失。 -
• 多次失败累积 → 上下文里塞满了错误信息 → 模型的注意力被错误信息绑架,忘记自己在写文章。
Harness 策略
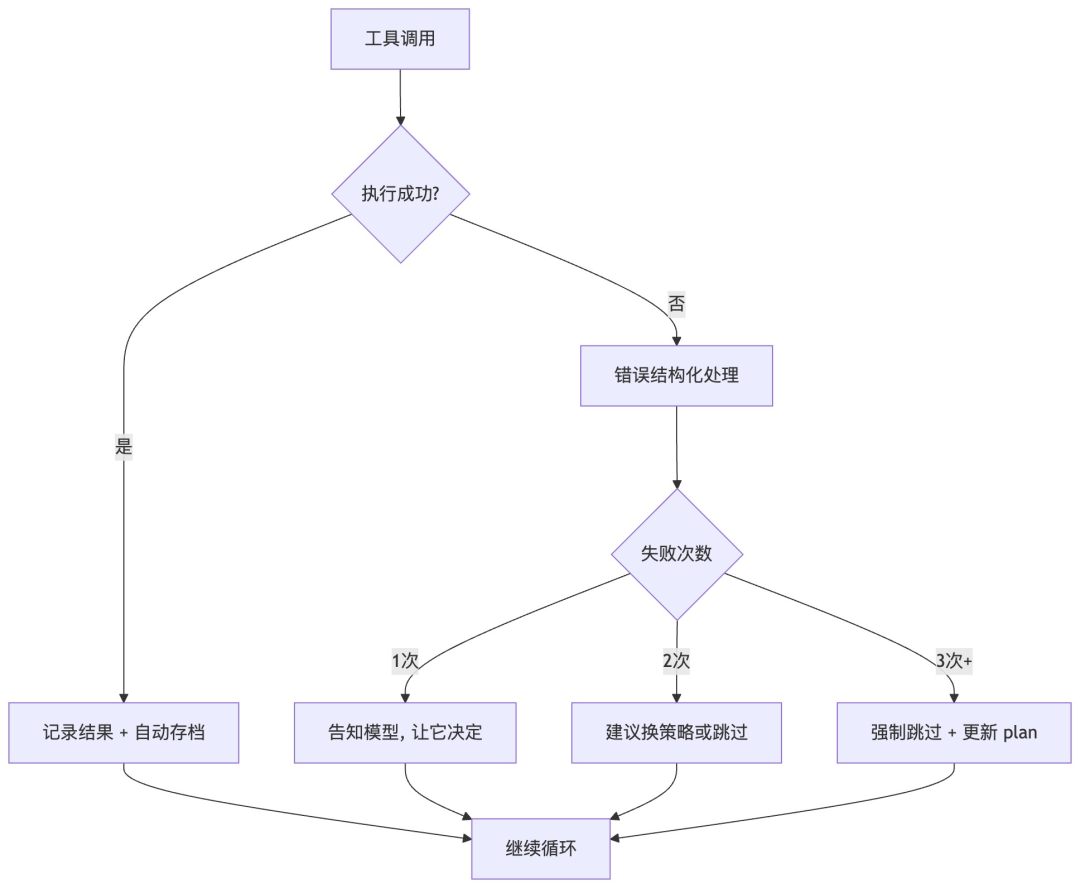
策略一:错误信息的结构化处理
工具调用失败时,不是把原始错误日志直接丢进上下文,而是经过 Hook 处理成结构化的错误摘要:
❌ 工具调用失败:web_search
原因:API 请求超时(30秒)
建议:换一个搜索关键词重试,或跳过该搜索步骤
这是该步骤的第 2 次失败。如果再次失败,建议跳过该步骤。
这比一堆 stack trace 对模型友好得多。模型看到这个信息,知道该怎么做。
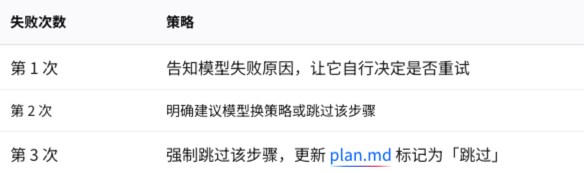
策略二:失败计数与降级
对每个工具维护失败计数:
策略三:关键节点的自动存档
每次 write_file 或 edit_file 执行成功后,自动通过 Hook 保存一个快照(或触发 git commit)。如果后续步骤出错导致文稿损坏,可以回滚到上一个正确版本。
V0.7 描述

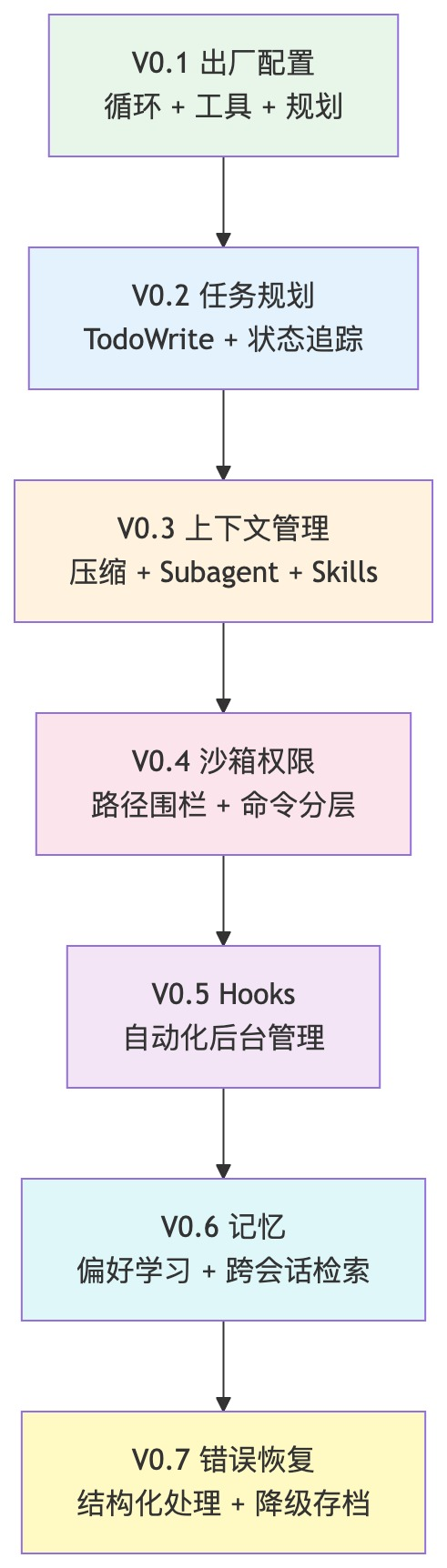
总结:七层迭代全景

回到 Harness 的基本概念
Model + Harness = Agent
我们用七层迭代,展示了「Harness」到底在做什么:
-
• 循环让模型能行动。 -
• 任务规划让模型不迷路。 -
• 上下文管理让模型不遗忘。 -
• 沙箱让模型不越界。 -
• Hooks让机械操作不消耗模型注意力。 -
• 记忆让模型能成长。 -
• 错误恢复让模型不崩溃。
每一层都不是「锦上添花」,而是在真实场景中必须解决的工程问题。跳过任何一层,Agent 在实际使用中都会暴露对应的缺陷——这就是 Harness 工程的意义。
附录:给产品经理的自检清单
如果你正在设计一个 Agent 产品,可以用这份清单逐项检查:
-
• [ ] 循环控制:Agent 有明确的停止条件吗?最大轮次限制是多少? -
• [ ] 任务规划:Agent 能生成任务清单吗?清单会在每轮循环中被回顾吗? -
• [ ] 状态管理:Agent 怎么知道自己做到哪了?连续跑偏时有检测机制吗? -
• [ ] 上下文窗口:系统提示词占了多少 token?工具定义占了多少?给对话历史留了多少空间? -
• [ ] 上下文压缩:消息历史太长时怎么处理?压缩后关键信息丢了吗? -
• [ ] 沙箱:Agent 的文件操作有路径限制吗?能逃逸出工作空间吗? -
• [ ] 权限管理:哪些命令直接执行?哪些需要用户确认?哪些永远禁止? -
• [ ] Hooks:哪些操作可以自动化?不依赖模型主动记得去做? -
• [ ] 记忆:用户的偏好怎么跨会话传递?历史会话怎么检索? -
• [ ] 错误处理:工具调用失败时怎么告诉模型?连续失败时怎么降级? -
• [ ] 用户追加消息:Agent 干活时用户发了新消息,怎么处理?中断还是排队?
另一个版本
上面是按照 Agent 作业流程的「任务规划」开始,把流程上每个遇到的问题进行优化的版本。
另一个思路是从 Agent 的另一个基础组件tools的优化开始的。
最终解决一样,但却是思维方式的差异:
-
• 前者是流程导向,通过约束流程的可控性来确保产品的可控性 -
• 后者是原子导向,通过约束基本组件的可控性来保证产品的可控性
篇幅关系,不再贴一遍了,感兴趣可以去知识星球搜索Harness Demo获取。
重要通知:AI产品经理转型线下课就要开营了
如果你觉得线上学习不够快,欢迎报名来线下“突击”
——两天时间,从认知到实践,一次性打通。
首期课程安排了北京、上海、深圳三城联动,每城周末两天。
-
• 第一天: 带你成为会用 AI 的产品经理。 从趋势认知到工具实操,竞品分析、PRD 撰写、高保真原型图、AI 赋能可行性分析、RAG 知识库搭建——产品经理日常工作中最高频的 AI 应用场景,现场练完 -
• 第二天: 成为能开发AI 原生产品的 PM。 Agent 原理、Harness 工程策略、Skill 设计、Web Coding——从概念到动手,下午直接分组做项目实战,现场 Demo Day 展示成果
首发价 2999 元(原价 3699),受场地限制,名额有限。
深圳 6.27-28 → 北京 7.4-5 → 上海 7.11-12
扫描下方二维码,联系班主任获取完整的课程安排
