

如果你用过任何 AI Agent 框架,你一定遇到过这个问题:API 费用。一个下午的测试和调试,几十块钱就没了。换成免费模型?要么效果差,要么频繁触发速率限制,一顿操作下来比付费还累。
Free Ride 这个 Skill 做的事就是在 OpenClaw 里自动配置 OpenRouter 的免费模型链路。66.2k 下载量,461 个 Star,MIT-0 许可证,作者 Shaishav Pidadi 用不到 500 行 Python 解决了一个挺实际的痛点。但真正让我觉得值得写一篇文章的,不是它”能用免费模型”这个结论,而是它处理速率限制和回退链的设计方式。
说真的,这篇文章不会跟你讲太多 AI 概念。我会把 Free Ride 的安装配置、操作流程、设计决策拆开来看,哪里做得好,哪里还有坑,以及它背后反映的一个趋势:免费模型的可用性正在逼近付费模型,而 Skill 生态正在把这种能力变得像装个插件一样简单。
环境准备
Free Ride 的前置条件不算多,但有一个容易忽略的环节。你需要先有一个 OpenRouter 的 API Key,去 openrouter.ai/keys 注册就能拿到。这个 Key 是免费的,注册不需要绑信用卡,OpenRouter 会按月给你一定额度的免费调用配额。
拿到 Key 之后,先把它设到环境变量里:
export OPENROUTER_API_KEY="sk-or-v1-..."
或者用 OpenClaw 的 config 命令持久化,这样不用每次开终端都重新 export:
openclaw config set env.OPENROUTER_API_KEY "sk-or-v1-..."
然后是安装 Free Ride 本身。一条命令搞定:
openclaw skills install free-ride
装完后还需要初始化一下 CLI 环境,这一步很多人会忘。切到 Skill 目录跑 pip install:
cd ~/.openclaw/workspace/skills/free-ride
pip install -e .
漏了这一步的话,后面跑 freeride 命令会提示 command not found。看起来像是小问题,但从社区反馈看,这是新手最容易卡住的点,差不多占了故障排查的一半。
验证环境是否就绪,跑个最简单的状态查询:
freeride status
如果输出了当前配置状态(哪怕是空的),说明环境没问题,可以往下走了。
操作流程
Free Ride 的核心操作链路其实只有两步,但这两步之间有一个很容易被忽略的细节。
第一步,自动配置最佳免费模型和回退链:
freeride auto
这个命令会从 OpenRouter 的免费模型池里选出当前表现最好的一个作为主模型,然后按性能从高到低排出一个回退链。默认链长是 5 个,你可以用 -c 10 扩到 10 个,越多理论上抗速率限制能力越强,但配置也会更臃肿。
如果你对当前的主模型已经满意了,只是想刷新回退链,加个 -f 就行:
freeride auto -f
这条命令不碰主模型,只更新 fallbacks。在模型频繁变动的周更节奏里,这个小开关很实用。
第二步,重启 OpenClaw 网关让配置生效:
openclaw gateway restart
这一步写出来只有一行,但它是我看到最多人跳过的环节。Free Ride 修改的是 openclaw.json 配置文件,OpenClaw 只在启动时读一次这个文件。不改配置不重启的话,你跑出来的还是旧模型。改完配置再开一个新的会话(/new),用 /status 确认当前激活的模型名称是不是 openrouter/<provider>/<model>:free 格式。
除了 auto 这种一键方案,Free Ride 还提供了几个细粒度控制命令。想看有哪些免费模型可选:
freeride list
想指定某个模型而不是让自动选择:
freeride switch qwen3-coder
这条命令在你知道自己想要什么模型的时候比 auto 更直接。比如你明确需要代码能力,qwen3-coder 在免费模型里表现确实不错。
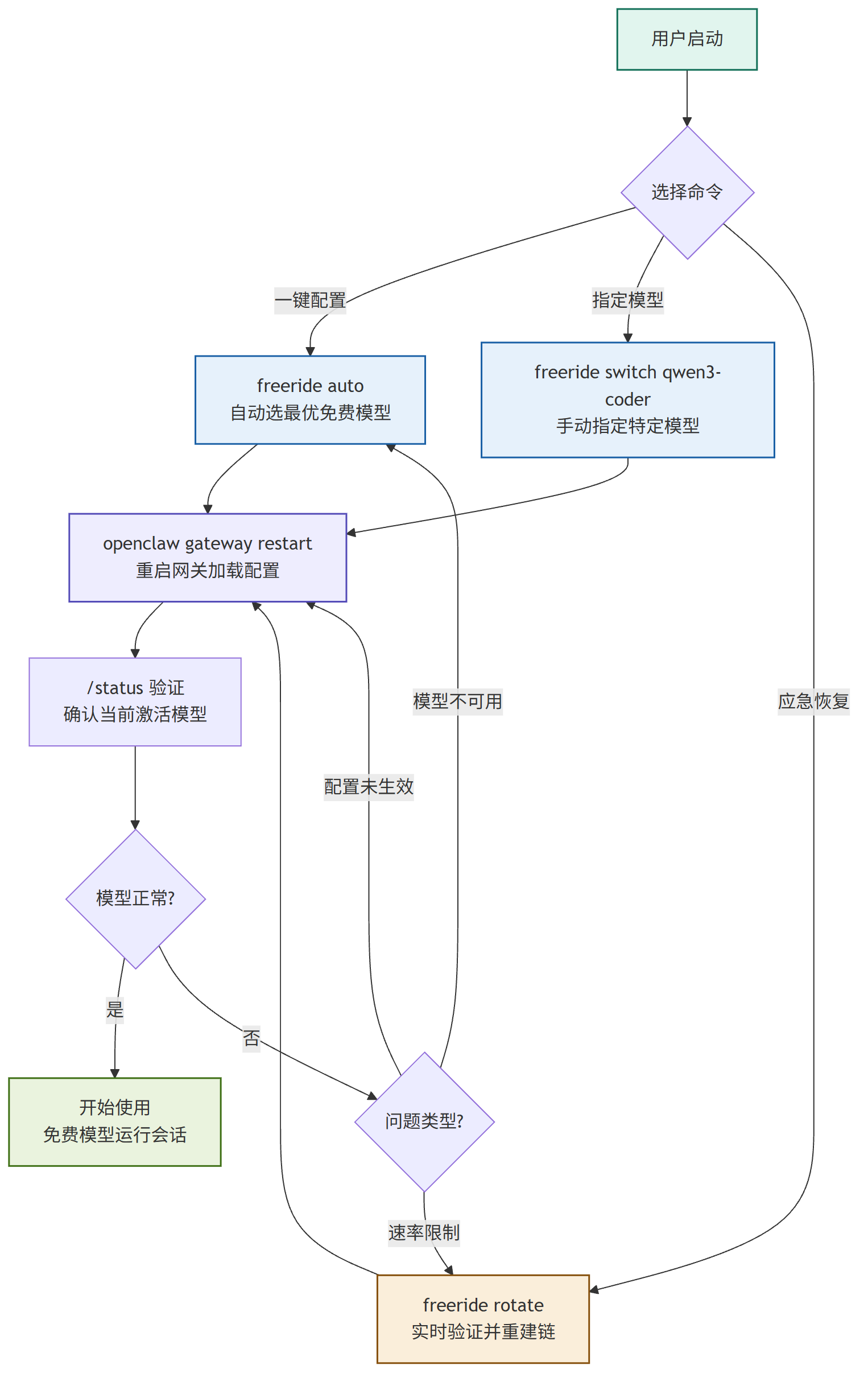
还有一个救急命令值得单独说。当你正用着免费模型,突然遇到速率限制,回退链也全挂了,别手动一个个试:
freeride rotate
这个命令会实时测试每个候选模型的可用性,只把能正常响应的放进回退链。比 auto 慢一点(因为要逐个发请求验证),但准确率明显更高。实测下来,在回退链完全耗尽的时候,rotate 能省掉至少十分钟的手动排查时间。
关键设计
Free Ride 的设计里,最值得拆开看的是三个决策:回退链的结构、配置写入的策略、以及后台守护进程的存在意义。
回退链的第一个位置永远是 openrouter/free,这看起来像是一个偷懒的默认值,实际是一个很聪明的容错设计。openrouter/free 是 OpenRouter 自己的智能路由端点,它会根据你的请求内容动态选择最合适的免费模型。也就是说,即使 Free Ride 缓存的模型列表过时了,只要 openrouter/free 这个端点还在,你至少还有一个能用的兜底。把这个端点放在回退链第一位,相当于在”精确选择”之前加了一层”智能路由”的安全网。
配置写入策略也很有意思。Free Ride 只改 openclaw.json 里的三个字段:agents.defaults.model.primary、agents.defaults.model.fallbacks、agents.defaults.models 白名单。其他所有配置,gateway、channels、plugins、自定义 agents,原封不动保留。这不是技术上的妥协,而是一个明确的边界声明:我只管模型选择,别的事我不碰。
这个边界意识在 Skill 生态里其实相当罕见。大多数同类工具要么写死整个配置文件,要么要求你手动编辑。Free Ride 的”最小侵入”策略让它既能自动化配置,又不会在你手动改过其他配置后覆盖掉你的设置。从代码仓库的 commit 历史来看,作者在 v1.0.7 之后专门做了配置 diff 逻辑,确保写入前先读后比,只改动真正需要改的字段。
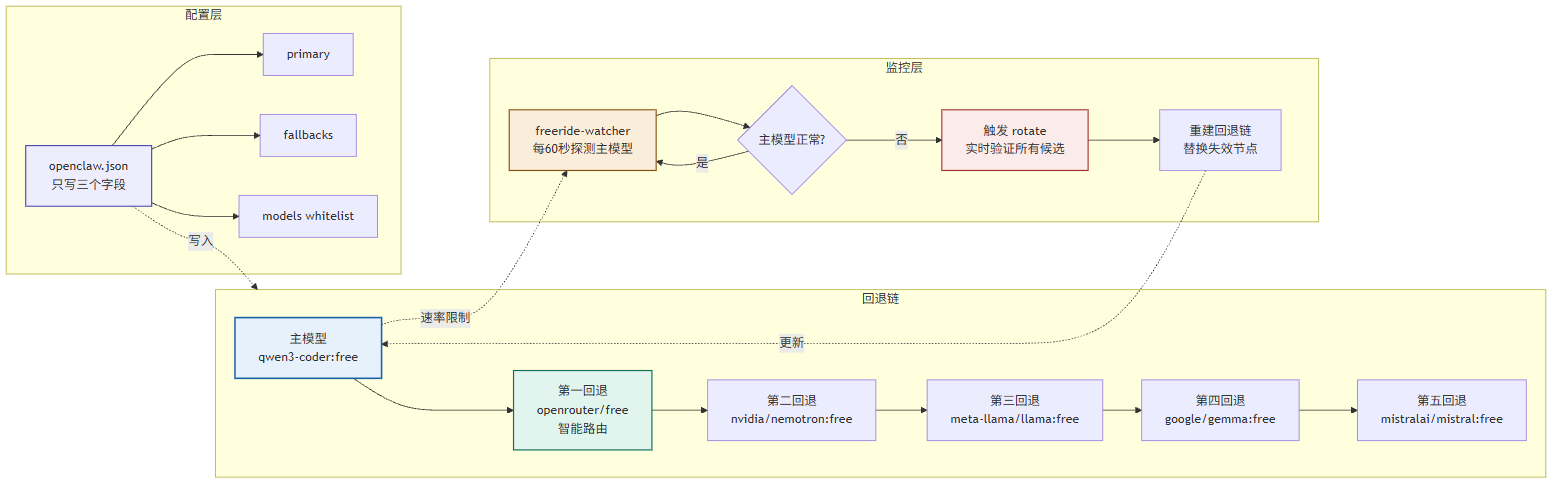
后台守护进程 freeride-watcher 是一个”看起来没必要,但有了之后体验完全不同”的设计。它每 60 秒探测一次主模型是否还能正常响应,一旦发现失败,就自动用经过实时验证的模型重建回退链。对于无人值守的场景(定时任务、后台 Agent、长时间运行的工作流),这个守护进程把”回退链耗尽”从人工排障问题变成了自动恢复能力。
启动方式很简单:
nohup freeride-watcher > ~/.openclaw/freeride-watcher.log 2>&1 &
如果只是偶尔想检查一下而不是持续监控,freeride-watcher --once 跑一次就行。想看守护进程的历史活动记录,freeride-watcher --status 会输出最近的探测结果和重建次数。
但我必须说,这个守护进程也有一个明显的局限:它只监测主模型的可用性,不追踪每个回退模型的状态。如果主模型还活着,但第三个回退模型已经不可用了,watcher 不会管。这意味着在极端情况下,你可能仍然会遇到回退链中某个节点挂掉的问题。不算致命,但确实是一个可以改进的点。
使用场景
Free Ride 最适合的三类场景,分别对应了三个完全不同的人群。
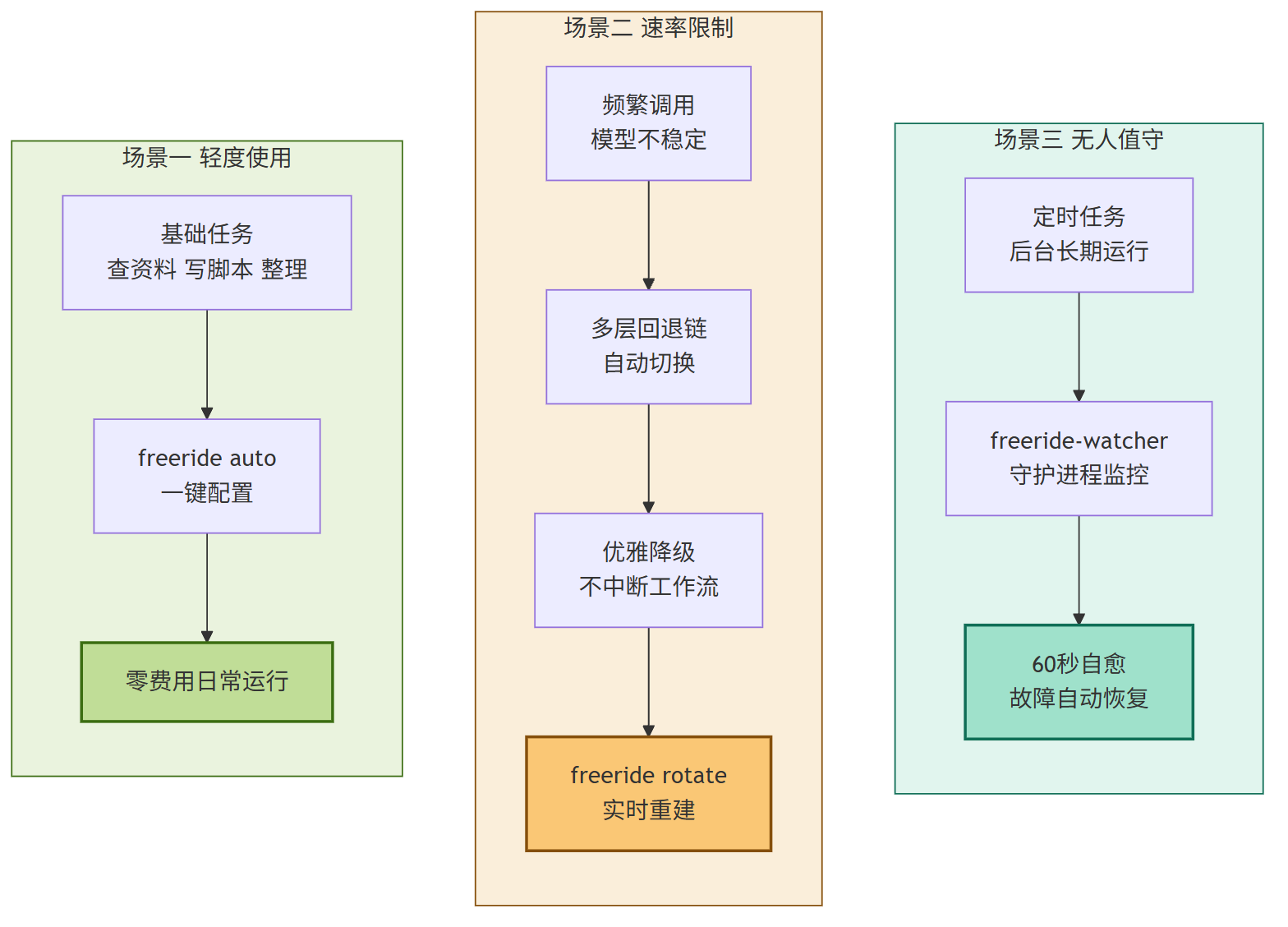
第一类是日常轻度使用者。你不需要处理复杂推理、长文本生成或者专业领域问答,只是想让 OpenClaw 帮你做一些基础任务:查资料、写简单脚本、整理信息。这时候用免费模型完全够用,而 Free Ride 的一键配置让你不需要手动去 OpenRouter 翻模型列表、对比 benchmark、调试参数。跑个 freeride auto 加一次重启,三分钟搞定的时间成本换来的是一整个模型的零费用运行。
第二类是被速率限制搞到崩溃的开发者。免费模型的最大痛点不是效果差,是不稳定。一个模型白天能跑,晚上可能就被限了。Free Ride 的多层回退链在这里的价值就体现出来了:第一个模型挂了,自动切第二个,再挂切第三个。配合 freeride rotate 的实时验证,你甚至可以在回退链耗尽之前主动感知并更新。这种”优雅降级”的模式让我想起 CDN 的多级缓存策略,虽然不是新概念,但在 AI Skill 里落地得这么干净的还不多见。
第三类是跑定时任务或后台 Agent 的自动化场景。这类用户往往不会盯着终端看模型有没有挂,他们需要的是”设完就不用管了”。freeride-watcher 守护进程就是为这种场景设计的。设好后丢在后台,每 60 秒自检一次,挂了就自动重建。
当然,完全不花钱是不可能的。OpenRouter 的免费额度是有限的,每个月有固定配额。Free Ride 能做到的是让你在额度内最大化利用免费模型,而不是无限量白嫖。如果你的使用量很大,比如一天几百次复杂推理请求,免费模型和付费 API 之间的差距会迅速拉大。这个 Skill 的价值边界在”轻度到中度使用”这个区间里。
洞察与反思
写这篇文章的过程中,我一直在想一个问题:Free Ride 的 66k 下载量到底是因为它做得好,还是因为它踩中了一个正在形成的趋势?
从设计角度看,Free Ride 的代码量和复杂度都不算高。它的核心竞争力不在算法创新,而在对 OpenRouter 免费模型生态的理解深度。知道哪些模型免费、知道怎么排序、知道速率限制的触发模式、知道回退链的最佳长度,这些东西随便一个开发者花两天都能调研出来。但 Free Ride 把这些封装成了一个开箱即用的 CLI,这就把”知识门槛”变成了”安装门槛”。
Skill 生态的一个核心价值正在于此:不是让你能做之前做不到的事,而是让你不需要重新发明轮子。Free Ride 本质上是一份”免费模型使用指南”的自动化版本。
但这也引出了一个不太让人舒服的问题。OpenRouter 的免费模型策略能持续多久?目前的免费模型列表里,qwen3-coder、nvidia/nemotron 这些模型的免费额度是厂商提供的推广配额,不是永久免费的承诺。一旦某个模型取消免费或提高门槛,Free Ride 的模型池就会缩水。作者在 v1.0.11 里加入了缓存的模型列表刷新机制(freeride refresh),但这只能解决”数据过时”的问题,解决不了”数据源头消失”的问题。
另外一个值得留意的点是,随着越来越多的 Skill 开始用 Free Ride 做默认模型配置,OpenRouter 的免费额度压力会越来越大。66k 次下载如果对应 10% 的活跃用户,每个用户每天发几十条请求,这个量的免费调用对 OpenRouter 来说不是小数。我不确定 OpenRouter 会不会在未来收紧免费额度,但从商业逻辑推断,无限免费在长期是不可持续的。
话又说回来,就算免费模型哪天消失了,Free Ride 的设计模式不会过时。自动选最优模型、多层回退链、最小侵入配置、后台自愈守护,这四种模式可以套到任何需要”智能路由模型选择”的场景上。这也是为什么我觉得这篇文章值得写:它不是让你省几块钱 API 费,而是展示了一种把”模型选择”这个看起来简单、实际很琐碎的问题标准化处理的思路。
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/shaivpidadi/free-ride |
| GitHub | https://github.com/shaivpidadi/free-ride |
| OpenRouter API | https://openrouter.ai/keys |
总结
Free Ride 解决的不是一个技术难题,而是一个体验问题。它做的事总结起来就是三件:选模型、排队、自动恢复。每件事单独拎出来都算不上高深,但把它们串成一个零配置的自动化流水线之后,体验就从”我得自己管这些破事”变成了”跑一条命令就行”。
看完它的设计和实现,我最大的感受倒不是”免费模型真好用”,而是 Skill 这个形态对 AI 工具链的改造潜力。一个好的 Skill 可以把分散的知识、琐碎的配置、反复踩坑的经验封装成一个可复用的单元。Free Ride 做到了这一点,虽然还不完美,但方向上是对的。
注册一个 OpenRouter 免费 API Key,装好 Free Ride,跑 freeride auto 加 openclaw gateway restart。然后用 /status 确认当前激活的模型是不是 :free 结尾。接下来一整天的工作会话全部跑在免费模型上,看看到底会不会触发速率限制,以及触发了之后回退链能不能兜住。如果遇到回退链耗尽,跑一次 freeride rotate 看看自动重建的效果。
FAQ 常见问题
Q: Free Ride 只能用 OpenRouter 吗? A: 目前是的。它的整个模型发现、排序和路由逻辑都基于 OpenRouter 的免费模型池,不支持其他 API 供应商。不过设计模式是通用的,理论上可以移植。
Q: 免费模型的效果跟付费模型差多远? A: 日常任务(信息查询、简单代码、文本处理)差距不大,qwen3-coder 在基础编程上表现甚至超出预期。但复杂推理、长文本生成、多步 Agent 协作这些场景,付费模型(GPT-4o、Claude Sonnet)的优势还是很明显。
Q: 如果 OpenRouter 收紧免费额度,这个 Skill 还有用吗? A: 它回退链和自动选最优模型的设计模式不会过时。即使免费模型变少或消失,这套逻辑换一个模型池同样适用。
Q: 回退链里一共有几个模型? A: 默认 5 个,可以用 -c 参数扩到任意数量。第一个位置固定是 openrouter/free 智能路由,后面按性能排序。建议不要设太多,5-8 个足够了,再多反而让配置冗余。