
ClawHub 上有接近 6000 个 Skill。搜索、安装、更新、发布,这些事情如果全靠在网页上点点点,一天下来能处理十个 Skill 算你手速快。更别说那些想维护自己 Skill 集合的开发者,版本升级、批量同步、跨机器迁移,每一个环节都能让人暴躁。
所以 steipete 做了一件事。他给 ClawdHub 写了一个 CLI。
不是那种”先打开终端,敲一条命令,然后还是得切回浏览器”的半吊子方案。是从搜索到安装到更新到发布,所有操作都能在终端里搞定。对,包括发布你自己的 Skill。
说真的,这个 Skill 解决的问题比表面看起来深得多。它不是在给 ClawHub 加个命令行入口,而是在给整个 Skill 生态搭一层可编程的基础设施。换个角度讲,有了这个 CLI,你不再只是一个 Skill 的消费者——你可以用脚本管理 Skill 集合,用 CI 自动更新,甚至搭建自己的私有 Skill 注册表。这篇文章拆的就是这件事。
环境准备
前置条件不复杂。你的机器上需要 Node.js(什么版本都行,npm 全局安装不挑版本),以及一个已经跑起来的 OpenClaw 实例。如果只是想发布 Skill,还需要一个 ClawdHub 账号。
安装只有一行命令:
npm i -g clawdhub
跑完之后用 clawdhub --version 确认一下。如果你用的是 OpenClaw 内置的 Skill 安装机制,也可以直接在 Agent 对话里敲 openclaw skills install clawdhub,本质上是一样的。
最常见的卡点有两个。一个是全局 npm 路径没加到 PATH 里,装完发现 clawdhub: command not found。另一个是发布时需要先 clawdhub login,走标准的 OAuth 认证流程,这一步如果跳过了,后面 publish 会报 401。两个问题都不难解决,但第一次碰到的时候确实会愣一下。
操作流程
ClawdHub CLI 的命令设计遵循一个清晰的认知路径:先探索,再获取,再维护,最后贡献。这个顺序不是乱排的,它对应了大多数人从”试用”到”重度依赖”的自然演进。
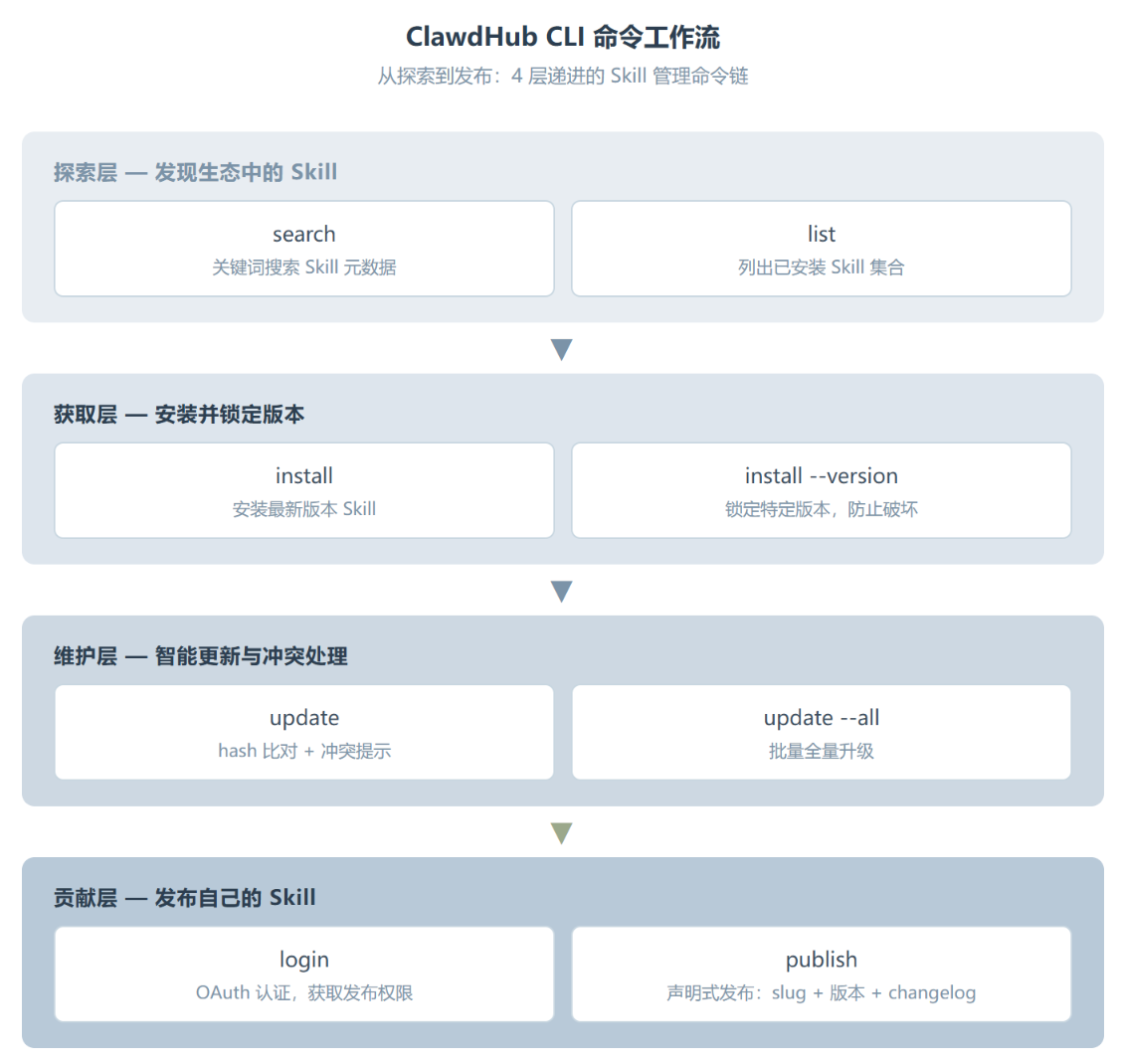
搜索是你跟这个生态的第一次接触。clawdhub search "postgres backups" 返回的结果不是简单的名字匹配,而是包含了描述、下载量、评分之类的元数据。这个过程的关键在于关键词的粒度。搜”slack”可能返回几十个结果,搜”slack message scheduling”才能精准命中你真正需要的那个。
安装同样简单:clawdhub install my-skill。默认装最新版,加 --version 1.2.3 锁定特定版本。安装目录默认是当前目录下的 ./skills 文件夹,用 --dir 可以改。这个默认行为很务实——大多数 Skill 是跟项目绑定的,版本锁定能防止上游更新突然破坏你的 workflow。
更新是 ClawdHub CLI 最值得细看的命令。它用 hash 比对本地文件和远程版本,而不是简单看版本号字符串。clawdhub update my-skill 会先检查你本地的 Skill 文件有没有被修改过,然后找到对应的远程版本,再决定要不要升级。如果你改过 Skill 的源码(很多团队会 fork 后改),它不会傻傻覆盖你的修改,而是提示冲突。批量更新用 clawdhub update --all,配合 --no-input --force 可以用在 CI 里做全自动升级。这个设计思路很清晰——它把你当成了一个”可能有自己修改”的用户,而不是一个只会被动接收更新的消费者。
发布是体验闭环的最后一环。clawdhub publish ./my-skill --slug my-skill --name "My Skill" --version 1.2.0 --changelog "Fixes + docs",所有参数一次传完。这跟 npm publish 的交互式流程不太一样,它偏向声明式的批处理风格,更适合脚本化和 CI 集成。
整条链路走下来,最直观的感受是:这个 CLI 没有试图教你做事。它把每一步都设计成可独立执行的原子操作,组合和编排的权力完全留给使用者。
关键设计
ClawdHub CLI 的设计有几个决策值得深挖。它们表面上看只是技术实现问题,实际上决定了这个工具在生态中的角色定位。
最核心的取舍:零配置 vs 可配置。默认注册表指向 clawdhub.com,默认安装目录是 ./skills,装上去就能用。但你随时可以通过环境变量 CLAWDHUB_REGISTRY 切到私有注册表,用 --dir 改安装路径。这个设计平衡了两类用户——个人开发者开箱即用,企业团队有完全的自定义空间。没走”全配置 yaml 文件”的路线,也没走”完全零配置”的另一端,刚好卡在中间。
更新机制的 hash 比对是另一个亮点。大多数包管理器用版本号比对来决定升级策略,但 ClawdHub CLI 额外做了文件 hash。这意味着即使你本地改了一个 Skill 的 SKILL.md,工具也能察觉。它的处理方式不是暴力覆盖,也不是拒绝升级,而是提示冲突然后给你选择。这个细节说明 steipete 在设计时考虑的不是”干净的环境”,而是”真实用户的环境”——有自定义、有 hack、有多台机器之间不同步。这种脏数据容忍度,是区分”演示用工具”和”生产用工具”的关键分界线。
不过也有明显可以改进的地方。publish 命令的参数是长长的一串 flags,没有交互式引导,也没有 clawdhub init 这样的脚手架命令帮你生成默认的 SKILL.md 模板。对比 npm 的 npm init 和 npm publish 的引导体验,ClawdHub CLI 对第一次发布 Skill 的新手确实不太友好。另外 search 命令目前不支持按下载量排序或按分类过滤,结果多了之后得靠肉眼筛选,这在实际使用中会是一个高频痛点。
使用场景
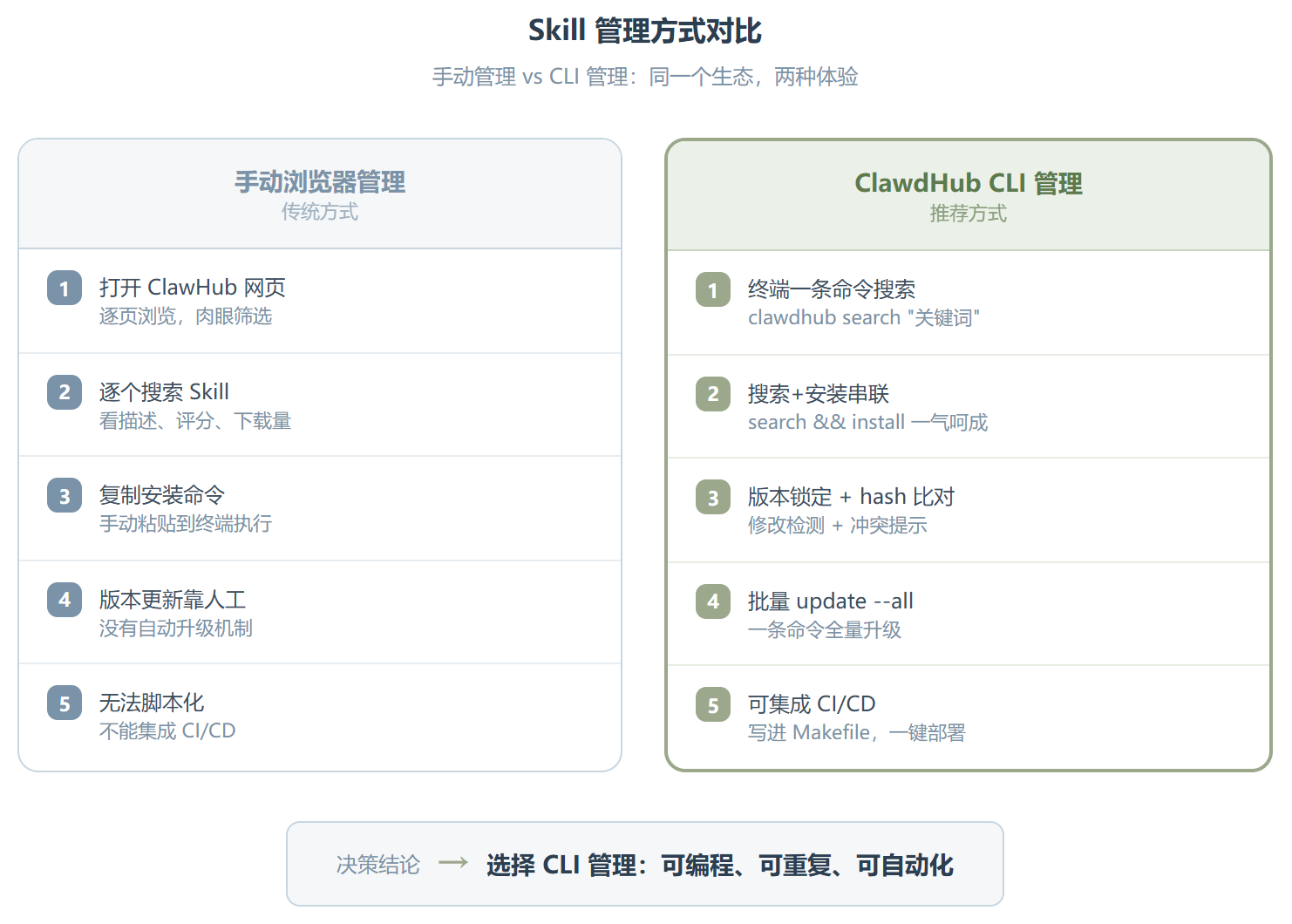
找 Skill 的日常体验是这样的:你在做一个自动化流程,中途发现少一个环节。可能是想在 CI 结束后自动发 Slack 通知,可能是想批量处理 PDF 文档。以前你得上 ClawHub 网站搜索,看描述、看评分、看下载量,找到合适的之后复制安装命令,再跑回终端执行。
有了 CLI 之后这整个流程缩成了一条命令:
clawdhub search "slack notify" && clawdhub install <matched-slug>
另一类用户是 Skill 作者。假设你维护了三个 Skill,每个有 2-3 个版本在跑。当其中一个 Skill 的依赖(比如某个 API 的 endpoint)变了,你需要通知用户升级。没有 CLI 的时候,你只能在 GitHub Release 页发通知,指望用户看到。有了 ClawdHub CLI 的 publish + 版本管理机制,你的用户只需要 clawdhub update --all,工具自动判断哪些 Skill 该升级、哪些不该。
最容易被忽略但价值最高的场景是自动化流水线。你的团队可能在多台机器上部署 Agent 实例,每台机器需要相同的 Skill 集合。把安装命令写进脚本:
clawdhub install my-org/security-audit
clawdhub install my-org/code-reviewer
clawdhub install my-org/slack-reporter --version 2.1.0
然后用 clawdhub update --all --no-input --force 做定期全量升级。这比手动 ssh 到每台机器上敲命令靠谱得多。而且因为版本是锁定的,你可以先在 staging 环境验证新版本,确认没问题之后再统一 push 到 production。
把 CLI 管理方式和传统的手动管理方式放在一起看,差距更明显。
洞察与反思
ClawHub 生态的结构让我想到早期 npm 的处境。2010 年的 npm 只有几百个包,没有人觉得需要 npm publish 之外的任何东西。但到了 2013 年,包数量从几百跳到几万,一套 CLI 工具链就成了必需品。Clawdhub CLI 现在的处境类似——37k 下载量,在接近 6000 个 Skill 的生态里排在第 72 位,不算高。但这不是因为它不重要,而是因为多数人还没意识到它重要。
我个人觉得最有意思的地方在于,ClawdB CLI 给这个生态带来的不仅是效率提升,而是一种”可编程性”。有了 CLI 之后,Skill 管理这件事可以被写进 Makefile、被放进 CI pipeline、被集成到自定义的管理面板里。它在做的事情本质上跟 apt、brew、npm 一样——把一个生态从”人肉操作”升级为”自动化基础设施”。
这里也有一个值得警惕的信号。Clawdhub CLI 目前是 steipete 独立维护的,社区贡献不算活跃。如果有一天 steipete 不维护了,或者 ClawdHub 的 API 发生了不兼容变更,整个依赖这条工具链的自动化流程就会出问题。这不是在说它一定会发生,而是在说它作为一个基础设施层工具,社区参与度还远远不够。npm 当年靠的是整个 Node 社区的集体维护才活到今天,ClawdHub CLI 能不能走上同样的路,决定了它的天花板在哪。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub 页面 | https://clawhub.ai/steipete/clawdhub |
| ClawdHub | https://clawdhub.com |
总结
ClawdHub CLI 解决的问题很具体:在一个 6000 个 Skill 的生态里,把搜索、安装、更新、发布这四件事从网页操作变成终端命令。但它真正有价值的地方在于,给整个 Skill 生态注入了一层可编程的基础设施。
37k 的下载量在这个生态里不算惊艳,但它解决的是”怎样让这个生态规模化运转”的问题,而不是”怎样再多装一个 Skill”的问题。这两者的区别,就像问”怎样再多装一个 npm 包”和”npm 这个工具本身怎么设计”,完全不是一个层面的问题。
如果你已经在日常工作中依赖 ClawHub 上的 Skill,花五分钟装一下 ClawdB CLI,然后写一行 clawdhub update --all 放进你的日常检查脚本。这件事值得做,理由不是因为它是 steipete 写的,而是因为它让你的 Skill 集合从一个静态的快照变成了一个可维护的系统。