
大多数人对 AI 学术工具的理解,还停在”帮我把这段中文翻成英文”这个层面。不能说错,但确实把这件事想小了。
nature-skills 做的事情完全不在这个维度。它把从读论文、做图、写稿、润色、审稿、回复审稿人、生成文献汇报 PPT、甚至论文转专利,这一整套学术发表流程,全部封装成了可独立调用也能串联协作的 Skill。
11 个 Skill,504 次 commit,一个半月两万颗 GitHub Star。更值得关注的是,Google DeepMind 已经明确表示参考了它的设计哲学,推出了自己的 Science-skills。一个中国开发者做的开源项目,被全球顶级 AI 实验室当作设计参考,这件事本身的信息量就不小。
说真的,这篇文章不想跟你讲太多概念。我就是把拆完这套 Skill 之后的想法整理了一遍。它的架构是怎么设计的,11 个 Skill 之间怎么协作,哪些地方做得漂亮,哪些地方还有明显的问题。如果你也在设计自己的 Skill 体系,或者正在考虑怎么把学术工作流 AI 化,应该能找到点有用的东西。
架构解析
nature-skills 的目录结构看一眼就能理解它的设计思路。skills/ 下面每个 nature-<topic>/ 是一个独立 Skill,各自包含 SKILL.md(触发后由 AI Agent 加载的核心规则)、README.md(面向人的说明文档),复杂的 Skill 还有 references/(模块化规则文件)和 manifest.yaml(路由式 Skill 专用)。
最关键的共享层是 skills/_shared/。这个目录的存在说明设计者意识到了一个问题:11 个 Skill 如果各自维护一套引用格式、配色方案、输出模板,不仅冗余,而且一旦要改就会牵一发动全身。统一抽取共享内容之后,单个 Skill 的体积明显瘦了,维护成本也低得多。这是一个很务实的工程决策。
每个 Skill 被标为 Draft、Beta 或 Stable 三种状态,不是随便标的。从文档表述来看,Draft 意味着规则已定义但未在真实论文上测试过,Beta 是在示例上跑通了但边界情况还可能出问题,Stable 是经过真实学术内容验证的。这个三级体系本质上是一个质量标准,让使用者不用读源码就能判断每个 Skill 的可靠程度。
部分 Skill(如 nature-figure、nature-polishing)使用了路由式设计,通过 manifest.yaml 定义了不同场景下的行为分支。以 nature-figure 为例,它不是一个”画所有图的 Skill”,而是根据用户说的是”想做投稿级图片”“想用 figures4papers demo”还是”想做特定图表类型”,路由到不同的子规则集。这种设计比一个巨大的单一 Skill 灵活得多,也避免了 Prompt 过长导致的注意力分散。
五条共享设计原则也值得拆开看。优先使用一手来源意味着规则基于已发表的 Nature 内容和官方期刊指南,不是泛泛的审美偏好。显式胜过隐式要求每条规则说明理由。输出优先强制每个 Skill 返回可直接使用的产物,而不是给一堆建议让你自己整理。

工作流分析
从架构层面看,11 个 Skill 不是随机堆在一起的。如果你把它们按学术发表的时间线排列,一条完整的流水线就出来了:nature-reader 先把论文转成结构化 Markdown,nature-writing 起草手稿,nature-figure 生成投稿级图表,nature-polishing 润色为 Nature 风格英文,nature-citation 检索 CNS 系列支撑文献,nature-data 准备数据可用性声明,nature-reviewer 模拟审稿人视角评审,nature-response 起草逐点回复信。
这条流水线的妙处在于,每个环节的输出刚好是下一环节的输入。nature-reader 生成的结构化 Markdown 可以直接喂给 nature-writing 做草稿起草,nature-writing 输出的手稿章节又能被 nature-polishing 自动检测并润色。这种”数据格式兼容”的设计看起来简单,但如果没有在架构层面做统一的输出规范,根本做不到。
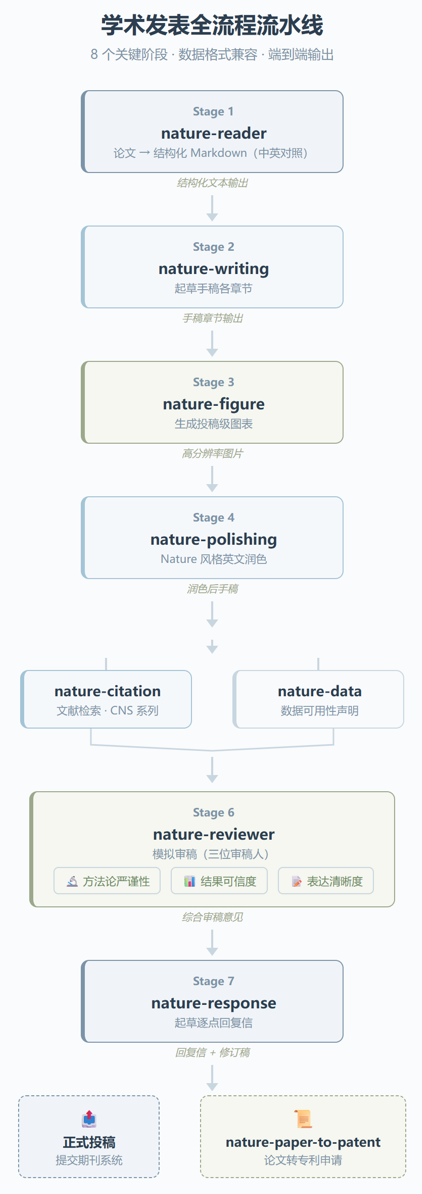
nature-reviewer 的设计尤其有意思。它不是简单地”帮你看一遍论文”,而是模拟了三位不同侧重点的审稿人。从文档描述看,一个侧重方法论严谨性,一个侧重结果可信度,一个侧重表达清晰度。三位审稿人各自输出一份独立的 reviewer report,再合成一份综合意见。这个设计直接对应了真实投稿场景中多位审稿人给出不同意见的情况。
不过也要说清楚,这套流水线目前更多是一种”理念上的串联”而非引擎级的集成。11 个 Skill 在代码层面是独立的,它们之间的衔接依赖用户手动传递输出。也就是说,你跑完 nature-writing 之后,需要自己把结果告诉 nature-polishing。这在当前阶段可以理解,Skill 的耦合度越低越容易独立迭代,但长远来看,如果有一条官方的编排层做自动传递,体验会好很多。
nature-academic-search 是另一个值得注意的节点。它不只是检索文献,还承担了”引用核验”的角色。从触发词来看,你可以让它 verify DOI 或查文献,它会多源交叉验证,确保引用的文献真实存在且信息准确。这个功能在其他学术 AI 工具里很少见到,但恰恰是投稿前最容易出问题的环节。引用造假或引用错误被审稿人发现,轻则大修,重则直接拒稿。
使用场景
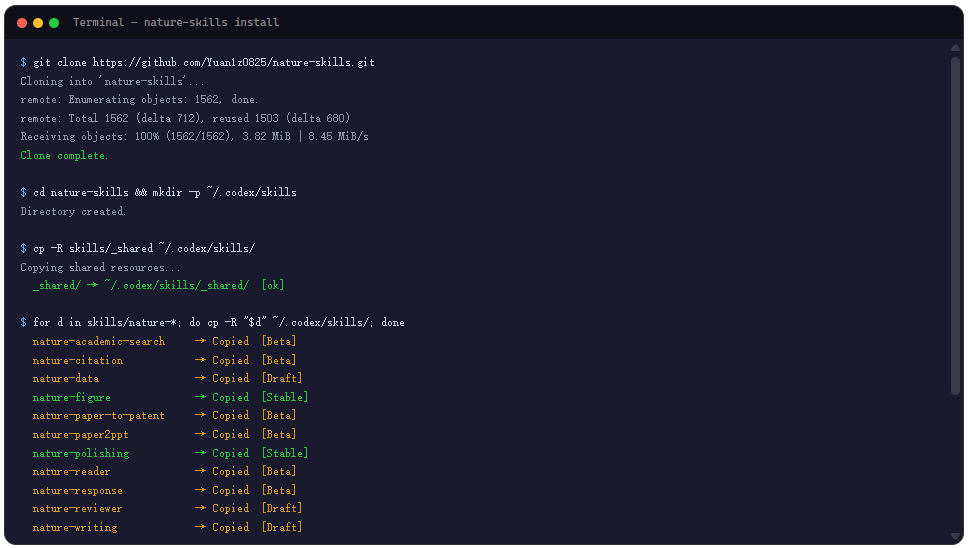
安装方式本身就是对设计理念的一次验证。推荐做法是把 GitHub 仓库链接直接交给 Codex,告诉它”安装 skills/ 下的全部技能,包括 _shared”。Codex 会自动识别每个 Skill 的 SKILL.md、manifest.yaml 和依赖的共享文件,完成完整安装。这个过程不需要用户手动复制粘贴任何一个文件。对于那些手动安装的场景,也提供了一键 bash 脚本,clone 仓库后自动复制到 Codex 的 skills 目录。
一个真实的科研场景是这样的:你刚读完一篇 CNS 子刊的相关论文,需要在下周的组会上做文献汇报。传统做法是花 2 到 3 小时读论文、做笔记、做 PPT。用 nature-skills 的话,先让 nature-reader 生成中英文对照的结构化 Markdown,再让 nature-paper2ppt 直接生成 PPTX 文献汇报 deck。从文档和社区反馈来看,这个流程可以把准备时间压缩到半小时以内。
另一个高频场景是投稿前的质量自检。论文写完之后,多数人会发给导师或同事审一遍,但别人的时间总是有限的。nature-reviewer 可以充当第一轮审稿人,从三个维度给出结构化的评审意见。虽然它不能替代真实审稿人的领域判断,但至少在方法论逻辑漏洞、图表标注完整性、引用格式一致性这些可以通过规则检查的问题上,比人眼更可靠。
边界也很清楚。nature-skills 目前深度绑定 Codex 生态,官方文档明确写了非 Codex 场景需要自行适配 frontmatter 和正文结构。对 Claude Code 用户来说,需要多做一步格式转换。而且 11 个 Skill 中只有 3 个标了 Stable,剩下大部分是 Beta 或 Draft,在真实论文投稿场景下使用需要额外的质量把控。
洞察与反思
拆完 nature-skills 之后,我最深的感受是它的设计思路和大多数 AI 工具不一样。市面上主流的学术 AI 工具走的是功能集成路线,把所有能力塞进一个界面。nature-skills 反其道而行之,用 Skill 的模块化设计把功能拆开,但通过共享资源和统一的输出规范保证协作。这很像软件工程里从单体应用到微服务的演进。说到这里,可能跟你预期的方向不太一样。
Google DeepMind 参考 nature-skills 推出 Science-skills 这件事,是一个很值得玩味的信号。一个大厂实验室选择以开源社区项目为设计参考,而不是自己从零设计一套体系,说明 nature-skills 在 Skill 工程化这个方向上的探索已经得到了顶级研究机构的认可。但这同时也意味着,学术 Skill 这个赛道可能很快就会进入平台级竞争。
nature-skills 最大的局限不在技术层面,在生态层面。它目前完全绑定 Codex,11 个 Skill 的触发词、路由逻辑、输出格式都是围绕 Codex 的 Agent 行为模式设计的。如果换个 Agent 平台,迁移成本不小。另外,Draft 和 Beta 状态的 Skill 占比超过 70%,这意味着目前在真实论文投稿中使用这套工具仍有相当的风险。
不过换个角度看,nature-skills 的真正价值可能不在于 11 个具体的 Skill。它悄悄推开了一扇门:让很多科研工作者第一次意识到,原来可以用 AI Agent 来操控本地电脑做科研。当一个博士生发现他不用再手动调整 matplotlib 参数到凌晨两点、不用再逐条手动格式化参考文献、不用再对着审稿意见发愁怎么组织回复语言的时候,他已经回不去了。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/Yuan1z0825/nature-skills |
总结
回头看 nature-skills 的整体设计,它的核心判断其实很简单:学术发表的每一个环节都是可标准化的流程,而标准化的流程恰好可以封装成可复用的 Skill。这个判断本身不复杂,但真正把它落地成 11 个可以协同工作的 Skill、配上共享资源层和三级质量体系、并且让 Google DeepMind 都来参考,需要的是工程执行力和对学术工作流的深度理解。
这引出了一个更值得讨论的问题。如果这种模块化 Skill 的思路继续发展下去,未来的学术出版会变成什么样?审稿人会不会逐渐适应与 AI 润色过的稿件打交道,从而抬高发表门槛?期刊编辑是否会要求作者声明使用了哪些 AI Skill?当所有人都在用类似工具的时候,差异化从哪来?这些问题目前没有答案,但已经开始浮出水面。
这可能是整件事里最值得关注的地方。不是 nature-skills 本身有多好用,而是它代表的方向正在改变学术工作的基本假设。当”做研究”这件事的很多环节可以被 AI Skill 标准化之后,真正稀缺的东西就不再是执行能力,而是提出好问题的能力。你打算问什么?这才是接下来最关键的竞争力。