
做 AI 视频这事,最烦的从来不是写提示词,而是模型太多、入口太散。Veo 在谷歌那套体系里,Seedance 是字节的,Wan 来自阿里和 fal,每家的 API 风格、鉴权方式、参数命名全不一样。你想横向比一比哪个效果好,光是把环境配齐就够喝一壶。
inference.sh 的这个 ai-video-generation Skill,想解决的正是这个碎片化问题。它的定位很直接:一个 Skill,把 40 多个视频模型塞进同一个命令行入口。不管你要 Veo 3.1 还是 HappyHorse,调用方式都是同一句 belt app run。
这篇文章会带你走一遍它的完整用法。从装 CLI、登录,到第一条生成命令,再到文本生视频、图片生视频、数字人对口型这些不同场景该挑哪个模型。读完你大概能判断出:这种”聚合层”设计到底是省事,还是只是把复杂度挪了个地方。
先说清楚一点,这个 Skill 本身不跑模型。它是个翻译层,把你的自然语言意图变成规范的 belt 命令,真正的推理发生在 inference.sh 的云端。这个边界,后面会反复提到。
环境准备
用它之前,你需要 inference.sh 的命令行工具,名字叫 belt。Skill 的 frontmatter 里写得很死,allowed-tools: Bash(belt *),意思是它只被授权执行 belt 开头的命令,别的一概不碰。这个约束本身就说明了它的设计意图:薄、专一、不越界。
安装方式有两条路。如果你用 Claude Code,直接装插件最省事;如果你只想要这一个能力,单独拉这个 Skill 也行。两种方式的命令如下:
# 方式一:作为 Claude Code 插件安装全部 skill
/plugin install inference-sh
# 方式二:只装视频生成这一个 skill
npx skills add inference-sh/skills@ai-video-generation
装完 Skill 还不够,belt CLI 是单独的依赖,得按官方 cli-install 文档单独装。装好之后第一件事是登录,否则任何 belt app run 都会因为没有凭证而失败。
belt login
这里有个容易被忽略的卡点。belt 走的是云端推理,登录绑定的是你 inference.sh 账户的额度。也就是说,环境就绪不等于能免费跑。生成视频是要消耗账户余额的,这点和本地部署的开源模型完全是两种逻辑,心里要先有数。
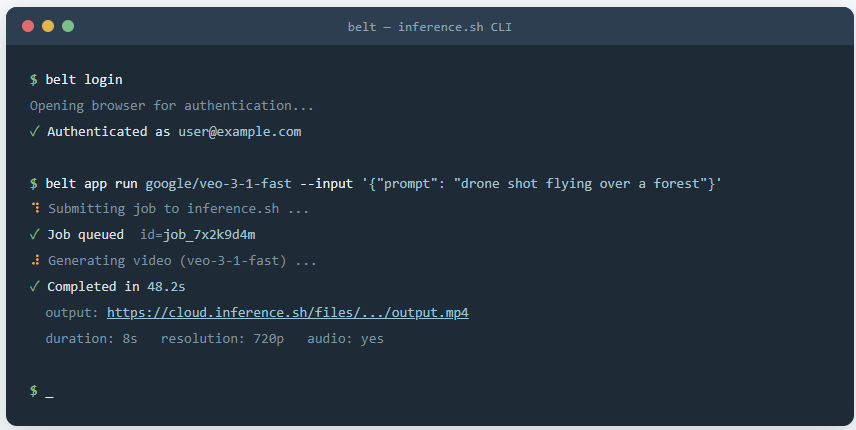
操作流程
跑通一个视频,核心就一句话的结构:belt app run <模型ID> --input '<JSON 参数>'。模型 ID 决定调哪个模型,JSON 参数决定生成什么。把这两块拆明白,整个 Skill 你就掌握了七成。

最基础的文本生视频,拿 Veo 3.1 Fast 举例,只给一个 prompt 就能跑:
belt app run google/veo-3-1-fast --input '{"prompt": "drone shot flying over a forest"}'
想要更多控制,就往 JSON 里加字段。比如 Grok 的视频模型支持自定义时长,加个 duration 就行。不同模型支持的参数不一样,这是用这个 Skill 时最大的认知负担来源,后面会专门讲。
belt app run xai/grok-imagine-video --input '{
"prompt": "Waves crashing on a beach at sunset",
"duration": 5
}'
图片生视频的逻辑也一样,只是把 prompt 换成图片地址。值得留意的是参数名在不同模型间并不统一,有的叫 image_url,有的就叫 image。这个不一致后面是要吃亏的,先记住这个坑。
belt app run falai/wan-2-5 --input '{"image_url": "https://your-image.jpg"}'
如果不知道有哪些视频模型可选,不用去翻文档,belt 自带商店。一条命令列出全部视频类应用,这是我觉得这个 Skill 最实用的辅助设计之一,省去了记一长串模型 ID 的负担。
belt app store --category video
关键设计
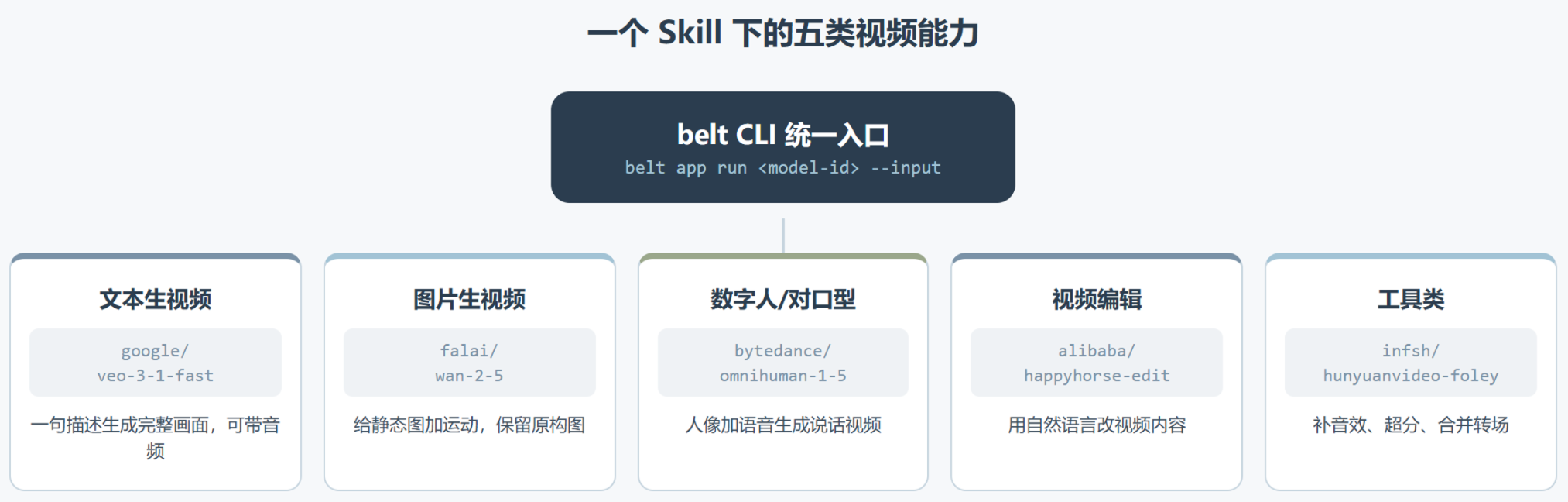
这个 Skill 最值得拆的,是它的”聚合层”设计哲学。它没有给每个模型封装一套复杂的工具函数,而是反过来,把所有模型统一成 belt app run + JSON 这一个极简接口。从 SKILL.md 的结构看,它把模型按能力切成了五类:文本生视频、图片生视频、数字人对口型、视频编辑、工具类。
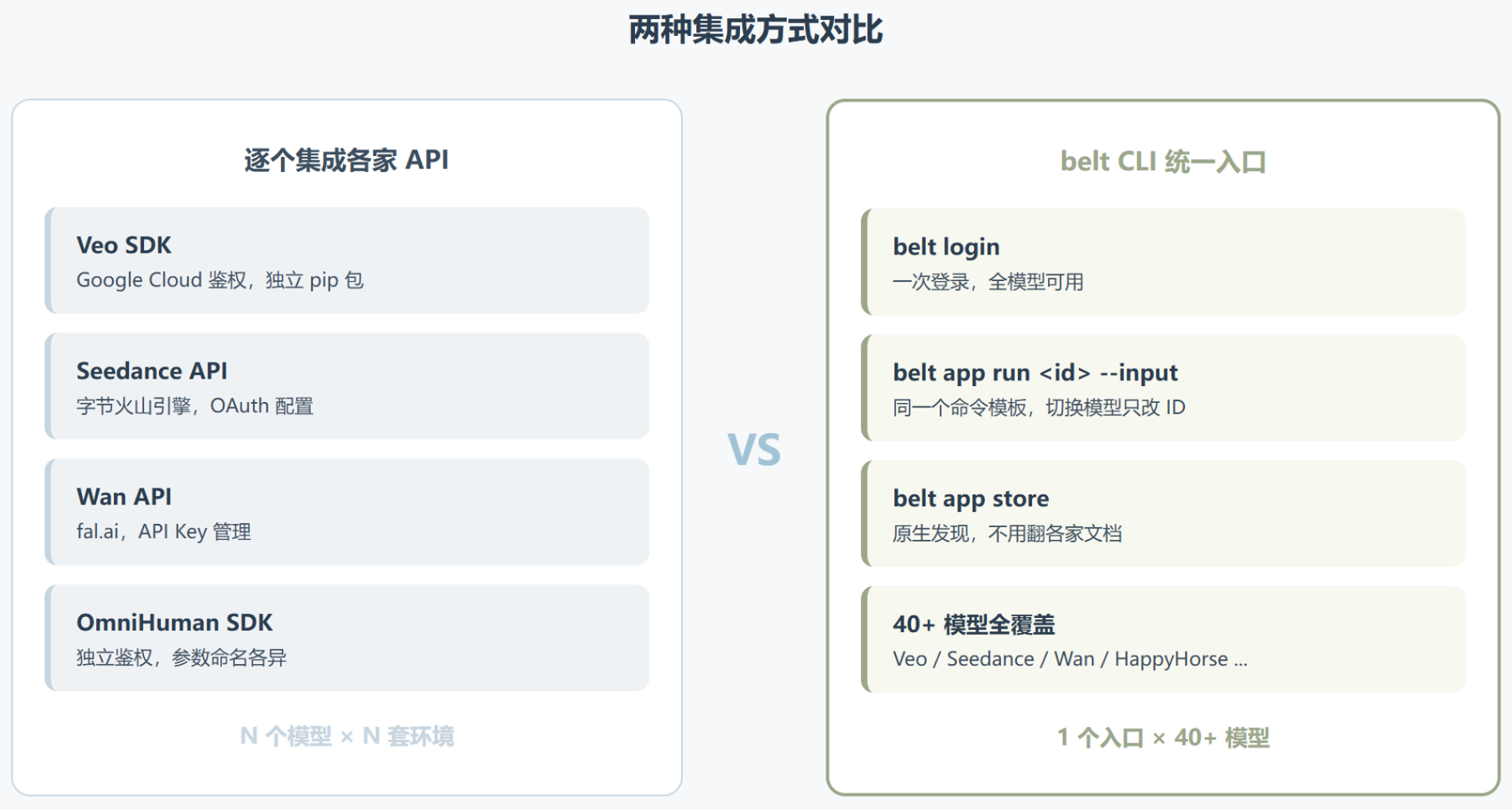
这种设计的好处显而易见。你学一次调用方式,就能用上全部 40 多个模型,横向对比的成本被压到了最低。同一段 prompt,换个模型 ID 就能在 Veo 和 Seedance 之间切换,这种切换成本在传统的多 SDK 方案里是不可想象的。
但代价也很实在。统一了”怎么调用”,却没法统一”调用什么”。每个模型的 --input 字段是各家自己定的,时长范围、分辨率选项、有没有音频生成,全得查具体 app。Skill 文档里给了一堆示例,本质上就是在替你记这些差异,但它没法消除差异。
我个人觉得,这个 trade-off 是诚实的。它没装作能抹平所有模型的差异,而是老老实实把差异以”示例清单”的形式摊开给你看。比 Seedance 2.0 用 generate_audio 控制音频、HappyHorse 用 resolution 指定 1080P,这些细节它都列了出来。聚合层能做的就到这里,再往上抽象反而会失真。
还有个藏在 description 字段里的设计值得一提。它把 veo、sora alternative、runway alternative、pika、kling 这些触发词几乎塞满了整段描述。这不是堆关键词凑数,而是为了让 Agent 在用户说”帮我做个视频”时能准确命中这个 Skill。对一个给 AI 用的 Skill 来说,被正确触发本身就是核心能力。
使用场景
光看命令容易懵,挑几个真实场景串一下就清楚了。最直接的是社交媒体短视频,文本生视频配上音频一步到位。Seedance 2.0 在这个场景里挺有代表性,它支持文本、图片、参考图三种输入,还能同步生成音频。
belt app run bytedance/seedance-2-0 --input '{
"prompt": "a jazz band performing in a dimly lit club",
"generate_audio": true,
"duration": 10
}'
第二个高频场景是数字人和对口型。你有一张人像照片加一段语音,想让照片里的人开口说话。这类需求对应的是 OmniHuman 和 Fabric 这几个模型,参数也很直白,给图给音频就行。
belt app run bytedance/omnihuman-1-5 --input '{
"image_url": "https://portrait.jpg",
"audio_url": "https://speech.mp3"
}'
不同输入会带来完全不同的产出形态,这也是这个 Skill 覆盖面广的地方。同样是视频生成,文本生视频靠想象力,图片生视频保留构图只加运动,数字人则要求音画同步。下面这张表把五类能力的代表模型和适用场景理了一遍。
| 能力类别 | 代表模型 ID | 最擅长的场景 |
|---|---|---|
| 文本生视频 | google/veo-3-1-fast |
凭一句描述生成完整画面,带音频 |
| 图片生视频 | falai/wan-2-5 |
给静态图加运动,保留原构图 |
| 数字人/对口型 | bytedance/omnihuman-1-5 |
人像加语音生成说话视频 |
| 视频编辑 | alibaba/happyhorse-1-0-video-edit |
用自然语言改视频内容 |
| 工具类 | infsh/hunyuanvideo-foley |
给无声视频补音效、超分、合并 |
它最擅长的边界,是”我知道大概想要什么,但不想为每个模型单独配环境”的快速试验场景。工具类那几个模型尤其有意思,Foley 给视频补音效,Topaz 做超分,Media Merger 加转场拼接,等于把视频后期的几个零碎环节也收进了同一个入口。
洞察与反思
真正用起来后,有个地方和我预期的不太一样。我原以为这种聚合 Skill 的价值在于”功能强大”,跑了一圈才意识到,它的价值其实在于”降低决策成本”。当所有模型都在一个 belt app store --category video 里平铺出来时,选型这件事突然变轻了。
和那些把模型深度封装的方案比,它走的是相反的路。封装型 SDK 给你漂亮的函数签名和类型提示,但每加一个新模型都要重新封一遍。这个 Skill 的薄封装让它能轻松跟上模型的更新速度,新模型上线只要补一行示例就行。代价是你得自己消化参数差异,没有 IDE 帮你补全。
说实话,这点我一开始没太意识到它的分量。对 Agent 场景来说,薄封装反而是优势。Agent 不需要类型提示,它需要的是一个稳定、可预测、覆盖面广的命令模式。belt app run 这种结构对模型来说极其友好,参数就是一段 JSON,没有任何隐藏状态。这可能才是它选择不做重封装的真正原因。
当然它的短板也很清楚。强依赖 inference.sh 的账户和余额,离线场景直接出局;参数不统一意味着你仍然要查文档;它也没在 Skill 层面给出失败重试或异步轮询的明确说明,这些得靠 belt CLI 本身和 streaming 文档去补。它解决了”入口碎片化”,但没解决”参数碎片化”,这个区分很重要。
资源地址
| 资源 | 链接 |
|---|---|
| GitHub 仓库 | https://github.com/inference-sh/skills |
| ai-video-generation Skill | https://github.com/inference-sh/skills/tree/main/tools/video/ai-video-generation |
| 官网 | https://inference.sh |
| 运行应用文档 | https://inference.sh/docs/apps/running |
| CLI 安装说明 | https://raw.githubusercontent.com/inference-sh/skills/refs/heads/main/cli-install.md |
总结
回头看,这个 Skill 的核心就三步:装 belt、belt login、belt app run <模型ID> --input。剩下的全是在五类能力里挑模型、调参数。它把视频生成里最折磨人的”入口碎片化”问题处理得很干净。
它最适合的人,是想快速横向比较多个视频模型、又不愿意为每家单独配环境的人。如果你只盯着一个模型长期深耕,或者需要离线本地推理,这个聚合层对你意义就不大。
想再深入,可以从 belt app store --category video 开始,把每类能力的代表模型各跑一遍,亲手感受 Veo 和 Seedance 在同一段 prompt 下的差异。那种切换成本几乎为零的体验,才是这个 Skill 真正想给你的东西。