
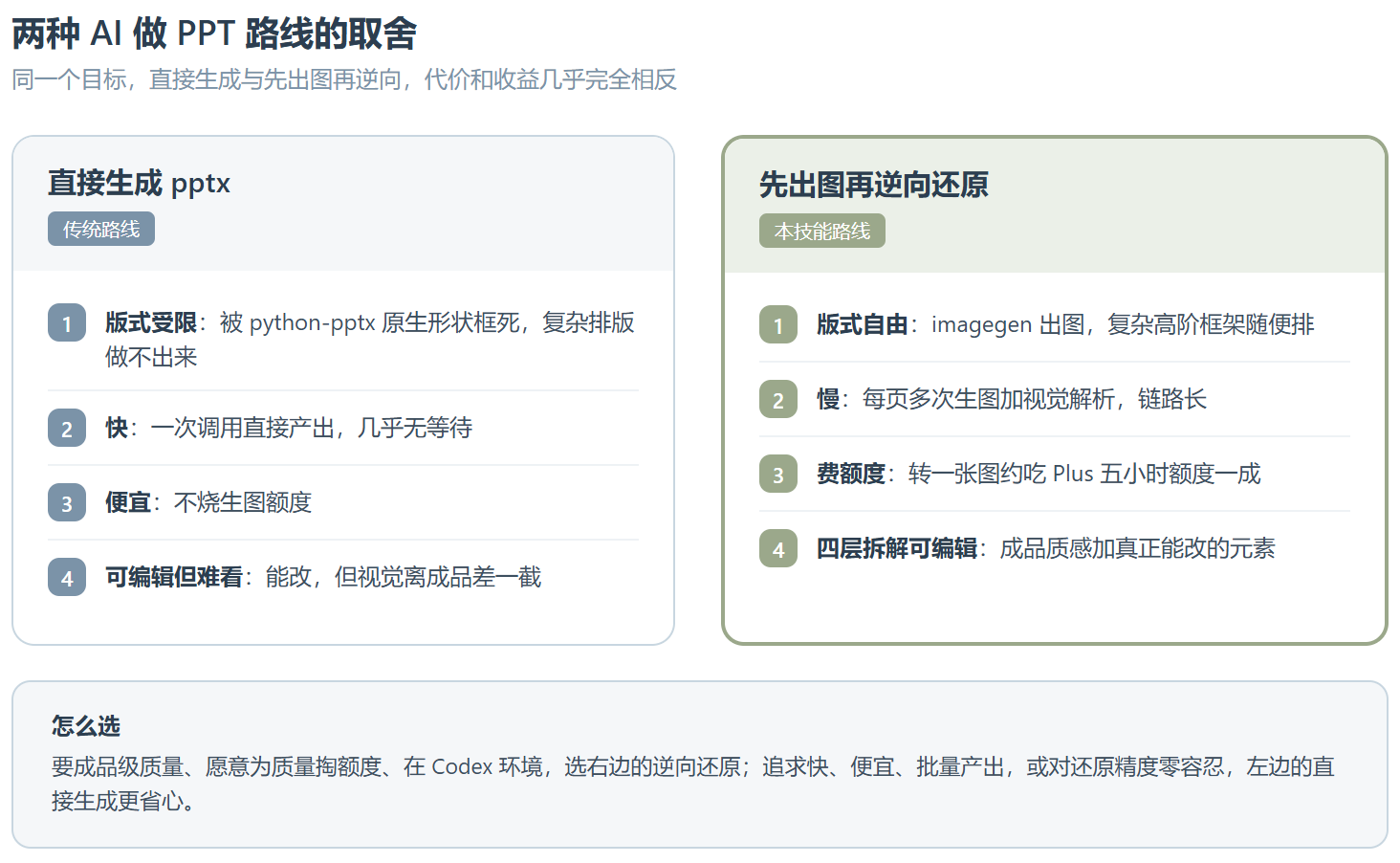
用 AI 做 PPT 这件事,长期卡在一个尴尬的二选一上。你让模型直接吐 pptx,得到的版式往往是几个方块加几行字,排版能力被 python-pptx 那套原生形状死死框住。你让模型去出图,画面是好看了,可那是一张焊死的位图,一个字都改不了。好看和可编辑,像是天生不能同时拥有。
GordenSuperPPTSkill 给的答案有点反常。它是 Gorden Sun 开源的一个 Codex 技能包,准确说不是一个技能,而是三个技能的编排。它没有去硬啃”怎么让 AI 直接排好一份 pptx”这道题,而是把题目本身换了个问法。
它的核心架构思想一句话能说清:先用 imagegen 把每一页画成一张成品图片,把”好看”这件事交给生图模型;再用 GPT 的视觉能力把这张图逆向拆成背景、框架、图标、文字四层,按坐标重新拼回一份可编辑的 pptx。一条路走不通,它就拆成两条路接力跑。
这个设计值得拆开看,不是因为它有多少脚本,而是它绕的这条远路,恰好踩在了当前 AI 能力的长短板分界线上。说实话,这点我一开始完全没意识到,看懂之后才觉得它聪明在哪。
架构解析
先看三个技能怎么分工。最外层的 GordenSuperPPTSkill 是个纯编排层,它自己不画图也不抠图,只负责按顺序把两个子技能跑完。阶段一是 GordenImagePPTGen,专门出图片型 PPT;阶段二是 GordenImage2PPTX,专门把图片转成可编辑 pptx。这种拆分的好处是每一段都能单独拿出来用。
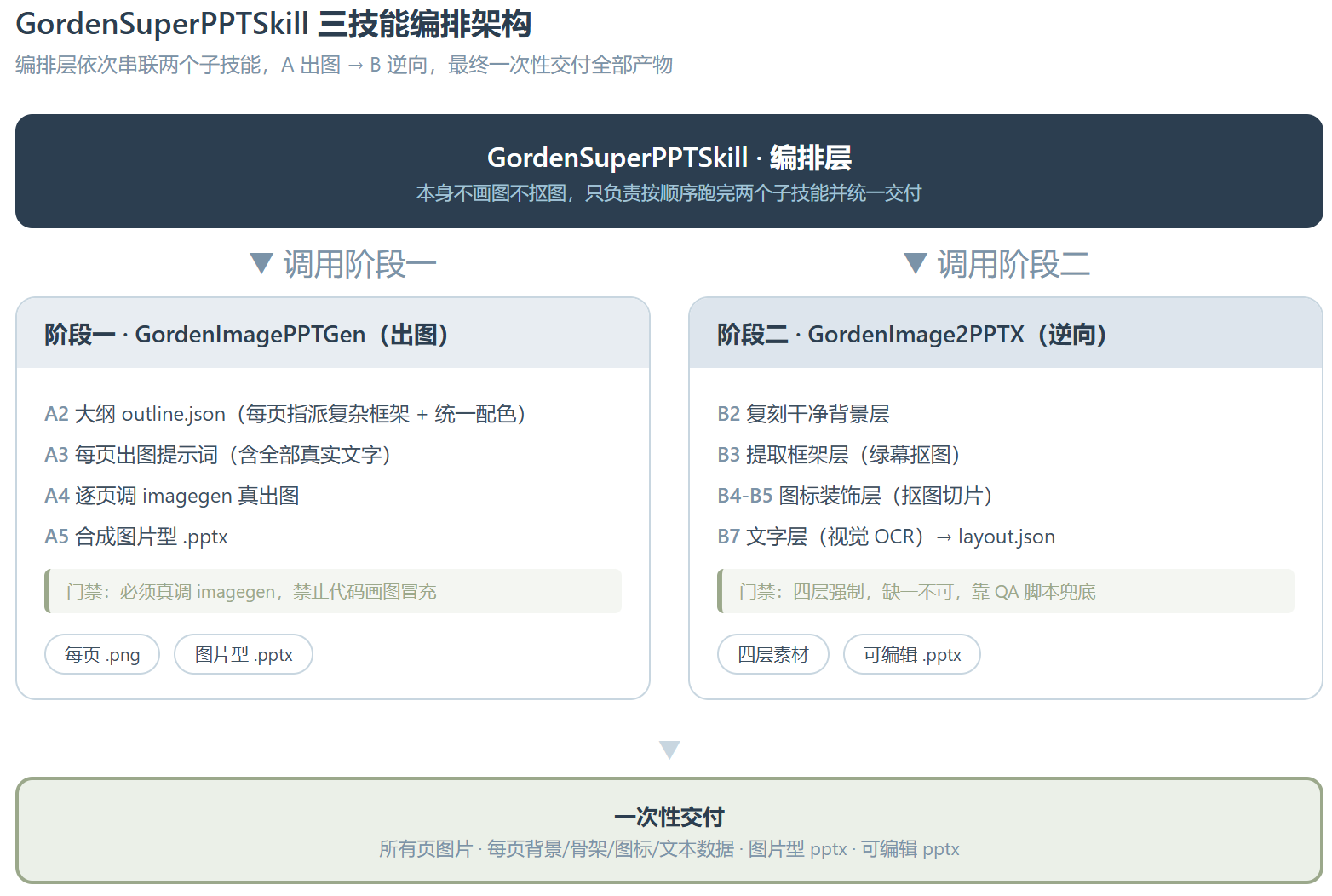
阶段一的活儿是设计加出图。它先把内容解构成大纲 outline.json,给每页指派一个不重复的复杂框架和统一配色,再把大纲落成每页的出图提示词,然后逐页调 imagegen 真的把图生出来,最后合成一份全幅图片型的 pptx。这里有一条铁律:必须真调生图模型,禁止用 PIL、SVG、Canvas、matplotlib 这类代码画图来冒充。
为什么阶段一死磕”出图”不肯”画图”?因为代码画不出 imagegen 那种版式。它默认要的是房子型、莫比乌斯环、便当盒、同心雷达这类高阶框架,每页二十多个信息点,”简单”直接判不合格。这是架构的第一个取舍:吃下生图模型的版式自由度,代价是图里的文字可能出错,留到第二阶段再修。
阶段二才是这套架构最反直觉的地方。一张完整的幻灯片图,信息全叠在一起,要让它变回可编辑,就得先解耦。它强制分四层还原:背景图复刻、整体框架图、元素图标装饰、普通文字。前三层都靠 imagegen 提取式重新生成加绿幕抠图,最后一层文字靠 GPT 视觉直接读出来。

四层为什么非得这么切?因为每一层在 pptx 里是不同的对象。背景是一张底图,框架是可整体移动的透明 png,图标是一个个独立切片,文字是真正能改的文本框。绿幕抠图就是把图形元素从纯色底里抠成透明的手段,默认用纯绿 #00ff00,要是原图本来就有绿就换成品红。而 layout.json 这份坐标契约,保证每个元素拼回去时位置不偏。
工作流分析
把一个请求从头跑一遍,链路是这样的:用户给主题,Super 先读两个子技能的说明,完整跑完阶段一的所有页面,再对每一页跑一遍阶段二,最后一次性把全部产物交出来,包括每页图片、四层素材、图片型 pptx 和可编辑 pptx。编排层只管串联和交付,真正的重活都在两个子技能里。
阶段一内部,大纲是整个质量的地基。outline.json 要给每页指派不重复的复杂框架,定下统一配色,还要把内容写厚,每页至少四个并列模块、二十多个信息点。技能里反复强调内容先于排版,排版显得简单几乎都是因为每页内容太薄,所以”先备厚内容再出图”是硬要求。
这里有个容易被忽略的关卡:阶段一的验收门禁。每页出图都要写进 imagegen-manifest.json,逐条记录模型生成的源图和复制后的路径。只要缺了这份清单,或者任何一页没有 generated_source,阶段一直接判失败,不准进阶段二。这道门就是用来防止模型偷懒用代码画图蒙混过关的。
阶段二的关键路径更长。先探色定下本页的抠图底色,避免和画面撞色,再用三次 imagegen 分别生成背景、框架、图标三层,然后抠图切片、量坐标、读文字,写进 layout.json,最后过坐标契约校验和并排视觉对比。每一步几乎都配了一个 QA 脚本盯着,layout_guard 校验坐标一致性,placement_qa 在源图上画框复核,visual_compare_qa 出差异热图。
性能瓶颈很清楚,就在 imagegen 的调用次数和成本上。光阶段二每页就至少三次生图,加上多轮视觉解析,开销自然下不来。看到这套调用密度的那一刻我意识到,它贵不是偶然,是架构换”无损还原”必然付出的代价。
使用场景
实际用的时候,三个技能是按意图分流的。你只想要图片版就单用出图技能,你手头有别人的 PPT 截图只想转可编辑就单用还原技能,你只给主题要个能用的成品、或者干脆没点名,才走 Super 全流程。
| 用户意图 | 用哪个技能 |
|---|---|
| 做一份图片版 PPT / AI 出图幻灯片 | GordenImagePPTGen |
| 把 PPT 图片或截图转成可编辑 pptx | GordenImage2PPTX |
| 只给主题要成品 / 既要好看又要能编辑 | GordenSuperPPTSkill |
这种拆法对使用体验的影响是双向的。好处是灵活,你能只为自己需要的那一段付费,不必每次都跑全流程。代价是你得理解三者的关系,知道什么时候该用哪个,否则容易把简单需求硬塞进最贵的全链路里。
把两条技术路线摆在一起对比,取舍会更直观。直接生成那条路快也便宜,但版式受限、还原度无从谈起;先出图再逆向这条路慢且贵,换来的是接近成品的视觉质量加上真正可编辑的结果。
约束也得说清楚。它只能在 Codex 跑,因为整条链路依赖 GPT 的生图和视觉能力。它很费额度,转换一张图大约要吃掉 Plus 订阅五小时额度的一成。画面里要少用纯绿,免得和绿幕抠图撞色。数据零编造是底线,逆向过程里 OCR 读错字、抠图边缘误差、坐标精度损失也都真实存在。
洞察与反思
这套架构最让我服气的,是它选择不和”让 AI 直接排好 pptx”这道难题死磕。它很坦然地承认 AI 直接排版的能力就是弱,然后掉头去用 AI 当下最强的两件事,生图和视觉理解,把问题迂回解决。扬长避短四个字,落到架构层面就是这个样子。
更有意思的是那些强制约束是怎么来的。技能文档里反复写”绝不用代码绘图兜底”“绝不跳过骨架图和图标层”,作者直接点明这是上一版退化的根因。这说明四层强制和 manifest 门禁不是设计时就想周全的,而是踩了坑、模型偷过懒之后一道道补上去的护栏。一个技能的约束密度,某种程度上就是它踩坑深度的记录。
当然这条路不是没有软肋。逆向还原本质是概率性的,不是无损的。OCR 会认错字,抠图会丢边缘细节,坐标换算有精度损失,复杂图表那一层还原难度最大。它用一整套 QA 脚本去兜底,并排图、叠图、差异热图轮着核对,但兜得住大部分不等于兜得住全部。对还原精度零容忍的人,这里要打个问号。
抛开 PPT 本身,它给我的启发其实更通用。当某个能力短期内补不上来,与其正面硬刚,不如把问题重新表述成一组你已经擅长的能力的组合。GordenSuperPPTSkill 没发明任何新模型,它只是把”排版难题”翻译成了”生图加视觉还原”,这个问题重构的动作,比任何脚本细节都更值得借鉴。
资源地址
| 资源 | 链接 |
|---|---|
| GitHub 仓库 | https://github.com/GordenSun/GordenSuperPPTSkills |
| 子技能 GordenImagePPTGen | https://github.com/GordenSun/GordenSuperPPTSkills/tree/main/GordenImagePPTGen |
| 子技能 GordenImage2PPTX | https://github.com/GordenSun/GordenSuperPPTSkills/tree/main/GordenImage2PPTX |
总结
回头看 GordenSuperPPTSkill,它真正的价值不在某个抠图脚本或者某份坐标契约,而在那个”先出图再逆向”的问题重构。它把一道 AI 啃不动的排版题,硬生生换成了一道 AI 擅长的生图加视觉还原的组合题,然后用编排把两段接力跑通。
它适合谁也很明确。要成品级视觉质量、愿意为质量掏额度、手里又有 Codex 环境的人,用它能拿到别的方案给不了的东西。反过来,追求快、追求便宜、要批量产出、或者对还原精度零容忍的场景,它并不合适,那条又慢又贵的逆向链路会变成负担。
留一个问题给你。等哪天生图模型能直接吐出结构化的版面数据,连坐标和文本框都一并给出,这条费劲的逆向还原链路,会不会被一步到位地取代掉?如果你也在折腾 AI 做 PPT,不妨想想这个临界点什么时候到。