

锅里水烧开了,你双手都在处理食材。孩子走向了灶台。监控画面里冒出了烟。
这些事情的发生没有先兆,也不会等你掏出手机点开 App。今天的 AI 在面对这种场景时基本帮不上忙,这些模型从设计上就是回合制的:安静地等你召唤,然后回答你刚刚提出的问题。
京东未来研究院 JoyAI-VL 团队认为这不对。他们 6 月 20 日正式开源了一个叫 JoyAI-VL-Interaction 的项目。一个 8B 规模的视觉语言交互模型,附带完整训练配方、400 万条时间对齐交互数据和一个可部署系统。核心逻辑简单到让人意外:像人一样持续看着画面,每秒自己判断该说话、该沉默、还是把难题丢给更强的模型。
他们在 58 个真实场景的盲评中把这个 8B 模型拉去跟豆包和 Gemini 的视频通话功能直接比。结果不只是”能打”,而是”在自己擅长的领域碾压”。这件事的值得聊的程度,远超过它目前 626 个 Star。
但评测数字说不了全部故事。它到底是在哪些场景里领先的,靠什么做到的?
参数比你小,但时机感比你好
JoyAI-VL-Interaction 最让人意外的不是功能列表,而是在特定场景里把两个商业产品按在地上摩擦的评测结果。现在市面上的同类开源方案,比如 LLaVA-OneVision 和 Video-LLaMA 3,它们能做视频理解,但交互能力基本靠外挂框架。一个能把”什么时候开口”训练进模型参数的开放实现,此前不存在。
58 个真实视觉交互场景的人工双盲评判中,它对豆包视频通话功能的综合胜率 77.6%,对 Gemini 的胜率 87.9%。监控与告警、实时计数、实时翻译这三个细分场景,它对两者的胜率都是 100%。豆包背后是字节 Seed 2.0,Gemini 用的是 3.1 Flash Live,两者都经过了多年面向真实用户的产品化打磨。一个 8B 开放模型在这个维度上拿到这种成绩,不靠参数规模,靠的是范式差异。
传统的多模态模型收到一帧画面后回答你的提问然后结束。JoyAI-VL-Interaction 不同:每秒都在做一个自主决策 说话、沉默、委托。这个决策逻辑被训练进了模型参数本身,不是靠外挂规则引擎驱动。换句话说,它的”时机感”是学出来的。
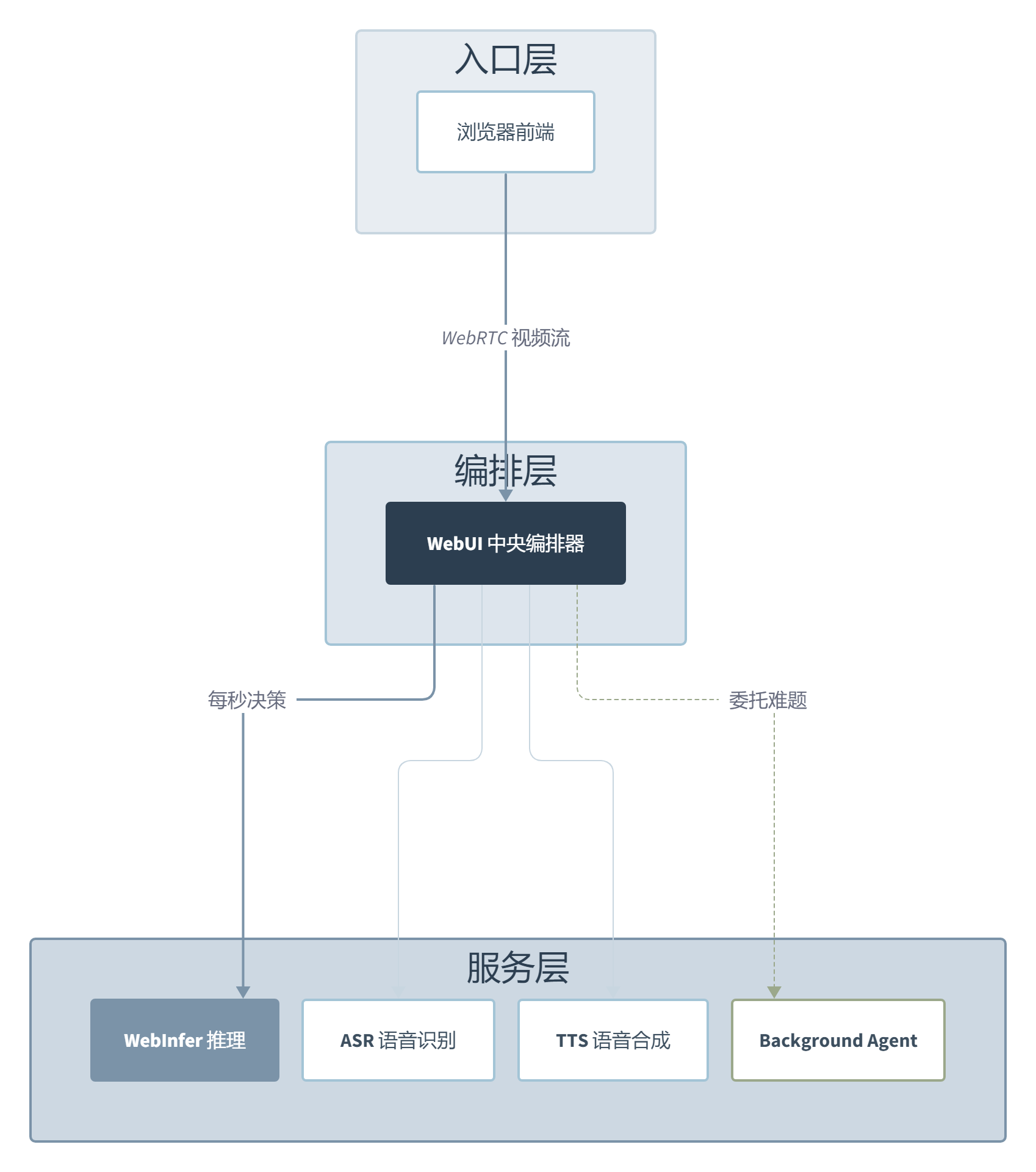
系统架构是 Hub-and-Spoke 模式。WebUI 作为中央编排器,通过 WebRTC 把视频流传给推理服务。ASR 和 TTS 是基于 Qwen3 的可插拔语音模块,Background Agent 负责对接外部 API 或 Agent。模型本身只做一件事:看画面,判断行动时机。团队在知乎上写了一段让人印象深刻的话,“在 4M 数据下就观测到了涌现的能力和适时响应的情商”。这种适时闭嘴、在该出声时才出声的行为模式,是回合制模型不管怎么调 prompt 都做不出来的。
还有一个容易被忽略的细节:预测式视频编码器 AdaCodec。可预测的帧只消耗少量 token,只在场景真正变化时才保留完整细节。长视频流的 token 预算因为这件事变得可控,不然持续看监控画面的成本会高到不可用。
设计听着漂亮,实际部署起来是什么感觉?
跑起来不难,但有几个前提
安装流程不算复杂,但也不是一条 pip install 命令能搞定的事。好消息是整套脚本写得很规整,install.sh 把依赖、环境、CUDA 版本检查全包了。
git clone https://github.com/jd-opensource/JoyAI-VL-Interaction.git
cd JoyAI-VL-Interaction
./install/install.sh --with-all
./install/download-models.sh --all
./services/scripts/run.sh minimal
启动后在浏览器打开 https://127.0.0.1:8099。想启用完整语音交互和后台 Agent 就走 run.sh full。系统依赖 vLLM 做推理后端,跑在 CUDA 12.x 上,目测最低需要一块 24GB 显存的 GPU。
常见的坑有三个,提前知道能省不少时间:
-
模型下载:四个模型加起来体积不小,网速不够建议先单独下交互模型跑 minimal 模式 -
CUDA 版本:系统要求 CUDA 12.x,环境停在 11.8 的需要升级驱动 -
WebRTC HTTPS:浏览器会拒绝在 HTTP 下访问摄像头,README 里的地址是 https,别漏了那个 s
好消息是 vLLM 团队在项目发布当天就给了 day-0 原生支持,部署指南在 vLLM-Omni 的 recipes 目录下。团队在 TODO 里还写了正在做量化版本和 RTX 3090/5090 最优推理配置,等这两项落地后消费级显卡跑这个系统的门槛会大幅降低。
跑得起来是一回事,值不值得你花这个力气是另一回事。
适合谁,不适合谁
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 安防监控与实时告警 | 安防系统集成商 | 视觉触发主动性,检测异常立即报警 | 8B 模型对复杂场景的误报率待验证 |
| 直播解说与内容生产 | 直播运营/游戏主播 | 实时解说、弹幕式评论,不需人工介入 | 开放聊天能力不如商业模型 |
| 实时翻译与辅助 | 跨国会议/教育场景 | 实时翻译准确率高(评测 80%-100%) | 依赖 ASR/TTS 模块的部署复杂度 |
| 交互研究与应用开发 | AI 研究员/产品团队 | 全栈开源,可完全复现和二次开发 | 项目仅 2 周,社区生态几乎为零 |
不适用的情况同样清楚,分四种:
-
你需要一个能陪你聊天的通用 AI 助手:豆包或 Gemini 的综合体验更好,这个 8B 模型在开放域对话、个性化风格、长尾日常请求上跟商业产品有明显差距,团队在论文里坦率承认了 -
你的显存低于 24GB 且不想折腾量化:暂时跑不动完整系统,建议等量化版本出来再试 -
你只想拿它做传统视频理解 VLM:找错方向了,它的价值不在”看得准”,而在”说得对时机” -
你做的是离线的长视频分析(比如纪录片标注):LLaVA-OneVision 或 Video-LLaMA 3 更适合这个场景
判断完场景,还得看一个更现实的问题:这项目有人持续维护吗?
社区还没形成,但关注度不低
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 626(截至 2026.06.25) | 开源 2 周,增长曲线陡峭 |
| Forks | 41 | 部署型项目的合理分叉量 |
| Open Issues | 6 | 项目极新,暂无技术债堆积 |
| 核心维护者 | 14 位署名作者 | 京东 JoyAI-VL 视频理解团队,机构背景稳定 |
| 协议 | Apache 2.0 | 商业友好,无使用限制 |
项目 6 月 11 日创建仓库,6 月 20 日正式开源并发布模型权重。澎湃新闻、凤凰科技、科创板日报等主流科技媒体在两天内集中报道,这种传播密度在一个新开源项目上不多见,后面有京东的开源运营推力。
知乎上的团队自述透露出一个有意思的上下文。Thinking Machines Lab 几乎在同一时期提出了”interaction model”的概念,两边不约而同地在做同一件事。团队的态度很开放,“希望大家和我们一起把 VL 交互性 scaling 上去,一起尝试和探索 interaction model 更多的场景和玩法”。
不过 29 次提交、626 个 Star 的项目还处在极早期。没有 Release,没有 Contributors 指南,Issue 区目前也只有基础性问题。这个项目的社区还没有真正形成,现在关注它的人更多是在围观一个概念验证,不是在使用一个成熟产品。
聊完了这些数据,该说点真的了:这东西到底值不值得跟。
交互模型不是 VLM 的优化,是 VLM 的下一个阶段
要理解 JoyAI-VL-Interaction 真正的价值,得先搞清楚一个问题:交互模型跟传统 VLM 到底差在哪?传统视觉语言模型处理视频时做的是”视频理解”,把视频切片、编码、对内容进行问答。它不关心时间,不关心时机,不需要判断什么时候该开口。交互模型多了一个维度:时机。这个维度是训练出来的,不是靠 prompt 调出来的。
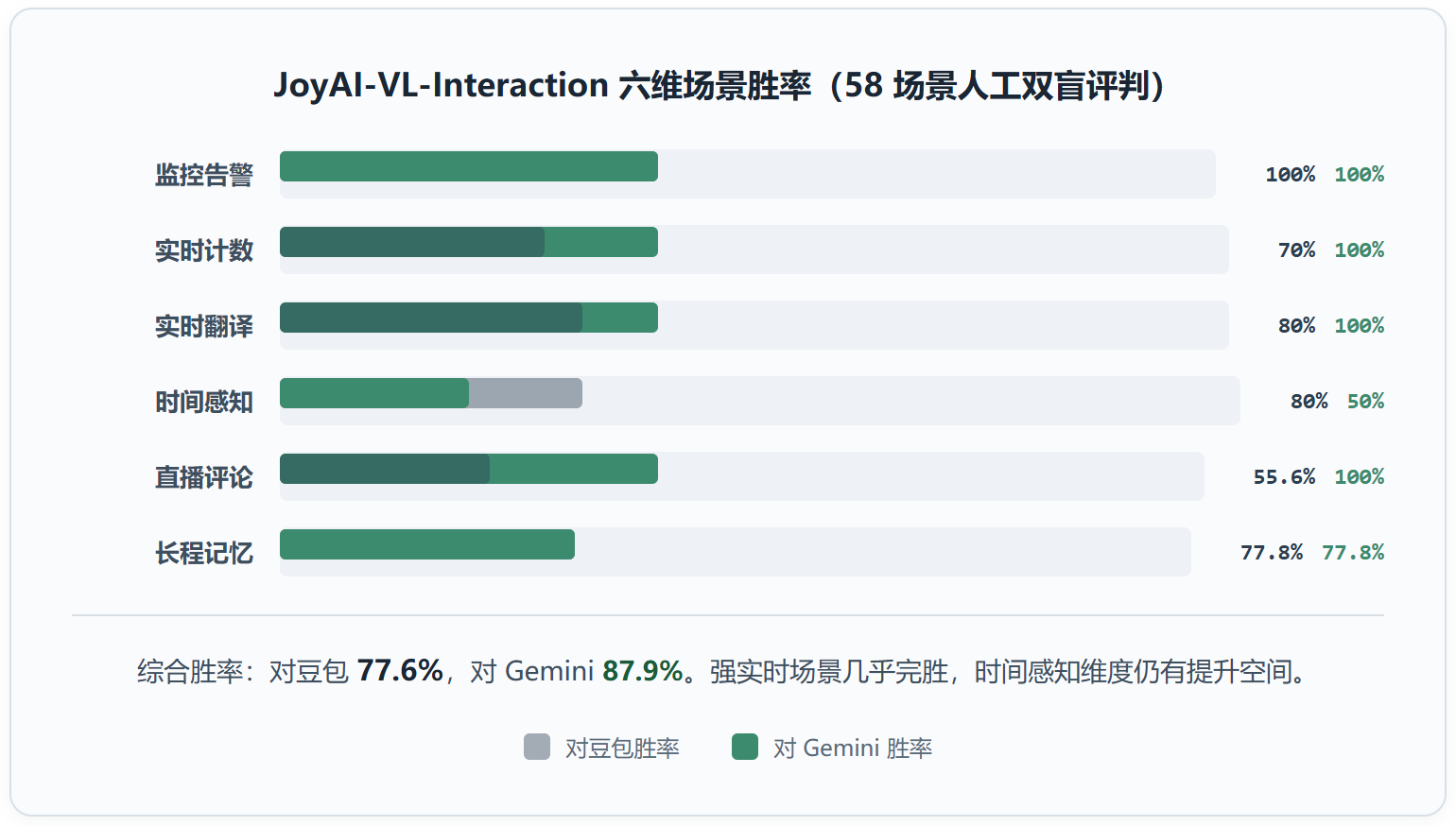
从评测的六个维度看,监控告警、实时计数、实时翻译这些强实时场景里, JoyAI-VL-Interaction 对两个商业产品几乎完胜。但在时间感知和直播评论引导这种需要更强语义理解的场景中,差距在缩小,说明交互模型的”在场能力”和”理解能力”是两条不同的能力曲线。8B 的在场能力已经做到顶级,但理解能力的上限被参数规模锁死了。
我在它的 commit 历史里翻了翻,整个项目的组织方式很务实。五个服务各司其职,推理服务暴露的居然是 OpenAI 兼容 API,意味着你可以用任何支持这个协议的工具对接。Background Agent 已经接了 OpenClaw 和 Claude Code 的桥接,这条”后台 Agent 跑复杂任务、前台模型继续看画面、结果回来再整合进对话”的闭环,是目前整个设计里最有想象空间的一条线。

风险也很透明。8B 的规模注定了它在通用对话和复杂推理上打不过更大的商业模型。但你换个角度想:如果未来半年里,字节或 Google 直接把交互模型架构整合进豆包和 Gemini,这个 8B 的开放模型还剩多少独特性?训练数据只有 400 万条,论文明确写了”继续扩展数据会带来明确收益”,上限还没到。目前没有量化版本、没有消费级显卡配置、没有生态,这些都是你决定要不要跟之前要想好的事。
但这些问题不会阻止交互模型往前走。它的范式优势是结构性的,不是规模性的。就算商业模型把参数做大十倍,只要它们仍然采用回合制,在实时交互的维度上就永远慢一拍。反过来说,如果商业模型开始往交互模型架构迁移,这个 8B 的开放实现就是它们最好的参照系。
资源地址
先看论文,再看要不要部署
如果你在做多模态交互方向的研究,先读论文。arXiv 2606.14777 不长,架构部分讲得很清楚,评测方法论也值得参考。
如果你只是对这个概念感兴趣但没 GPU,关注两个时间点:量化版本发布和消费级显卡配置指南发布。等这两个落地了,从 minimal 模式跑起来,接个摄像头体验那个”每秒决策”的交互闭环。
现在这个时间点直接上生产的人大概率会撞墙。但把核心思路吃透的人,可能会在未来几年持续受益。把交互能力训练进模型参数、让视觉主动性取代外部触发,这条路不是 VLM 的修修补补,是 VLM 的下一个阶段。而一个 8B 的开放模型已经证明:这条路走得通。