

Mimo-v2-Pro & Mimo-v2-Omni
综合场景深度测评报告
数据来源:XSCT Arena | 评测日期:2026-03-19
用例集:16 条跨模型对比(L/W/A 三维覆盖)+ 14 条小米内部对比
基于 XSCT Arena 平台 L(文本理解)/ W(Web 应用生成)/ A(Agentic 任务)三轨全量数据,对标 Mimo-v2-Flash 内部基线,横向比对 Claude Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro。
Judge:Claude 50% · Gemini 30% · Kimi 20%
本报告所有评测数据均由小山基于 XSCT 用例生成。
详细报告请点击查看原文查阅原始数据与评测用例。
一、执行摘要
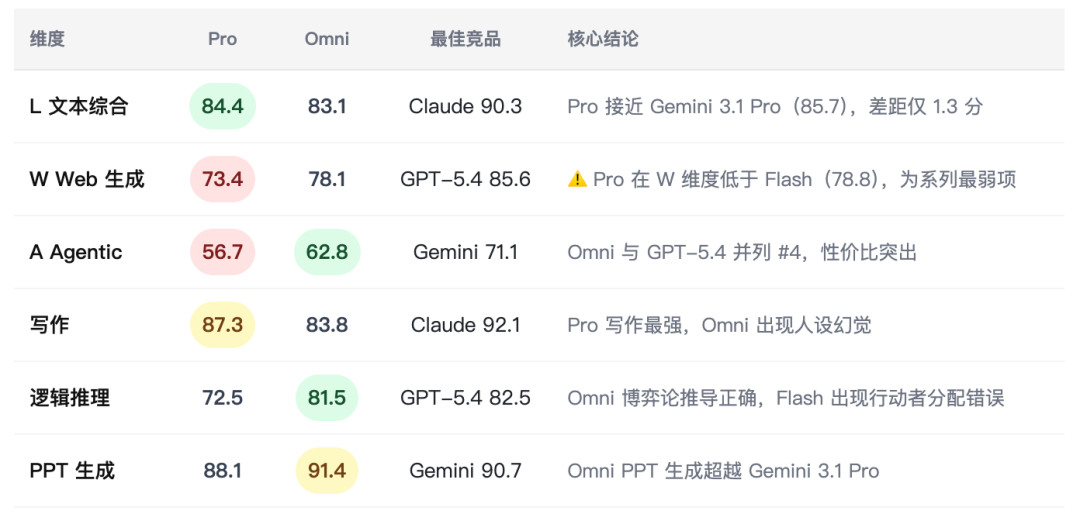
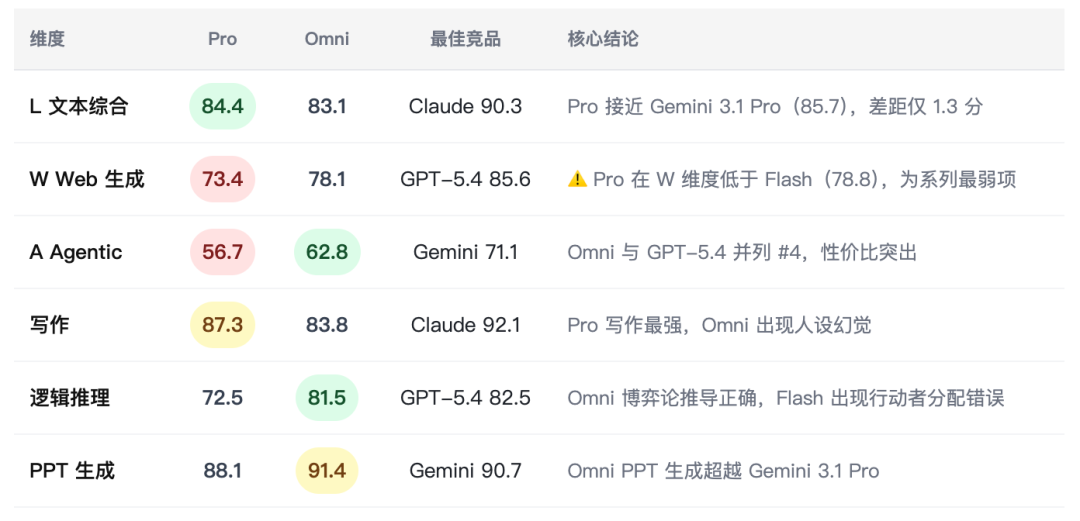
核心结论速览
二、研究背景与方法论
2.1 平台说明
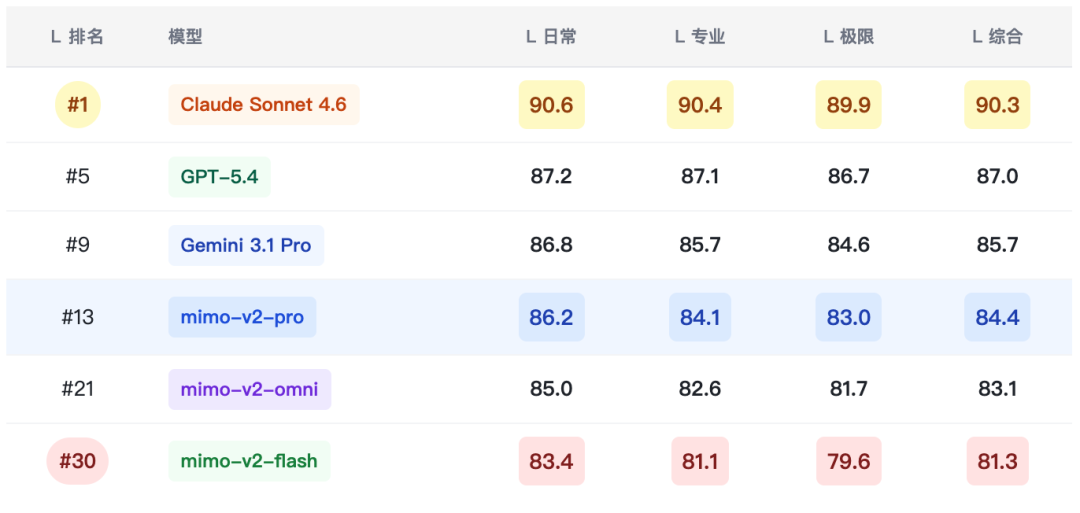
本报告全部数据来自 XSCT Arena 场景化大模型评测平台,评测覆盖文本理解(xsct-l)、Web 应用生成(xsct-w)、Agentic 任务执行(xsct-a)三个维度,每条用例设 Basic / Medium / Hard 三档难度,综合分 = 日常(30%)+ 专业(40%)+ 极限(30%)。
2.2 公平对比原则
-
横向对比仅选所有目标模型均有数据的公平用例集,某模型缺数据则该用例不参与排名 -
每个维度取 ≥3 条用例均分;单用例数据在报告中明确标注用例数量 -
Judge 分差 >15 分时专门说明分歧原因 -
得分差距判断:≤2 分 = 误差;5-9 分 = 有意义;≥10 分 = 明显优势
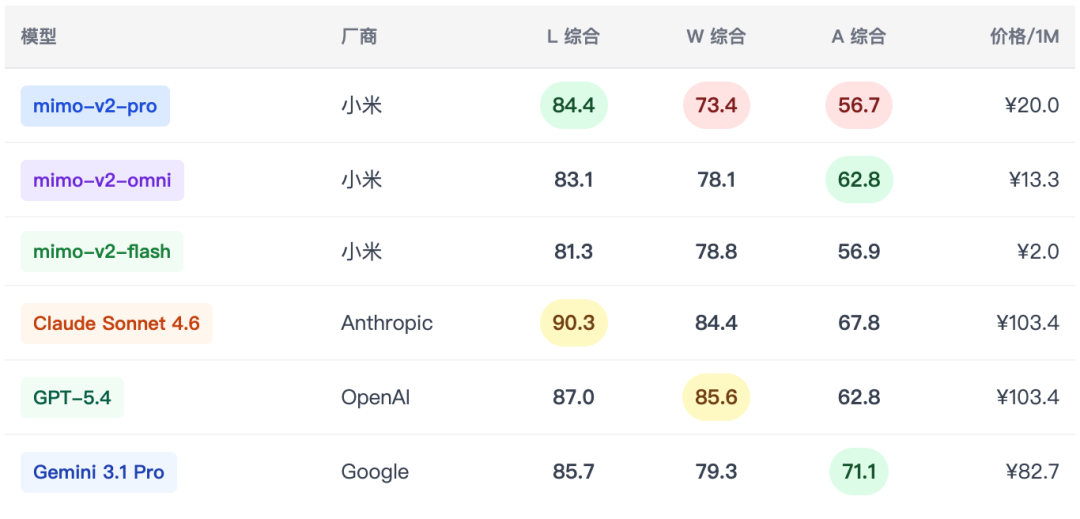
2.3 目标模型与竞品列表
三、模型基本档案
3.1 Mimo-v2-Pro
- 强项:
文本写作(L-Writing 87.3 hard)、长文逻辑一致性、多场景人设控制 - 风险1:
Web 生成能力严重低于系列预期(W 综合 73.4,#18,甚至低于 Flash #11) - 风险2:
Agentic 任务执行较弱(56.7,与 Flash 持平),工具调用可靠性存疑 - 适配场景:
内容创作平台、专业写作辅助、长文本生成、角色扮演类产品 - 不建议场景:
前端代码生成、Web App 构建、复杂 Agent 工作流
3.2 Mimo-v2-Omni
- 强项:
Agentic 任务(62.8,与 GPT-5.4 并列 #4)、PPT/文档生成类 Agent、多轮对话意图追踪 - 风险1:
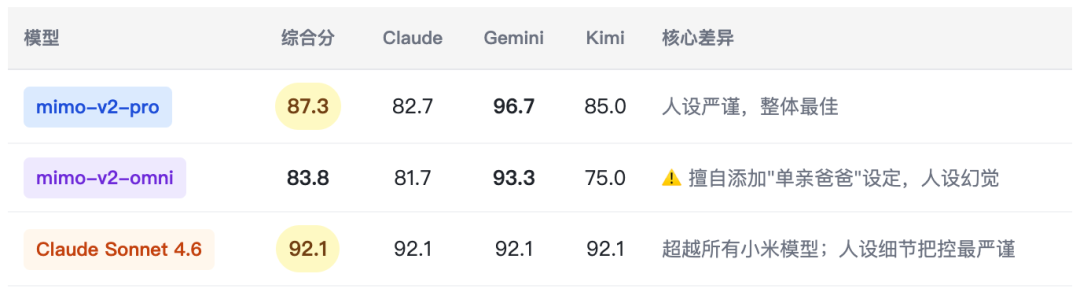
文本写作出现幻觉风险(擅自添加”单亲”人设) - 风险2:
Web 生成低于竞品(78.1,落后于 Flash 78.8) - 适配场景:
办公自动化 Agent、文档生成工作流、PPT/报告自动化、轻量级 Agentic 产品 - 不建议场景:
严格事实性写作、医疗/法律高精度内容生成
3.3 系列内部进化对比
四、全景维度评分(L / W / A)
4.1 xsct-l 文本综合热力表
4.2 xsct-w 热力表(Web 应用生成)
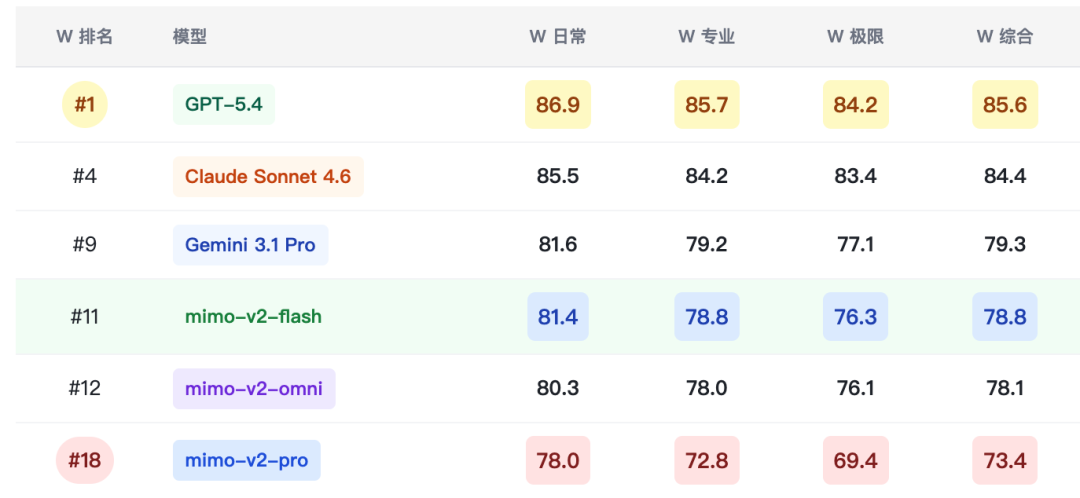
4.3 xsct-a 热力表(Agentic 任务)
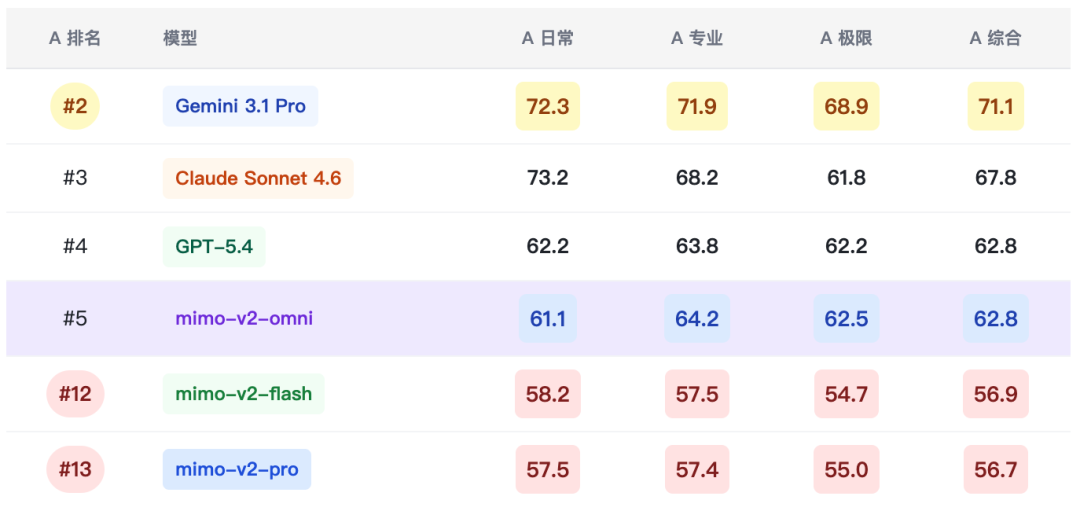
五、核心场景深度分析
5.1 写作任务 — 多场景角色一致性(l_write_001 · hard)
用例描述:扮演”林思远”(35岁 UX 设计师,建筑师转行,有4岁女儿,移居成都),完成私人邮件 + 约会软件简介 + 面试回答三段写作,并输出人设一致性自查表。
5.2 博弈论推理 — 蜈蚣博弈逆向归纳(l_logic_009 · hard)
用例描述:100轮蜈蚣博弈完整分析——要求逆向归纳推导子博弈完美均衡、解释实验现象与理论偏差(认知层次、社会偏好等≥2维度)、批判「完全理性」与 CKR 假设局限、分析 AI 对战均衡与强化学习偏差。

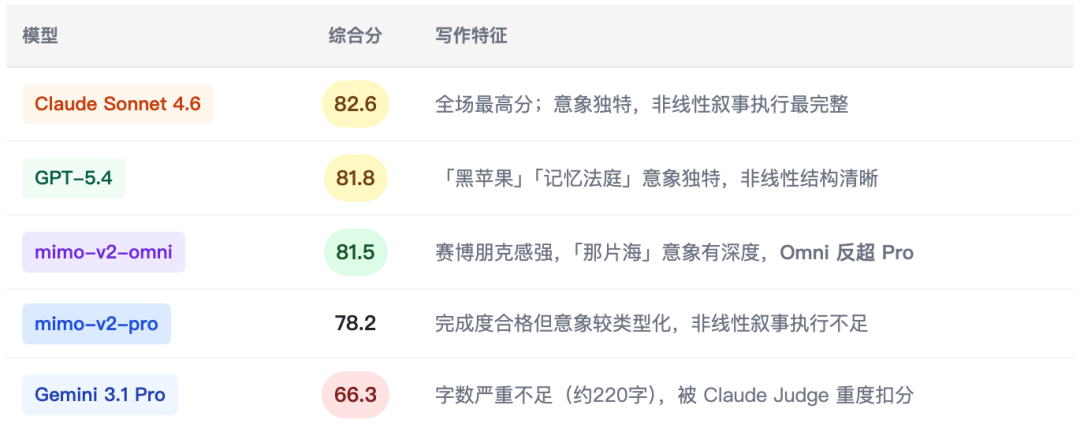
5.3 科幻短篇创作 — 非线性叙事(l_creative_001 · hard)
用例描述:280-320字科幻故事开头,需包含哲学命题(100字内)、非线性叙事结构、≥2种感官描写、自然融入伏笔,禁止套语和旁白式解释。
5.4 Agentic PPT 生成 — 多轮矛盾指令处理(a_034 · hard)
用例描述:多轮对话中将”政府汇报 PPT”改版为”投资人路演 PPT”,处理风险页去留矛盾、总页数 10 页限制、保留特定场景页等冲突约束。
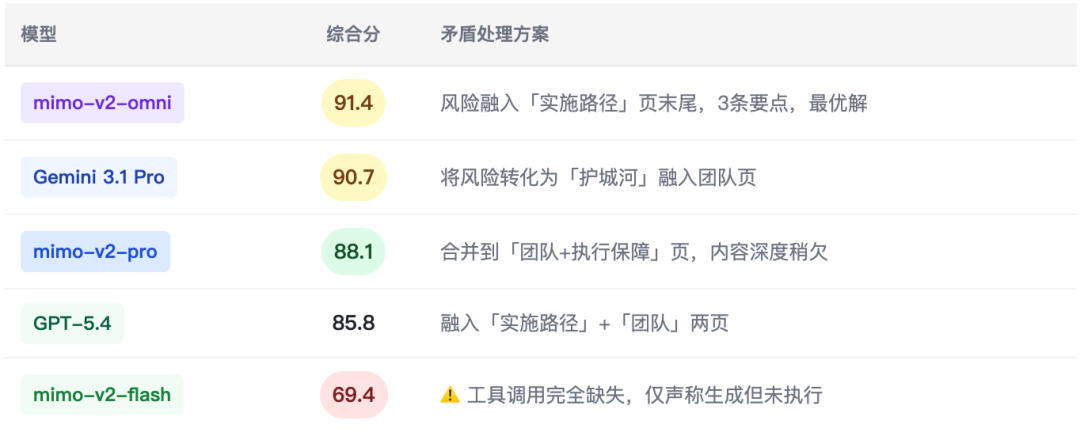
5.5 多视角叙事写作(l_write_007 · hard)
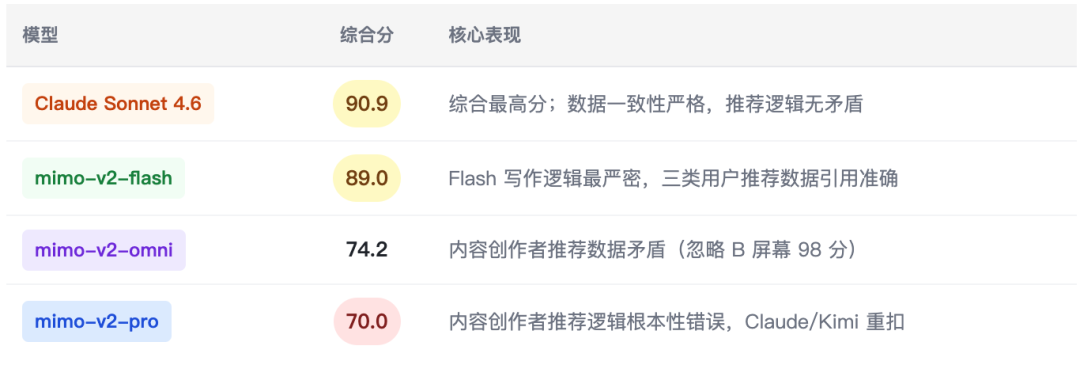
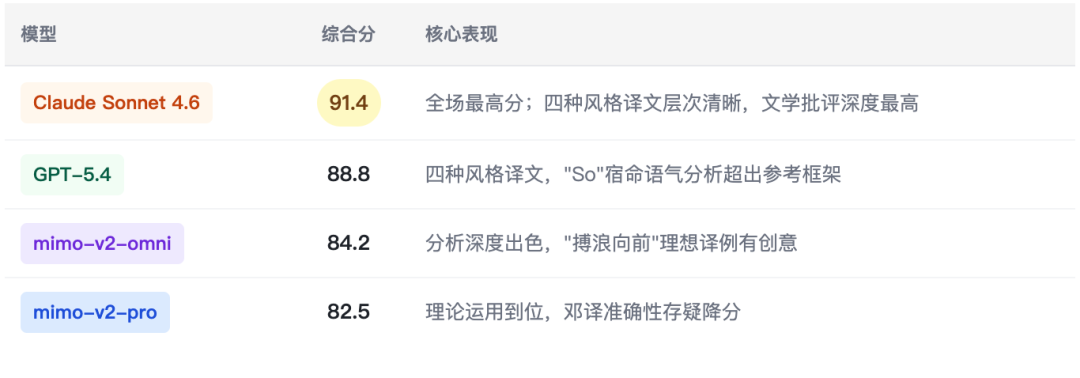
5.6 文学翻译批评 — 《盖茨比》结尾句(l_trans_004 · hard)
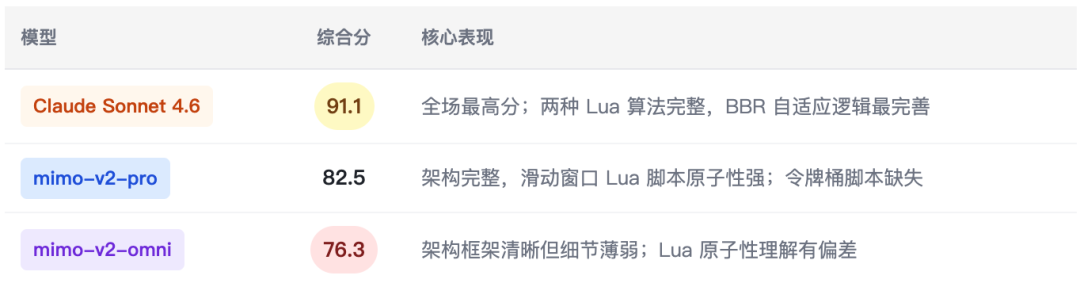
5.7 代码工程 — 分布式限流器设计(l_code_038 · hard)
5.8 多工具协同执行 — Flash 极端失分(l_agent_004 · medium)
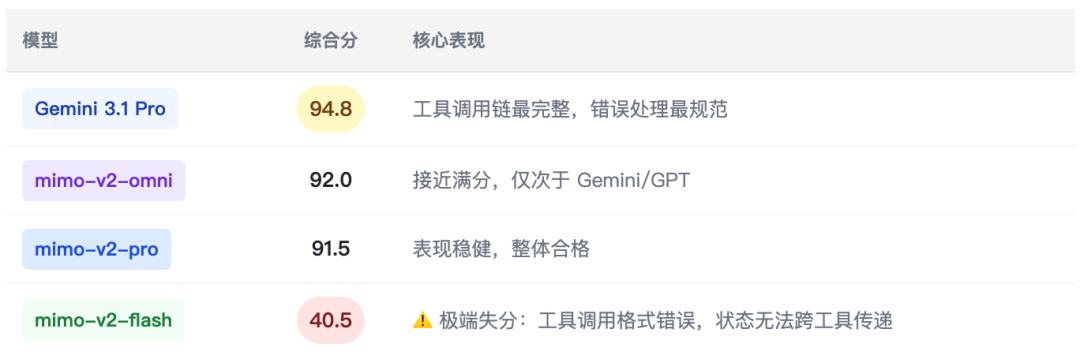
5.9 数学推理 — 质数无穷证明(l_math_007 · hard)
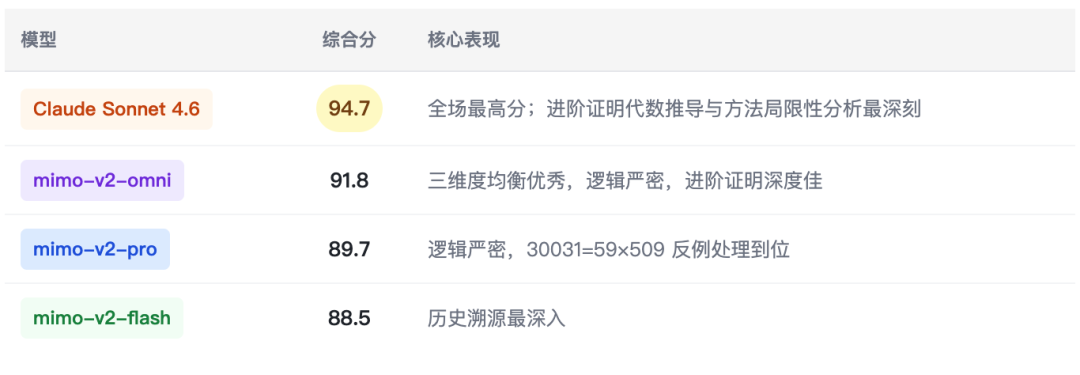
5.10 数学竞赛深度推理(l_math_008 · 三档难度对比)
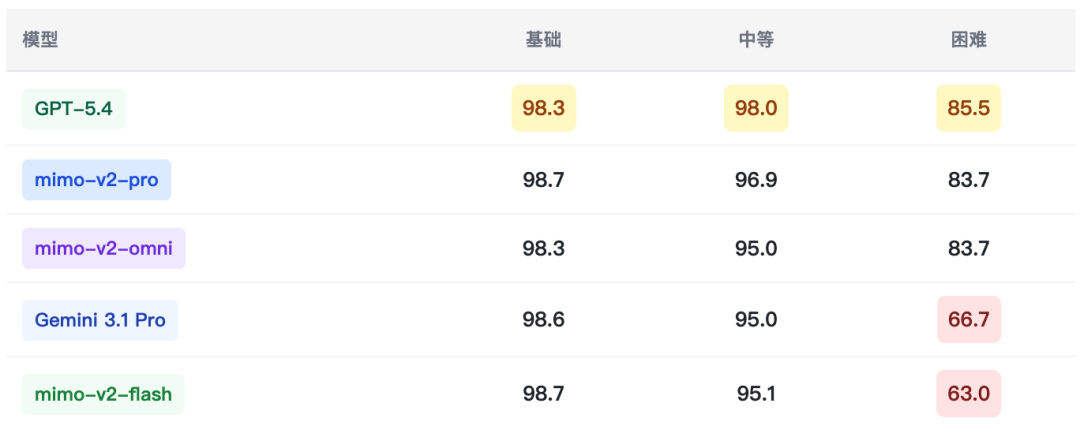
5.11 子 Agent 并行编排(orch_001 · 三档难度)
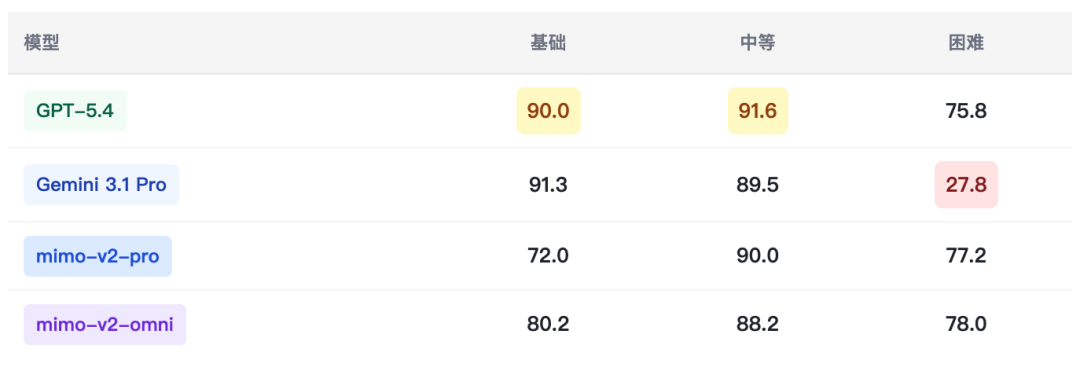
六、横向竞品对标
6.1 公平用例集逐条对比(9 条全模型完整数据)
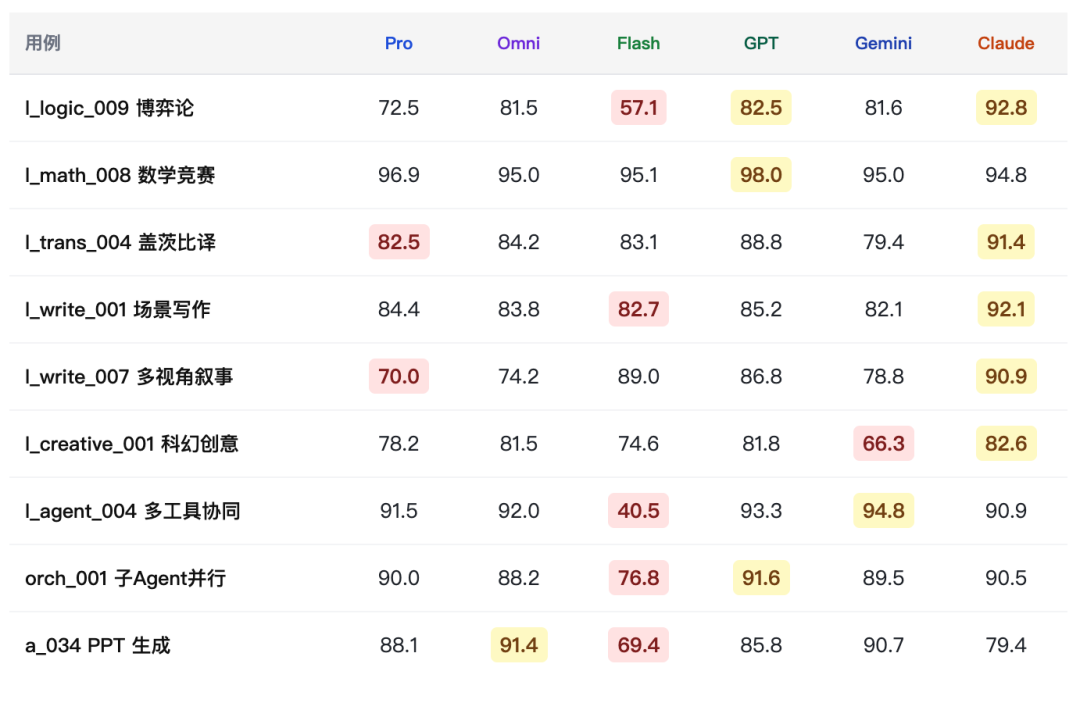
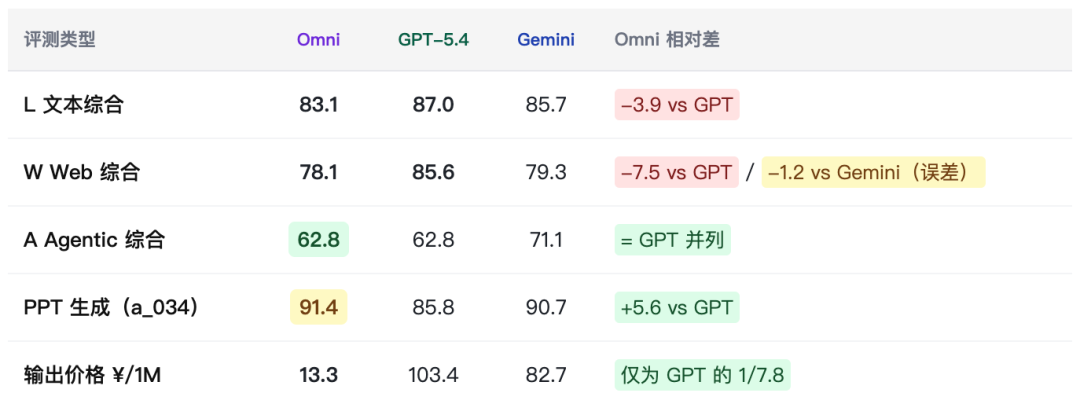
6.2 Omni vs 外部竞品维度均分对比
七、综合评估:优劣势矩阵
Mimo-v2-Pro 优劣势
Mimo-v2-Omni 优劣势
八、场景选型建议
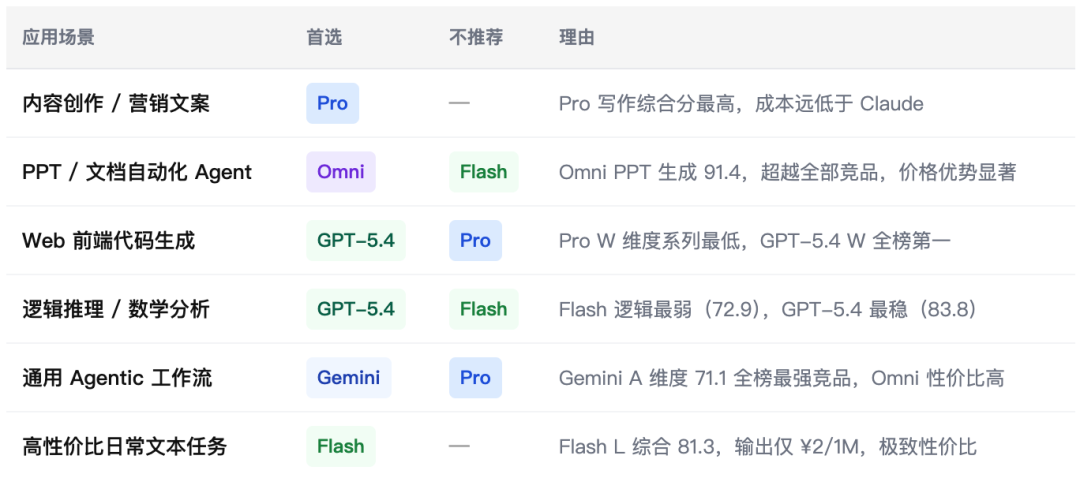
- 选 Pro:
核心任务是高质量长文本生成、多场景写作、内容营销,且对 Web 生成无需求 - 选 Omni:
需要 Agentic 能力(文档生成/工具调用/多轮对话),PPT 自动化,或希望以 1/7.8 的 GPT 价格实现相近效果 - 选 Flash:
高并发低成本场景,日常文本质量够用,需要 Web 生成能力,预算极度敏感
⚠️ 避免将 Pro 用于 Web 前端代码生成,这是其最大短板。
九、核心结论与改进建议
改进建议优先级

展望
综合 30 条测评用例数据来看,小米 Mimo-v2 系列的核心竞争力在于极致的性价比——Omni 以 GPT-5.4 约 1/56 的输出成本,在 A 维度达到与其并列的水准;Flash 以极低的价格覆盖大量日常 L/W 场景。然而当前版本存在三条明显的”能力断层线”:Flash 在复杂 W 用例中的代码截断与逻辑崩溃;全系列在 Agentic 冷启动场景中的决策陷阱;Pro 在 W 维度的系列内倒退。
本次新增 Claude Sonnet 4.6 数据进一步明确了差距边界:W 和 A 维度已与外部顶级竞品基本持平,L 维度的代码工程规范性、人文写作深度、复杂逻辑推理是与 Claude 差距最显著的三个方向,建议作为 Mimo-v3 的重点强化目标。如果 Mimo-v3 能够在保持现有成本优势的同时修复上述问题,小米系列将在中等复杂度 Agent/Web 应用市场形成较强的差异化竞争位置。
十、附录:全量用例对照表
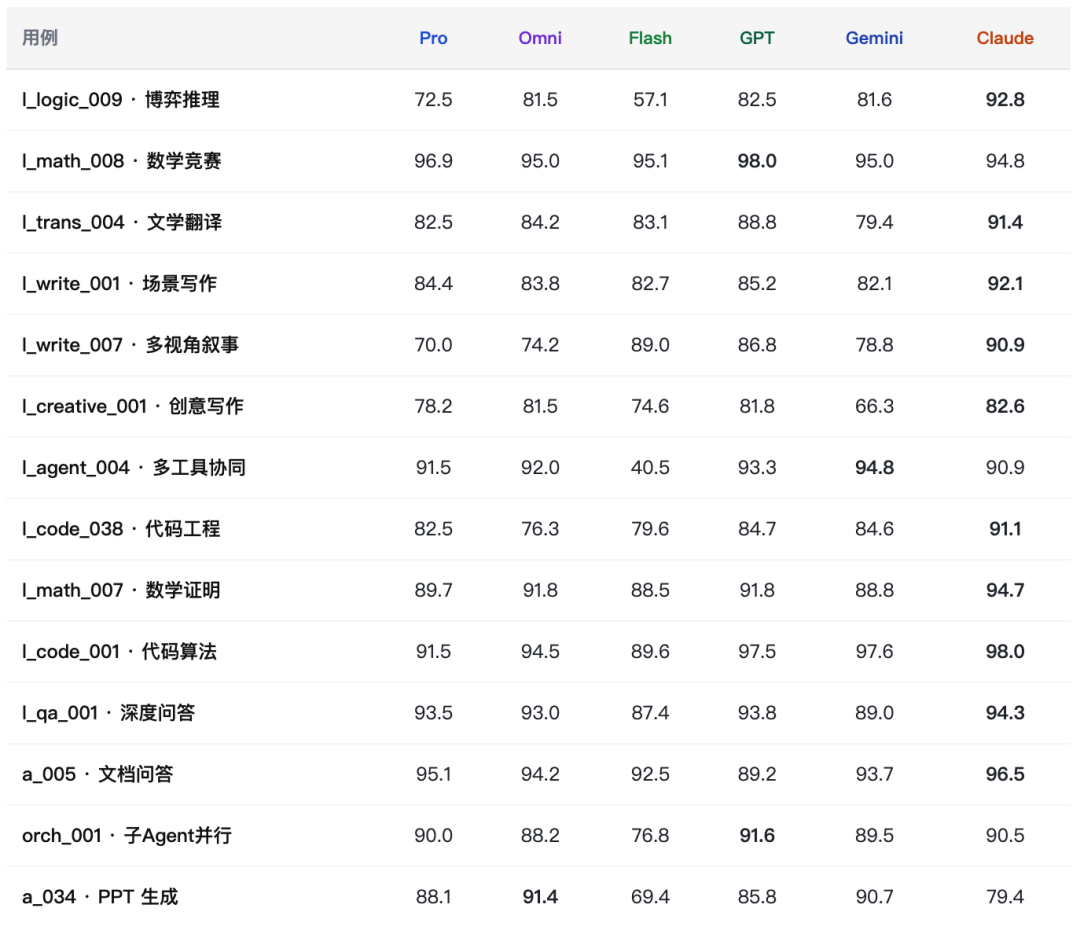
十一、局限性声明
用例覆盖不完全:本报告深度分析集中在 L / W / A 三轨 Hard 难度代表性用例,通过维度均分呈现整体表现。建议关键决策前通过平台验证更多用例。
LLM-as-a-Judge 主观性:Judge 模型(Claude 50% · Gemini 30% · Kimi 20%)本身的偏好会影响评分。对分差 >15 分的用例均已进行分歧分析,但无法完全消除主观性影响。
价格数据时效性:定价以 2026-03-19 各厂商官方公示价格为准,实际决策时请以最新定价为准。
模型版本迭代:数据采集于 2026 年 3 月,报告结论不代表未来版本表现,建议定期通过 XSCT Arena 平台重新评估。
数据来源:XSCT Arena(xsct.ai) · 报告日期:2026 年 3 月 19 日
评测方式:XSCT Arena 平台全自动化评测,全程无人工干预;
Claude 系列 API 赞助:PIPELLM(pipellm.ai),未参与报告内容撰写
关于我
我是洛小山,一个在 AI 浪潮中不断思考和实践的大厂产品总监。
我不追热点,只分享那些能真正改变我们工作模式的观察和工具。
如果你也在做 AI 产品,欢迎关注我,我们一起进化。