


本文提出的是一套以商品侧标准语义空间为核心锚点的生成式召回体系。系统并不直接让模型生成商品 ID ,也不追求 Query 与商品的双边共训,而是先在商品侧构建一套稳定、可控、可解释的显式属性语义空间,再让 Query 侧通过大模型对齐到这一空间,最终基于结构化属性完成召回。
1. 背景:为什么选择显式语义
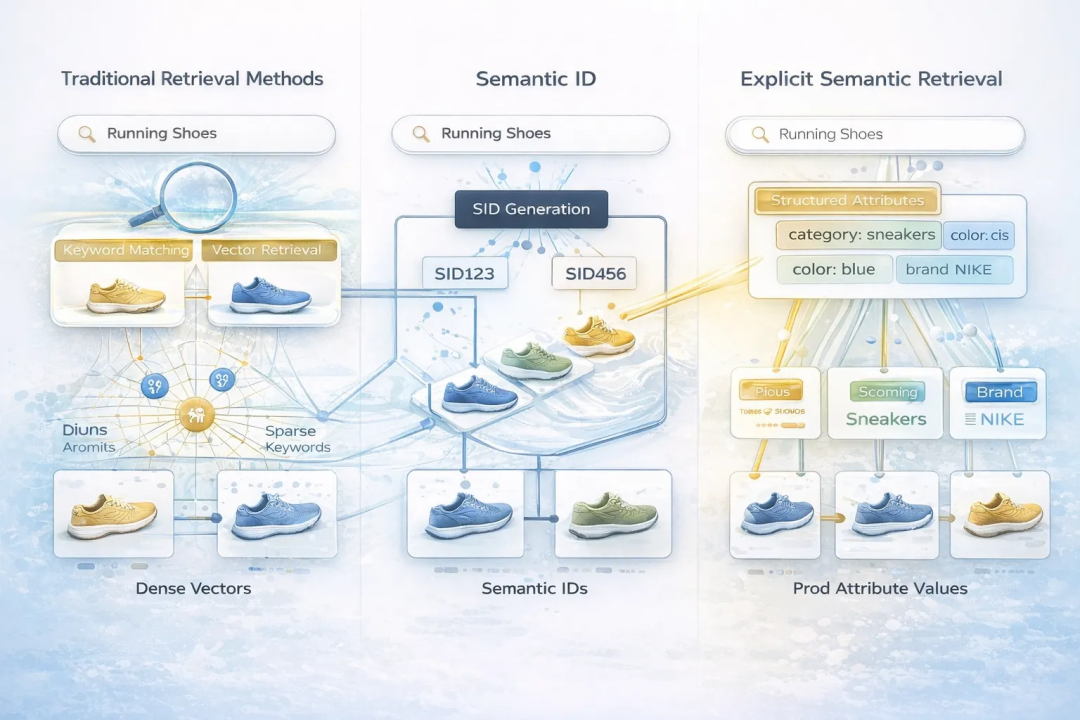
在搜索广告与电商检索的演进过程中,检索范式经历了从词项匹配到语义建模的持续跃迁。传统倒排检索受限于字面匹配,难以跨越同义表达与语义鸿沟;而稠密向量检索虽提升了泛化能力,却由于其黑盒特性,在需要精细化调控的广告场景中缺乏可解释性与干预能力。随着大语言模型的发展,生成式召回成为新的技术方向。当前主流方案多基于语义 ID(Semantic ID, SID),尝试让模型直接生成离散标识以完成召回。然而,该范式在工业落地中遭遇了‘语义割裂’的根本性挑战:它迫使拥有通用世界知识的大模型,去死记硬背一套与自然语言分布正交的‘人工暗语’(Semantic IDs)。这不仅造成了预训练知识的巨大浪费,更因生成目标与预训练目标的分布偏移,显著削弱了模型在零样本场景下的语义泛化与逻辑推理能力。因此,我们重新回到召回问题的本质:检索的核心不是“生成 ID”,而是“表达语义”。基于这一认知,我们提出以商品结构化属性(显式语义)作为生成式召回的统一表达空间,使模型直接生成可解释的语义键值对,而非黑盒标识。这种显式语义驱动的生成式召回,本质上是一种“可控的语义生成范式”,在实际业务中展现出以下关键优势:
-
可解释性与可控性:结构化属性构成完全白盒的语义空间。召回错误可以被精确归因到具体属性(如style、color),为规则干预与策略调优提供直接抓手。
-
对齐问题的结构化简化:通过预定义 Schema,将 Query 语义映射到收敛的属性空间,将复杂的端到端拟合问题转化为结构化语义提炼问题,显著降低对齐难度。
-
预训练能力的直接继承:生成 KV 本质仍属于自然语言建模任务,与 LLM 的预训练目标高度一致,使模型能够直接复用其已有的语义理解与推理能力。
-
天然支持冷启动与扩展 :新商品只需一次属性解析即可接入系统,无需重建 ID 或重训索引,具备极强的扩展性与系统鲁棒性。
从“生成 ID ”走向“生成语义”,并非对生成式范式的回退,而是在大模型能力基础上的一次范式重构。大模型不再被用于记忆标识,而是用于理解世界本身。重剑无锋,虽然这把巨剑他并不锋利,但是只要作为基底的大模型足够力大砖飞,那么实际上一击狮子斩下去,也能砸出很棒的效果。
2. 技术方案:为什么进行“单边对齐”
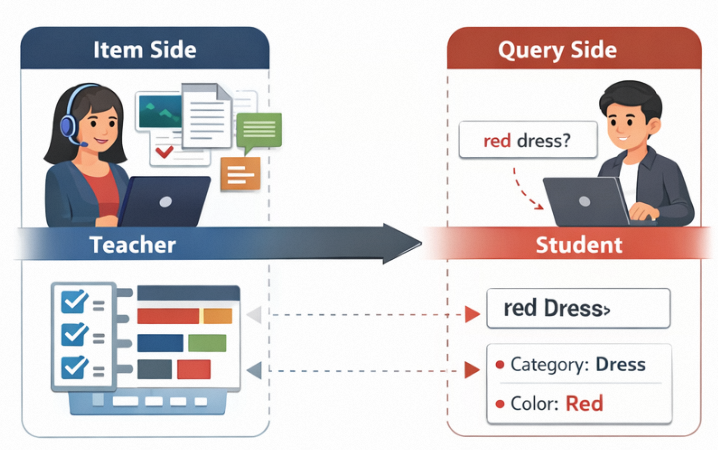
在确定以显式结构化属性作为统一语义空间后,核心问题转化为:如何让 Query 与商品在该空间中实现高质量对齐。业界已有工作(如 GRAM )尝试通过 Query 与商品的联合训练(Co-training)学习共享表示。然而,这类方法隐含一个前提:两侧信息密度应大致对称。
但在真实电商场景中,这一前提并不成立。商品侧具备极高的信息密度:不仅包含 Title,还包括 OCR、详情页、结构化属性(CPV/SKU)等多模态信息,能够完整刻画商品特征,商品侧对于一条裙子可以抽取出材料,颜色,款式等五花八门的特征。而 Query 往往极短且高度压缩,仅表达部分意图,用户搜索的仅仅只是一个red Dress 。这种‘重商品、轻Query’的结构性不对称,宣告了对称式联合训练在此场景下的失效:为了强行对齐,富含多模态细节的高维商品表征不得不向信息贫瘠的短文本Query‘降维’妥协。这种‘削足适履’式的压缩,不仅导致了关键细粒度特征(如材质、设计细节)的信息坍缩,更引入了大量噪声,最终构建出一个模糊且不稳定的语义空间。
2026年3月最新发表的跨模态检索研究 NanoVDR 也明确指出,在面对一端信息极度复杂(如多模态文档/商品)、一端极度贫瘠(如短文本Query)的场景时,追求模型结构的对称或双边联合共训是缺乏效率且容易导致信息坍缩的。相反,通过剥离两侧编码路径,利用纯空间对齐,让轻量级 Query 强制拟合冻结的重型基座空间,不仅能避免排序对比学习带来的效果骤降,更能在极低在线延迟下保持极高的检索精度。
基于这一观察,我们采用非对称对齐范式:以商品侧为语义锚点(Teacher),Query 侧作为映射对象(Student),进行单边对齐。具体而言:
Teacher(商品侧)
利用大模型对多模态商品信息进行深度解析,通过 Schema 归一化与候选值聚合,构建稳定、收敛的属性语义空间。该空间一经构建即保持固定,作为全局语义基座。
Student(Query 侧)
训练轻量模型学习将 Query 映射到该固定语义空间中,输出严格受约束的属性键值对,实现语义对齐。
在该架构下,“对齐”被重新定义为两个层面:
-
工程层(输出约束):模型生成结果必须严格落入预定义候选值集合,确保与底层倒排索引完全一致,实现可控召回。
-
业务层(行为蒸馏):通过点击与曝光数据,使 Query 学习其对应的高频商品属性,本质上完成用户意图向商品语义的蒸馏过程。
这种“固定语义空间 + 单向映射”的非对称对齐方式,本质上避免了信息坍缩问题,使模型无需学习复杂的双向对齐关系,而专注于高精度语义投影,在保证效果的同时显著降低系统复杂度与在线推理成本。
3. 详细实现-显式语义的双端生成和对齐
3.1 商品侧多模态特征的解构与提纯
因为本模块的核心目标是将商品多模态信息统一抽取为结构化属性表达(KV),构建高置信的商品语义表征。为此,我们设计了一套 “多源独立并发抽取 + LLM 聚合清洗 (LLM-as-a-Judge)” 的两阶段抽取流,即先从不同模态分别抽取属性,再进行统一归一与质量控制,从而最大化地榨干商品多模态特征,并保证最终输出的纯净度。
3.1.1 基于 Schema 约束的多源独立抽取
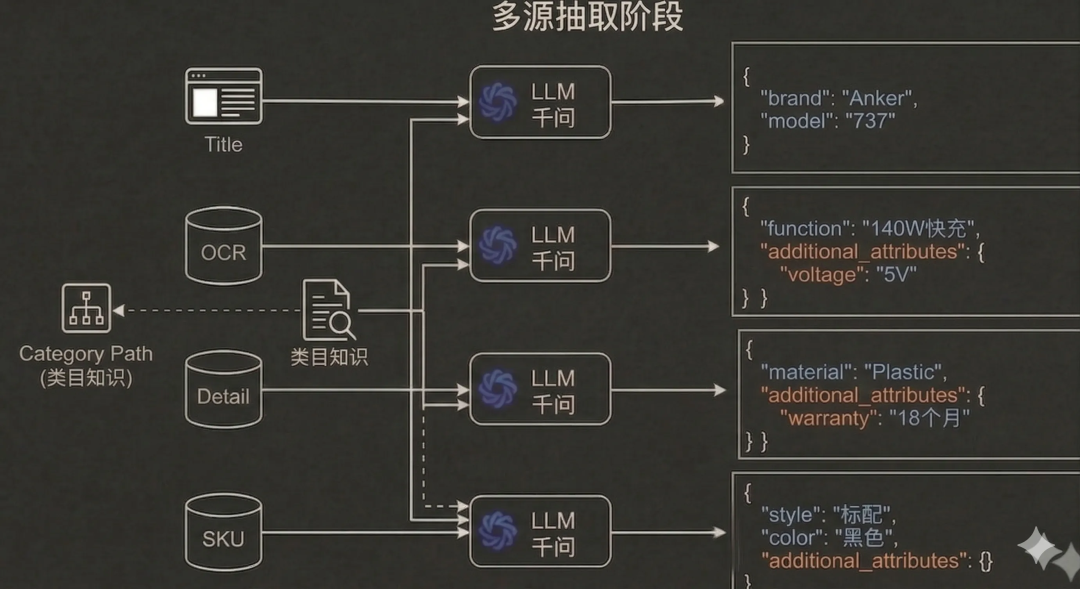
我们并未将所有文本打包一次性喂给大模型(容易导致 Attention 灾难和信息淹没),而是将 Title、OCR、Detail、SKU 作为四个独立信源,分别请求大模型进行抽取。每一类模态单独调用大模型进行解析,避免多模态混合输入带来的语义干扰问题,同时保留不同模态的表达信息。
在抽取 Prompt 的设计上,我们引入了以下三个核心工程约束:
-
结构化底座约束: 参考通用商品属性标准,定义了约20个高频基础属性(如brand, product_type, material, function等)作为提取基准。
-
Category-Aware 推理(类目引导理解): 强约束大模型必须将商品的类目路径(Category Path)作为逻辑推理框架,而非直接提取源。例如,在“充电宝”类目下看到“140W”,大模型能依据类目常识将其推断为
function: 140W Fast Charging,而不是一个无意义的数字。 -
Open-World 长尾发现(兜底机制): 真实商品的属性往往超出预设的 20 个 Schema。我们在输出结构中强制保留了 additional_attributes 数组。当大模型在源文本中发现不属于预设 Schema 但极具区分度的特征时(如芯片的“输入电压”),可以作为扩展 KV 对输出,以此捕获极致的长尾属性。
3.1.2 LLM-as-a-Judge 融合与规范化清洗
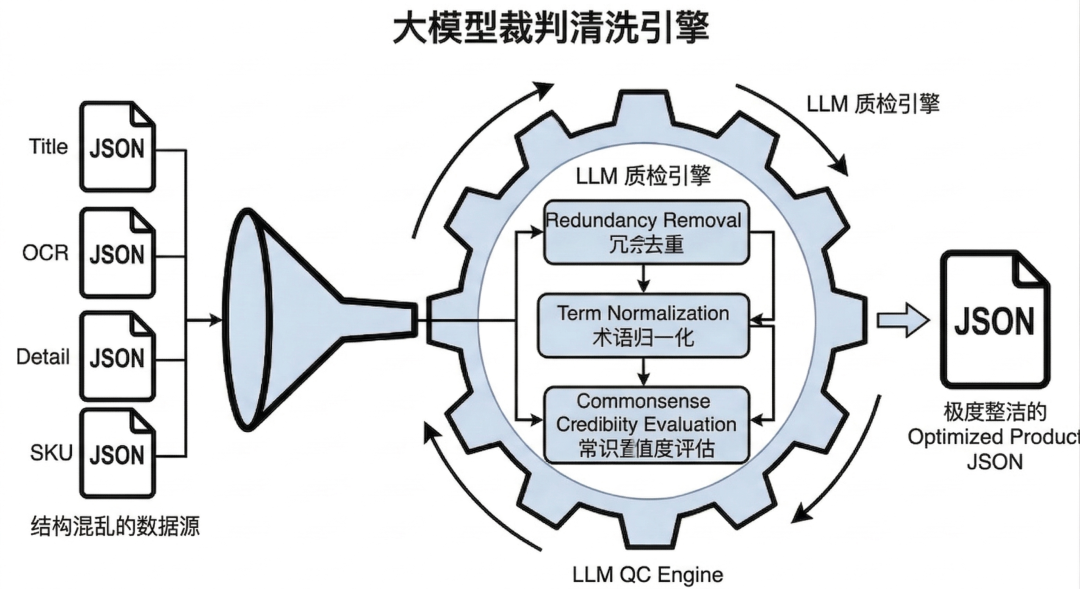
四个信源独立抽取完成后,我们面临着数据合并的问题。此时,数据中存在大量冗余(如 Title 和 OCR 都抽出了颜色)、格式不一(如 Black 与 BLK)、甚至源文本自带的明显谬误。
针对这一痛点,我们引入了大模型作为“质量控制专家(QC Specialist)”,进行第二阶段的融合清洗。
-
输入构造: 我们将第一阶段聚合后的粗糙 JSON,连同商品的上下文信息(
category_tree,title,base_attributes)一同送入模型。 -
评价与重写: 我们对大模型的指令不仅是“合并”,而是进行“打分与修正”。模型需要对每个合并后的属性输出
grade(Excellent/Good/Fair/Poor)和reason,并强制产出一个干净、去重、归一化的optimized_value(例如将["Lc11, Lc11"]修正为规范的["LC11"])。 -
引入专家先验信任: 在 Prompt 中设定了一条关键边界:如果合并 JSON 中的某个属性(如“墨盒”的材质是“塑料”)符合客观世界的品类常识,即便在当前上下文切片中找不到直接出处,也应当予以保留并评定为高置信度。这赋予了模型“宽容并接纳合理信息”的弹性,避免了死板的字面匹配导致有效特征丢失。
最终,通过这套“先发散提纯,后收敛评价”的流水线,我们将杂乱的多模态商品数据,转化为了极其干净、高信息密度的标准化 JSON 结构,为后续的 Schema 构建打下了最坚实的数据底座。
3.2 分类目 Schema 构建与候选值空间标准化
在完成商品多模态特征抽取后,我们得到了海量但高度发散的商品属性 KV 数据。此时,原始属性虽然已经具备一定语义信息,但无论是 Key 还是 Value,都还远未达到可直接用于检索建索引与模型训练的程度:同一类语义往往对应多个异构 Key,不同商家、不同模态、不同语言风格下的 Value 也存在大量错别字、噪声词、冗余表达与长尾变体。单个属性下的候选值规模少则几十,多则数百万,如果不先完成标准化收敛,直接进入检索与训练阶段,会带来明显的索引膨胀、语义稀疏和召回不稳定问题。
因此,这一阶段的核心目标非常明确:围绕商品侧构建一套分类目约束的标准 Schema,解决属性 Key 的收敛问题;同时围绕每个标准属性构建高纯度的候选值空间,解决属性 Value 的收敛问题。对整个系统而言,这并不是一个简单的数据清洗步骤,而是生成式召回得以成立的前置基础设施。后续 Query 侧无论是 Teacher 数据构建、14B 模型训练,还是线上倒排召回,最终都必须对齐到这套商品侧先行固化的标准语义空间上。因此,这部分虽然最耗时、最依赖细粒度工程投入,但同时也是整个系统最具业务壁垒的核心护城河。
3.2.1 分类目 Schema 本体构建:Multi-Agent 交叉验证与专家决策
速卖通拥有近 30 个一级类目,不同类目的核心属性差异巨大(如3C类目的 model 极其重要,而服饰类目的 style 更为关键)。
为了高效定义每个类目的 Schema,我们摒弃了纯人工盘点,设计了一套 LLM Multi-Agent 交叉验证机制:
-
统计提纯:遍历所有类目,统计出每个抽取 Key 的命中商品数(覆盖度)及其 Top Value 的分布,形成类目属性画像。
-
多模型博弈 (Debate):将这些统计画像同时输入给多个不同底座的大模型(充当行业专家)。要求它们独立判定该类目下应当保留哪些核心
target_key,以及这些 Key 的重要度分级(tier)和聚合动作(action,如merge_and_clean或drop)。 -
交叉评价与人工收口:让多个大模型互相 Review 对方的 Schema 提议,暴露分歧点。最终由算法工程师进行人工仲裁与合并,沉淀出一份全局的、强业务导向的 Schema 配置文件。这使得系统能够精确知道在什么类目下,应该抽取什么特征,为后续的定向对齐奠定了基础。
3.2.2 Value Space 标准化清洗:防幻觉的五步漏斗流水线
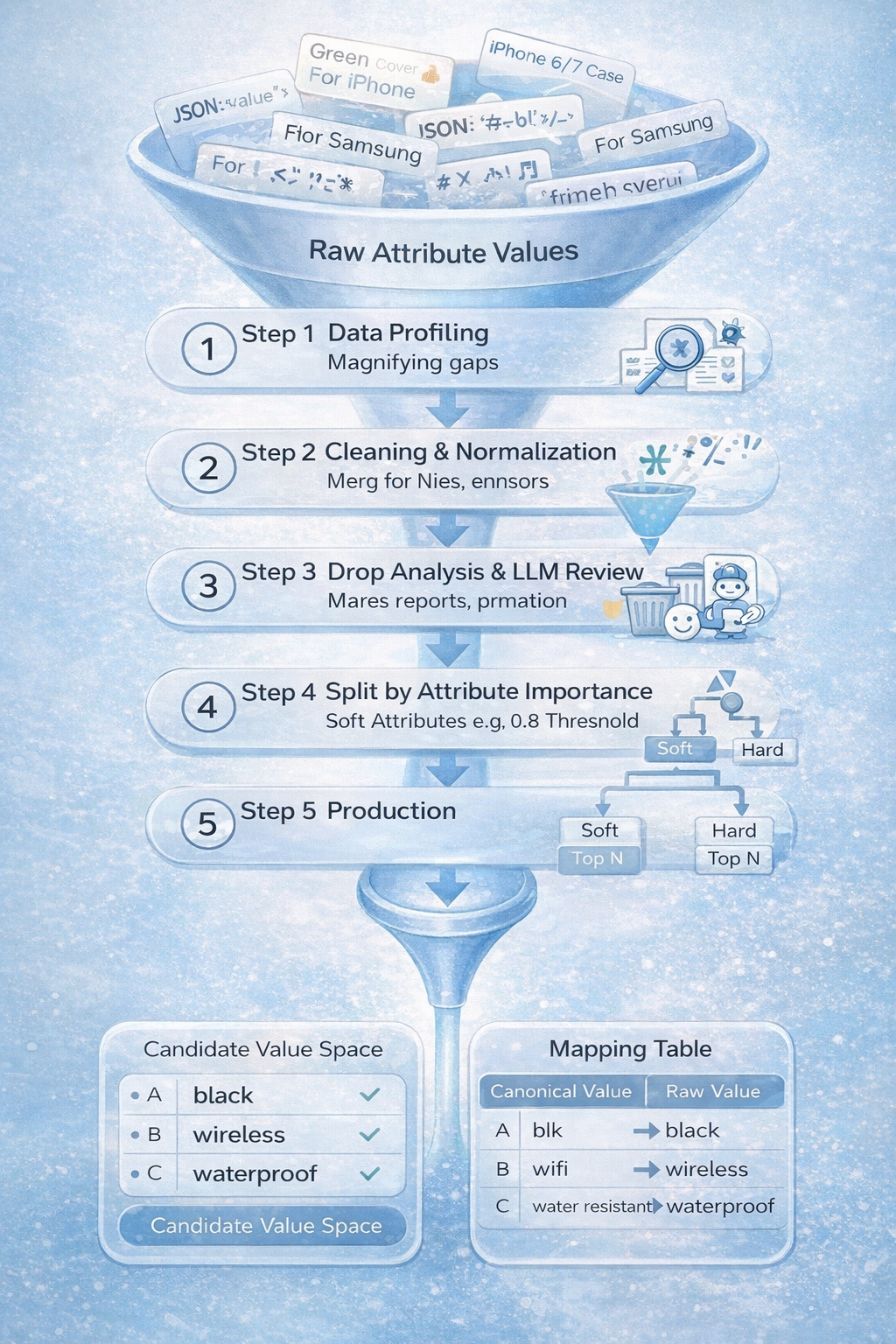
如果说 Key 的收敛依靠大模型的通识,那么近 200 个核心属性 Value 的标准化,则必须依靠极其严苛的工程手段。为了绝对杜绝大模型在此阶段的幻觉污染,我们针对每一个核心属性(如compatible_vehicle,style,material),定制了一套 “硬规则优先 + LLM 辅助” 的五步漏斗清洗流水线。
-
Step 1: 数据体检 (Data Profiling) 对原始值与对应的 PV(页面浏览量)进行探查。编写 Profiling 脚本对 Top 100 和 Random 500 的 Value 进行扫描,精准定位数据劣化的模式:是否混入 JSON 串、是否带入面包屑导航、分隔符(如
/,&)分布规律、是否包含无意义的营销前缀(如For,With)或纯数字乱码。 -
Step 2: 定制化清洗与归一 (Cleaning & Normalization) 为每个高优属性编写独立的清洗逻辑,执行刚性清洗:
-
-
结构化穿透:解析并提取异常的 JSON 结构。
-
正则降噪:剔除冗余修饰词、商品品类词(如把
Phone Case洗为Phone)。 -
裂变与继承 (Explode):针对兼容性等复杂属性(如
iPhone 12/13/14),进行原子化炸开,并强制继承前缀品牌语义。 -
单复数坍缩:结合
inflect库与全局PV投票机制,将同义的单复数表达强行归一到最高频的形式。
-
-
Step 3: 损失拦截与大模型巡检 (Drop Analysis) 规则清洗不可避免会产生误伤。我们将被脚本 Drop 掉的 Top PV 属性值自动汇总,逆向抛给大模型进行 Review。如果 LLM 判定被 Drop 的值具备显著的业务语义,则立即告警并驱动我们反向优化 Step 2 的清洗代码,形成闭环。
-
Step 4: 软硬属性的路由分流 (Coverage Analysis & Decision) 基于清洗后数据的 Top 10k~30k PV 覆盖率,进行业务决策与召回策略分流:
-
-
软属性 (Soft Attributes, 如 Style/Function):表达相对主观,允许一定程度的泛化。我们启用 Embedding 向量吸附(Threshold ~0.80),将长尾词挂靠到头部标准词上。
-
硬属性 (Hard Attributes, 如 Model/Vehicle):要求极致精准,容错率为零。强行禁用向量吸附,直接采用 Top N 截断,长尾未匹配值直接丢弃(退化走传统文本召回),坚决防止类似
iPhone 13吸附到iPhone 12的灾难性错误。
-
-
Step 5: 最终基建产出 (Production) 流水线最终为每个属性生成两份至关重要的数据资产:
-
-
Schema 字典 :包含标准化的
canonical_value及其总 PV。这直接构成了后续 14B 模型 SFT 训练时的强约束目标词表。 -
索引映射 :将海量的
raw_value精确映射到canonical_value,直接作为线上倒排索引建库的翻译字典。
-
这套看似“重人力”的工程实践,本质上是用少量的算法人力,换取了检索底层数据的绝对安全与高纯度。它不仅将数百万长尾特征收敛成了数千个极高质量的标准语义,更让整个召回系统的可解释性达到了极致。
3.3 Query 侧意图结构化与候选池动态对齐(语义与行为的双重蒸馏)
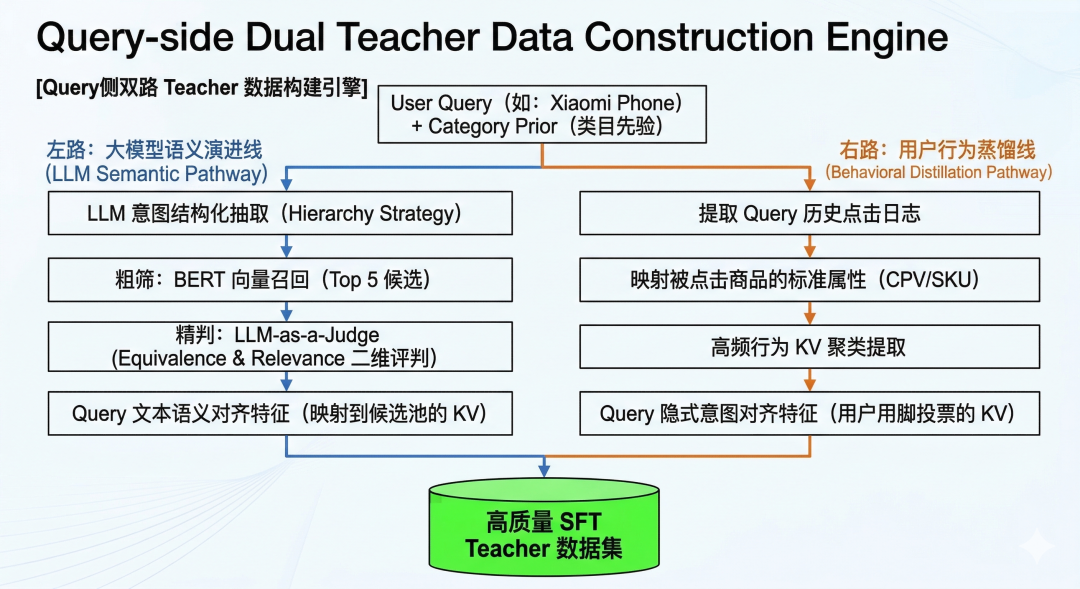
在商品侧(Teacher 空间)的标准候选字典构建完成后,对齐的锚点已经固定。考虑到Query 天然是“轻语义、弱结构”的短文本,其表达高度稀疏且存在大量隐式意图。因此,我们并未直接使用 Query 做无监督建模。而是把重心放到下面这个核心任务:如何将海量、简短、口语化的用户 Query,精准地翻译为这套标准字典中的词汇,从而构建出高质量的“教材”(Teacher 数据集合),供后续的 14B 模型进行 SFT(监督微调)学习。
为了保证这批“教材”的质量,我们设计了一套 “LLM 语义结构化 + 向量与大模型联合纠偏 + 用户行为融合” 的三段式数据生产链路。
3.3.1. 语义结构化:基于类目先验的 Hierarchy 抽取 (LLM Parser)
由于我们已经拥有 Query 的预测类目,我们在第一步利用强推理模型(Qwen-Max),将“预测类目”与“对应的 Schema 候选 Key(区分 Core 与 Optional)”作为上下文喂给大模型,进行定向抽取。
在 Prompt 设计上,我们不仅要求大模型提取字面属性,还植入了一条极具工程价值的指令:Hierarchy Strategy(层级展开策略)。
-
做法:当 Query 隐含特定的下位概念时(例如搜 “Xiaomi Phone”),强制要求大模型同时提取上位泛化词与下位精准词(即
product_category: ["Phone", "Xiaomi Phone"])。同时,要求大模型进行隐式推理,即使 “Xiaomi” 已经作为品类词出现,依然要将其切分并赋值给brand: "Xiaomi"。 -
业务收益:这一策略完美契合了底层搜索引擎的排序逻辑。包含 “Xiaomi Phone” 标签的精准商品会获得 2 次 Hit(相关性更高,排在前面),而仅包含 “Phone” 的商品获得 1 次 Hit(保证泛化召回底线)。这种将“排序逻辑前置到抽取阶段”的做法,极大提升了召回结果的层次感。
这一过程本质上是将 Query 从自然语言空间,投影到商品侧标准语义空间。
3.3.2 候选池动态对齐:Vector Retrieval + LLM-as-a-Judge ( 更新映射逻辑 )
大模型直接抽取的属性值往往是“开放世界”的(例如抽出Batman Cave LED Blocks),这在底层倒排索引中注定会遭遇“零召回”(因为标准候选池里可能只有 LED)。
为了把开放域词汇强制挂靠到封闭域候选池,我们设计了联合纠偏机制:
-
粗筛 (Vector Search): 首先,利用 BERT 向量检索,在标准候选池中召回与 Raw Value 语义最接近的 Top 5 候选值(如
LED Mask,LED Underground Lights,LED等)。 -
精判 (LLM-as-a-Judge): 向量检索只能计算字面/分布的相似度,不懂电商业务逻辑(比如“蝙蝠侠积木”和“LED地埋灯”字面有重合,但业务上毫无关联)。我们将这 5 个候选值和 Raw Value 再次送入 Qwen-Max,要求其从 Equivalence(标准化等价性) 和 Relevance(搜索召回相关性) 两个维度进行二维评判。
-
严格拦截: 强制要求大模型忽略向量 Score,仅基于电商常识进行评判。如果不满足,允许返回空列表。通过这一步,我们成功将千万级 Query 的发散意图,安全、精准地挂靠到了有限的候选集上,产出了极其珍贵的对齐字典。
也就是说向量负责“找候选”,LLM负责“做决策”,从而避免单纯依赖 embedding 带来的语义漂移问题。
3.3.3 闭环验证:融合用户点击行为的语义蒸馏
纯文本的语义推演存在极限。用户搜“geox sneakers mario”,字面抽不出什么特殊材质,但用户最终可能大量点击了“防水 (Waterproof)”属性的商品。
因此,在构建 Teacher 数据时,我们不仅依赖 Qwen 的文本解析,还引入了该 Query 下的历史点击商品日志。我们将被高频点击商品所对应的“标准属性 KV”逆向聚合到该 Query 上。 至此,每一个 Query 都获得了双重护航:一份来自大模型的**“显式语义理解”,一份来自用户点击的“隐式行为投票”**。这两份数据的交集与融合,构成了极高质量的 SFT Teacher 数据集。
这一步的本质是: 让 Query 学习“用户真实买的是什么”,而不仅是“字面表达是什么”
3.4 Student模型训练:14B 模型的 SFT 与 DPO 对齐
在完成商品侧标准语义空间构建,以及 Query 侧 Teacher 数据生成与候选值对齐后,系统已经具备了训练生成式对齐模型的基础条件。接下来的目标,不再是“让模型理解 Query”,而是进一步让模型学会:在给定 Query 和类目先验的情况下,稳定输出与商品侧候选值空间严格对齐的结构化属性表达。
这一阶段我们选择以 14B 模型作为 Student 模型进行训练,整体分为两个层次:
-
SFT(Supervised Fine-Tuning):让模型先学会在高质量 Teacher 监督下,稳定产出正确的标准属性;
-
DPO(Direct Preference Optimization):进一步压缩模型输出空间,惩罚那些虽然“看起来合理”、但实际上无法落入候选值空间的生成结果。
3.4.1 SFT 样本精炼:语义与行为的双向交叉验证引擎
在前置环节,我们通过大模型和点击日志构建了千万规模的粗糙 Teacher 数据集。然而,如果直接用这 1000 万数据进行 SFT,不仅算力成本高昂,且数据中掺杂的噪音会导致模型学习到不稳定的映射分布。因为如果不加区分地全部用于 SFT,会带来明显问题:
-
不同来源样本的置信度差异较大;
-
Loose 映射中可能混入 substitute 而非真正 synonym;
-
纯点击样本虽然覆盖长尾,但噪声和歧义也更高。
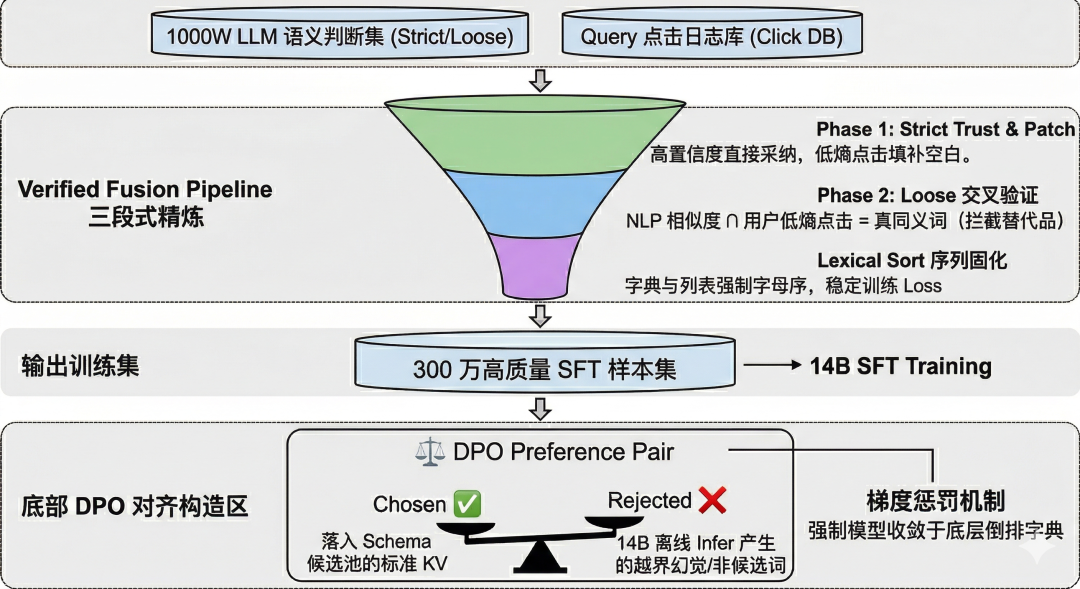
因此我们将 1000 万 Teacher 数据依据置信度划分为 Strict(严格等价)和 Loose(语义近似/中等相关)。为了提纯这批数据,我们设计了 “三阶段融合流水线 (Verified Fusion Pipeline)”:
-
Phase 1: Strict 基石与点击 Patch (兜底) 对于 LLM 判定为 Strict 的数据,我们予以绝对信任,作为 SFT 的基底。同时,针对大模型没抽出来、但用户点击分布极度集中的特征(
entropy <= 0.5且wilson > 0.15),我们利用点击行为进行 Patch 补全。 -
Phase 2: 语义与行为的交叉验证 (核心亮点) 对于 LLM 判定为 Loose 的数据(可能是同义词,也可能是替代品),我们强制要求必须有真实用户点击背书。逻辑原理:比如Query搜
red dress,BERT可能把wine red dress召回并被判定为 Loose。此时我们去查这个 Query 的历史点击,如果用户点击极其集中(低熵),且高频点击词中刚好包含wine red,我们才认为它通过了验证,进入 SFT 训练集。这一步完美拦截了纯 NLP 视角的“伪同义词/平替词”。 -
Phase 3: 严格数据清洗与字母序固化 (Loss 维稳) 为了消除大模型在自回归生成时,因为 JSON 字典或 List 元素顺序不同而产生的 Loss 震荡,我们开发了强力清洗算子。对多值属性进行彻底展平、去空、去重,并强制执行字母序排序 (Lexical Sort)。这保证了相同的意图永远只有一个唯一正确的 Token 序列目标。
3.4.2 DPO 对齐:惩罚“出圈”幻觉,强化约束生成
经过高质量 300 万数据的 SFT 后,14B 模型已经具备了很强的标准属性抽取能力。但由于生成式模型的自由度过高,在线上 Infer 时偶尔仍会产生幻觉,吐出不在 candi_1(标准候选池)里的词,导致底层倒排拦截漏召。
为此,我们引入了DPO(Direct Preference Optimization)阶段:
-
Chosen (正样本):1000 万标准 Teacher 集合中,严格验证通过、且存在于底层候选集中的标准属性 KV 对。
-
Rejected (负样本):利用 SFT 后的 14B 模型在离线批量 Infer,提取那些与标准集不一致、且生成的属性值游离于标准候选集之外的错误结果。 通过 DPO 偏好学习,我们在梯度更新层面严厉惩罚了“不守规矩的自由发挥”,逼迫大模型的输出概率分布严格向底层倒排字典收敛,真正做到了让大模型“戴着镣铐跳舞”。
本阶段通过“高质量监督数据筛选 + 候选空间偏好对齐”两层机制,将 Query-Attribute Teacher 体系真正转化为 14B 模型的稳定生成能力,使模型输出从自由语言表达收敛为工业可用的标准属性表达。
3.5 在线召回和工程落地机制
在前序步骤中,我们已经构建了高质量的离线商品字典库,并通过 14B 模型实现了 Query 侧的实时标准化解析。接下来的最后一步,不再是继续做复杂建模,而是将离线沉淀下来的标准属性表达,稳定、高效地转化为可执行的召回链路。
为了兼顾搜索引擎的极致性能与检索质量,我们在在线拼装与检索策略上采取了“重离线、轻在线”的设计哲学。离线尽可能把语义空间盘清,在线尽可能保持简单、稳定和可控。
3.5.1 在线召回与截断:基于匹配数与类目底线的排序逻辑
线上 14B 模型实时将 Query 解析出多个属性值后,我们并没有采用复杂的图计算或树状匹配,而是采用了极致高效的召回策略:
-
全量召回 (OR Logic):针对解析出的每一个属性值,向底层倒排索引发起无差别的拉取。这保证了召回池的绝对深度。
-
匹配数排序 (Match Count Ranking):在底层引擎中,直接按照商品命中 Query 属性值的“个数”进行降序排列。命中特征越多的商品(如同时命中品牌、颜色、款式),其相关性天然越高,优先进入后续的精排漏斗。
-
类目强过滤 (Category Filtering):作为兜底的“安全阀”,最终的召回结果会强制通过预测类目进行过滤。这一步斩断了跨类目语义漂移的可能(例如搜“苹果”,确保在手机类目下不会召回生鲜水果),守住了业务相关性的底线。
3.5.2 结构性漏召治理:基于 Schema 的上下位词扩充
在线上真实流量中,我们观察到了一种典型的“结构性漏召”现象:由于多模态大模型的抽取极其精细,商品侧往往被打上了细粒度的下位词标签(例如product_category = mini dress);然而,用户的搜索意图往往是宽泛的上位词(如product_category = dress)。在严格的 KV 匹配下,这种颗粒度错配会导致精准商品被漏召。
为了解决这一问题,我们没有在在线 Query 侧去做复杂的 Query 泛化(这会成倍增加在线检索的算力开销),而是将泛化逻辑前置到了商品侧的离线索引构建中:
-
依托电商基础概念图谱和 Schema 体系,我们对商品侧提取的底层标签进行了自动向上扩充。
-
当系统识别到商品拥有下位词
mini dress时,会自动为其补充打上其上位词dress的标签属性。 -
这样一来,商品侧的倒排链上同时存在了细粒度与粗粒度的表达。线上无论用户发起的是宽泛搜索还是精准搜索,均能实现无缝的精准匹配。
4. 实验效果
4.1. 离线实验结果
离线评估结果如下
|
语义提取方式 |
hitrate |
|
原生72B提取 |
15.3% |
|
原生72B提取+Schema规约 |
27.19% |
|
14B SFT+DPO |
42.1% |
4.2. 在线效果
在线实验累积多天数据,rpm相对基准桶有明显提升
5. 总结与展望
重剑无锋,大巧不工。当语义空间本身被打磨得足够清晰,模型所需要做的事情,反而变得简单而有力。
本文围绕“显式语义驱动的生成式召回”这一核心范式,系统性地构建了一套从商品侧语义标准化、Query 侧单边对齐、到模型训练与在线召回落地的完整技术链路。与当前主流依赖隐式表示(如向量或语义 ID)的方案不同,我们选择回归语义本质,以结构化属性作为统一表达空间,通过大模型完成从自然语言到标准语义的映射,并最终落地为可解释、可控的召回系统。在实践过程中,我们逐步验证了几个关键认知:
首先,语义空间的治理优先级高于模型复杂度。相比直接依赖模型端到端拟合,构建稳定、收敛的商品侧属性 Schema 与候选值体系,是整个系统能够成立的前提。这一阶段看似“工程化、重人力”,但本质上是用结构化确定性对冲生成式模型的不确定性,是系统可控性的核心来源。
其次,非对称单边对齐优于双边共训。在多模态商品与短文本 Query 信息极度不对称的场景下,让 Query 向商品侧语义空间收敛,而非强行构建共享表示,有效避免了信息坍缩问题,同时也更好地继承了大模型的通用语义能力。
再次,生成式能力必须建立在强约束之上。无论是通过候选值空间约束、SFT 数据的高置信筛选,还是后续的偏好对齐,本质都是在引导模型从“自由生成”走向“受控生成”。这也是生成式召回能够真正落地到广告与电商系统中的关键。
生成式 AI 给检索系统带来的最大改变,不是去发明一套不可解释的神秘代码,而是赋予了机器前所未有的理解力,去还原这个商业世界原本就该有的清晰结构。在此基础上,我们也在探索该范式进一步演进的方向。从整体趋势看,生成式召回并非终点,而是一个统一语义接口,其上仍有较大的优化空间。一方面,在语义表达层面,未来可以进一步增强模型在不同语言环境与表达方式下的统一映射能力,使其能够在更复杂的输入分布中,依然稳定收敛到同一套标准语义空间。另一方面,在召回与排序的协同上,当前基于显式属性的匹配机制,已经为更细粒度的相关性建模提供了良好的基础。后续可以在保持可解释性的前提下,引入更精细的属性级信号建模方式,使召回结果在保证准确性的同时,具备更强的区分能力。此外,从用户维度来看,当前系统已经具备对“Query → 商品语义”的稳定对齐能力,未来可以进一步探索在不破坏强搜索意图约束的前提下,引入用户行为信息对语义表达进行适度调节,使系统在标准语义之上具备一定程度的个性化适配能力。最后,在训练范式上,如何在保持候选空间强约束的同时,使模型更好地理解“什么是正确的生成边界”,也是后续持续优化的重要方向之一。
6. 关于我们
📩简历投递邮箱:intelligent_tech@aidc.alibaba.com
本文转载自阿里国际智能技术