


背景介绍
在 Qoder 产品家族不断壮大和用户量持续提升的背景下,用户对各个 Qoder 产品的反馈和建议也日益增多。然而,之前的反馈处理流程完全依赖人力:运营人员负责从反馈渠道导出 Excel 数据,清洗、分类后再手动录入到项目管理系统,最后由研发人工分析日志、定位问题。
这套流程的痛点非常明显——运营陷在问题录入和分派的重复劳动中,而研发人工分析日志每个问题至少需要 30 分钟以上,遇到复杂问题耗时更长。随着反馈量的增长,人力瓶颈越来越突出,大量反馈积压得不到及时响应。
我们的目标很明确:构建一套 7×24 小时无人值守的用户反馈自动处理系统——从反馈提交到问题分类、聚类、日志分析、甚至代码修复,全部由 Agent 自动完成,人只需要在最后环节对 Code Review 做终审。
产品方案
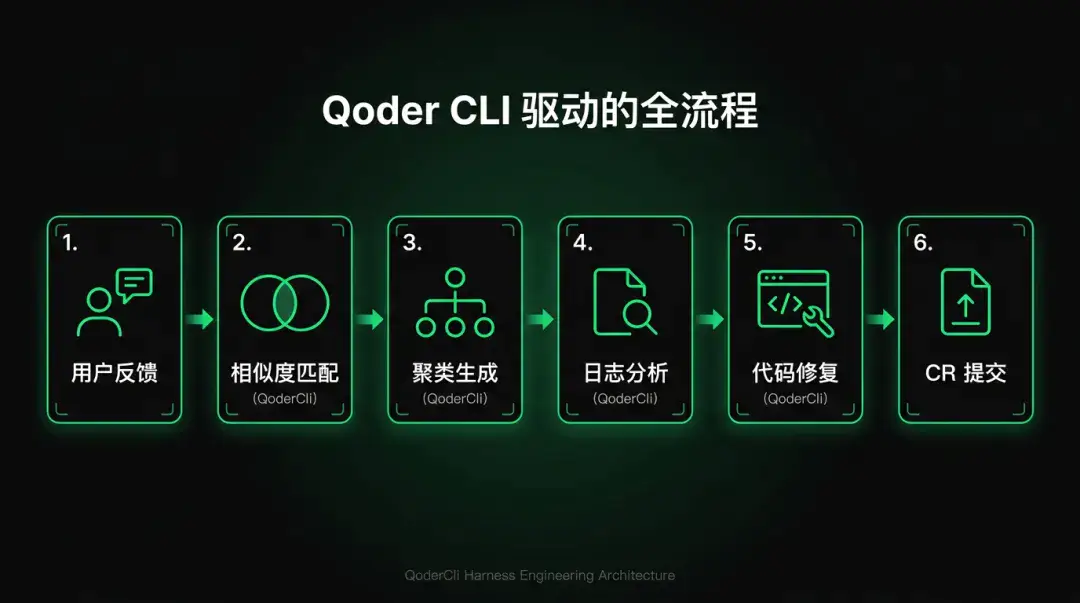
为此,我们设计了一套新的 issue 处理后台,整体分为四个核心模块,按流水线顺序串联:
-
问题分类:用户提交反馈后,系统首先自动过滤无效数据,将有效反馈分为产品建议和缺陷反馈两大类,并对缺陷反馈进一步判定业务领域细类。这一步替代了运营人员手动分类录入的工作。
-
问题聚类:在分类基础上,系统对相似问题进行聚合。这样可以减少重复问题的干扰,让后续的高级分析环节聚焦在真正需要处理的问题上,而不是被同一个 bug 的 N 条反馈淹没。
-
日志分析:针对需要深入排查的缺陷,系统结合代码库自动分析日志、提取用户操作轨迹、定位根因,并给出修复建议。这一步替代了研发逐条人工分析日志的工作。
-
自动修复:对于 AI 有较高把握能修复的问题,系统自动生成修复代码并创建 Code Review,由人工做最终评审。
在人机协作的边界设计上,我们的原则是:分类、聚类、分析这些环节完全交给 Agent 自动处理;代码修复环节由 Agent 完成编码,但保留人工 Code Review 作为质量关卡。Agent 负责吞吐量,人负责把关质量。
技术实现
为什么选 Qoder CLI
我们整套系统的 AI 能力层全部基于 Qoder CLI 实现。之所以选择 CLI 形态而非直接调用模型 API 或使用其他 Agent 框架,核心原因有几个:
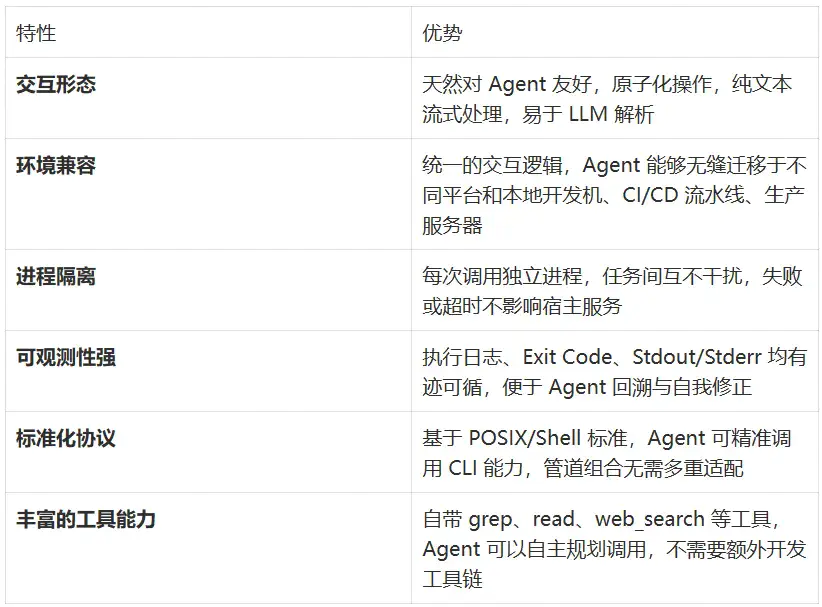
对于 Harness Engineering 这种 7×24 持续运行的场景,CLI 的随时启停、并发友好、进程隔离特性尤为关键。直接调模型 API 需要自己管理工具调用、上下文窗口、重试逻辑等大量基础设施代码,而 Qoder CLI 把这些全部封装好了,我们只需要专注于业务编排。
环境准备
在服务端应用的 Dockerfile 里增加 Qoder CLI 的安装脚本:
RUN curl -fsSL https://qoder.com/install | bash
然后在 https://qoder.com/account/integrations 复制 Access Token,并配置到环境变量 QODER_PERSONAL_ACCESS_TOKEN 中。这样就可以在服务端的代码里通过子进程调用 Qoder CLI 了。
调用时通过 -p 参数传入 prompt,启用无 TUI 交互的 headless 模式。其他一些常用的参数:
-
–yolo:自动确认模式,无需人工交互
-
–model:模型分级选择,效果越好的模型也越贵
-
–output-format=json:结构化输出,便于程序解析结果,观察思考过程
-
–worktree:独立工作区,避免多任务写文件冲突
-
–max-turns:限制最大轮次,防止无限循环浪费 tokens
问题分类
当用户提交反馈数据后,首先利用 Qoder CLI 对问题做初步分类。在这个单轮任务中,Qoder CLI 完成的事情包括:
-
过滤掉无具体反馈信息的无效数据
-
对剩下的问题分为产品建议和缺陷反馈两个大类
-
对缺陷反馈判断是否为有效缺陷
-
对有效缺陷进一步判定业务领域细类
此轮任务对模型能力要求不高,不需要深度思考,–model 用 Effective 就够了,能够节省不少成本。
问题聚类
在对 Qoder CLI 的结构化输出做解析后,我们得到了问题的分类。在不同的 category 维度下,会再进行一轮相似度匹配和聚类生成的任务。
聚类采用 Qoder CLI 做 LLM 语义化理解,而没有用传统的文本相似度算法。原因在于:相同问题可能有截然不同的描述方式,同时还需要结合用户的截图一起理解,纯文本匹配难以胜任。
在此轮任务中,我们利用 Qoder CLI Auto 模型分级的多模态能力,对截图、用户描述以及客户端环境信息进行综合分析,生成用于与已有活跃问题库进行聚类的元数据,并将这些数据传递给另一个 Qoder CLI 子进程进行聚类处理。
为了保证聚类效果,给大模型的上下文长度需要控制在一定范围之内,以免造成记忆力和注意力下降。因此我们设置了一个动态时间窗口来淘汰旧的聚类问题,根据问题的新鲜度结合时间衰减系数来提高命中正确聚类的准确性。
由于 Auto 模型分级的能力范围有限,对其输出的聚类结果我们还需要进一步动态调优。我们会让 Qoder CLI 输出一个问题相似度数据,在实际操作中可以动态调整阈值来调节聚合效果。更进一步,我们还可以用高级模型设置一个 Harness 工程系统里的「巡检员」来对聚合效果做抽样复查,根据质检结果给出相似度阈值的调整方向建议。
日志分析与根因定位
完成问题分类和聚类之后,进入更深层次的技术分析环节。此轮任务的目的是结合代码库分析日志、提取用户操作轨迹、定位根因。
这里采用Qoder CLI的性能模型,充分利用了 Qoder CLI 的 Agent 自主能力和丰富的工具调用能力。代码库和日志的体积通常非常大,全部用 read 工具读取反而会造成效果下降。Qoder CLI 在这里会聪明地根据问题描述用 grep 工具高效搜索相关内容,还会在没有提示的情况下自主规划用 web_search 工具查询 VS Code 上是否有同样的问题反馈。
在任务结束之前,我们要求 Qoder CLI 对此次任务做一次回顾复盘:是否能用更少的工具调用轮次来找到根因?本次的操作步骤里有哪些环节是无效的、可以避免的?有哪些经验教训是可以总结、避免下一次任务再犯错的?
这个总结反思的数据会单独写到一个 task-retro.md 文件里,由另一个负责流程改进的 Pipeline Agent 定期根据这份经验总结来更新对应的 Skill 内容。整个过程形成一条清晰的进化链路:
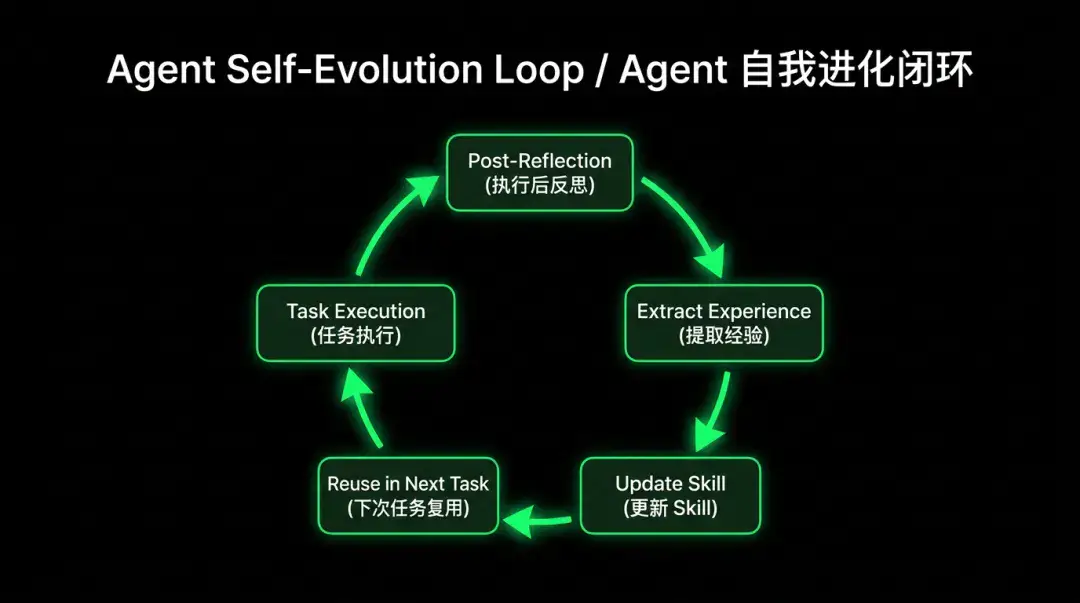
这个闭环让系统具备自我进化能力,对应了 Harness 里的 Critic → Refiner 反馈循环:每次 Agent 犯错都是一个信号,如果同一类错误反复出现,说明 Harness 本身有缺口。与其靠人去发现这些缺口,不如让系统自己分析、自己修补。
自动修复
在日志分析任务中,我们会让 AI 自主评估问题修复的确定性,并结构化输出一个修复问题的信心指数。我们设定动态阈值来触发自动修复任务。
之所以引入信心指数机制,是因为即使用上了 Ultimate 模型,当前 SOTA 的大模型能力也无法自主解决所有问题。虽然完全无人值守的 Harness Engineering 是终局目标,但在当下,我们还是得基于现实考虑成本消耗的控制,避免修复任务产出大量无效代码。在这轮任务里依赖了 Qoder CLI 的 –worktree 能力,可以支持并发地对同一个工程修复不同的 issue。
我们构建了一套问题诊断与修复的 Skill 体系:
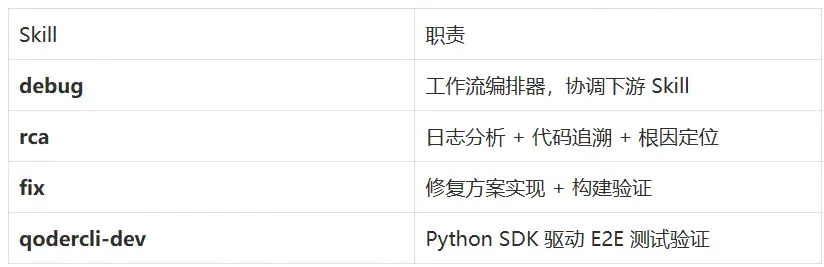
这些 Skill 协同工作,串联起一条完整的修复流水线:

为了控制成本上限,我们增加了两个手段:
qodercli -p "..." --max-turns 80 # 限制调用轮次timeout 1800 qodercli -p "..." --yolo # 限制超时时间
修复任务完成后,通过调用工单系统的 api 推送来创建 Code Review
系统自身的运维闭环
到目前为止,我们已经构建了一条从用户反馈到自动修复的完整链路。但这套系统自身也需要运维和迭代,因此我们同样采用了 Harness 的思路来建设它。
核心理念是:每一个任务失败不是终点,而是触发自检修复的起点。通过单次 Qoder CLI 调用加上 Aone 变更 MCP 提供的部署能力,Agent 能自主完成完整的自愈闭环。我们把这个流程沉淀为项目里的 devops Skill:
qodercli -p "任务 task-123456 执行失败,请诊断并修复" --yolo
devops Skill 告诉 AI「如何获取日志」「常见错误模式」「如何调用 Aone MCP 工具部署」。Agent 加载 Skill 后便自主驱动起整个修复流程:
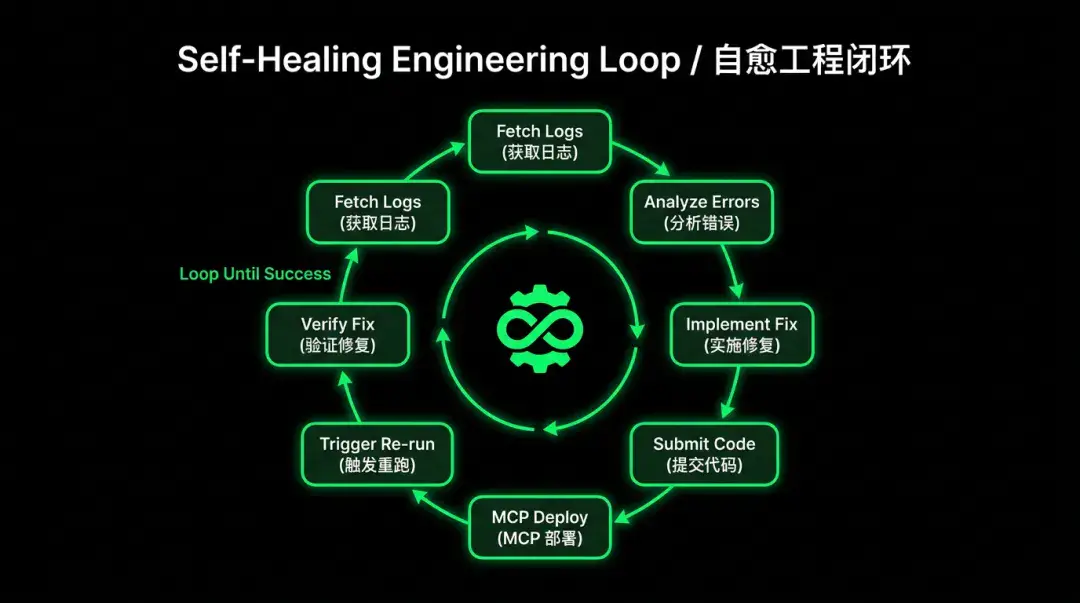
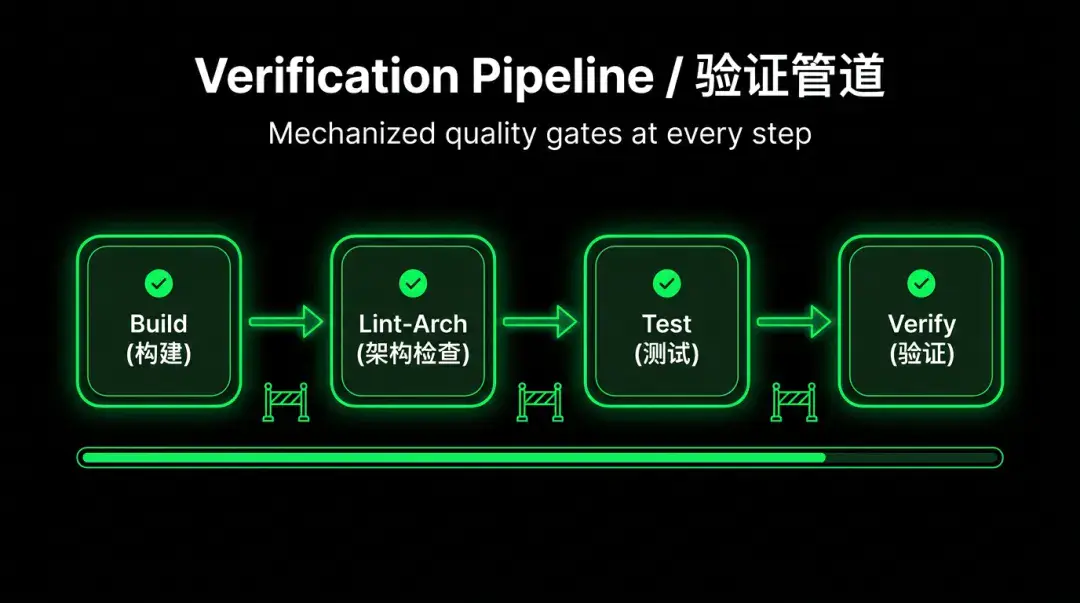
这对应了 Harness 里的验证管道思路:在每一步都设置机械化的质量关卡,不依赖 Agent 的「直觉」判断是否完成,而是用确定性的检查来保障质量。
在实践过程程序化自动调用 Qoder CLI 的过程中需要特别关注成本控制,避免出现因为程序异常而浪费了 credits。但是也不要为了节省 credits 就一刀切采用低成本的模型。从我们踩过的坑看采用便宜的模型反而是更加浪费的行为。
复杂任务必须用强模型。根因分析和代码修复这类深度推理任务,如果用低成本模型,它会在错误的方向上反复尝试,消耗大量 tokens 和时间,最终还是给不出正确答案。这种情况下不如直接上 SOTA 模型,一次到位反而更省。
简单任务用小模型。问题聚类、用户操作轨迹提取这类任务,用强模型会陷入不必要的深度思考,响应变慢不说,输出也并没有更好。用便宜的小模型反而又快又准。
最终我们摸索出来的经验是:按任务复杂度做模型分级——分类和聚类用经济模型,日志分析用性能模型,代码修复用极致等级模型。不同环节匹配不同模型,才是成本和效果的最优解。
实际效果
通过这套系统,用户反馈的处理流程发生了质的变化。以前一个问题从反馈提交到人工分析完日志、定位到根因,至少需要 30 分钟;现在系统自动完成根因分析只需要 2 分钟。
整套系统可以做到 7×24 小时不间断运行,而人在其中需要介入的部分只是对最后环节的 Code Review 做最终评审。全职运营不再需要花时间在 Excel 导入导出和手工分类录入上,研发也不用逐条人工翻日志了。
在环境设计上的投入回报是带有时间杠杆的——随着系统持续运转,Agent 的 Skill 在不断被自我复盘优化,积累的经验越多,表现也越来越好。欢迎大家多多试用 Qoder CLI,在自己的业务场景中打造能自己成长的 Harness Engineering。本文转载自@阿里云开发者公众号,原文链接
https://mp.weixin.qq.com/s/qngZyrzHYWM8wjYz4ovHXw