
最近 Pinecone 发布了一个新东西:Nexus。最早我是在抖音上看到的,说实话,这种标题挺吓人的,低劣但有效,我都忍不住要点进去:
RAG 时代终结了。
向量数据库不够用了。
Agent 需要 Knowledge Engine。
因为过去两年很多企业刚刚理解什么是 RAG,刚刚知道知识库不是把 PDF 丢给大模型,刚刚开始研究向量数据库、Embedding、Chunk、TopK、Rerank,结果现在突然有人告诉你:RAG 时代终结,那不是完了吗?
大家千万不要小看这种短视频,因为他真的会影响老板的心智,他会导致一个问题:
那企业到底还做不做 AI 知识库?
大家不要笑,这是真实在发生的事情,技术负责人要花很大的功夫去解释这一切,毕竟老板们多半只看标题不看内容…
当然,也会有一些“心志不坚”(对 AI 体系不了解)的产研负责人会疑惑甚至焦虑:刚学会走路,就被通知走路这件事已经落后了?
我觉得这里需要冷静一点:
RAG 没有消失,消失的是低配 RAG,毕竟低配 RAG 本来也没解决什么问题
所谓低配 RAG,就是传统三件套:
上传文档
↓
切成 chunk
↓
向量化
↓
用户提问时召回 TopK
↓
塞给大模型
↓
生成答案
如果问题简单,比如客服 FAQ、产品说明、内部制度查询,这套东西也能使用。
但如果你要让 AI 真正进入企业流程,帮你做合同审查、项目复盘、医疗辅助决策,这套朴素 RAG 就会开始暴露问题:
召回不稳定
证据不完整
表格读不准
上下文拼不全
引用对不上
多文档比较困难
权限不好控制
答案经常看起来对,其实依据很弱
综上,我深入研究 Nexus 后,我觉得他要表达的也不是 RAG 没了,而是在倡导新的范式:AI 知识库的重点,正在从检索片段走向编译知识。
关于这里的知识,我们在前两天讨论 NoteBookLM 的时候已经做了讨论,今天继续围绕 Nexus 做下简单扩展:
Nexus 是什么
Pinecone 原来是典型的向量数据库公司。
按理说,它最应该继续强化一个叙事:向量数据库是 AI 应用的核心基础设施。
只不过,随着模型的发展和我们在 AI 知识库的实践,大家都慢慢意识到貌似向量库不是必须,他跟 AI 知识库并不是绑定关系。
出于生存考虑,很多向量数据库公司都不得不贴着 AI 知识库讲新的故事,Nexus 就是这个场景下的产物。
因为既然向量库是“过时”的产物,所以 Pinecone 对 Nexus 的定位就肯定不是一个更强的向量库,而是:
Knowledge Engine for Agents,也就是面向 Agent 的知识引擎
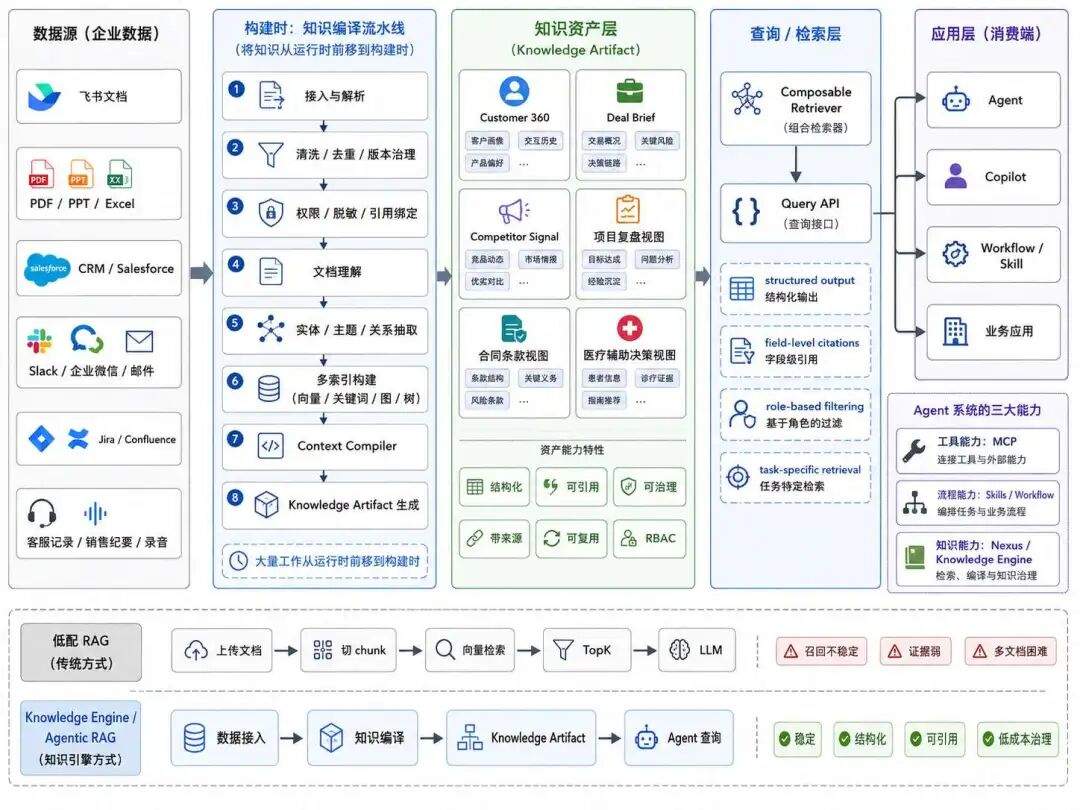
Pinecone 官方介绍里,Nexus 主要有两个核心组件:Context Compiler 和 Composable Retriever。
前者负责围绕企业业务结构组织知识,后者负责按照不同 Agent 的任务需求,把知识以合适格式返回给 Agent。
这句话听起来非常抽象,翻译一下就是,以前 RAG 是用户提问以后,系统临时去文档里找片段。Nexus 想做的是:
在 Agent 使用之前,先把企业数据提前整理、结构化、编译成任务可用的知识资产
前两天我们聊 NotebookLM 的时候,其实已经讲过类似的趋势。NotebookLM 给用户的体验是:你把资料上传进去,它可以围绕资料做问答。
并且,从表面上看,NotebookLM 好像完全没有 RAG 的痕迹:
看不到 chunk
看不到向量库
看不到 TopK
看不到 rerank
看不到 score 阈值
但这不代表它没有 RAG,而是 Google 把 RAG 的工程链路产品化、黑盒化了。
综上,Nexus 和 NotebookLM 虽然不是一个产品类型,但背后的方向是一致的:
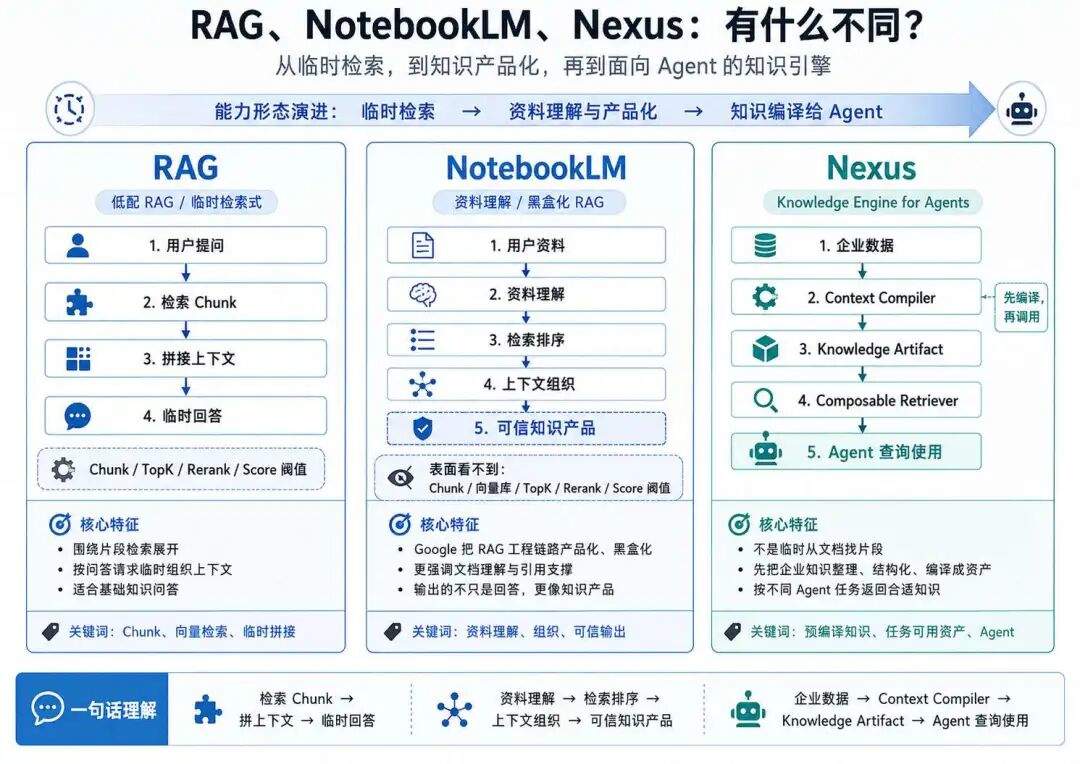
低配 RAG:
检索 chunk → 拼上下文 → 临时回答
NotebookLM:
资料理解 → 检索排序 → 上下文组织 → 可信知识产品
Nexus:
企业数据 → Context Compiler → Knowledge Artifact → Agent 查询使用
再往前看,Karpathy 提出的 LLM Wiki 也是这个方向。LLM Wiki 的核心观点是:传统 RAG 最大的问题,是每次回答都在临时拼答案,知识没有被持续沉淀。
更好的方式是:让 LLM 持续读取资料、维护一个结构化 Wiki,里面有实体页、主题页、交叉引用、矛盾点和综合结论。
至此,大家应该对 Nexus 有了初步印象,这里再补一句:
-
NotebookLM 是一个面向用户的 AI 知识库产品; -
LLM Wiki 是一种知识组织架构/方法论; -
Nexus 是 Pinecone 面向企业 Agent 应用推出的“知识基础设施层”。
Nexus 的野心是有点大的,他试图把企业数据提前编译成任务可用的知识资产,再通过统一查询接口交给 Agent 使用:
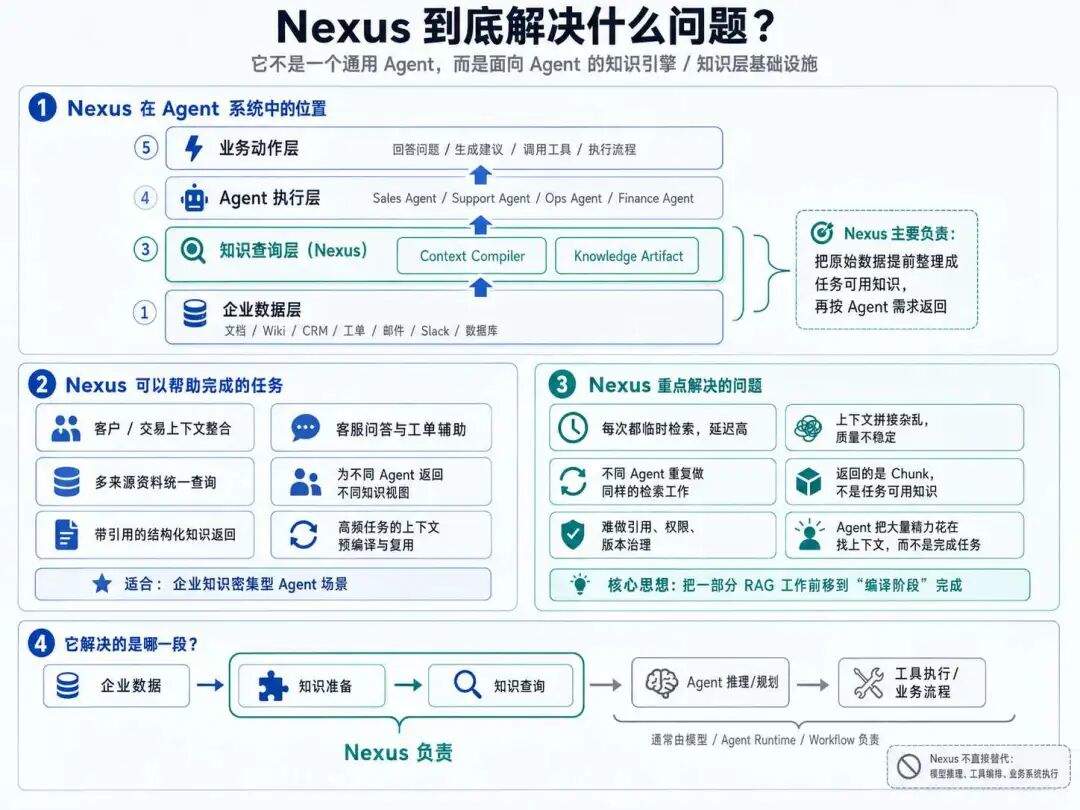
这里大家可能不太理解,Nexus 目标并不是更好的 RAG,而是想成为 Agent 时代的 Knowledge Infrastructure。
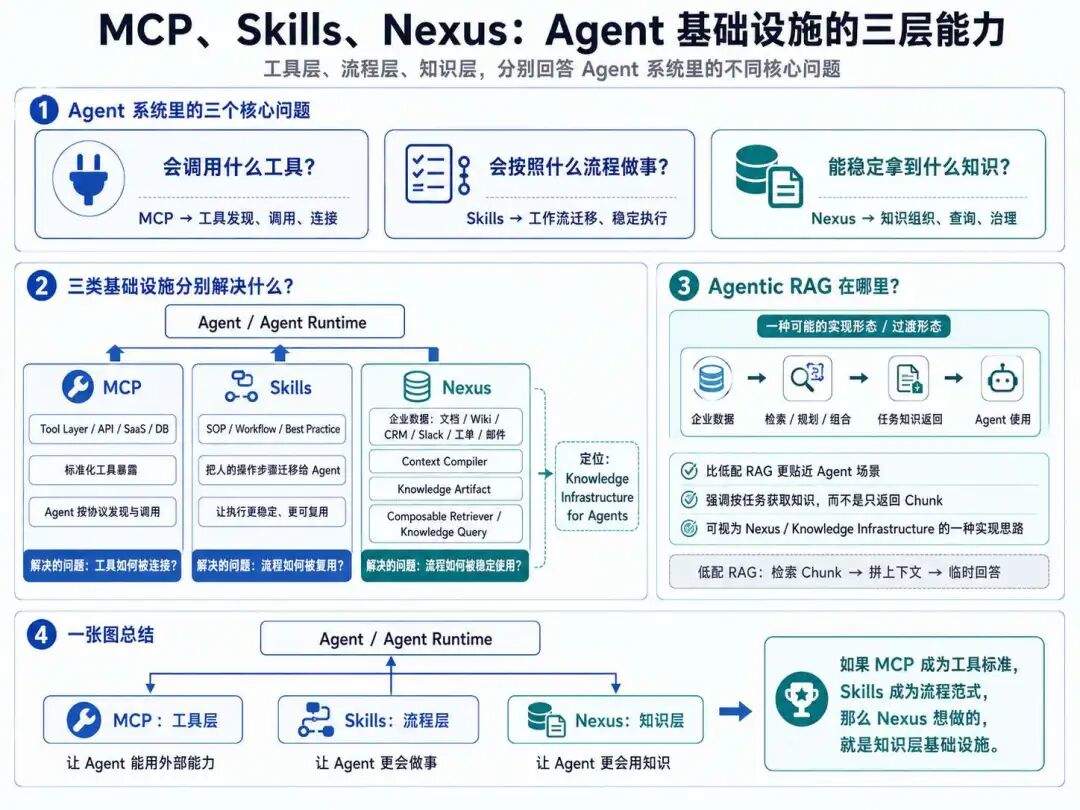
从我们现在的知识框架来说,这三个东西分别对应 Agent 系统里的三块核心能力:
-
会调用什么工具? -
会按照什么流程做事? -
能稳定拿到什么知识?
MCP 解决的是第一个问题:工具如何被 Agent 发现、调用、连接。
Skills 解决的是第二个问题:人类已有工作流、操作习惯、执行步骤,如何迁移给 Agent。
Nexus 想解决的是第三个问题:企业知识如何被 Agent 稳定、低成本、可治理地使用。
我们之前常说的 Agentic RAG Nexus 可能就是其中一种实现:
至于这一切是如何实现的,有个关键词:编译知识。
编译知识
编译知识,这个词听起来有点玄,但如果你是程序员应该很好理解。
我们写代码的时候,不是每次运行程序都重新理解一遍源代码,而是会经过编译、构建、打包,形成可执行产物。
传统 RAG 的流程是:
每次用户提问
↓
临时去文档里搜索
↓
临时找上下文
↓
临时让模型理解
↓
临时生成答案
Nexus 想表达的流程是:
企业原始数据
↓
提前解析、清洗、结构化
↓
围绕任务生成 Knowledge Artifact
↓
Agent 查询时直接使用
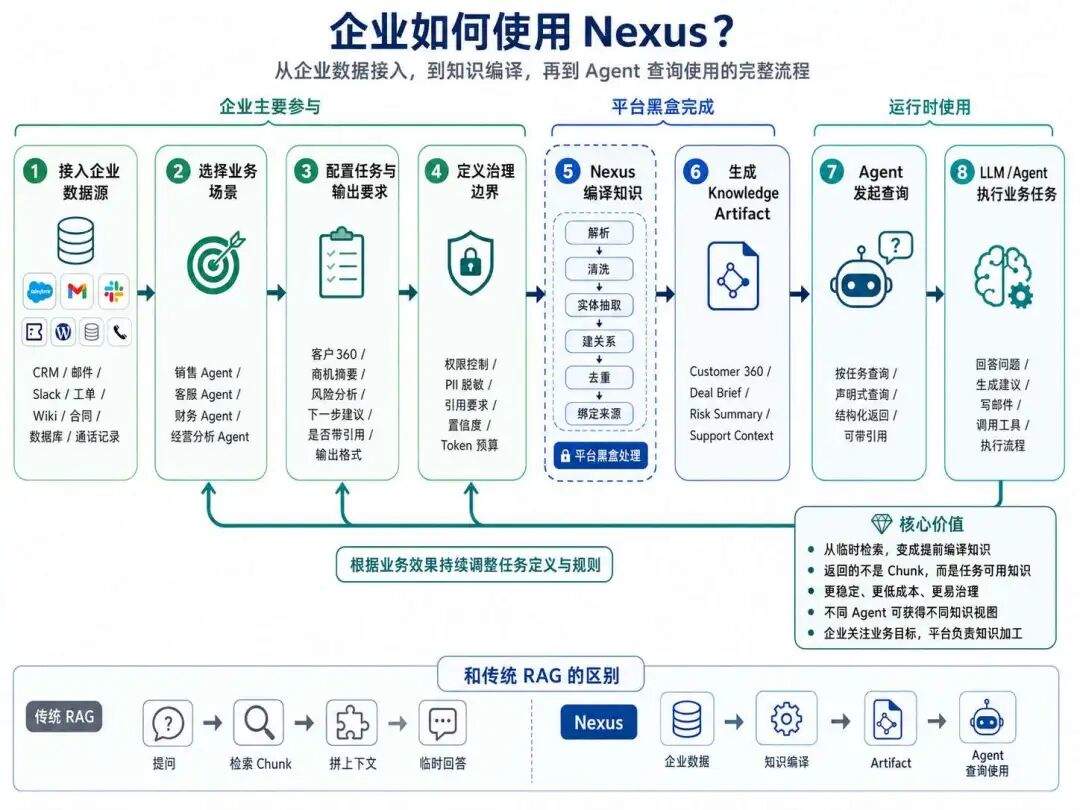
也就是说,它把大量工作从运行时前移到了构建时,这种编译知识的好处是:
提前结构化
提前消歧
提前绑定来源
提前做好权限
提前形成任务视图
提前沉淀可复用资产
这里核心想解决的是:怎么让 Agent 在企业复杂任务中稳定、低成本、可治理地使用知识。
值得注意的是编译知识是一个美好的愿望,暂时来说 Nexus 也没有被大量使用,他更像是一种在 AI 知识库上新技术范式的尝试:
概念很清晰,官方给了典型案例和早期效果数据,但真实大规模落地案例还不多。
这里有个官方案例:
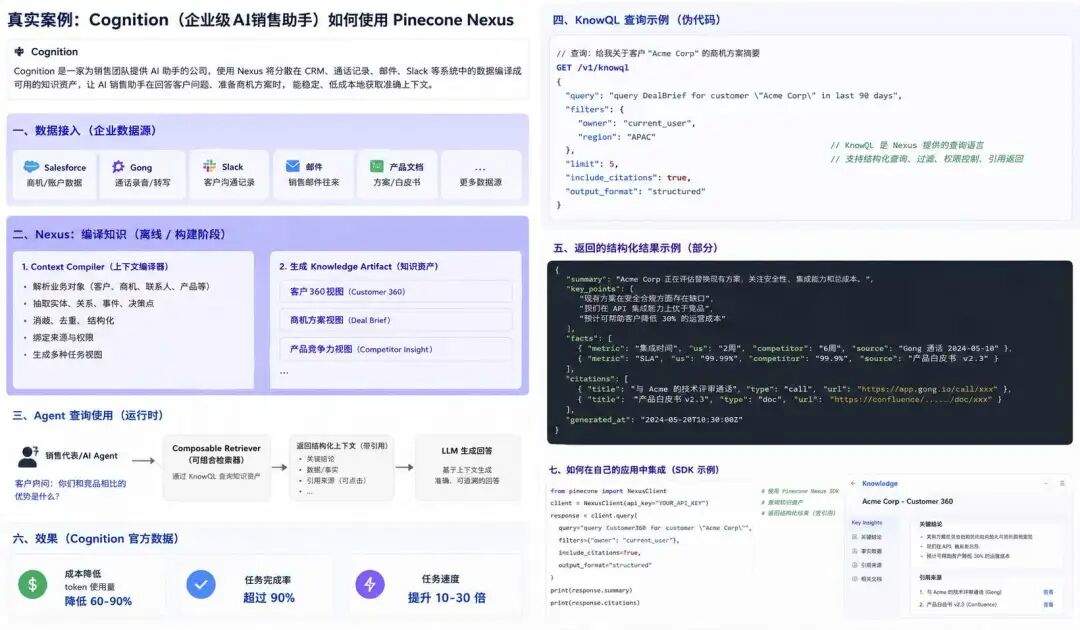
我这里做下详细说明,大家可以感受下,我们从产品/技术范式出发,Nexus 的使用方式可以拆成四步:
第一步:接入企业数据
第二步:定义 Agent 任务
第三步:编译 Knowledge Artifact
第四步:Agent 查询并使用结构化知识
这里第二步、第三步对于企业来说都是黑盒,任务定义企业大概率还得参与;而知识编译由 Nexus 这类平台黑盒完成。
意思是,他内部怎么抽实体、怎么建关系、怎么生成 Knowledge Artifact,我们是不知道的:
因为这套范式不稳定,我们重点看看 Agent 知识查询这块(官方案例):
# 企业开发者更可能做的是配置,而不是手写知识编译逻辑
nexus_project = NexusProject.create(
name="sales_agent_knowledge",
data_sources=[
"salesforce",
"gong",
"slack",
"gmail",
"jira",
"confluence"
],
scenario="sales_agent",
tasks=[
"customer_360",
"deal_brief",
"competitor_signal",
"next_step_recommendation"
],
policies={
"rbac": True,
"pii_masking": True,
"field_level_citations": True
}
)
# 下面这一步大概率是平台黑盒完成
nexus_project.build_artifacts()
# Agent 运行时只负责查询
result = nexus.query(
scenario="sales_agent",
task="deal_brief",
entity={
"customer": "Acme Corp"
},
output_format="structured",
include_citations=True
)
喷两句
好了都已经到这了,大家应该会感觉内容有点空,那确实很空,因为这东西还很不成熟,而就是这么不成熟的东西,很多人看了都会想去做一个什么Knowledge Engine…
先说要不要再说能不能,暂时当然是不要,其次 Nexus 代表的是一个可能的高级方向,但并不代表普通企业今天就应该照着做,并且多数公司也做不了,毕竟做向量数据库还是需要一些门槛的;
而且,现在很多企业连最基础的知识治理都没做好,他们资料散落在: 飞书文档、 企业微信、 微信群、 PDF、 PPT、 Excel、 CRM、 客服聊天记录、 销售个人电脑、 老板脑子里 ……
然后这些资料本身还充满问题:版本冲突、内容过期、口径不一……
如果企业内部连文档在哪、两个相同的文档,哪份资料是最新版都说不清,那就算给你 Nexus,你也很难用好。
那么问题来了,对于 Nexus 这种东西,普通企业真正该关注什么?
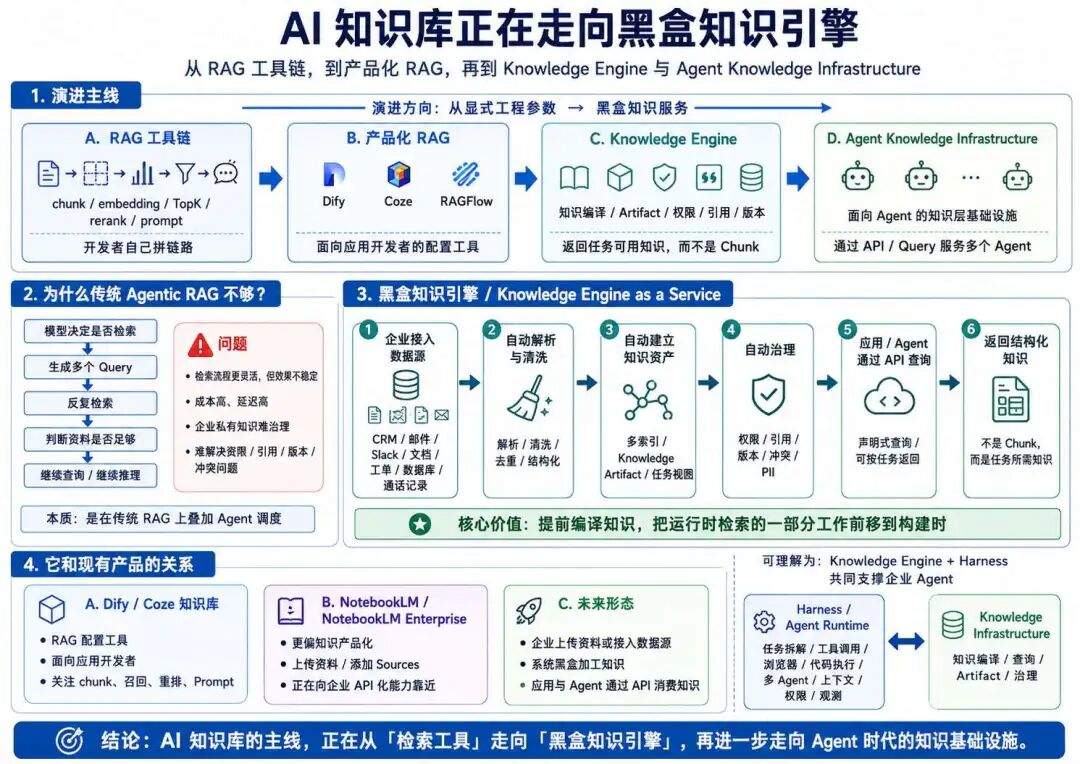
我觉得是关注趋势以及吸收一些方法论,比如 AI 知识库建设的方法论,因为 Nexus 本身未必会成为最终答案,但它释放出来的信号很明确:AI 知识库正在从检索系统,走向知识工程系统。
Agentic RAG
现阶段 AI 知识库的主线,确实正在沿着黑盒化知识引擎这个方向演进。
这个未必是我们技术人期望的技术主线,但一定是各个基模/向量库企业想要做的事情,因为这样的话他们收益足够大。
这个事情的背后不会简单等于把数据丢进去,什么都自动解决,而是会经历一个从 RAG 工具链 → 产品化 RAG → Knowledge Engine → Agent Knowledge Infrastructure 的过程:
事实上这也是之前我们常说的一个名词 Agentic RAG,只不过后面大家渐渐不用了,因为 Agentic RAG 这个词有点泛化了,没有最佳实践,甚至没有稳定的定义。
有些人说 Agentic RAG,指的是:
模型自己决定要不要检索
模型自己生成多个 query
模型自己反复检索
模型自己判断资料够不够
模型自己根据结果继续查
这是在传统 RAG 上加了一层 Agent 调度,解决的是:检索流程更灵活。
但效果有点差,而且企业私有知识如何被稳定、低成本、可治理地使用,这个问题没有被很好的回答。
Manus、OpenClaw、Hermes 这类 Agent 产品的关注点会放在 Harness,他包含了 任务拆解、 工具调用、 浏览器操作、 代码执行、 多 Agent 协作、 上下文管理、 权限控制、 执行观测……
于是,黑盒知识库产品的架构设想或者产品设想出现了,而且大概率会出现,只不过不能解决所有问题,这种产品大概长这样:
企业把数据源接进去
↓
系统自动解析、清洗、去重、结构化
↓
系统自动建立多种索引和知识 artifact
↓
系统自动处理权限、引用、版本、冲突
↓
应用或 Agent 通过 API 查询
↓
返回的不是 chunk,而是任务需要的结构化知识
这就是 Knowledge Engine as a Service,这跟之前的 Dify、Coze 里的知识库不太是一类东西:
一个是面向应用开发者的 RAG 配置工具
另一个是面向企业 Agent 的知识基础设施
举个例子,NotebookLM 现在更偏 2C 的 AI 知识库产品,但 Google 已经有 NotebookLM Enterprise,官方介绍里已经包括企业级共享 notebook,并且文档里也有创建 notebook、添加 sources 的 API 说明。
NotebookLM 这类产品如果继续往 2B 走,确实可能变成企业上传资料/接入数据源,然后通过 API 消费知识的基础设施。
AI 知识库会越来越像这样,你只需要告诉系统:
-
这些资料是什么; -
哪些人可以用; -
这个知识空间服务什么任务; -
返回结果需要什么结构; -
哪些结论必须可引用; -
哪些问题必须拒答或转人工。
至于底层是向量检索、关键词检索、图检索、树检索、rerank、多 query、long context,用户不应该关心。
所以回到最开始那个问题:RAG 时代真的终结了吗?
那当然是没有的