
35 小时写了一个 GPU 内核驱动,加速比 10 倍。这不是科幻,是 Qwen3.7-Max 长周期自主执行实验的真实结果。阿里云峰会上刚发布的这个新旗舰,编程智能体、高难度推理、办公自动化三项维度全面超越 Claude Opus 4.6,Arena 全球总榜国产第一。但闭源、API 还没上线、价格也不透明。到底能不能打,上手再说。
这是什么模型
Qwen3.7-Max 是阿里巴巴通义千问团队在 2026 年 5 月 20 日阿里云峰会上发布的全新旗舰大模型。一句话定位,面向智能体时代的全能基座。它不是聊天机器人,不是写作助手,而是一个能自主编程、长周期执行任务、跨框架稳定运行的 Agent 底层引擎。
和前代 Qwen3.6 系列相比,这次升级不是挤牙膏。Arena 全球大模型盲测总榜中,Qwen3.7-Max 拿下国产第一,综合排名进入全球前三。阿里千问这次瞄准的对手很明确,Claude Opus 4.6。
模型是闭源的,仅通过阿里云百炼 API 对外提供服务。但好消息是它同时兼容 OpenAI 和 Anthropic 两种协议,已有的工具链基本不用改就能切过来,生态迁移成本几乎为零。
到底强在哪
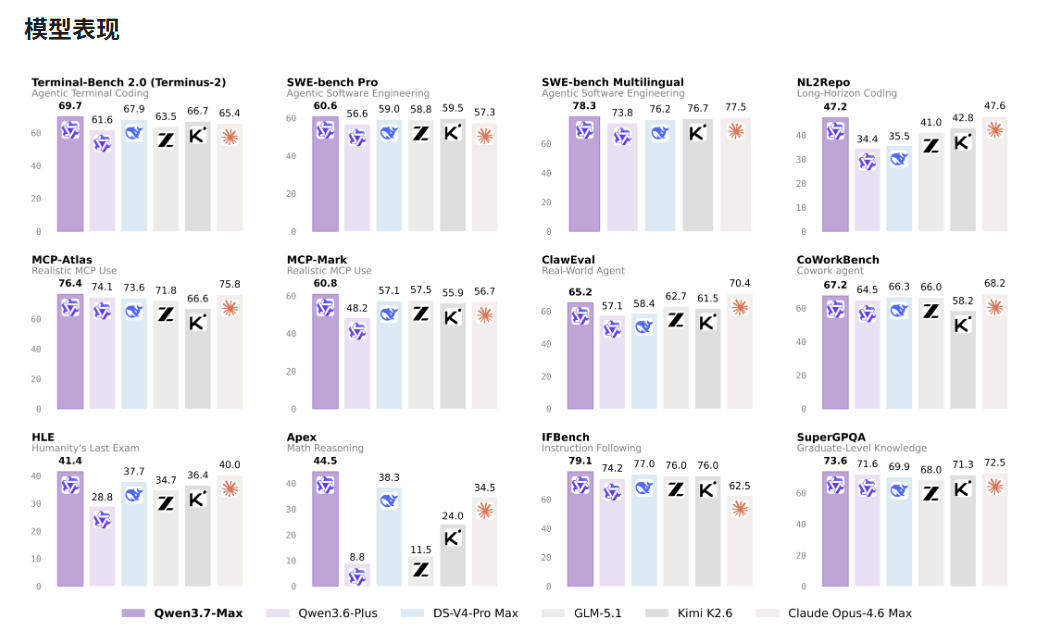
Benchmark 数据亮得有点不真实,那我们挑几个最能打的领域,看它到底凭什么敢叫板 Claude。
编程智能体:多项登顶
编程能力是这次升级最硬核的部分。Qwen3.7-Max 在 SWE-Pro(软件工程)、SWE-Multilingual(多语言编程)、SciCode(科学计算)、Terminal-Bench 2.0(终端智能体)四个编程 Agent 核心基准上,全部领先或持平 Claude Opus 4.6。
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro |
|---|---|---|---|
| SWE-Pro | 60.6 | 57.3 | 59.0 |
| SWE-Multilingual | 78.3 | 77.5 | 76.2 |
| SciCode | 53.5 | 51.9 | — |
| Terminal-Bench 2.0 | 69.7 | 65.4 | 67.9 |
| SWE-Verified | 80.4 | 80.8 | — |
全链路编程任务,从原型到复杂工程,几乎每个维度都在咬住甚至反超 Opus 4.6。SWE-Verified 只差 0.4 分,在可感知的误差范围内基本持平。
高难度推理:GPQA Diamond 登顶
Qwen3.7-Max 在推理领域的表现更让人意外。GPQA Diamond 得分 92.4,超越 Claude Opus 4.6 的 91.3。HMMT 2026 Feb 数学竞赛 97.1 分,IMOAnswerBench 拿到 90.0 分,这两个都是纯推理任务,几乎没有知识记忆的加成空间。
更重要的是 Apex 基准,这是目前最难的综合性推理测试,44.5 分的成绩比 DeepSeek V4 Pro 的 38.3 高出 6.2 分,比自家前代的 8.8 分提升了足足 5 倍。
长周期自主执行:35 小时硬核实测
说千道万不如跑一个真实任务。阿里千问团队做了一个极端的压力测试,让模型在一个完全没见过的硬件平台(平头哥真武 M890 PPU)上,仅凭指令手册和 SGLang 框架,从零写出 GPU 内核驱动并进行性能优化。
整个过程持续了约 35 小时,模型自主完成了 432 次内核调用、1158 次工具调用,包括写代码、性能分析、Bug 修复、反复迭代。最终产出的内核代码加速比达到 10 倍。作为对比,同在 M890 硬件上,GLM 5.1 的加速比只有 7.3 倍,Kimi K2.6 是 5.0 倍,DeepSeek V4 Pro 只有 3.3 倍。
更关键的一个细节是:30 小时后模型依然在发现有意义的优化方向。没有卡死,没有退化,反而越跑越聪明。对于需要长时间自主运行的企业级任务来说,这是比 Benchmark 分数重要得多的能力指标。
跨框架和办公自动化
Qwen3.7-Max 的另一点差异化是跨框架泛化。它不针对某个特定 Agent 框架做优化,在 Claude Code、OpenClaw、Qwen Code 以及各类自定义框架下表现都很稳定。MCP-Mark 通用 Agent 基准 60.8 分,MCP-Atlas 76.4 分,都超过了 Opus 4.6。
办公自动化方面同样强势。SpreadSheetBench-v1 拿到 87 分,在论文格式自动修复、文档批处理等办公任务上表现突出。YC-Bench 创业模拟场景中,它在虚拟经营里做到了 208 万美元营收,是 Qwen3.6 的两倍、Qwen3.5 的近六倍。
从零开始试
说了这么多参数,用起来到底什么感觉?我通过 Qwen Chat 在线版完整跑了一遍典型路径。
入口是 chat.qwen.ai,网页版直开,不用下载客户端。界面比之前干净了不少,核心区只有一个对话框和模型选择下拉菜单。选到 Qwen3.7-Max 后,我先丢了一个典型需求进去:用 Three.js 写一个可交互的 3D 粒子星系,带鼠标拖拽旋转和缩放。大概等了十几秒,前端代码一次性输出,HTML、CSS、JS 全在同一个文件里。复制粘贴跑起来之后,旋转流畅,缩放灵敏,粒子颜色还是渐变的。第一印象不错。
接着试了一把多文件工程任务。让它分析一个开源 Python 项目的代码结构,给出重构建议。模型先拉出了模块依赖树,然后逐个文件标注了循环依赖和可以拆分的函数。输出格式是带行号的 diff,直接贴进编辑器就能用。
槽点也有。思考模式下的首字响应时间不太稳定,简单任务偶尔也要等好几秒。而且目前 Qwen Chat 上只能跑纯文本交互,像终端命令执行、文件系统访问这些真正的 Agent 能力得通过 API 接到 Claude Code 或 OpenClaw 才能发挥出来。
进阶玩法
基础操作不复杂,但有些用法你不仔细试根本发现不了,这几个是我跑了一整天之后觉得最有价值的:
-
preserve_thinking 模式:在 API 调用时加一个参数,模型在多轮对话中会保留所有前序轮次的思考链。对于 Agent 长链路任务,比如分 10 步部署一个 Kubernetes 集群,每一步都能看到前面的推理过程,中间不会被上下文截断打乱。这个功能目前只有通过 API 才能启用,网页版还不支持。 -
Claude Code 配百炼端点:把 ANTHROPIC_MODEL环境变量设成qwen3.7-max,ANTHROPIC_BASE_URL指向百炼的 Anthropic 兼容端点,Claude Code 底层就跑 Qwen3.7-Max 了。对已经用 Claude Code 的团队来说,切换成本就是改两行配置。实测编程表现和原生 Claude Code 的差距已经很小。 -
OpenAI 协议直调:如果团队用的是标准的 OpenAI SDK,直接把 base_url换成百炼兼容端点、model设成qwen3.7-max就行。不需要装任何新 SDK。这个兼容性意味着大多数 AI 应用几乎可以零成本切换。 -
YC-Bench 玩法:启动一个模拟经营场景,让模型跨数百轮做商业决策。它会自动保存之前的经营数据、识别策略盲区、在后续轮次修正方向。对需要长期策略规划的团队来说,这比静态问答的效果好得多。
和同类比怎么样
参数上没输过,那放到真实赛道和竞品一块儿看,到底谁更值得选。
大模型旗舰赛道现在基本是四家混战,Claude Opus 4.6、DeepSeek V4 Pro、GLM 5.1、Kimi K2.6。Qwen3.7-Max 这次发布直接奔着 Opus 去的。
| 维度 | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro | GLM 5.1 |
|---|---|---|---|---|
| 编程 Agent | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 高难度推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 长周期自主执行 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 跨框架稳定性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 生态兼容性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 前端开发 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 中文本土化 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
核心差异在于两点。一是编程 Agent 的全面性,Qwen3.7-Max 是目前唯一在几乎所有编程基准上同时咬住或反超 Opus 4.6 的模型,不是单项爆种。二是跨框架泛化,Opus 4.6 在不同框架下的表现有波动,而 Qwen3.7-Max 在 Claude Code、OpenClaw、Qwen Code 三个主流框架上的成绩几乎持平。这种一致性对企业来说意味着切换框架时不需要重新评估模型能力。
但前端开发是 Qwen3.7-Max 的短板。QwenWebDev 评分 1568,低于 Opus 4.6 的 1617 和 GLM 5.1 的 1605。如果你的主要场景是前端页面生成,Opus 或者 GLM 可能更合适。
真实用户怎么说
成绩好看归好看,来看一波实际用过的人怎么评价。发布会刚开一天,但各大技术社区已经热闹起来了。
社区里最热烈的讨论集中在长周期自主执行实验上。不少开发者被 35 小时、1158 次工具调用、10 倍加速这些数字震撼到了,“以前觉得 Agent 过五个来回就会崩,这次连跑一天半还在进化”。知乎上有开发者实测后表示,编程 Agent 确实在 SWE-Pro 级别任务上跟 Opus 4.6 打平了,尤其在多文件重构场景里表现很稳。
吐槽的声音主要集中在两点。一是 API 还没正式上线,发布会开了、成绩公布了,但想接入的开发者暂时只能看不能用,有点干着急。二是价格完全没谱。旗舰模型的推理成本通常不低,加上 Qwen3.7-Max 在思考模式下的 token 消耗量可能更大,社区普遍担心开放后的定价”不够亲民”。知乎上有用户直言,速度和价格可能是选型时的最大障碍。
多维评分
评价有赞有踩,那从专业维度拉一个量化的分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | Agent 全链路能力覆盖,编程到办公一应俱全 |
| 易用性 | ⭐⭐⭐⭐☆ | API 兼容双协议很友好,但网页版能力受限 |
| 性价比 | ⭐⭐⭐☆☆ | 定价未公布,旗舰模型推理成本预计偏高 |
| 创新性 | ⭐⭐⭐⭐☆ | 跨框架泛化和 35h 长周期实验是真正差异化 |
| 稳定性 | ⭐⭐⭐⭐☆ | 多框架表现一致性优秀,部分场景响应有波动 |
| 推荐度 | ⭐⭐⭐⭐☆ | Agent 开发者和科研团队值得第一时间接入 |
综合评分:8.3 / 10
优点和槽点
优势
-
编程 Agent 全面领先:四项编程核心基准全部持平或超越 Claude Opus 4.6,全链路覆盖完整 -
长周期自主执行能力惊人:35 小时/1158 次工具调用的实测数据,远超所有国产竞品 -
跨框架泛化不绑定生态:Claude Code、OpenClaw、Qwen Code 三大框架下表现一致稳定 -
高难度推理多项登顶:GPQA Diamond、HMMT、Apex 全面突破,推理能力达到全球第一梯队 -
API 双协议兼容:同时兼容 OpenAI 和 Anthropic 协议,现有工具链几乎零成本迁移
不足
-
闭源且不可本地部署:无法私有化部署或自定义微调,对数据安全要求高的场景不适合 -
API 尚未正式上线:发布后接入延迟,想用的团队暂时只能等 -
定价完全未知:作为旗舰模型推理成本可能偏高,性价比无法提前评估 -
前端开发生成非强项:QwenWebDev 评分略低于 Opus 和 GLM,纯前端场景建议看其他选项
适合谁用
一句话概括,Qwen3.7-Max 是给需要 Agent 能力的人准备的,不是给所有人准备的。
-
AI Agent 开发者:编程智能体各项表现已经跟 Claude Opus 4.6 打平甚至反超,Claude Code 两行配置就能切过来。对于已经在做复杂编程 Agent 的团队,这是目前最有性价比的国产替代方案。 -
企业办公自动化团队:MCP-Mark 和 MCP-Atlas 成绩优秀,跨框架一致性也好。如果你的团队在用 MCP 做企业流程自动化,Qwen3.7-Max 的多 Agent 编排和长周期执行能力会让你省掉很多中间件。 -
科研和数学场景:GPQA Diamond、HMMT、Apex 成绩摆在那。做高难度推理、数学竞赛、科学计算的话,这是目前国产模型里唯一能在推理维度跟 Opus 正面打的产品。 -
长周期任务场景:GPU 内核优化、RL 训练监控、代码仓库级重构,这些需要模型连续运转几十小时的任务,Qwen3.7-Max 用实测数据证明了它不是跑一两个小时就崩的玩具。 -
嫌贵劝退的:如果你只是日常写写代码、改改 Bug、写写文档,Qwen3.7-Plus 甚至 DeepSeek V4 完全够用,没必要冲着旗舰多花钱。前端开发为主的团队也更建议看看 GLM 5.1。
多少钱
最让人纠结的部分来了,Qwen3.7-Max 的具体定价还没公布。目前只能通过阿里云百炼平台申请 API 接入权限,正式定价以官方后续公告为准。
从系列定位判断,Qwen3.7-Max 是闭源旗舰,推理成本预计不会低。Qwen3.6-Max 的 API 价格在当时就不算便宜,3.7 版加了更强的思考模式和更长上下文,token 消耗量大概率更大。如果预算紧张,Qwen3.7-Plus 或者 Qwen3.7-Flash 可能是更务实的选择,前者日常任务够用,后者适合高吞吐低成本场景。
| 版本 | 定位 | 预估价格 | 适合场景 |
|---|---|---|---|
| Qwen3.7-Max | 旗舰 | 预计较高 | Agent、长周期推理、科研 |
| Qwen3.7-Plus | 中端 | 待公布 | 日常开发、办公自动化 |
| Qwen3.7-Flash | 轻量 | 最低 | 高并发、低成本场景 |
等价格出来之后,性价比这块才能下最终结论。现在只能说,能力没毛病,就看你舍不舍得为它花钱了。
常见问题
看完这么多数据,你可能还有几个关键问题想搞清楚。
Q1:Qwen3.7-Max 开源吗?
A1:不开源,闭源旗舰模型。 仅通过阿里云百炼 API 对外提供服务,无法本地部署或自定义微调。如果对数据安全有强要求或需要私有化部署,建议等开源版本或看其他选项。
Q2:API 能用了吗?价格多少?
A2:尚未正式上线,定价未公布。 模型于 5 月 20 日发布,API 即将通过阿里云百炼上线。定价以官方公告为准。基于旗舰定位判断,推理成本不低,建议提前评估用量。
Q3:跟 Claude Opus 4.6 比到底谁强?
A3:综合打平甚至略胜,但各有擅长。 编程 Agent、高难度推理、长周期自主执行维度 Qwen3.7-Max 领先。前端开发和 SWE-Verified 维度 Opus 略好。选哪个取决于你的核心场景。
Q4:能在 Claude Code 里用吗?
A4:可以,两行配置搞定。 设置环境变量 ANTHROPIC_MODEL=qwen3.7-max 和 ANTHROPIC_BASE_URL 指向百炼 Anthropic 兼容端点,Claude Code 底层就跑 Qwen3.7-Max 了。
Q5:是否兼容 OpenAI SDK?
A5:完全兼容。 base_url 换成百炼兼容端点、model 设成 qwen3.7-max 即可,不需要装新 SDK。openai-python 和 langchain 等主流框架都直接支持。
Q6:35 小时长周期实验是怎么做的?
A6:在完全未训练的硬件上从零写内核驱动。 模型拿到指令手册后,自主完成 432 次内核调用和 1158 次工具调用,连续运行 35 小时并在 30 小时后仍发现新优化方向,最终加速比 10 倍。
Q7:中文本土化表现如何?
A7:国内模型天然优势。 多语言编程基准 SWE-Multilingual 成绩第一,中文理解深度远超 Claude 和 DeepSeek。中文场景的办公自动化、文档处理等任务有天然加分。
Q8:前端开发适合用 Qwen3.7-Max 吗?
A8:不是强项,但不差。 QwenWebDev 评分 1568,略低于 Opus 4.6 的 1617 和 GLM 5.1 的 1605。如果主要场景就是写前端页面,Opus 或 GLM 可能更适合。
Q9:相比之下 Qwen3.7-Plus 值得用吗?
A9:日常开发更务实的选择。 如果不需要极致的 Agent 长周期能力和高难度推理,Plus 版性价比大概率更高。Max 是给重度 Agent 场景准备的,不是给日常用的。
Q10:和 DeepSeek V4 Pro 怎么选?
A10:Max 在 Agent 和推理维度碾压,V4 Pro 生态更成熟。 如果你看重编程 Agent 和长周期自主执行能力,Qwen3.7-Max 明显更强。如果已经深度绑定了 DeepSeek 生态且对价格敏感,V4 Pro 依然是稳妥选择。
最后总结
Qwen3.7-Max 不是一台”更好用的 AI 聊天机器人”,它是一个严肃的 Agent 基座。阿里这次没有走”参数更大、分数微涨”的老路,而是用 35 小时的长周期实测和跨框架一致性证明了一点:在 Agent 时代,国产大模型可以跟 Claude 正面打,并且打赢。
对于认真做 AI Agent 的团队,Qwen3.7-Max 是目前国产模型里最值得接入的选择。对于日常开发者,不用着急,等价格出来、生态成熟了再看也不迟。对于只做前端的团队,可能得再等等。
建议所有对 Agent 方向有投入的团队,价格公布后第一时间试用。就目前公开的数据来看,这东西值得等。