
依旧延续周一 TGO 闭门会的分享思考,核心话题是:如何真正蒸馏一个人 + 如果完成了蒸馏动作,应该如何形成企业级 Agentic RAG 数据库类应用?
怎么说呢,现阶段为了适应 Agent 发展,模型本身已经往前走了很大一步,最核心的两个能力:
-
一个来自于模型本身,提供了百万级上下文窗口; -
一个来源于工程能力优化,Skills 缓解了模型不稳定问题;
现阶段 Agent,在数据处理一块有了很大的进步,甚至说可以解决 80% 的问题(也就是数据正确率会在 80% 左右),于是现有经典架构就出来了:
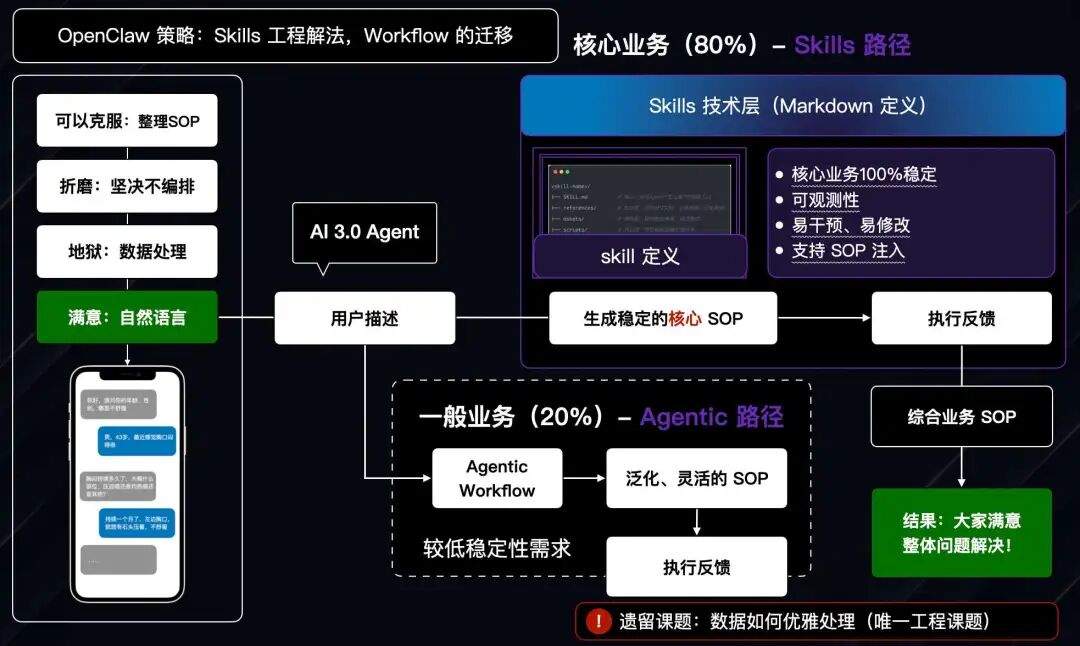
上图是前些日子爆火的小龙虾 OpenClaw 的大概架构和解决的问题,如图所示,就可以前些日子各个老板所谓“养虾”是个什么意思,其实就是在梳理工作流/SOP。
在这个基础之下就衍生出来了同事.skill,大家想要用这个方式去蒸馏员工,我们只是从底层架构来说,就不太可能,但这里依旧有一些不错的衍生实践,比如 obsidian + Claudian 组合:
类似于 obsidian + Claudian这种模式都可以归类于Workspace Agent/知识工作区 Agent/文件系统型 Agent,他属于:
以私有工作空间为上下文,以文件系统为操作对象的协作型知识 Agent
这里最为核心的问题就产生了:过往,我们使用 RAG 去引入私有数据,而且 RAG 有很多复杂、烦躁的技术流程、而现在我们直接上传数据即可,效果貌似也挺好了,于是乎最本质的问题来了:
既然,Workspace Agent 效果这么好,是否 Agent 就不需要 RAG 了?
这背后涉及了两套完全不一样的 Agent 类型和技术范式:
协同 VS 高可信
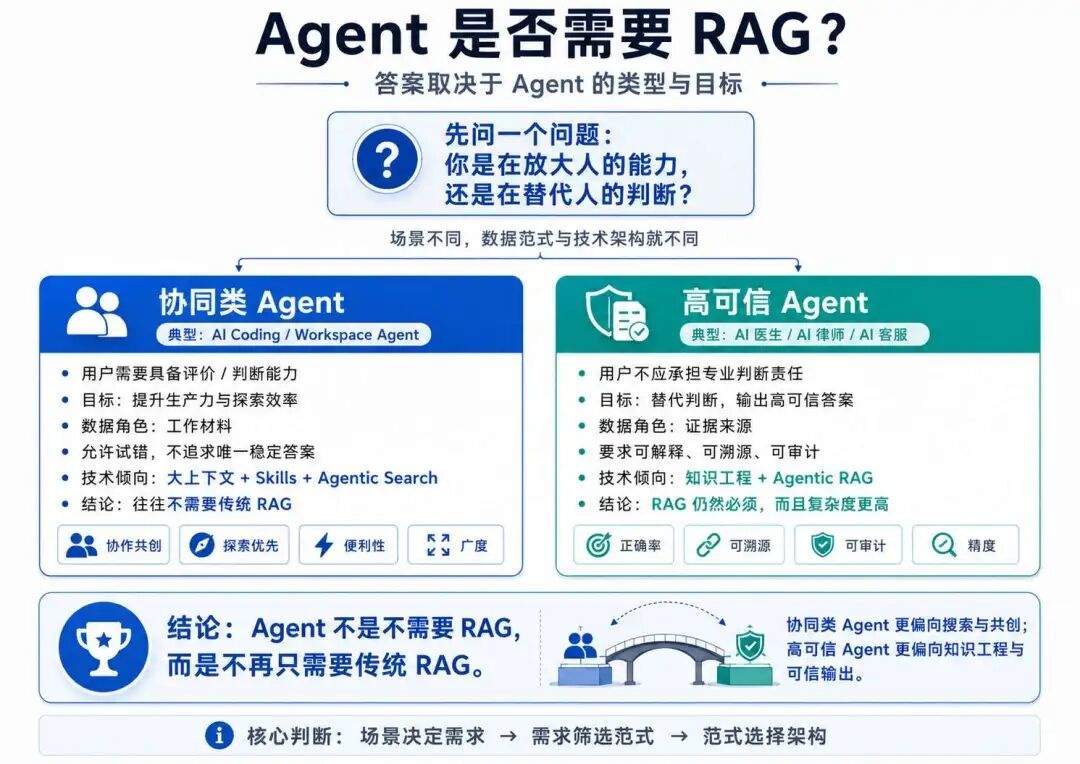
从用户角度出发,Agent 对数据的使用可以分为两类:
第一类是协同类 Agent,典型代表是 AI Coding Agent,他需要使用者对 AI 输出内容具备良好的评价/判断能力,也就是说个人专业能力越强,那么这类 Agent 工具会用得越好;
第二类是知识输出(高可信)类 Agent,典型代表是垂直领域的应用如 AI 医生/AI 律师,他不需要你去协同,也不需要你具备专业评价能力,他只需要你被他引导,然后输出最正确的答案。
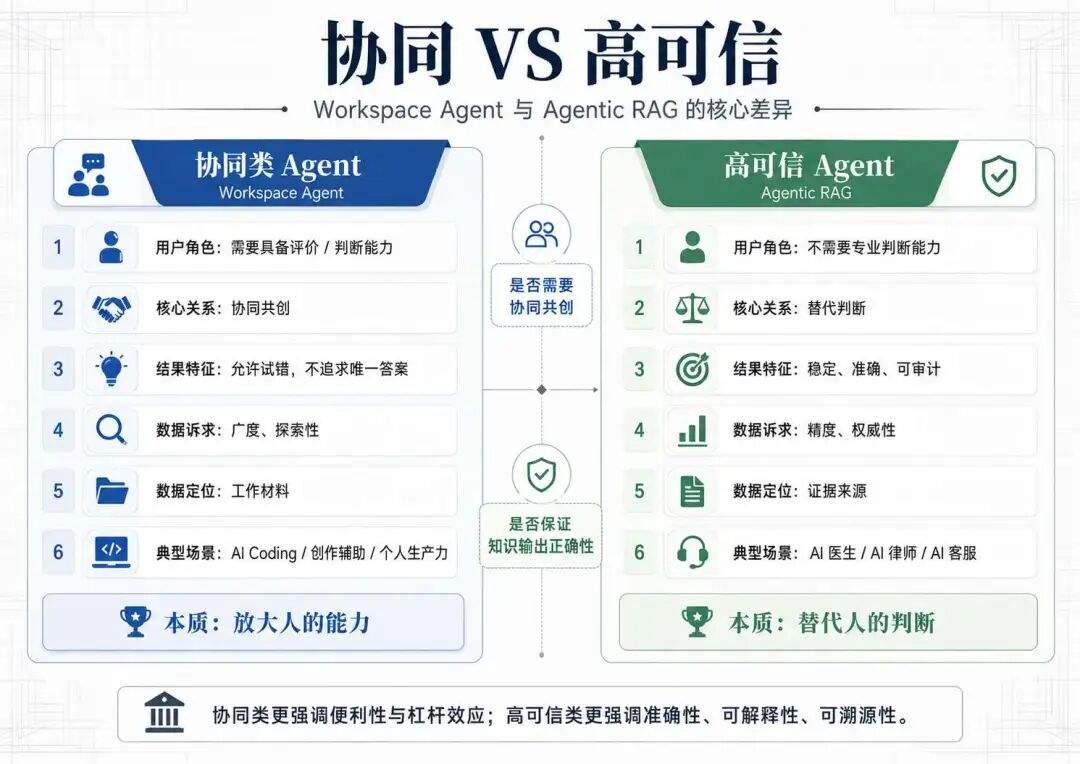
这里有两个核心差距:
第一是是否需要协同共创
第二是是否保证知识输出的正确性
比如 Claude/CodeX 这种都属于协同共创类 Agent,现在的主流技术架构是:Workspace Agent;
另一方面,一些复杂的行业应用(如 AI 医生)、AI 客服,都还是采用的第二套技术路径 Agent + RAG,只不过这里的 RAG 和大家以为的 RAG 会相去甚远,其复杂度会高非常多。
在这个基础上,我们再来聊聊Workspace Agent 与 Agent RAG的一些差异和应用场景:
协同:生产力工具属性
我们对于协同型 Agent 的核心假设是:使用者需要并具备评判能力,这里的意思是代码写得好不好,接下来怎么改,我们是门清的,AI 在这里的意义是杠杆作用,让我们做这件事的效率更高了。
因为是协作共创,所以他是允许错误的,于是对于数据的诉求是:广度和探索性。也就是他没办法给你唯一答案、甚至是稳定的正确答案,比如相同输入拿不到相同输出。
专家:替代的是判断本身
而严肃的 Agent RAG 面对的场景就很严苛了,比如 AI 医生/律师,这里的核心假设是:用户不需要也不应该具备专业能力判断,他们应该完全的相信 AI 的输出;
只要是严肃领域的 AI,毋庸置疑追求的一定是:精度和权威性。它要求的是 99.9% 以上的准确率,且每个结论都必须有据可查,能溯源到权威文档的具体章节,80% 的正确率在这里绝对不可接受的!
从实现上,高可信 Agent 追求的是:
可解释性,必须能准确指出结论来自哪份文档的哪一条,并且还要说清楚 CoT 是什么,这里可不是那种半吊子思维链,而是必须要符合行业逻辑的思维链
在这个基础上对数据的需求就会变得很苛刻,至于这里数据怎么做,就是各个行业的 KnowHow 与价值所在了。
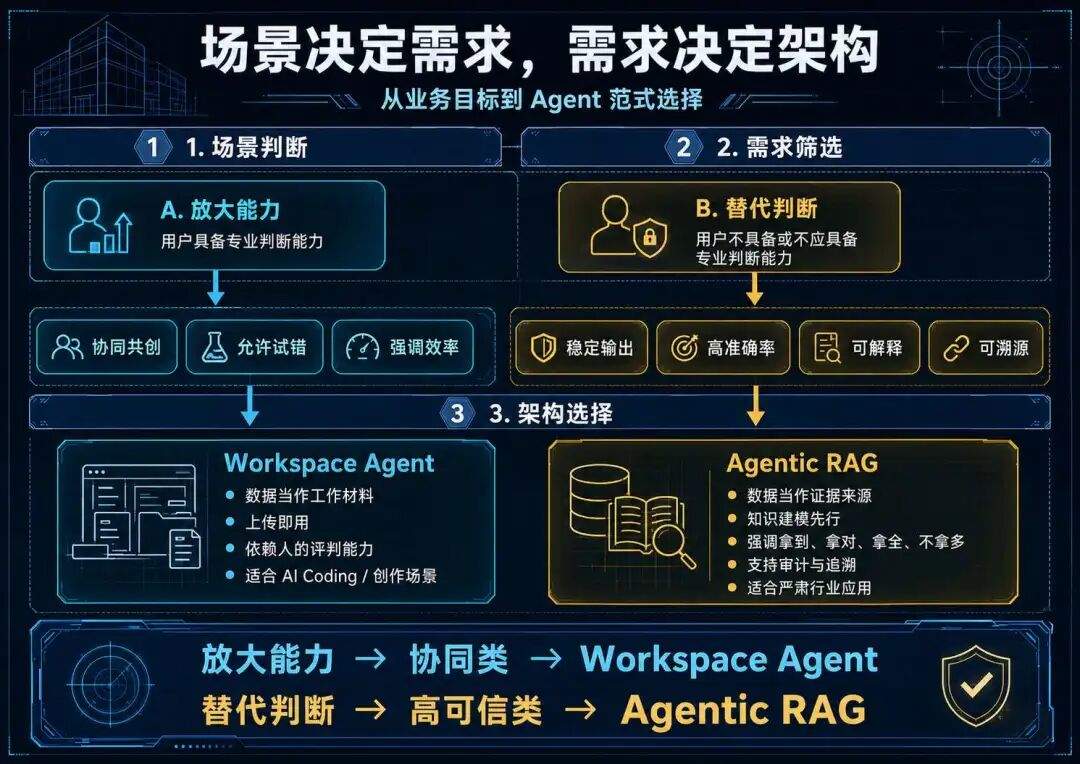
综上,我们整个 Agent 架构选择的递进逻辑就出来了,场景决定需求 → 需求筛选范式 → 范式选择架构:
-
如果你是放大能力,选协同类,走 Workspace Agent 路线。 -
如果你是替代判断,选稳定输出类(高可信 Agent),走 Agentic RAG 路线。
接下来,我们再说两者差异导致的优劣问题:
优缺点
Workspace Agent 与 Agentic RAG 都具备使用私有数据的能力,但他们对待数据的态度就成了他们的核心差异:
-
Workspace Agent 把数据当成工作材料,重要的是协同; -
Agentic RAG 把数据当成证据来源,重要的是 CoT;
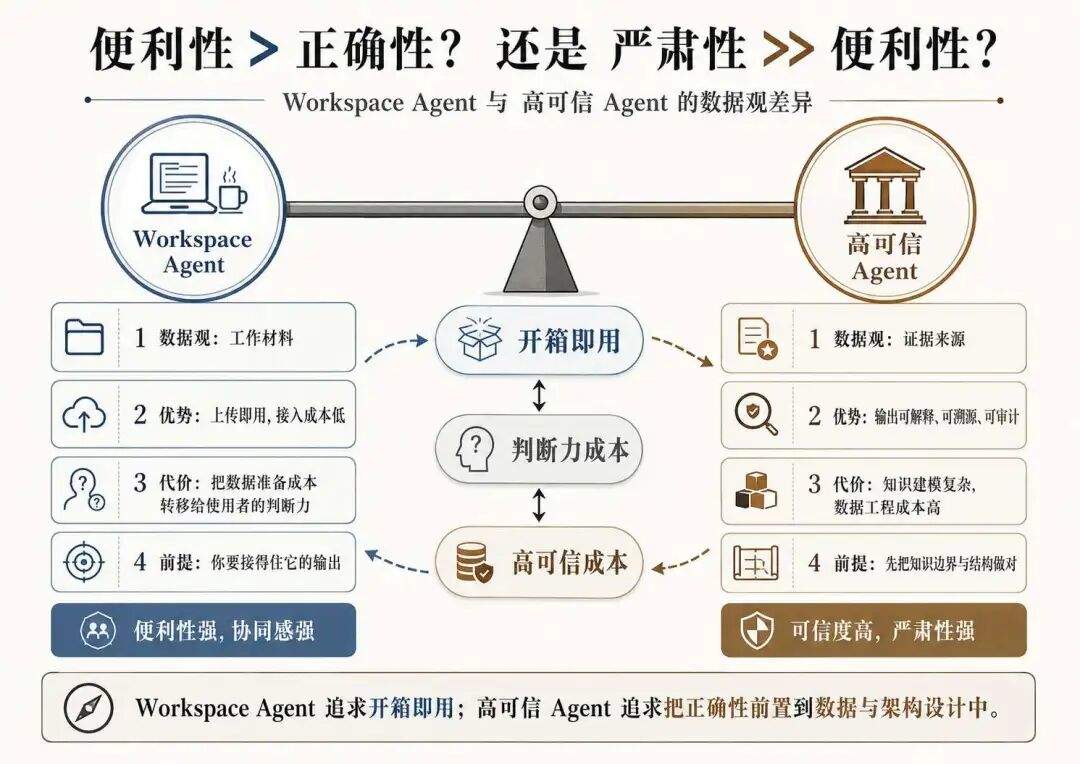
工作材料或者证据来源的背后是数据严苛态度,其最终会表现为:技术便利性与数据成本:
你愿意为开箱即用付出什么代价,又愿意为高可信投入多少成本
便利性 > 正确性
Workspace Agent 的最大魅力,在于它几乎消解了数据接入的所有前置成本。
你不需要对私有数据进行复杂的预处理,不需要设计切片策略、不需要 TopK…
直接把文件拖进去,Agent 就能开始工作。这种上传即用的体验,是大家推崇他的原因。
但这份便利性的背后肯定是有代价的:它要求使用者本身具备评判能力。
也就是,从底层设计上 Workspace Agent 就追求的是便利性,他把数据准备成本转移到了使用者的判断力,用起来很方便的前提是,你得有本事接住它的输出
严肃性 >> 便利性
高可信 Agent 走的是完全相反的路径。它要求在数据进入系统之前,就完成严格的知识建模。
这可不是简单的切片和向量化,我在国外处理过程中有很多心得可供分享:
第一,知识库设计尤为关键,其中最难的是缺点边界与结构,所谓边界是你的AI系统到底要完成什么任务,必须穷举定死;所谓结构,就是知识要能匹配这套系统;
第二,知识梳理的时候要考虑逻辑关系链、要设计实体结构,要找到切入知识库的核心,比如用一个不重样的关键词将知识实体搜索出来,再根据实体结构的逻辑链找到各种关系,只要逻辑链清晰,提示词就好设计,AI就会聪明很多;
第三,在做知识库实体结构时,类型不要太多,如果产生层级,层级也不能太多,因为关系越多工程实现越复杂、层级越多知识库处理越复杂。做AI应用要平衡真实世界的模拟与数据工程实现的ROI,也就是如果工程实现复杂度过高,就要在数据复杂度层面做取舍;
第四,在前三点的基础下需要考虑的是架构实现问题,这里必须由一号位自己写文档做产品甚至是架构设计,不用你写代码,但你文档写完需要相当于伪代码写完了,不然下面产品和技术没那个能力做出来的。这里的架构设计核心是你的知识,如何让AI每次都能拿到、拿对、拿全、不拿多;
第五,在知识齐全的情况下,如何让AI聊得像个人是个封闭性问题,他的前提是知识是对的,如何像人一样表达这段知识,需要考虑什么,需要建模,或者说需要设计策略;
这套成本极高,且高度依赖行业 KnowHow。但一旦建成,它的收益也极其明确:输出可解释、可溯源、可审计。
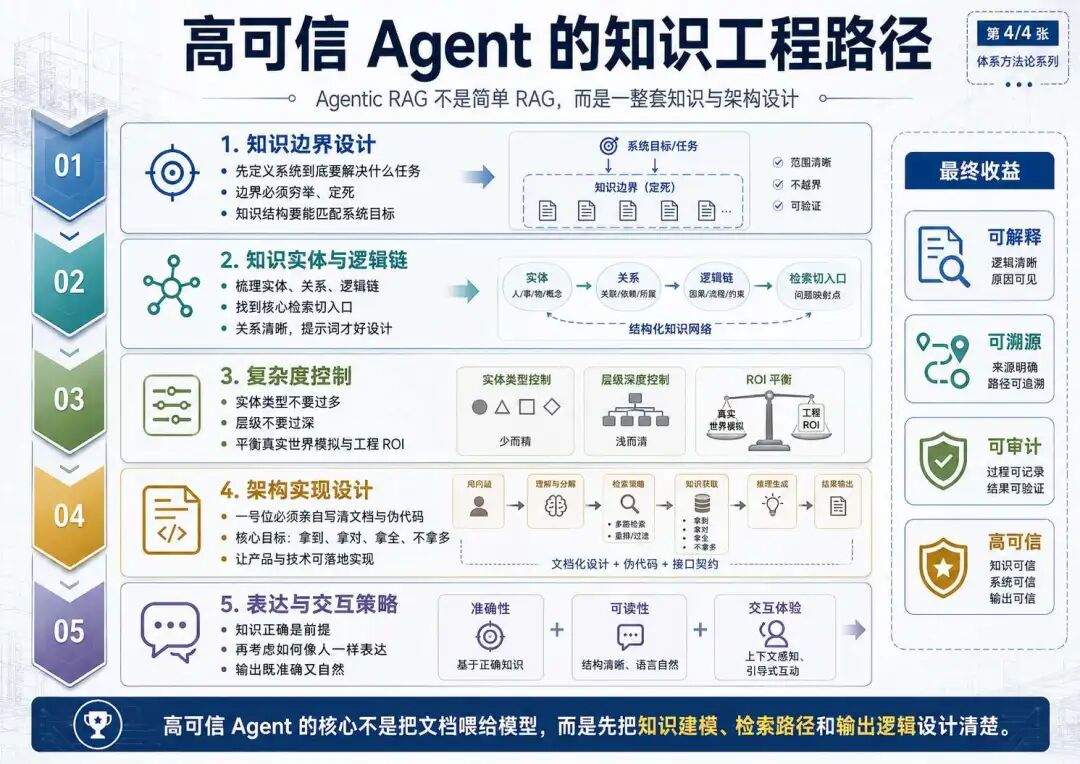
对于不能容忍大概对的场景,这种前期投入是必须的,总结一下就是:高可信 RAG,将正确率的成本投入了前期的数据建设,所以就不需要用户有独立判断了。
二八逻辑
人有个特点,可以偷懒的话绝不会想要多动一下,所以这里就会有个问题:既然 Workspace Agent 做知识库表现已经很不错了,是不是 RAG 那一套就没用了?
额,可能还真不是那么回事,至少现在 Workspace Agent 更适用的场景是:个人工作空间。
在个人工作空间里面你想怎么玩就怎么玩,但一旦上 10 个人你再试试,大家会发现,相同的问题就一定有很多不同的理解,那到时候是听叶老师的还是听听王老师的呢?
所以,只要 Workspace Agent 想要去组织企业的知识库,那么会遭遇很多复杂的工程问题,那么也就失去了他的便利性了;类似的问题在 NoteBookLM 这种产品里面也会发生。
所以在企业视角来说,技术选择会更倾向于融合,是一种共生关系,这里跟我们之前做生产级 AI 客服的经验是温和的:80% 客户的问题会围绕着 20% 的场景不停做展开。
其实就算是严肃场景也是一样,最核心的流程使用高可信 Agent,其他 80% 非核心流程敞开聊,让 AI 自由发挥就好。

这种方式是比较兼顾知识有效性以及数据工程实现成本的方法,因为高可信 RAG 本质依赖的是行业 KnowHow 形成的核心 SOP/Workflow,与他配合的就是公司那套可信知识内核了。
这个可信知识内核,是企业真正有价值的资产,你要相信着不是一个路人甲员工能够提供的。
跟进一步,高可信不是一个产品形态而是一种风险分层策略。比如 AI 医生,其实也并不是所有任务都要求那么严苛,他只是在核心流程追求99.999%,比如:诊断、用药、治疗方案…
但其实还有些泛医疗场景包括,运动、饮食建议,其实是不会进入核心逻辑的,这里就会因为风险等级不一样而选择不一样的技术选型。
当然,具体到如何做,这里就展开了,总而言之,复杂度挺高的…
Agent 是否需要 RAG
写到这里,可以正面回答那个最本质的问题了:Agent 是否需要 RAG?
这里其实行业有相对成熟的案例:在 Coding Agent 这个最成熟的协同类 Agent 领域,传统 RAG 正在被主流产品集体抛弃。
Claude Code 官方提到过:他们早期版本也在用 RAG 但效果不好,取而代之的是一种 Agentic Search 的技术(也就是现在比较主流的技术),让模型自己玩,最后效果比 RAG 好多了…
这在之前 3 月份 Claude Code 代码泄露中有相关证据链,也就是我们是看不到 RAG 相关技术的痕迹的。
如果从这个角度看,传统 RAG 似乎确实不是 Agent 的必要组件。
但是大家要注意,按照我们之前的逻辑,这里的 Coding Agent 是协作型 Agent,他本来就不需要……
所以,如果只用这类的 Agent 去评判是有点不合理的,如果是高可信 Agent,RAG依旧是必须的,但是这个 RAG 的复杂度却不可同日而语。
两者的核心差异在于对检索这件事的目标和要求完全不同:
Agentic Search 追求的是探索效率和覆盖面,模型自己去走 ReAct循环,决定搜什么、读什么、要不要再搜一轮。
这套逻辑在处理代码、文档类材料型数据时非常高效,因为数据本身就是给人读的,上下文完整,逻辑自洽。
但高可信场景要的不是这个,它要的是每一次检索都必须拿到、拿对、拿全、不拿多。少拿一条关键证据,结论就可能出错;多拿一条无关信息,反而干扰模型判断,这不是 grep 加 glob 能解决的事。
所以,高可信 Agent场景下的 RAG,肯定不是检索,更确切的说法是知识工程,这里的难点或者工作量在搜索之前就决定了:边界在哪、实体结构如何设计、关系链要完整到什么程度、AI 代码工程如何与数据工程做结合……
综上,Agent 没有不需要 RAG 技术,只不是不需要之前那个 RAG 技术…
结语
回归一下,第二大脑如何做、到底怎么去蒸馏一个人、同事.skill的局限性在哪、他们各自到底在说什么?
我认为今天的内容是有一个不错的回答的:
同事.skill 有价值,但它蒸馏的是工作流,这种先做什么、后做什么属于之前数字化转型的延续,核心是吃掉重复工作,目标是降本增效;
要真的蒸馏一个人,这里的关注点就不是动作了,而是要去思考他为什么这么判断、怎么取舍、遇到异常如何决策。
这需要从 Workflow 再往上走一步,把判断标准、分类逻辑、案例边界等等全部考虑到位,这个就是我们之前说的高可信 Agent 依赖的数据工程了。
至于 Agent 需不需要 RAG,那是当然需要的,只不过又换了个名字罢了…