
karpathy之前发布了一条帖子表示,最近绝大部分 Token 消耗从写代码转向利用 LLMs 构建个人知识库,这条推文引起了大量的关注,很快就高达1700多万阅读。
抛开karpathy自带流量因素之外,从另外一个角度也说明,在构建AI知识库这个场景还远没有被满足,有很多的人都受困于知识管理。
次日,karpathy就在Github上面公开了LLM wiki 的构想文件,详细的阐述了这套知识库构建方案的架构和理念。
到目前为止,网上也有很多关于这套理念的实践,比如使用Obsidian + Claudidan + LLM wiki来构建第二大脑,但是Claude Code对于很多同学来说上手门槛确实有点高,本篇文章我们把门槛降低一点,使用WorkBuddy + LLM wiki + Obsidian来做实践。
首先,我们先大致先了解下LLM wiki 是个啥东西。
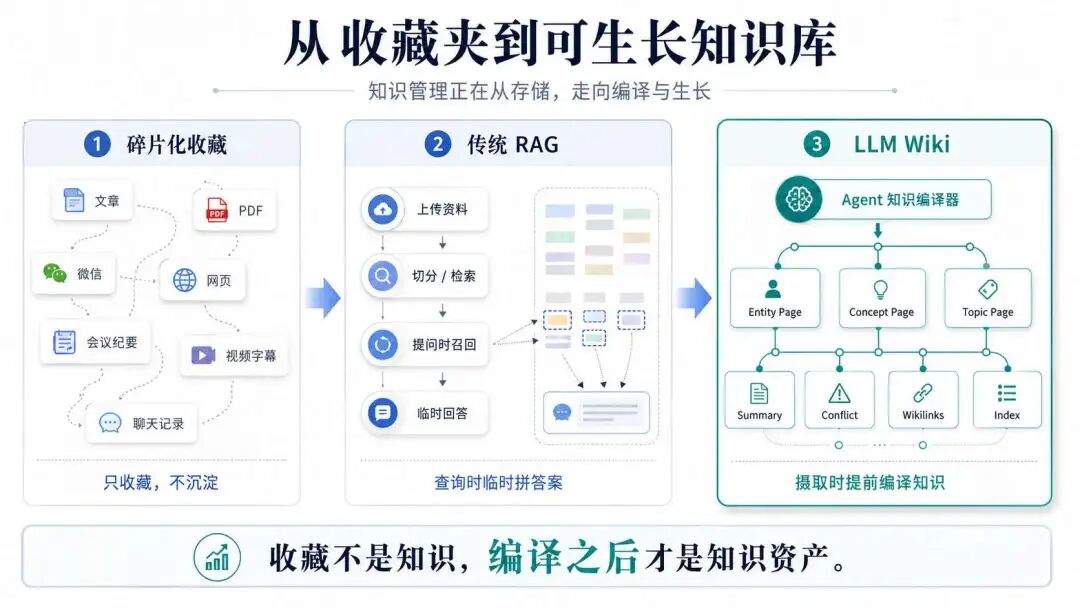
他的核心观点是,传统的RAG系统和NotebookLM/ChatGPT文件上传功能,大部分都是先上传资料,查询时召回相关知识片段,然后临时综合性回答。
但问题是,每次问问题,模型都是在重新从碎片里临时拼答案,知识并没有被持续沉淀下来。
karpathy 提出的LLM wiki 则是:我们负责收集原始资料,大模型读取这些资料,然后增量维护一个结构化的Wiki,不断的更新实体页、主题页、交叉引用、矛盾点和综合结论。
也就是说,他不再是查询时临时拼答案,而是提前把知识编译成一个可持续演化的知识结构。相当于一次编译,持续复用,知识像滚雪球一样越滚越大。
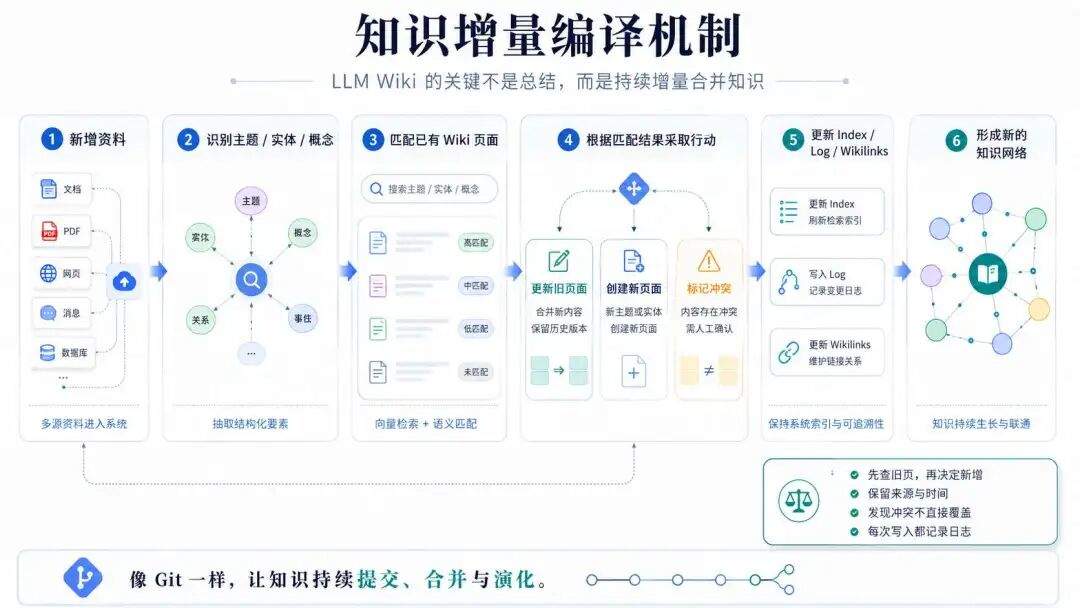
另外,LLM Wiki 并不是一次性把所有资料重新总结一遍,而是做增量更新,编译新的知识时,Agent 会先判断它对应哪些已有实体、概念和主题,再决定是更新旧页面,还是创建新页面;如果新旧资料的说法不一致,也不会直接覆盖,而是同时保留来源、时间和适用范围,并给出冲突提示。
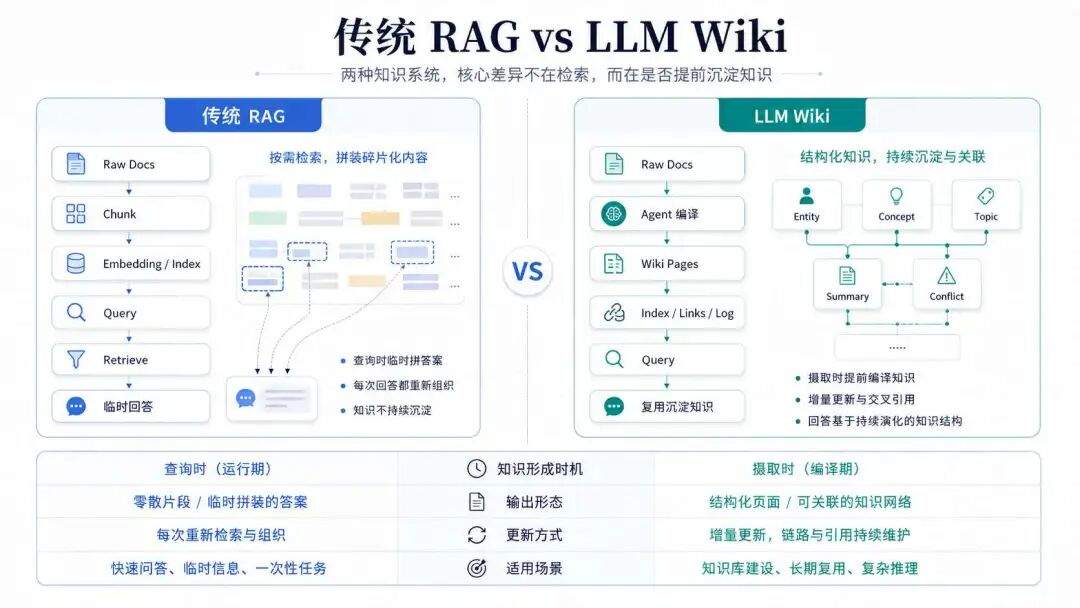
他的整体架构分为三个层级:
-
Raw层用于存放采集的原始资料,比如我们看到的文章、论文、图像、数据文件、以及聊天记录等,这些内容是不可变的,LLM只负责读取但是不会修改它们,这些内容是整个知识体系的事实来源。 -
Wiki层相当编译层,用于存放由LLM处理后的结构化知识,包含摘要、实体页面、概念页面、比较、概述、综合理解等,这一层主要是由LLM维护更新。 -
Schema层,这一层相当于是Claude Code 的CLAUDE.md或者Codex的AGENTS.md,它告诉大模型Wiki的结构、约定以及处理资料来源、问题回答或者维护wiki时应该遵循的工作流程。
简单来说,raw层提供原始材料,我们负责往里面存放;wiki层是加工品,由AI负责把原材料编译成结构化的知识;schema层是生产规范,指导AI怎么加工。
以上就是关于LLM wiki的核心理念,大家有一个简单的认知,下面我们继续看如何实践。
依赖工具
实践过程中,我们需要使用Workbuddy、Obsidian、Obsidian Web Clipper这些工具,其中Workbuddy、Obsidian到对应的官网下载安装即可,Obsidian Web Clipper是一款浏览器插件,需要到Chrome扩展商店下载,主要用于把网页内容提取为Markdown格式并保存到Obsidian Vault中。
初始化工程
首先我们打开 Obsidian,点击【创建】,在指定文件夹下创建一个新的仓库,这里命名为kb-wiki,并使用Git版本管理工具初始化仓库,便于后续管理版本记录。
然后打开WorkBuddy,新建一个会话,工作空间选择刚刚在Obsidian中创建的项目文件夹。
这样Obsidian、WorkBuddy这两个软件的工作空间都指向了同一个本地目录,只不过现在文件夹还是空的,我们继续往下。
整体架构
根据前面的LLM Wiki的原则,我们在Obsidian中把目录文件层级设置为如下结构:

其中AGENTS.md就相当于Schema层,是指导WorkBuddy维护wiki的工作原则;index.md是wiki内容的索引文件,便于快速找到目标内容;log.md是用于记录每次操作的记录,比如什么时间写入了什么知识、新增了哪些内容等;
raw存放原始资料,里面的目录结构可以自定义,根据自己的实际需求进行分类;wiki就是经过AI编译后结构化知识;templates用于给AI生成wiki时参考的模板文件,与wiki下面的目录结构一一对应。
整体的目录结构和职责划分还是很简单清晰的,我们在看整体的工作流程是怎么样的:
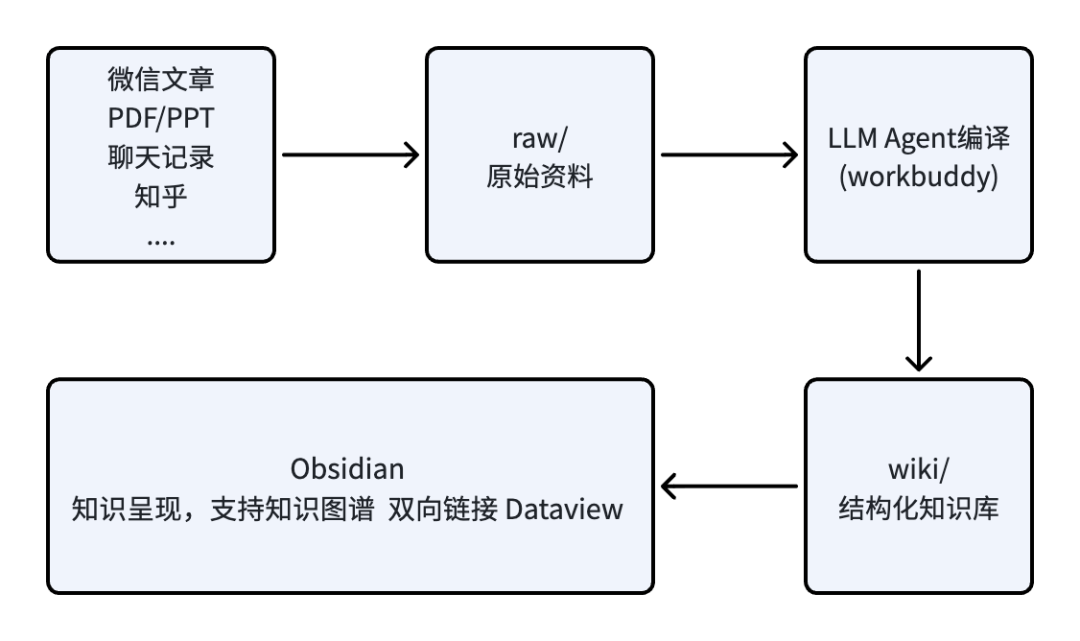
其中workbuddy的职责就是承担编译器,负责对原始资料进行加工,当然也可以用Claude Code、Codex等Agent工具;而Obsidian更多的承担编辑器和UI视图的职责,提供双向链接的功能,并以可视化的方式呈现知识之间的关系,还提供其它查询类的操作。
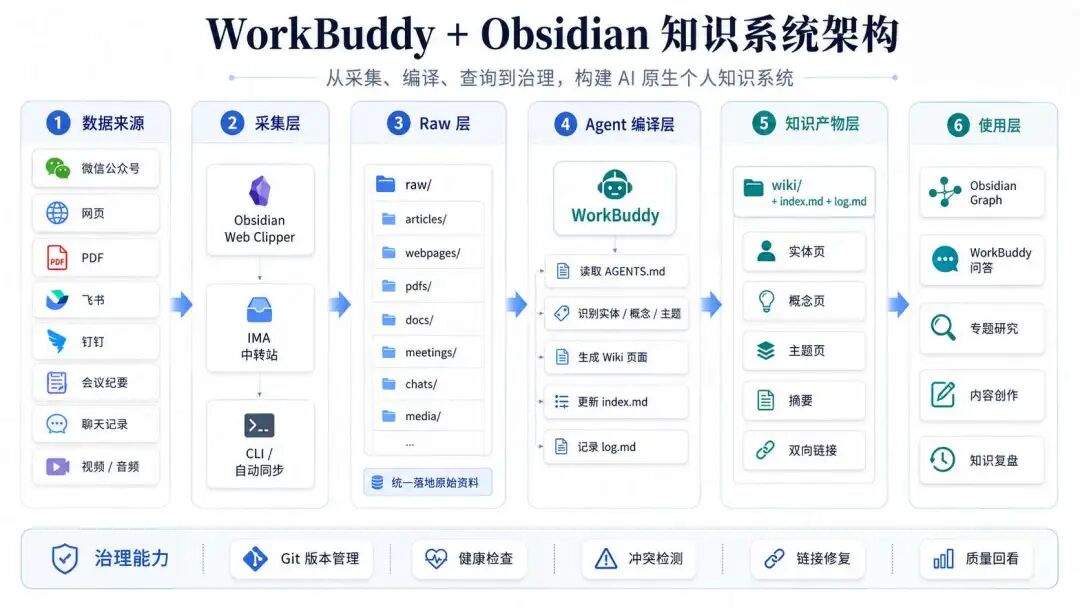
可以看出,整体流程中最为关键是,数据怎么采集、知识怎么加工、用什么模型加工、如何被查询、怎么保持加工的质量能够稳定持续。下面我们围绕这些方面进一步展开。
编写Wiki Schema
前面说过,Wiki Schema层相当于就是定义AGENTS.md文件,指导Agent如何工作。可以说这是整个Wiki系统的灵魂,它负责告诉Workbuddy的角色是啥、目录结构怎么维护、从哪里读取素材、素材怎么编译、摘要怎么写、链接怎么创建等等。
下面是一份部分示例:

把上面的内容编写到项目的根目录AGENTS.md中,这个文件的内容并不是一劳永逸或者一蹴而就的,需要我们持续的维护更新,直到表现稳定。
数据采集
前面我们已经把项目的目录结构和AGENTS.md定义清楚后,项目的主体结构就搭建完成,接下来就可以开始采集数据了。
这一步主要看我们的搭建知识库的目的是什么,这决定了我们需要采集哪些数据。
如果是用于构建个人第二大脑,那需要采集的数据要求就很多,比如我们每天看过的重要文章、视频、参与过的会议、聊天、通话、文字记录等信息;如果是做专题研究学习,那么仅收集查阅过的优质论文、文章、报告即可。
而收集的这些数据可能存在多个平台上,非常分散,想要把这些信息放入到项目的raw目录中,还是很费劲的,这里我们可以借助IMA和Obsidian Web Clipper用来收集整理数据。
比如,在电脑端浏览器中,我看到一篇优质的文章,我想把它加入我的知识库项目原始资料中,就可以使用Obsidian Web Clipper插件把网页内容以markdown的格式直接添加到项目的raw目录中。
而在移动端,我的大多数内容来自微信公众号,我想把优质的内容加入项目中,操作路径相对更长,得先把这篇公众号链接发送到电脑端,然后在电脑端用浏览器打开,在用Obsidian Web Clipper插件收藏到raw中。整个操作流程是断裂的,有时候还会忘记在电脑端进行操作,有价值的文章内容就流失掉了。
这里我们可以使用IMA知识库作为中转站,用来收集移动端的内容,把在微信中看到的各类信息一键收藏到IMA知识库中,这个方法对于微信生态的内容尤其友好。
然后我们还要借助Workbuddy的定时任务,定期的从IMA知识库中把新增的内容同步到项目raw目录中来,自动化任务设置大致如下:
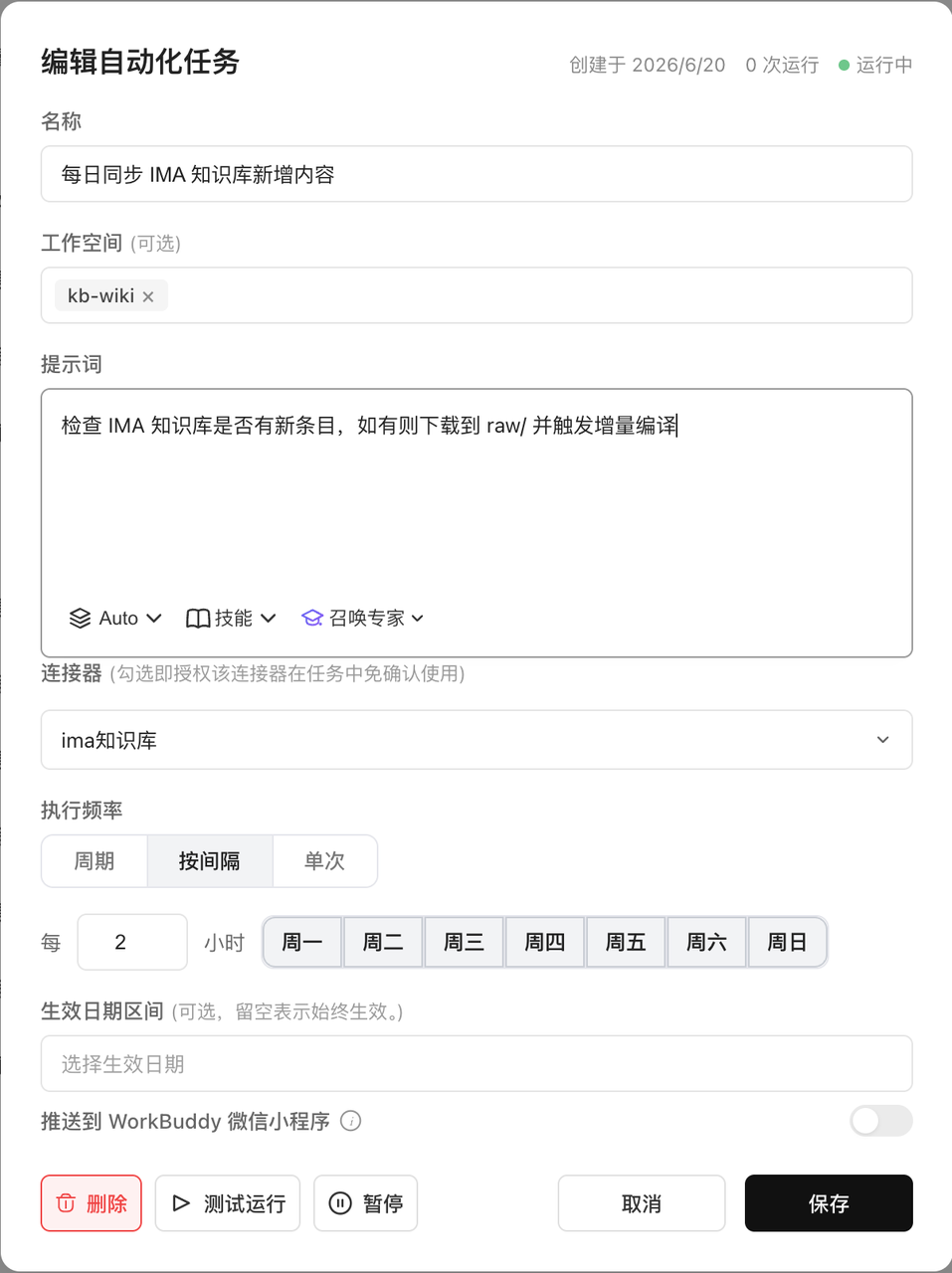
这样我们就能同时收集到电脑端和移动端看到的多数优质内容了。
除了上面提到的两种情况外,内容可能存在其它平台上,比如飞书文档或钉钉文档中,我们可以借助这些平台的CLI工具 + Workbuddy自动化任务来实现数据的同步,方式方法很多,就不一一列举了。
此外,我们收集数据格式可能存在多样性,有文档、图片、视频、音频、PPT、PDF、聊天记录等,关键是要把这些格式的内容识别为文本,这里可以借助多模态模型进行解析,便于后续模型加工处理。
需要注意的是,原始资料的质量决定了Wiki的质量,这里的核心原则是,只收集高质量的内容,宁缺勿滥,否则我们的知识库就变成了垃圾进垃圾出。
这里我通过Obsidian Web Clipper插件,把之前写过的所有关于知识库和RAG的微信公众号文章都放入到项目的原始资料中来。
编译知识
原始资料采集完成后,我们就可以开始让WorkBuddy编译知识了。
打开WorkBuddy,把工作空间指向kb-wiki这个目录,在会话中告诉它:
阅读当前项目raw/中新增的文件,按照项目根目录中的AGENTS.md的规范,将它们编译到wiki/目录中,并同时更新index.md和log.md文件
WorkBuddy 就会阅读这些原始资料,提炼出概念和实体知识,并为每个有效来源创建摘要信息,并在每个页面之间创建[[wikilinks]]双向链接,这里生成的一系列的Markdown 文件,都会放到 wiki 这个文件夹下。
此外,还会更新知识wiki的索引文件index.md,以及把本次知识写入日志更新到log.md中。
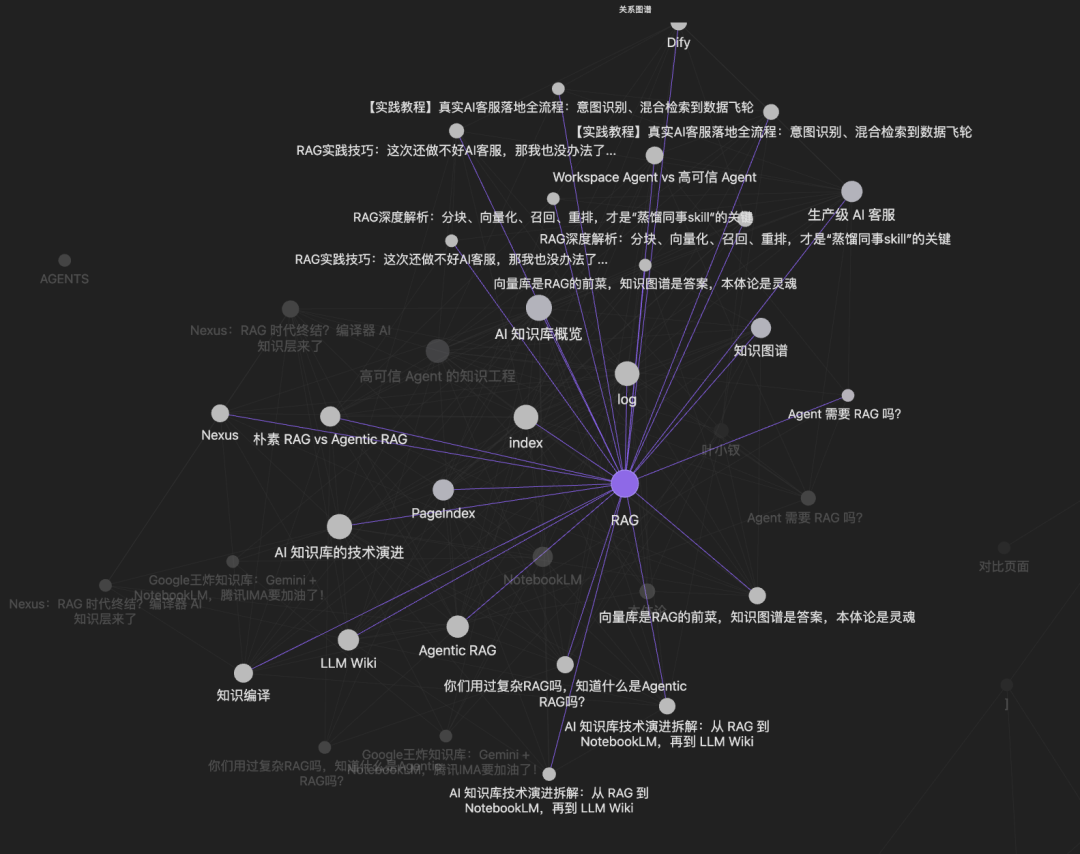
生成的这些文件并不是散乱的,彼此之间会用双向链接关联起来,我们在编辑器中查看不够直观,但是在Obsidian中使用关系图谱功能查看,就会以下图这样的知识图谱形式展示,我们可以看到不同知识点、不同资料之间的关联,点击某个知识点,还可以直接跳转到对应知识文件去。
到这一步就完成了知识的摄取,接下来我们看如何查询知识。
查询知识
查询这里就非常简单了,直接向WorkBuddy提问即可,它会根据wiki中沉淀下来的知识,进行综合回答。
比如我问:
根据 Wiki,解释一下LLM wiki的工作原理是什么,它与传统的RAG有啥区别?
下面是回答截图:
可以看到索引文件index.md,在查询时就派上用场了,WorkBuddy在查询时会先读这个索引文件,判断哪些页面跟当前问题相关,然后在进一步读取,这与我们从目录结构找到对应的章节知识是类似的做法,可以大幅提高检索的效率。
这里Wiki 页面的渐进式展开和 Skills 的渐进式披露的机制也非常一致。
当然,这里生效的前提是,我们要在AGENTS.md中定义查询的工作流程,让Agent先查index.md,然后在加载wiki中的相关知识。

另外,对于有价值的回答,还可以把结论写回wiki,让知识越攒越厚。
治理知识
知识治理则是让Workbuddy定期检查一遍,看整个知识库wiki有没有矛盾、有没有孤立页面,链接有没有断,保证知识库不会因为资料越多就越乱。
这里可以通过Workbuddy的定时任务来实现自动化健康检查,比如每周检查一次,定时任务设置如下:
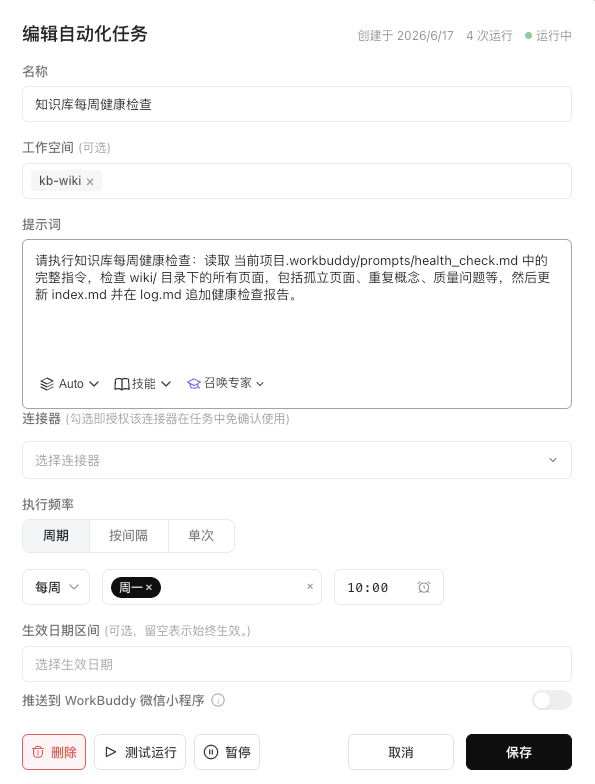
知识健康检查指令大致如下:

在企业场景中,LLM wiki的局限
在LLM wiki概念出现之后,又有一大批自媒体在自嗨,宣称RAG已死,认为LLM wiki可以完全替代RAG做企业知识库,成为企业知识库的新架构。但从我目前的感受来看,LLM wiki这套理念还是更适合构建个人知识管理的需求,放在企业场景中还是不太适合。

首先,数据规模的限制是一道门槛,当wiki文档数量膨胀到成百上千个时,每次新增知识编译或者查询时,Token的消耗会显著上升,甚至Index.md的索引内容可能就会撑爆上下文窗口,存在高昂的成本和性能压力。
其次,就是权限管理,企业级的知识库通常需要权限访问控制,而LLM Wiki目前对细粒度的访问控制支持还不完善,难以满足企业级安全合规要求。
另外,知识引用的可溯源性也存在隐患,企业场景对来源追溯要求很高,尤其是医疗、法律等严肃场景,RAG方案可以明确这个回答是基于哪个文档中的那一段内容,而LLM Wiki生成的内容本质上依赖于模型对原始知识的理解与重构,是极有可能出现幻觉的,存在生成错误知识关联的风险。一旦这类偏差被写入Wiki,就可能会误导后续所有查询结果。
因此,LLM wiki的使用还是要分场景的,对于个人知识库构建、学习研究等低风险场景中,效率高、体验好。但是对于企业知识库构建就需要评估了,根据数据规模以及权限要求、引用准确性来确定。
总结
这套个人知识库构建方案,改变了我们对知识处理的方式,以前我们把看到的优质内容放进收藏夹,等到需要时再临时搜索,但大概率再也没打开过。而现在让Agent持续参与知识的整理、连接和更新,让每一份新的资料都能和已有知识产生关系。
建议大家先从一个小主题开始,跑通本文说到的采集、编译、查询和治理的完整流程,再根据实际使用中的问题逐步调整,而不是一开始就追求一个大而全的知识库。
以上就是使用WorkBuddy + LLM wiki + Obsidian搭建知识库的一次简单实践,后续我们在对每个环节进行深入讨论。