
今年,市场被 OpenClaw 洗了一波,数字员工的概念开始撬动人心,随后类似的 Agent 便如雨后春笋,比如 Hermes、Aipy、WorkBuddy、钉钉悟空、字节 Aily…
与 Agent 相关的专业名词也层出不穷,包括 Context Engineering、ReAct、Harness、MCP、Skills、Agent Loop…
这种多且杂的局面,把很多人搞得很慌、搞得很乱。介于此,可以站在工程角度拨开这一层层迷雾,首先就可以从两个问题开始:
第一,现在到底什么 Agent 在火,真正用得好的 Agent 是哪个品类,为什么?
第二,为什么 Agent 会出现?
Agent 的场景分类
现阶段绝大部分 Agent 的底层架构(Model + Harness)高度趋同,所以对 Agent 分类意义不大,我们这里需要对其应用场景做工程化分类。
这里第一步,我们先穷举下当前市面上有数的 Agent 场景:
-
内容生成/创意生产场景; -
搜索/研究/知识问答场景; -
数字员工/个人助理场景; -
数字员工平台/企业协同场景; -
Coding 场景; -
客服/AI CRM 场景; -
专业服务场景:医疗、法律、金融;
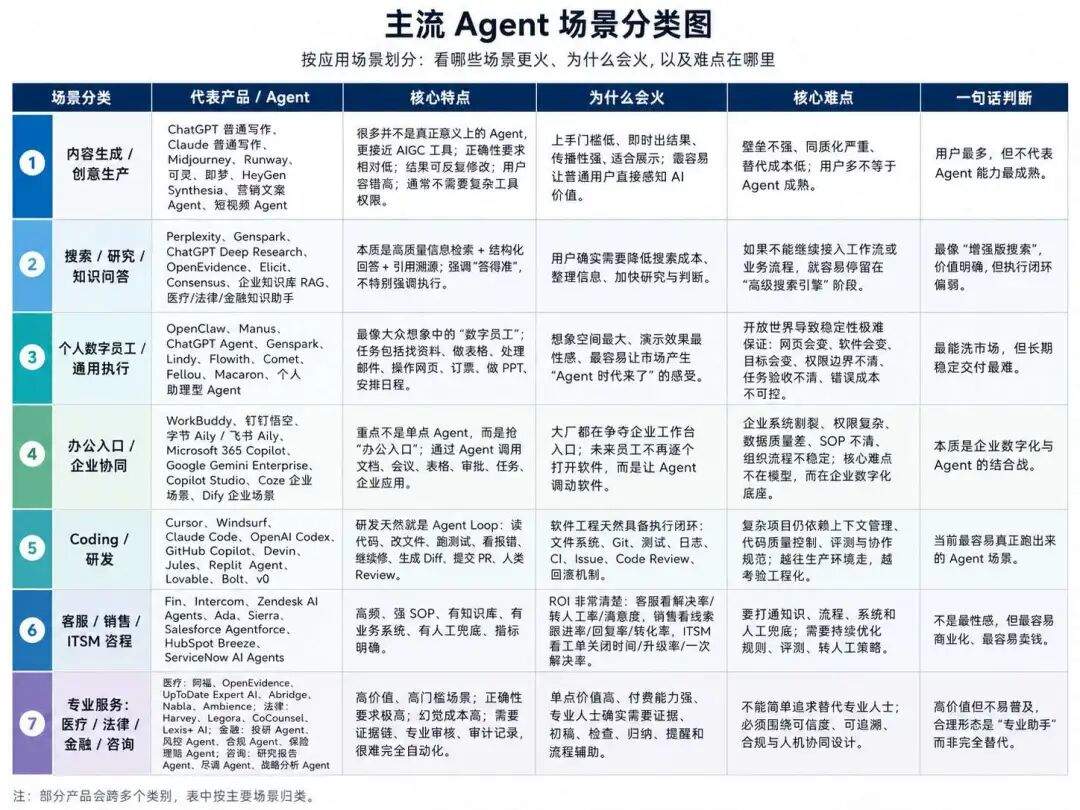
现在我们按照火爆、使用程度简单做下梳理:
一、真火 + 真有用
要进入第一梯队有几个硬性要求:大规模、高粘性、有付费、生产价值清晰,其中是否有人付费是检验一个 AI 工具是否有用的金标准。
现阶段符合这个要求的有三类产品:Coding Agent、AIGC 与 AI 客服。
无论是最初的 Cursor 还是现在的 Claude Code、CodeX,他们都在持续证明一件事:Coding Agent 是唯一被大规模验证的【真 Agent】赛道,日活千万级,企业批量采购。
其次是 AIGC,这块也是火得不行,月活上亿,但这个东西可能不应该被称为 Agent,他其实是 AIGC 工具。
怎么说呢,Agent 是自主完成多步骤任务,AIGC 是输入 Prompt → 输出单次结果的范式,门槛极低,几乎就是工具使用。
包括 SeeDance2.0 的使用,一天就能学会,但如果要用得好、出的视频效果好,功夫肯定是在故事框架、连续叙事能力这些地方。
当然,如果把 AIGC 工具当做基础设施,在上面架构 AI 漫剧工作流,那就另说了。
最后就是 AI 客服/AI CRM,都是闷声发大财的现金牛,这是真实可以节约能力成本的存在,我之前 AI 客服拿到的成绩是 10 倍提效,团队 ROI 很容易被算清楚。
但这东西只能勉强算作 Agent,他最核心的模块是严肃知识问答,这部分大概率不会使用 ReAct 架构,在此基础上会叠加其他 Agent 功能。
二、垂直火 + 门槛高
其次就是专业领域的 Agent 了,他们的特点是 AI 的专业能力比肩真人,大多数时候(98%+)能解决问题,但受限于伦理、法律,AI 实际做得还有限。代表是:
-
医疗:OpenEvidence、阿福、未来医生; -
法律:Harvey、Lexis+ AI -
金融:…
这类产品专业价值高,但因为医疗、法律、金融这些场景的正确性压力太大,其实现成本也高,他需要证据链、引用溯源、专业人士审核、法理通道…
严格来说,Coding Agent 应该被放到这个品类,因为他们都是协作型 Agent,需要使用者对他的输出有一定判断能力;
但因为 Coding Agent 走得太远,又是通用型生产工具,所以被拿出去了,但从实现路径上,他们会很类似。
另一方面,这种工具一旦要 2C 使用,那么其实现成本,尤其是对数据的要求会非常高!
三、有用户 + 有入口 + 待验证
办公入口型 Agent 这个品类是今年立起来的,几个代表是:
-
腾讯 WorkBuddy; -
钉钉悟空; -
飞书 Aily/也可能是 Coze3.0; -
…
就我咨询企业观察所得,现阶段很多企业倾向于使用 WorkBuddy 这类办公类 Agent 作为承载工作流的工具(意思是要把重复工作干掉)。
只不过理想很丰满,现实是他们最多用这类工具做些文案生成或者简单数据分析工作。
因为这类东西想要进一步推动已经不只是工具层面的问题了,他需要面临各种组织复杂度衍生的管理问题,包括:SOP 混乱、标准不清、跨部门协作难等。
所以,虽然大家都在抢 AI Office 的入口,但离最终的数字员工平台还很远,因为那就不是平台公司能解决的,除非他们有大量 FDE 能够驻场下去…
四、概念火、Demo 火、使用存疑
这一块的典型代表要属今年爆火的小龙虾 OpenClaw,网上各种疯传他神乎其技的案例,这也是普通人想象中最符合要求的数字员工形象。
只不过,你真的把这东西打开就完犊子了,他很多看起来很屌的案例在真实世界并不是那么回事:
Demo 都是在各种有限前提的环境里,而通用执行的 Agent 面对的是真实世界,真实世界就很难稳定了…
真实世界什么都会变,页面会变、用户目标会不停来回变、各种状态也会变…
所以,OpenClaw 这类产品真实状态是:传播火,但高频留存和真实使用这块要打个大大的问候,如果你问我他最大的价值是什么,我会说:
OpenClaw 狠狠的教育了市场,他让老板们知道 Agent 可以干活了
在这个基础上他才便宜了 WorkBuddy 等数字员工平台
还有其他 Agent,我们这里就不再展开了,接下来我们来尝试场景分类:

分类模型
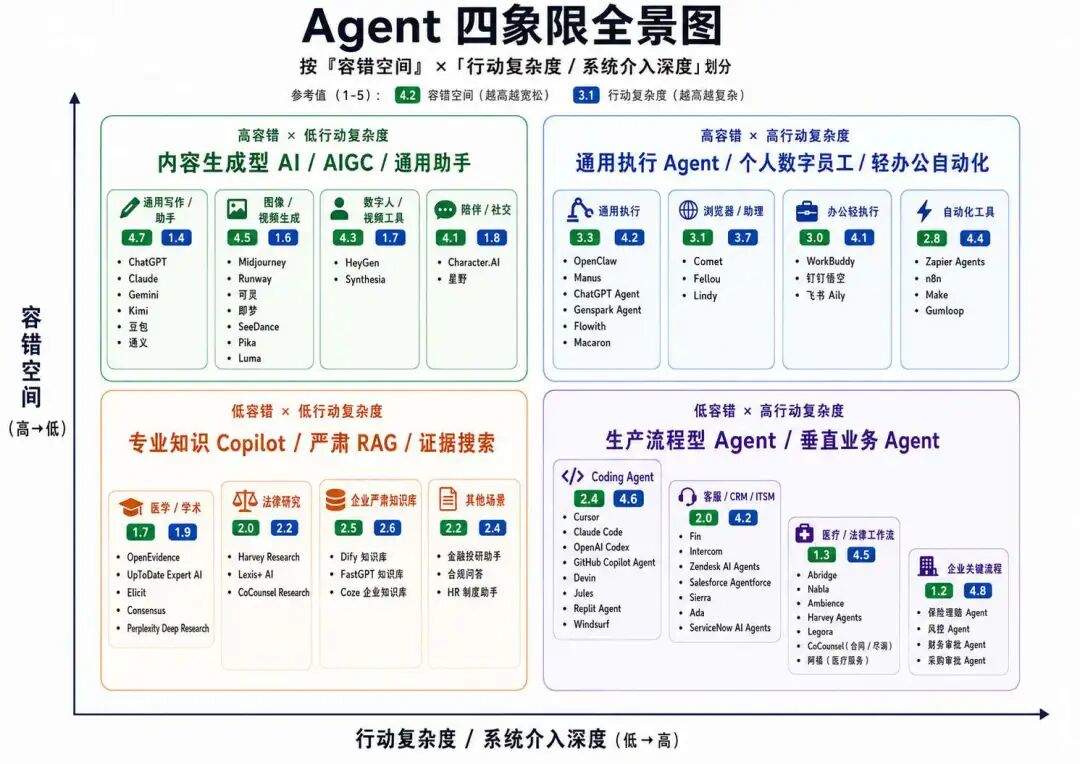
我们这里首先选两个分类维度:
第一,容错空间,也就是 AI 输出错了,代价有多大?
高容错:错了可以改,用户损失小,结果偏创意、偏草稿、偏辅助;
低容错:错了会造成生产事故、法律风险、资金损失。
第二:行动复杂度,所谓复杂度就是 AI 除了输出内容外有接入什么复杂度的系统、解决多复杂的流程,关注的核心是步数和工具调用数。
低行动复杂度:只做检索、分析、总结等工作;
高行动复杂度:这里我们稍微写全面点,包括调 API、操作浏览器、改文件、发邮件、查订单、改状态、创建工单、提交审批、生成 PR、发起退款等。
在这个基础下,四象限就出来了,我们出张表:
Agent 有用的前提
如前所述,今天真正被大规模使用、企业持续付费的 Agent(这块不考虑 AIGC 了),只有两个品类:Coding Agent 和 AI 客服。
它们的共同点是,能够有效提升效率,是生产力工具本身,但他们之间又有所不同:
-
Coding Agent 是协作型 Agent,他对容错性有要求,但不那么高; -
AI 客服是流程执行型 Agent,他对容错性要求极低,并且因为生产环境两大,所以对成本和效率是有要求的;

除此之外,还有很多看起来很火、但还没解决问题的 Agent,其中三个典型案例是 专业 Agent、办公协同 Agent 和 个人助手 Agent:
-
专业 Agent 如 AI 医生,从专业能力上来说已经达到了真人水准,但当前受制于法规现在还不能大规模应用; -
办公协同 Agent,潜力巨大,但当前被企业数字化底座卡死了,因为很多企业搞不明白 SOP 和数据,这里有大量管理工作要做; -
个人助手 Agent,能做的十分有限,一方面是多数人没意识沉淀自己的 Skills 和 私有数据,另一方面是他们这些东西也没什么价值;
综上,如果要判断一个 Agent 是不是真火,可能还是要从他是否成为了生产工具展开,而生产力工具是结果,一个 Agent 能不能真正成长起来还是有很多前提的,比如那些已经跑出来的 Agent 他的共同特点是什么呢?
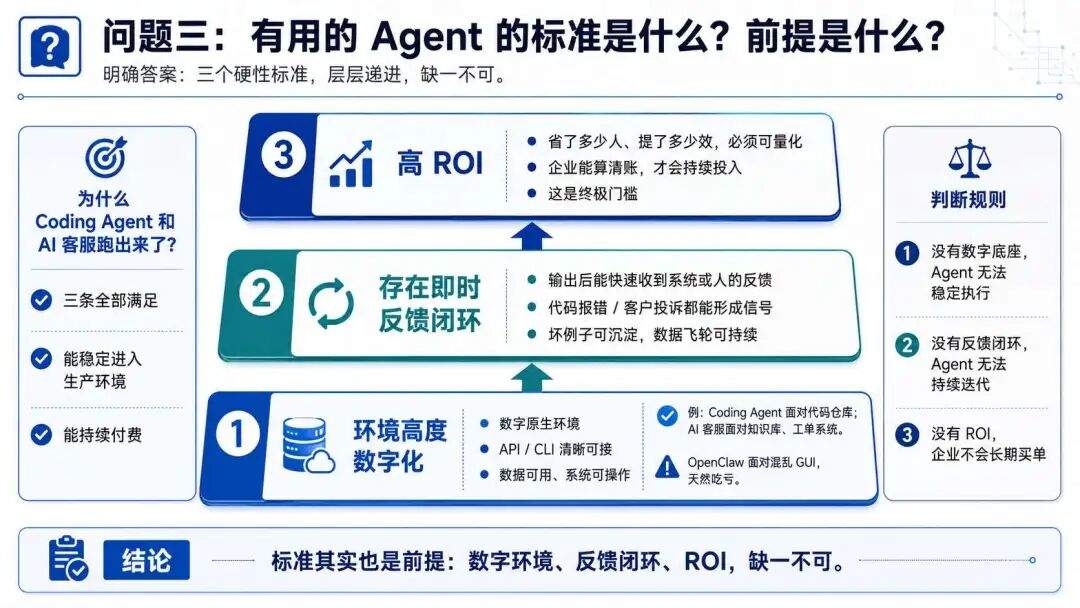
一、环境高度数字化
这是最硬核的前提,这点做不到,后续就不好展开。
Agent 的所处环境要求一定要是数字原生的,比如代码仓库/数据库/工单系统撒的,他们要有清晰的接口,比如之前 GUI 的系统,需要做 CLI 的改造,这样会更适应于 AI 的要求。
这里 Coding Agent 大家都懂,不必多说;
就 AI 客服来说,知识库充足只是第一步,如果数字底座做得不好,很多数据、很多行为都没法进行的,比如查个订单都难受。
二、存在即时反馈闭环
反馈闭环是 Agent 能否自主迭代的关键,比如:
-
Coding Agent 有问题,代码会报错、界面会点不动; -
AI 客服回答错了,客服会骂娘、会要求人工;
这里要存在反馈通路,我们需要根据反馈通路统计 Bad Case,从而才能构建数据飞轮。
三、高 ROI
最后一点很朴实,你这个 Agent 的引入对企业来说 ROI 如何,这也是我们说你的 Agent 一定要是个生产力工具,这里无论 Coding Agent 还是 AI 客服都做得很好。
大家这里要注意,如果对于企业 ROI 很低,就算对于个人效率很高的事情,他们也不会做。
企业偶尔会 Coding Agent 买单,但绝对不会为你的营销文案或者 PPT 买单,而只要 ROI 算不明白,就不会存在买单这回事,比如:
某头部互联网公司,他们半年前鼓励全员用 AI,每个员工配了几千元的 Token 费用,这个月开始,这个费用砍半,因为他们自己也没发现这个费用产生了什么价值。
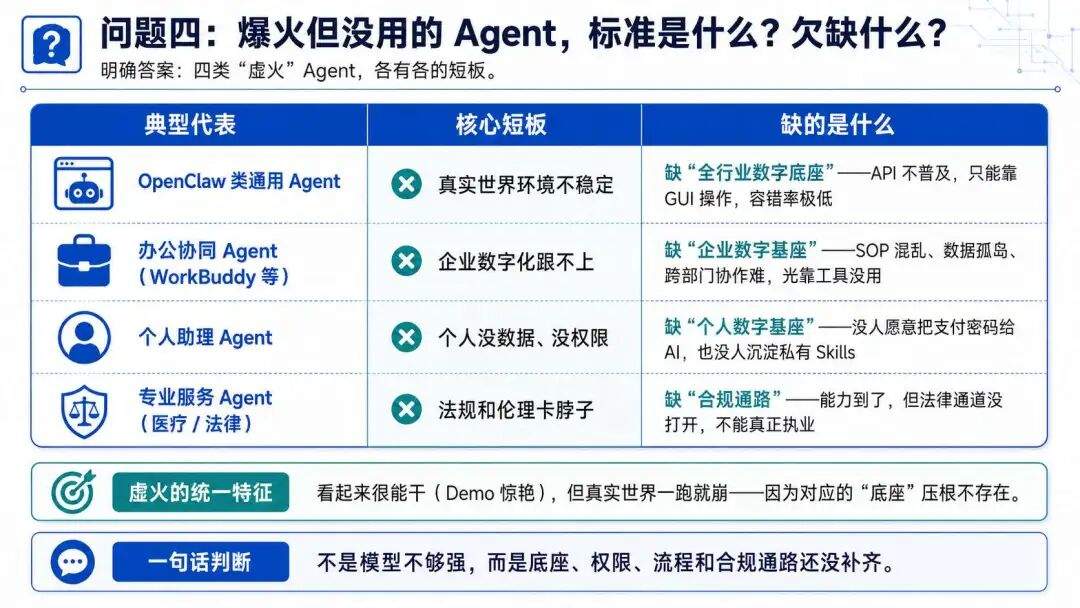
接下来,我们也聊聊那些火起来了,但是有争议性的 Agent 为什么还没站起来的原因:
一、全行业的数字底座还没建设好
要说 Demo 惊艳但实际效果不行的 Agent,这里首推 OpenClaw,他的 Demo 在固定浏览器、固定登录态、固定网页中进行,表现优异,但一到真实世界就完蛋,他完蛋有很多因素:
-
全行业的数字底座还没建设好,我们希望使用 API 去操作,但却只能通过 GUI 去操作(Browser-Use),这东西容错率很低; -
ReAct 框架带来的循环,成本有点吃紧;
二、企业数字基座不行
然后就是办公协同/数字员工平台类 Agent(WorkBuddy、钉钉悟空)了,他们的难以产生价值的最大原因就是企业数字化跟不上。
并且,暂时也不能证明企业数字化跟上了,这类 Agent 的 ROI 就一定高
我们之前为了帮一个企业实现业务 AI 原生化,直接派了一个总监级 FDE 去驻场了 3 个月时间!!!
其中多数的时间都是在做数字基座、部门对接标准的工作,所以国内几个数字员工平台要做好,可能也得复制这条路,只不过就做得挺重的了。
三、个人数字基座不行
现阶段很多人都在用 Agent,但与其说他们是助理不如说他们是闹钟。
这里面依旧会有很多数据建设和风险问题,比如我是绝对不会把自己的支付类账号给 AI 的,谁知道他订机票的时候会玩出什么花呢?
四、风险 + 法规问题
最后就是很多专业类 Agent,现在能力也许到那里了,基本数字平台也准备好了,但是依旧会受限于政策法规,还需要徐徐图之。
最后总结一下,跑出来的 Agent 至少要具备数据充足 + ROI 为正 + 能自进化的特点,说白了就是:能不能成为稳定不出错成本低的生产工具。
在这个基础上,我们再来探讨为什么需要 Agent 的问题:
为什么需要 Agent?
关于 Agent 为什么会出现,我们跳过模型需要外部数据这种基本解释,直接进入终极答案,因为:
用户无限的意图难以被有限的古法编程所覆盖
这句话是什么意思呢?我觉得可以从两点做展开:
-
核心流程的泛化能力,借助 AI 实现核心 Workflow 的泛化,也就是我们常说的 Agentic Workflow; -
跳出流程的补足能力,这个场景是 Agent 完全进入了现实不知道的场景,但依靠着 AI 的能力也把实现步骤生成出来了;
这里说得有点抽象,我翻译翻译:以前我们写代码,程序员需要将所有可能性都提前想好,用 if...else... 的方式去做流程;
但是用户的脑子并不会完全照着既定的流程来,他们今天想查天气、明天就会问你哪个机票最便宜,这也是说意图/需求是无穷的,难以全部写到如果里,这里有实际的案例:
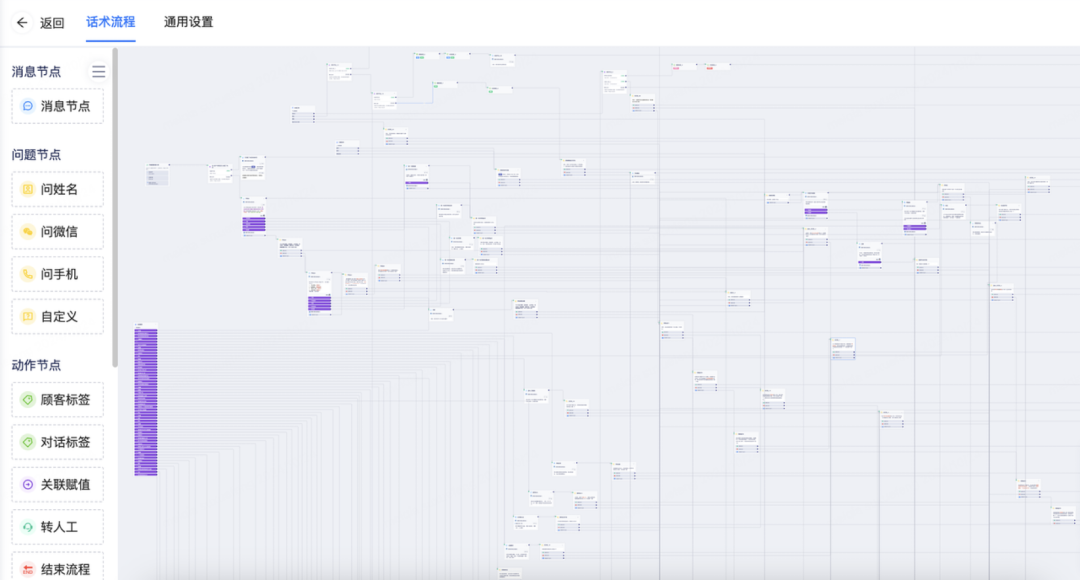
我们一个同学是某客服公司的 CTO,上图是他们某个核心业务的工作流图,他最开始非常简单,但就是不停的补充用户的“微调需求”而变得特别复杂,3 年下来程序员已经到了不想改、也改不动的状态了,维护成本极高。
再比如,原本公司内部有一个处理客户投诉的老流程(接收->分类->转人工->回复),使用 Agent 重构后,这个老流程就变聪明了,他会围绕这个大框架做事,但又会在每个环节上叠加必要的小插曲。
然后我们再说说这个跳出流程的补足,也就是完全未知的场景。之前还至少有个框架,后面完全就是 Agent 自由发挥了,这里也举个经典案例:
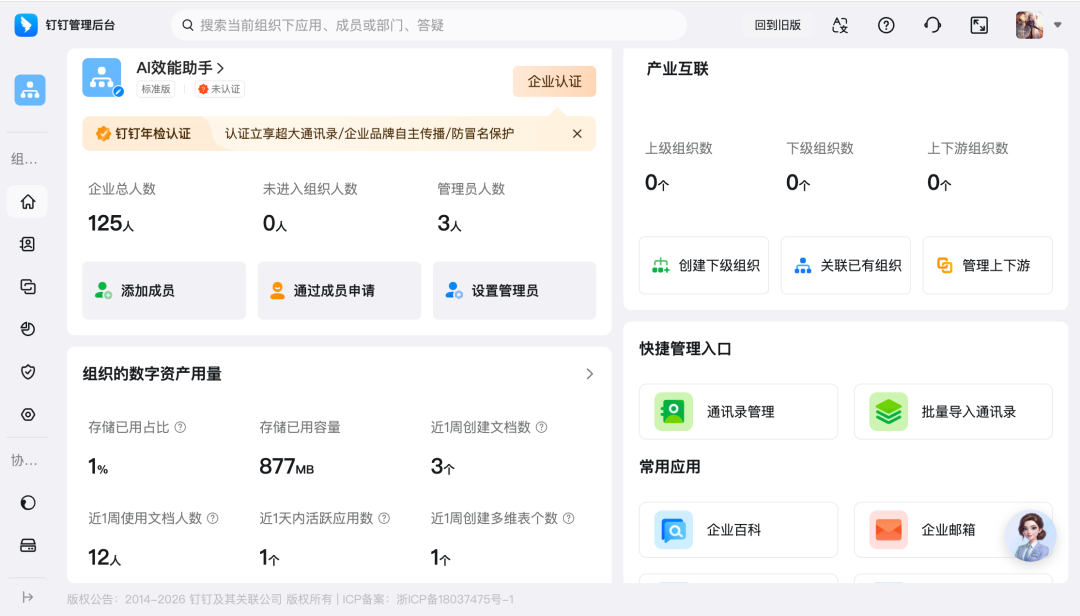
我之前使用钉钉文档时遭遇了一个问题:文档空间快满了,系统提醒你处理,但弹出框上没有任何引导,点击下就关了,所以要升级需要进入巨复杂无比的后台,也就是这个界面:
于是这里问就来了:
-
我只是文档空间满了,系统提示充值,我并不知道怎么充值; -
我本身不想充值,最好能够不充值解决问题;
类似的问题是很多的,比如一不小心就开启了京东白条,但等要关闭的时候,我感受到了噩梦!
他们都是那种直接给我干得一眼抓瞎,TMD 还得重头学习,甚至还得搜攻略的东西(这些家伙绝壁是故意的)!
这个时候就进入了前文所述:“完全未知场景”,而这个场景却是 Agent 可以覆盖并解决的经典 Case,当然前提是需要完成数字化底座的改造,这里最简单的策略就是 API CLI 化。
比如前面订单的场景会如何发生呢?我们来简单模拟下,对 Agent 说:
我的钉钉文档空间满了,你帮我看看怎么处理。
Agent 接到请求后,现场推理出解决路径,并逐条调用宿主暴露的 CLI 能力:
第一轮
Agent 先查用量,模型输出工具调用:
{"name": "doc_space_usage", "arguments": {}}
宿主映射为底层执行:
dingtalk doc-space usage --output json
返回:
{"used_gb":2.1, "capacity_gb":2, "status":"exceeded"}
第二轮
确认超限后,Agent 调权限检查:
dingtalk doc-space permission-check --output json
返回:
{"allowed": true, "admin": "叶小钗"}
第三轮
Agent 发现可以升级,转而生成一条申请文案并且钉钉消息给我确认,并调通知接口:
dingtalk message send --to 叶小钗 --text "当前空间2.1G/2G已满,建议升级至pro_10g(¥99/月),确认后立即生效,是否执行?"
等我回复“确认”后,Agent 才会执行真正的升级命令:
dingtalk doc-space upgrade --plan pro_10g --confirm --output json
整个过程的关键在于两点:
-
所有的 CLI 是什么,Agent 全部知晓; -
模型有能力根据这些 CLI 排列组合处正确的执行步骤;
综上,就是 Agent 真正出现的原因,很多朋友的业务太简单的,根本不能显示出 Agent 的为例,但另一方面如果 Agent 权限过大也会很危险。
泛化与工程代价
至此可以给出阶段性结论了:
Agent 的价值在于泛化,泛化本身就会引起很多问题
传统 Workflow 最大的问题是太死板,所有流程都需要提前设计,所以一旦用户意图变复杂,流程就会越来越臃肿,维护成本也会越来越高。
Agent 不再要求程序员把所有路径都提前写死,而是让模型根据用户目标、当前状态、可用工具,动态规划出一条执行路径,这当然很爽。
但问题也来了:模型动态规划,就一定会带来不确定性,比如:
输入目标 → 理解意图 → 制定计划 → 调用工具 → 观察结果 → 修正计划 → 继续执行
这个链路越长,变量就越多,所以我们之前才有 Agent 是一种 Token 换架构的说法:
Agent 用更高的计算成本、效率成本和稳定性成本,换取更强的场景泛化能力
总结下来,这里的工程问题有四点:
第一,稳定性差
典型表现是相同的输入拿不到相同的输出,他包括:
-
同一个任务,今天跑通,明天不一定跑通; -
这个用户能跑通,那个用户不一定能跑通; -
测试环境能跑通,生产环境不一定能跑通; -
…
第二,效率低 + 成本高
这两点都没办法,因为 Agent 的底层是 ReAct 循环,他为了保证稳定性,只能不断的确定、不断的校准。
但是真正的生产环境不会那么呆板,实际在跑的程序多半是 Workflow + Agent 的组合,几乎 80% 的核心场景 20% 工作流就搞定了,剩下的 20% 场景就交给 Agent 使出 80% 的力气就好。
第三,难治理
这也许是 AI/Agent 项目难或者说非对称性高的核心原因,传统程序出问题可以看日志、看代码,他的定位逻辑是很清晰的;
但 Agent 出错就是很多黑盒了,什么意思呢?意思是你得一个一个试,比如:
-
它为什么这么理解? -
为什么选这个工具? -
为什么跳过那个步骤? -
为什么没有转人工?
有些同学可能有点不懂,我这里简单说两句什么叫一个个试,这里涉及到了可观测性和测试数据集了,举个例子:明明该调用某个工具,它却没调用,或者调用了另一个工具?
遇到这种错,我们的解决方式是逐个修补、反复试探:
-
先收集错误 Case; -
然后思考为什么意图 A 会匹配到工具 B; -
微调工具描述、命名甚至提示词; -
改完后先用失败用例做验证,反复跑; -
…
测试数据集也是这样形成的,都是一些小数据:有问题输入、错误工具调用集、参数提取错误 Case……
这些东西,每次发布或者模型更新都得先跑一次,总之挺烦人的,AI 项目并没有大家想的那么高大上,全部在做治理…

为什么跑出来的是 Coding Agent 和 AI 客服?
上述也是为什么 Agent 这块反复出现新名词的原因,无论是 MCP、Skills、提示词工程、上下文工程还是最近集大成的 Harness,他们都是为了解决实际工程问题而生。
理解了这一点,我们再回头看为什么跑出来的是 Coding Agent 和 AI 客服?因为他们天然就存在于在高度结构化的数字环境里,也很容易做到可观测性。
Loop 工程
理解到这里,我们再来看今年很火的 Loop Engineering,就不容易被名词带偏了,他解决的是如何让 Agent 稳定执行的问题,也就是说构造执行环境的问题。
因为前面我们已经说了,Agent 的泛化能力一定会带来不稳定、低效率、高成本和难治理的问题。
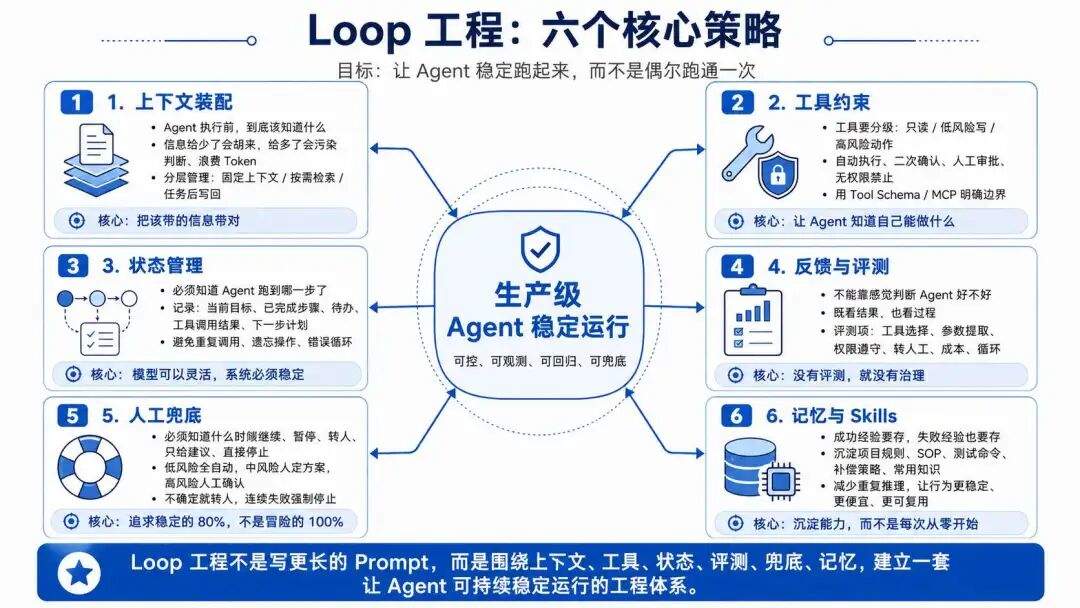
那 Loop 工程要解决的,就是怎么把这些问题兜住,他是面向生产级 Agent 的协作与治理工程,如果你要打开,会发现全部是些策略,比如:
结语
今天我们聊了很多内容:
-
什么 Agent 在火; -
Agent 为什么出现; -
用好 Agent 的工程代价是什么;
其实搞这么多事情,最终都是想要回答一个问题:企业要如何把 Agent 用好?而这里的答案应该也很清晰了:
为 Agent 构造工程环境 + 数字原生底座
这也是很多公司实际在做的事情:追求 AI 原生。
只不过现阶段行业对于 AI 原生概念是很模糊的,也没有个通用的最佳实践,于是容易出现两个极端:
-
一上来就喊 AI 原生、数字员工、Agent 化组织; -
把 AI 只当成个人工具;
根据之前实践,普通企业进入 AI 原生团队,应该是一个渐进过程:
L1 个人工具
L2 团队助手
L3 流程节点
L4 数字员工
L5 原生组织基建
判断一个团队是不是 AI 原生团队,需要从业务出发看他们在用 AI 做什么,这里就又要回归三类核心资产了:
第一,工程能力:能不能把 AI 做成稳定系统;
第二,行业认知:能不能把业务 Know-how 梳理成 SOP/Workflow/判断规则;
第三,优质数据:能不能把业务过程、专家经验、错误案例、反馈结果沉淀成数据资产。
毕竟,前面 AI 切入团队的七种方式,没有一种对员工能力是低要求的…
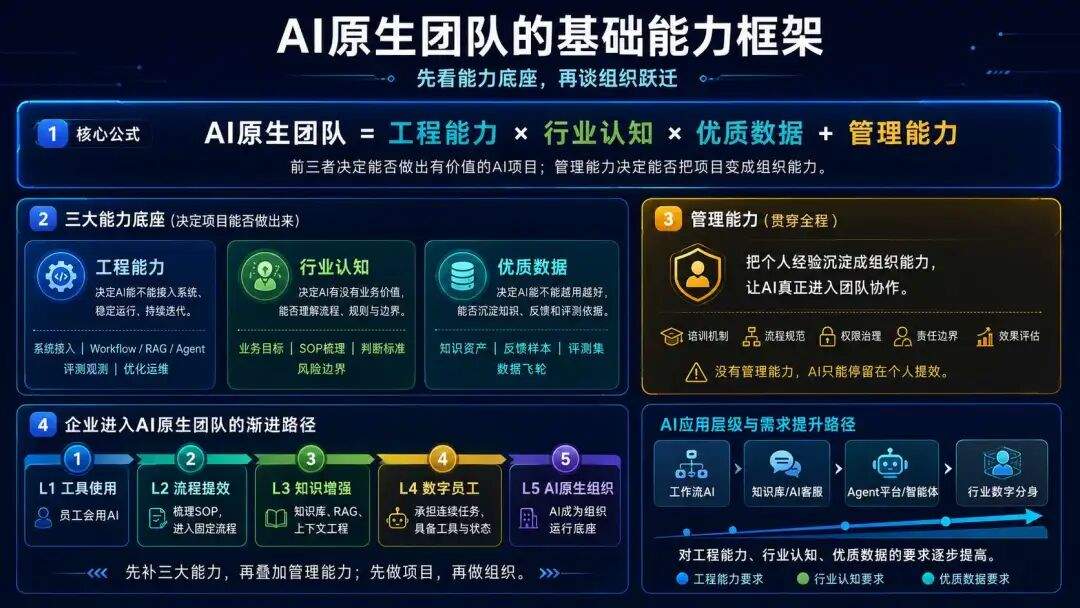
工程能力决定 AI 能不能跑起来。Demo 可以很简单,但真实项目要调工具、控成本、做评测,还要能兜底和迭代。没有工程能力,AI 项目很难从 Demo 走向生产。
行业认知决定 AI 有没有业务价值。AI 不只是回答问题,更要理解业务流程、判断标准和风险边界。没有行业 Know-how,AI 只能做通用问答,很难解决真问题。
优质数据决定 AI 能不能越用越好。聊天记录、文档和表格不等于数据资产。真正有价值的数据,必须能被结构化、追溯、反馈和评测。否则 AI 项目很容易上线即巅峰,后面越用越差。
好了,篇幅已经不小了,今天的内容就到这,希望对各位有用!