
先说一个反常的画面。一个仓库才两天大,提交记录数到一只手都用不完,README 里有一整节标题写着 Visualization 底下却是空的。可它同时挂着一篇 arXiv 论文、一个 ModelScope 模型入口,还有一张端到端 SOTA 的跑分表。这就是百度 2026 年 6 月 22 日丢出来的 Unlimited-OCR 给我的第一印象:论文先到了,工程还在路上。
这种”先发论文再补代码”的节奏,在大厂开源里越来越常见。它不像一个打磨好的产品,更像把研究成果原封不动搬到 GitHub。所以你要是冲着”开箱即用的长文档 OCR”来的,得先把期待往回收一点。但要是你关心 OCR 这条赛道接下来往哪走,这个项目值得认真看一眼,因为它解决的问题相当真实。
它想干掉的,是长文档 OCR 里那个最烦人的环节:切页、切块、识别、再把结果拼回去。这套流程在年报、合同附件、扫描论文上一旦跑起来,跨页表格和目录层级很容易被切碎,后处理重得让人头疼。Unlimited-OCR 的答案是让模型在一次前向里把几十页文档一口气解析完。听起来像营销话术,但它背后有套不算花哨的机制撑着。
打动我的几个地方
最核心的卖点只有一句话:KV cache 不随文档变长。
传统的视觉语言模型做长文档解析,输出序列越长,解码器的 KV cache 就线性膨胀,显存和延迟跟着一路涨。这也是为什么 DeepSeek-OCR 这类方案处理超长文档时还得回到分页的老路上。
Unlimited-OCR 用一个叫 R-SWA(Reference Sliding Window Attention,参考滑动窗口注意力)的机制把这个问题摁住了:每个新生成的 token 只关注全部参考 token(视觉特征加提示词)和最近的 128 个输出 token,KV cache 被实现成一个容量固定为 m+n 的队列,每吐出一个新 token 就淘汰最旧的那个。
结果就是无论文档多长、输出多长,显存占用和单次推理延迟都保持水平。据官方论文和第三方整理的数据,它在 OmniDocBench v1.6 上拿到 93.92% 的总分,是端到端口径的第一,推理速度做到 5580 TPS 且全程常数延迟。这个”常数”才是真正的看点,不是那个被打了引号的 Unlimited。

上图把两条路线摆在一起看就清楚了。左边是切页拼接的老流程,环节多、跨页结构容易丢;右边是 Unlimited-OCR 把多页图像塞进一次长上下文推理,工程链条短了一截。对要处理成百上千页扫描件的团队来说,少切一刀,后处理的规则工程就能省下一块。
还有个容易被忽略的点:R-SWA 不是 OCR 专属的 trick。它本质是个通用的”参考源加长输出”解码方案,理论上能迁移到 ASR、字幕生成、长文翻译这类任务上。这意味着这套机制的价值可能不止于 OCR 本身。
它到底怎么做到的
把模型拆开看,结构其实挺清晰,三段式。
视觉这头用的是 DeepEncoder,沿用 SAM-ViT 级联 CLIP-ViT 的架构,中间加了个 bridge 层做 16 倍的 token 压缩,一张 1024×1024 的图像被压成 256 个视觉 token,编码一次之后就冻结。压缩这一步很关键,它直接决定了后面解码器要背多重的视觉包袱。解码器是个 3B 总参、500M 激活的 MoE 架构,全部注意力层都被换成了 R-SWA,整个模型是基于 DeepSeek-OCR 的 checkpoint 续训 4000 步得来的。
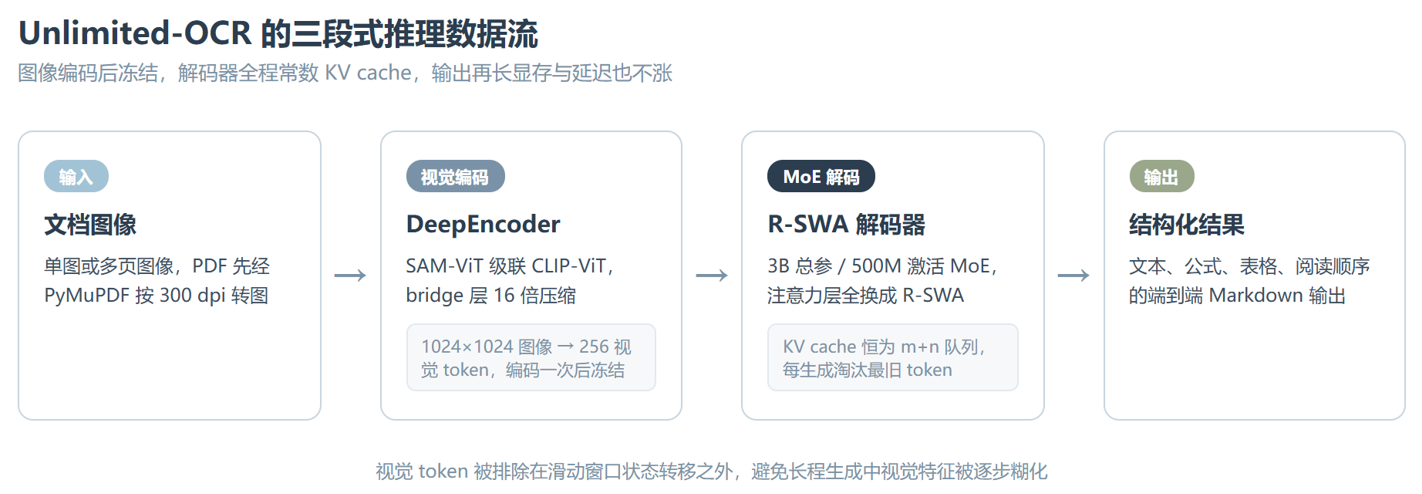
数据流走下来就是上图这条线:图像进 DeepEncoder 压成 256 个视觉 token,喂给带 R-SWA 的 MoE 解码器,常数 KV cache 一路滚动,最后吐出带版面结构的 Markdown。值得多说一句的是 R-SWA 把视觉 token 排除在滑动窗口的状态转移之外,这是为了避免长程生成里视觉特征被一步步糊掉。这个细节挺聪明,长文档解析最怕的就是越往后越跑偏。
“基于 DeepSeek-OCR 续训”这件事得讲明白。它不是从零造的孤立方案,README 的致谢里同时列了 DeepSeek-OCR、DeepSeek-OCR-2 和 PaddleOCR。换句话说,它是站在 DeepSeek 那条端到端解析路线上,再叠了一层注意力机制的改造。理解这个出身,你才能正确判断它的定位。
跑起来什么感觉
官方给了两条路径,门槛差别不小。
轻量试的话走 Transformers,直接 AutoModel.from_pretrained('baidu/Unlimited-OCR') 加载,调 model.infer 处理单图,调 model.infer_multi 处理多页或 PDF。单图有 gundam 和 base 两种配置,gundam 用动态分辨率追求单页精度,base 固定 1024×1024 用于多页长文档。要注意 PDF 不是原生读入的,得先用 PyMuPDF 按 300 dpi 把每页转成图片,再进多页解析流程。
要做服务化或者批量跑,就上 SGLang,拉一个 OpenAI 兼容的接口,配合仓库里的 infer.py 能自动起 server 并发处理整个图片目录或 PDF。
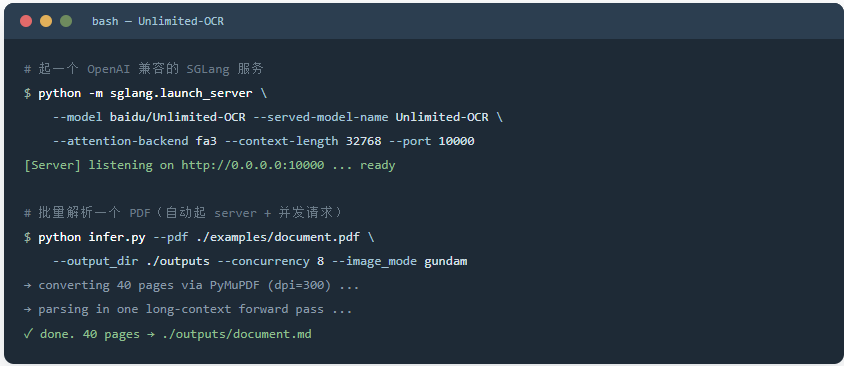
部署命令大致是上图这个样子。但这里藏着第一个真坑:依赖版本新得吓人。torch 要 2.10.0、transformers 要 4.57.1、跑在 CUDA 12.9 上,SGLang 用的还是一个本地的 dev wheel(sglang-0.0.0.dev11416)。这套组合不是你现成的环境能直接接住的,老老实实开个干净的虚拟环境吧,不然依赖地狱够你折腾一下午。
什么时候用,什么时候先别用
它适合谁,不适合谁,得分清楚。
| 场景 | 适配度 | 说明 |
|---|---|---|
| 长 PDF 批量结构化(年报、合同、论文扫描件) | 高 | 跨页一次解析正是它的主场,少切片少拼接 |
| 企业档案数字化(古籍、合订本、成百上千页) | 高 | 常数显存让长文档不会越跑越吃资源 |
| 单页截图、票据快速取字 | 低 | 杀鸡用牛刀,PaddleOCR 这类工具链更轻更稳 |
| 生产环境直接替换现有 OCR | 暂不建议 | 两天大的仓库,工程化几乎为零 |
局限也得摆上台面。那个 Unlimited 是要打引号的,README 里的示例上下文长度是 32768,不是任意页数任意长度。PDF 非原生读取这点前面说过,多了一道转图的预处理。更现实的是,早期评论者普遍认为它公开的并发服务单位成本、不同语种复杂版面的准确率、超长 PDF 下的真实显存曲线,这些落地最关心的数据还不够充分。跑分漂亮,不等于你的业务文档上也漂亮。
社区怎么样了
这部分没法粉饰,项目实在太新了。
| 指标 | 现状 |
|---|---|
| 首次提交 | 2026 年 6 月 22 日 |
| 提交总数 | 仅 4 个 commit |
| 论文 | 6 月 23 日上 arXiv(编号 2606.23050) |
| 模型分发 | Hugging Face + ModelScope 已上线 |
| 开源协议 | 仓库含 LICENSE 文件,以官方仓库为准 |
Star 数现在没什么参考价值,一个发布两天的仓库还没攒到能说明社区态度的量级,这时候盯着 Star 看纯属自欺欺人。真正能看的是分发渠道:模型同步上了 Hugging Face 和 ModelScope,论文也进了 arXiv,说明百度是按”研究项目”的规格在推它,而不是随手扔个 demo。
外部已经有了第一批冷静的声音。科技媒体 ic.work 在发布次日给了一句相当克制的锐评:”名曰 Unlimited,实看边界。能少切一刀是进步,若把名字当能力,便是买椟还珠。”同一篇文章给的落地建议我觉得最实在:把它放进测试队列,挑团队手里最难啃的 20 到 50 份长文档,跟现有 OCR、PaddleOCR 或自研链路做人工复核对比,跨页结构明显更稳再谈替换,要是只是单页识别打个平手,省下的那点工程量会被推理成本吃掉。
我的真实看法
值得跟,但得摆正姿势,这是我的总判断。先说值得跟的理由,再说为什么得按住别冲动。
如果你做的是文档智能,尤其被多页 PDF 的版面恢复和跨页表格折磨过,这个项目应该进你的观察清单。它对标的是 DeepSeek-OCR,而且在 OmniDocBench 上的数字确实压过了基座:v1.5 总分 93.23% 对 87.01%,文本编辑距离 0.038 对 0.073,公式和表格指标也都领先一截。这不是营销吹出来的,是论文里的硬跑分。常数显存这个工程特性,对要长期跑长文档流水线的团队是实打实的诱惑。
那它和大家更熟的 PaddleOCR 又是什么关系?说实话,这俩根本不在一个层面上比。PaddleOCR 是百度自家那套成熟的工程化工具链,强在生态、稳定和轻量,单页取字、票据识别这种活儿它又快又省。Unlimited-OCR 走的是视觉语言模型端到端解析这条路,要论同类,它跟 DeepSeek-OCR、MinerU 这些端到端方案才算同代竞争者。一句话区分:PaddleOCR 解决的是”看得清每个字”,Unlimited-OCR 想解决的是”一口气读懂整本文档”。目标不一样,别想着拿它当现有 OCR 工具链的替代品直接换上去。
但别急着上生产。四个 commit、两天历史、空着的 Visualization 章节,这些都在提醒你它现在还是个研究原型。依赖栈又新又重,SGLang 还停在 dev wheel 阶段,这意味着接下来几周接口和用法都可能变。我的判断是:现在适合拿来跑实验、验证它在你自己数据上的真实表现,不适合写进任何采购或架构决策的结论里。
趋势上我是偏乐观的。它踩在 DeepSeek-OCR 这条最热的端到端解析赛道上,又有百度的资源背书,R-SWA 这个机制本身的通用性也给了它超出 OCR 的想象空间。这种项目通常不会停在四个 commit,接下来值得盯着它的更新节奏。一个真实的好东西,往往是从一个还很粗糙的研究原型开始的。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub 仓库 | https://github.com/baidu/Unlimited-OCR |
| arXiv 论文 | https://arxiv.org/abs/2606.23050 |
| ModelScope 模型 | https://modelscope.cn/models/PaddlePaddle/Unlimited-OCR |
论文先到的项目,先验证再下结论
回头看这一圈,Unlimited-OCR 最值钱的不是那个被打引号的名字,是它把长文档解析的资源曲线从线性拉平成常数这件事。这是个真问题的真解法。但它现在的形态是研究原型,不是生产工具,拿你最难的几十份文档去实测一遍,比看任何跑分表都靠谱。它在往上走,只是还太早。