
《万字:拆解 OpenClaw:从 Gateway、Memory、Skills、多 Agent 到 Runtime》
我们之前说过除了记忆系统,Agent 是没什么技术难度的。
比如你自己做了个 Agent,如果只是想用他去装载几个 skill,去完成日常自媒体的选题、或者去小红书等平台上自动发发文章,那是比较简单的。
但,如果你想让这个 Agent 越用越好用,越用越贴心,用的越久它就越懂你,这就难办了,他会涉及很多问题,比如:
-
它是如何知道你前天干了什么事情; -
它是如何记住做事的先后次序而没有混乱; -
…
要解决这一切,就不得不提 Agent 的上下文工程了。在 Manus 时代,这个技术就很金贵,大家都捂着捂着不想拿出来,可 OpenClaw 这波开源,一下就让大家看到生产级别的记忆系统是什么样的了。
所以,你如果问我 OpenClaw 什么最有价值,我一定会建议大家去读读他记忆模块的源码,那可是进阶利器啊!!!
当然,我也知道各位时间紧(懒)任务重,所以今天我们特别带着大家一起来拆解 OpenClaw 的记忆模块/上下文工程:
上下文工程
很多人一看到上下文第一反应就是提示词或者 RAG。
这个理解不能说是错的,但有点片面,也就像把写几行代码等同于软件工程一样。
在我看来,上下文工程是一整套系统性地构建、管理和注入与任务相关的上下文信息的工程方法,简单来说:
上下文工程,就是给大模型设计一套高可用、可治理、能长期稳定运行的输入系统
那么更具象化一点,什么是上下文?说白了,可能还是提示词,它是模型在当前这一轮推理中/提示词中,能看到的所有信息的总和。
Context = System Prompt
+ User Input
+ 历史对话
+ 工具返回结果
+ 检索内容(RAG)
+ Memory(长期记忆)
所有这些信息拼在一起,才是模型真正用来思考、决策、输出答案的全部依据。
解决什么问题
大模型有三个短板,上下文工程,就是为了补齐这些短板而存在:
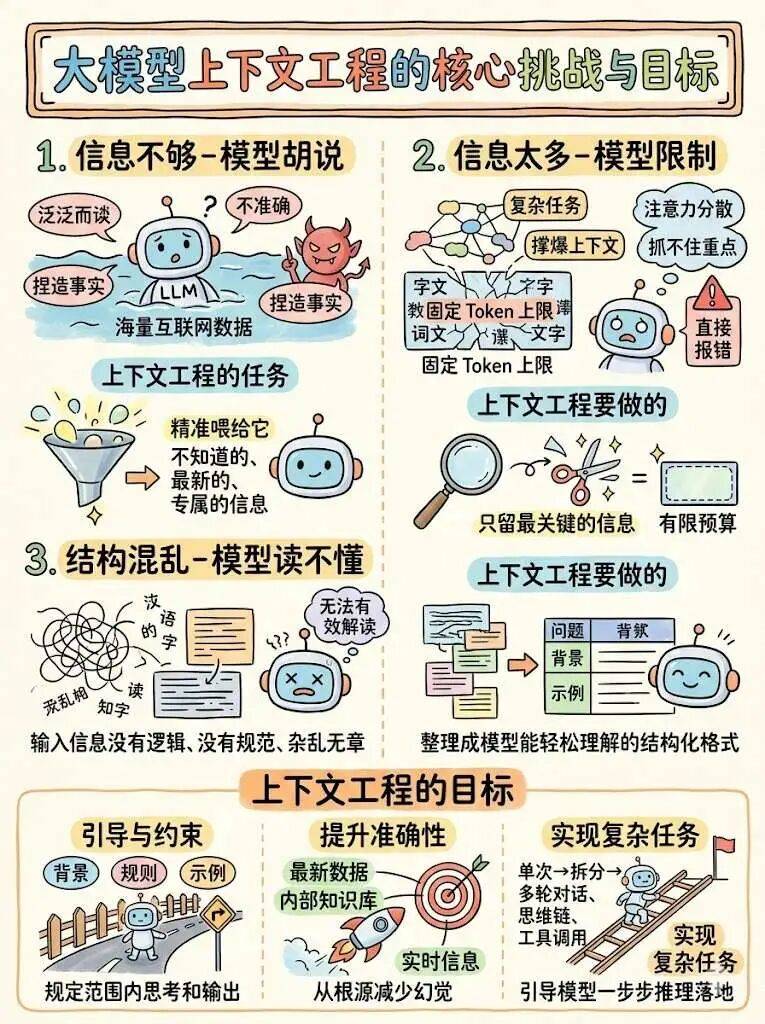
胡言乱语
大模型在训练时,从海量互联网数据中学习到了很多知识,如果不加以引导,模型会泛泛而谈,回答不够准确,甚至捏造事实;
上下文工程的任务,就是把模型不知道的、最新的、专属的信息精准喂给它。
长度限制
模型有固定的 Token 上限,复杂任务很容易把上下文撑爆。
过长内容会让模型注意力分散、抓不住重点、甚至直接报错。
上下文工程要做的,就是在有限预算里,只保留最关键的信息。
模型读不懂
如果输入信息没有逻辑、没有规范、杂乱无章,模型就无法有效解读。
上下文工程要做的,就是把信息整理成模型能轻松理解的结构化格式。
上下文工程的目标
所以,上下文工程的任务也就出现了,他需要:
-
引导与约束。用背景、规则、示例给模型划定边界,让它只在规定范围内思考和输出。 -
提升准确性。注入最新数据、内部知识库、实时信息,从根源减少幻觉。 -
实现复杂任务。把单次无法完成的复杂任务,拆成多轮对话、思维链、工具调用,引导模型一步步推理落地。
如何实现
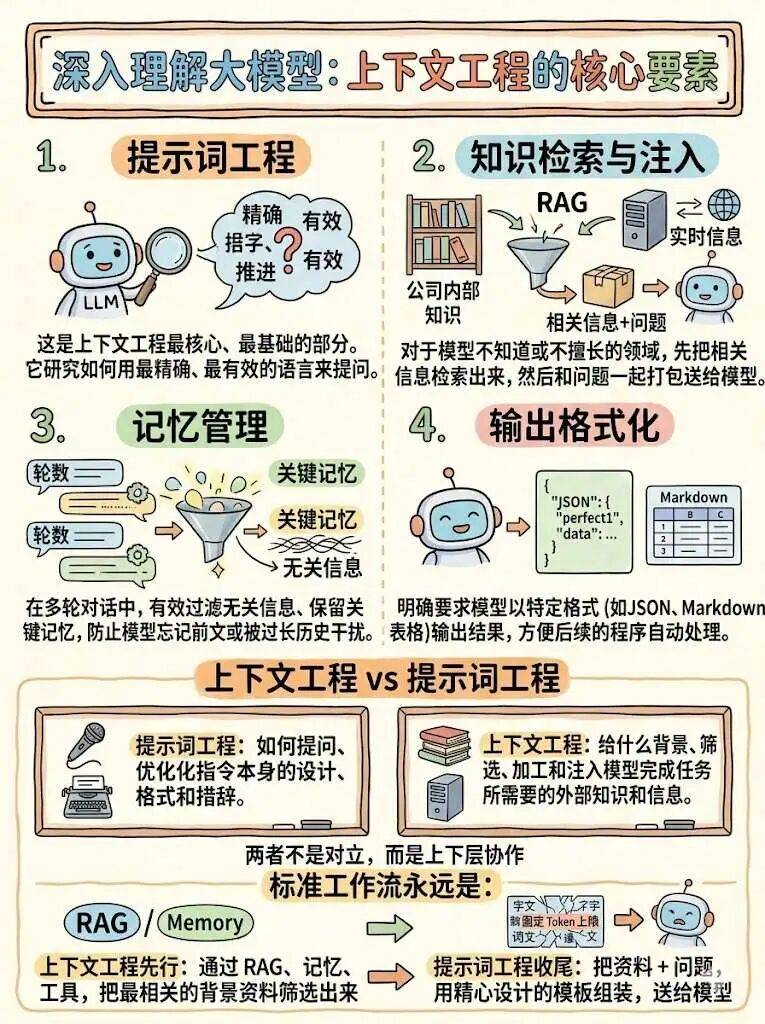
首先,提示词工程是上下文工程最核心、最基础的部分。它研究如何用最精确、最有效的语言来提问。
然后就行知识检索与注入,对于模型不知道或不擅长的领域(如公司内部知识、实时信息),上下文工程会通过技术手段(RAG)先把相关信息检索出来,然后和问题一起打包送给模型。
然后就是对记忆的管理,在多轮对话中,有效过滤无关信息、保留关键记忆,防止模型忘记前文或被过长历史干扰。
最后就是输出格式化,明确要求模型以特定格式(如JSON、Markdown表格)输出结果,方便后续的程序自动处理。
这里特别提一下:上下文工程 vs 提示词工程。很多人分不清这两个概念,我们用最直白的方式讲清楚:
-
提示词工程:如何提问、优化指令本身的设计、格式和措辞。 -
上下文工程:给什么背景、筛选、加工和注入模型完成任务所需的外部知识和信息。
所以可以看出来,两者不是对立,而是上下层协作。标准工作流永远是:
-
上下文工程先行:通过 RAG、记忆、工具,把最相关的背景资料筛选出来 -
提示词工程收尾:把资料 + 问题,用精心设计的模板组装,送给模型
我知道大家看不懂,所以举个真实例子:
用户问:华为最新的旗舰手机是哪一款,什么价格?
- 上下文工程:从新闻搜索到华为旗舰手机、价格等信息
- 提示词工程:设计模板 → 根据以下资料:{{context}},回答用户的问题:{{query}}
至此,大家对上下文的基本概率有所了解了,我们开始上强度:
OpenClaw 的上下文工程
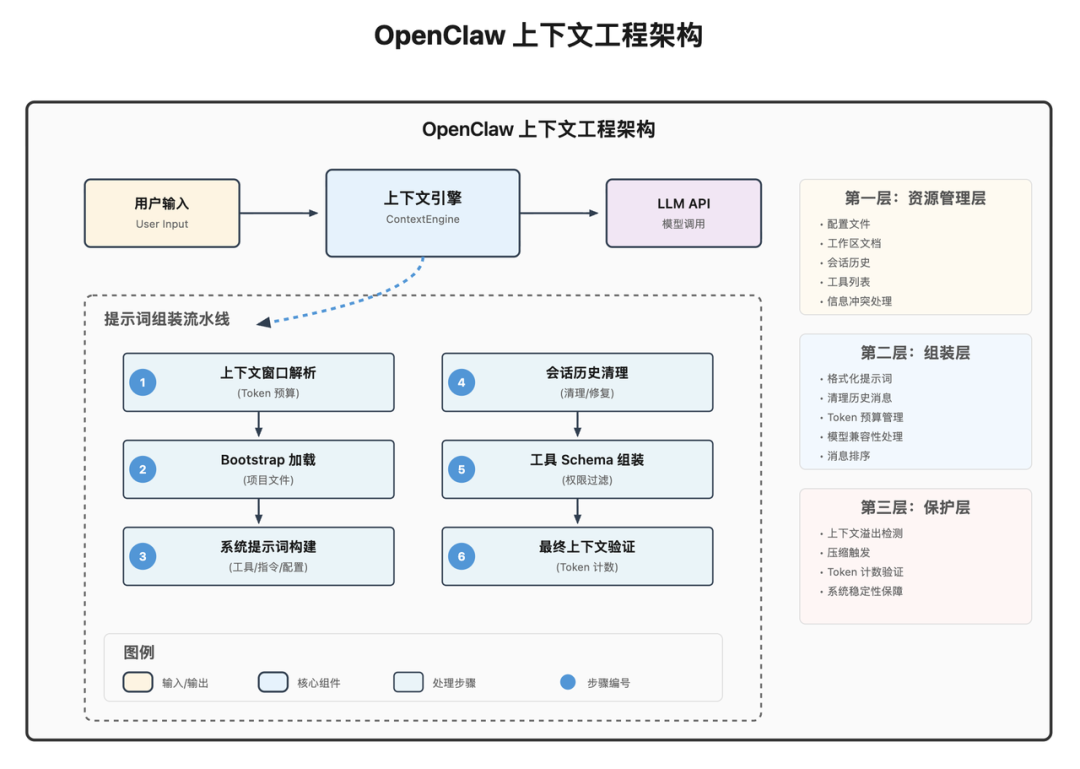
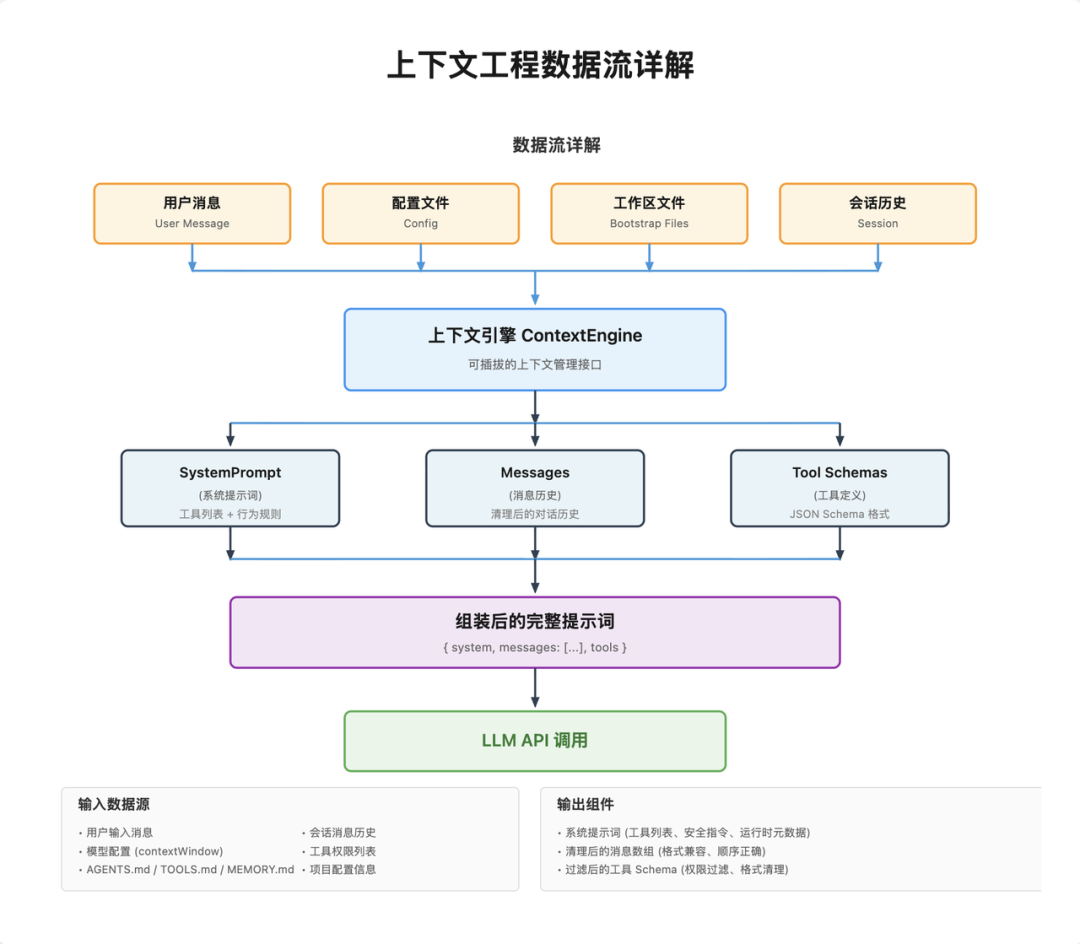
OpenClaw 的上下文工程采用了流水线架构。整个提示词的组装过程像一条工厂流水线,原始数据从一端进入,经过一系列处理步骤,最终成品(完整的提示词)从另一端输出。
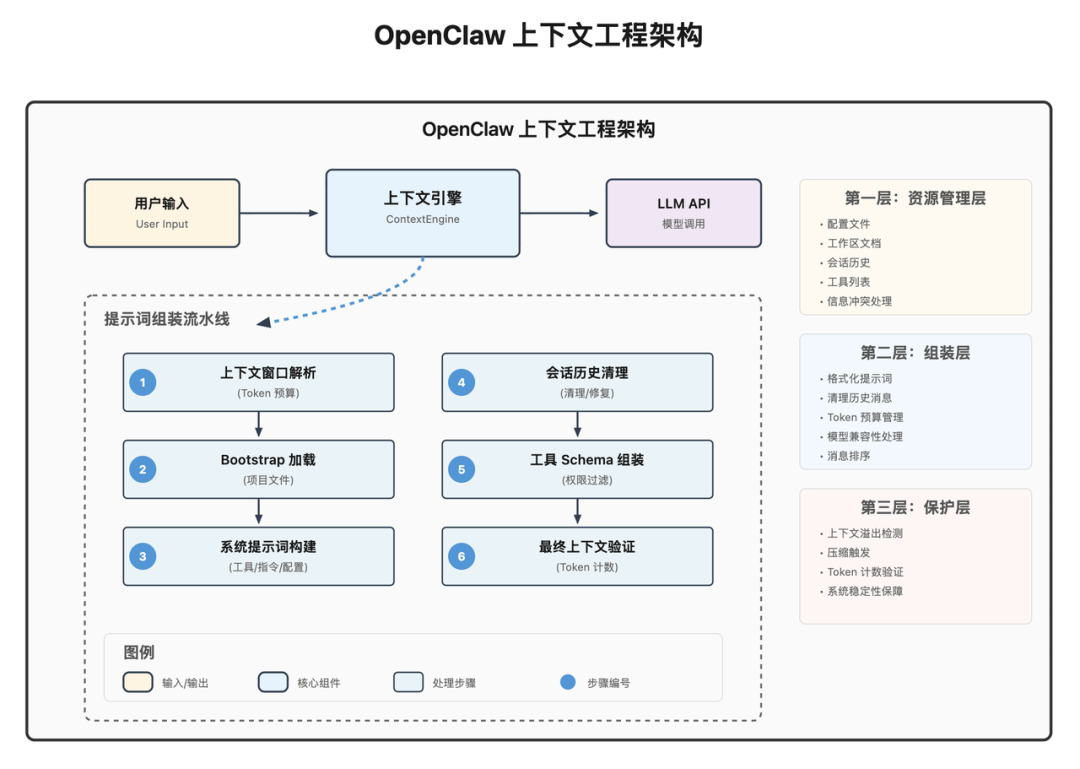
从解析来说,可以分为三层:
第一层:资源管理层
负责管理所有上下文的信息来源,核心工作:决定哪些信息必须留、哪些可以删、冲突信息怎么处理。
用户配置
工作区文档(AGENTS.md、TOOLS.md 等)
对话历史、工具列表、长期记忆
第二层:组装层
把收集到的所有资源,按固定格式、固定顺序拼装。
模型格式兼容问题
历史消息脏数据清理
Token 预算内的取舍权衡
第三层:保护层
确保系统安全稳定运行:
检测上下文是否即将溢出
自动触发压缩
防止系统因上下文过大崩溃
接下来是核心模块的实现:
上下文引擎
可插拔标准接口,定义上下文管理全生命周期契约。
默认提供传统引擎,支持自定义扩展,比如接入 RAG:
接下来按照流程图依次做展开:
系统提示词构建器
生成 Agent 的 身份说明书,一段高质量系统提示词,他决定了 Agent 的能力上限。
你是什么
你能做什么
你应该遵循什么规则
你的工作目录在哪里
Bootstrap 加载器。读取工作区里的特殊配置文件,自动注入提示词:
AGENTS.md:项目行为规则
TOOLS.md:工具使用说明
MEMORY.md:长期记忆
SOUL.md:人格风格
会话清理器。修复历史消息里的所有问题,保证送给模型的历史干净、合规、兼容的。
删除无效工具调用
压缩超限图片
修复消息顺序错乱
处理跨会话消息标记
当上下文快撑爆时,就启动上下文压缩器自动瘦身,不丢关键信息。
上下文组装
在开始组装任何内容之前,系统需要确定模型的上下文窗口大小(context window),也就是模型一次能够处理的最大 token 数量。
不同的模型有不同的上下文窗口:小模型可能只有 32K tokens,而大模型可能有 200K 甚至更多。
OpenClaw 通过四个来源来获取这个数值,优先级从高到低是:
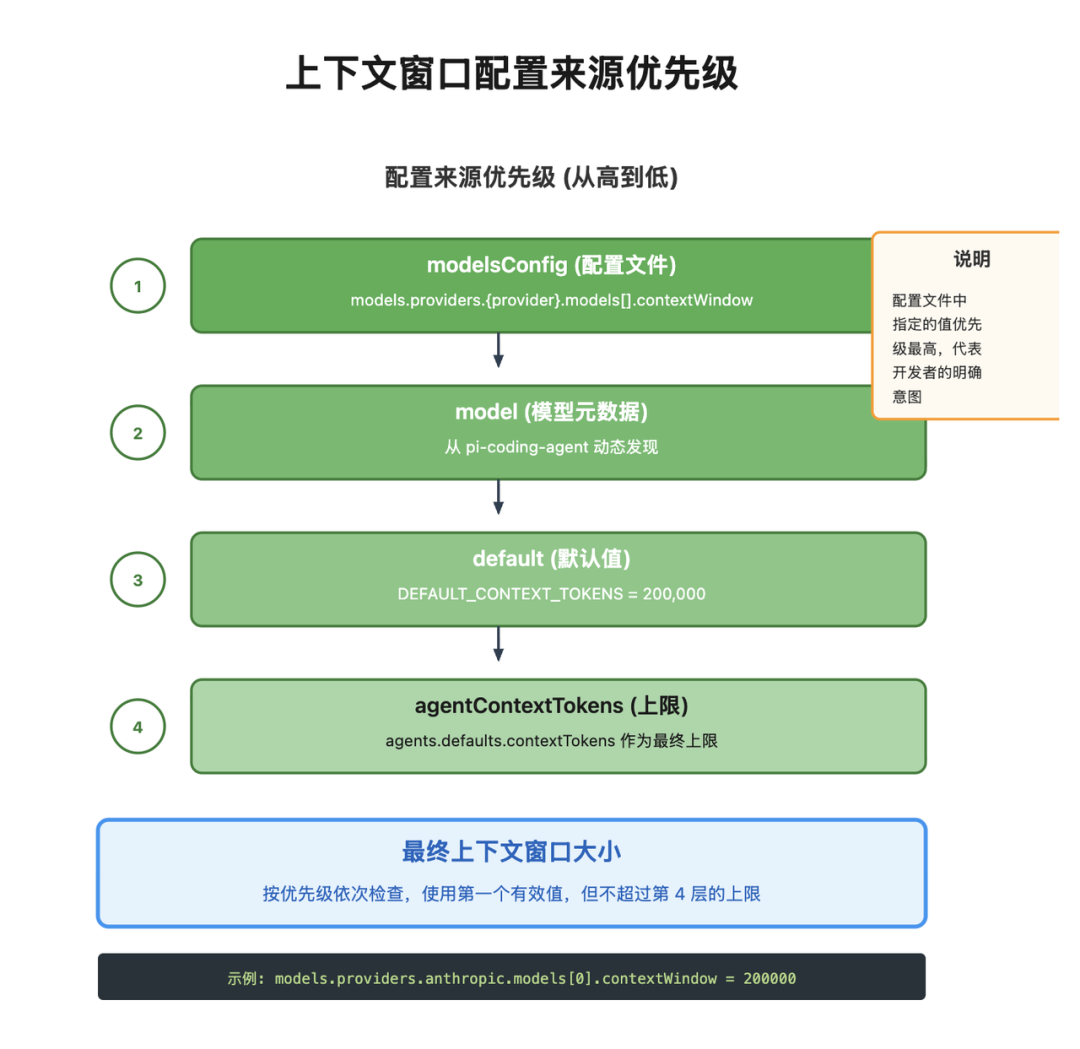
1. 配置文件中的明确指定:开发者可以在 models.providers.{provider}.models[].contextWindow 中明确指定。这个值的优先级最高,因为它代表了开发者的明确意图。
2. 模型元数据:OpenClaw 的模型发现系统会自动从模型提供商获取元数据,其中包含上下文窗口信息。
3. 默认值:如果前两个来源都不可用,系统使用 200,000 作为默认值。
4. 配置上限:最后,系统会检查 agents.defaults.contextTokens 配置,如果这个值小于前面计算的值,会使用这个较小的值作为上限。这可以防止开发者不小心配置了过大的上下文窗口。
确定上下文窗口后,系统还需要执行保护检查。这里有一个关键的细节:配置上限的覆盖作用。
即使你在模型配置中明确指定了 contextWindow,系统还会检查 agents.defaults.contextTokens 配置。
如果这个值更小,会用它作为实际上限,这可以防止开发者不小心配置了过大的上下文窗口导致内存问题。
保护检查的阈值:
-
硬性最小值(16000 tokens):如果上下文窗口低于此值,系统会直接阻止运行并抛出错误,因为这么小的空间无法支持有意义的对话 -
警告阈值(32000 tokens):如果低于此值,系统会记录警告日志,提醒用户上下文可能不足,但不会阻止运行

加载项目上下文
在确定上下文窗口大小后,系统开始收集项目特定的上下文信息。这些信息来自工作区中的特殊文件,被称为”Bootstrap 文件”。
Bootstrap 文件是开发者为 Agent 提供的”项目说明书”,例如:
- AGENTS.md:告诉 Agent 在这个项目中应该如何表现,有哪些特殊的规则要遵循
- TOOLS.md:解释项目中使用的特殊工具或命令
- MEMORY.md(或 memory.md):记录重要的决策、约定或历史信息,确保 Agent 能够记住关键细节
- SOUL.md:定义 Agent 的人格和语气,让它的回复更加一致和有个性
- IDENTITY.md:定义项目身份和边界,说明这个工作区是什么、做什么的
- USER.md:提供用户特定的偏好和习惯,让 Agent 更好地适配用户风格
- HEARTBEAT.md:用于定时检查任务的指令
- BOOTSTRAP.md:仅在新工作区首次运行时提供初始化引导
系统会按优先级加载这些文件:主会话加载全部,子 Agent 和心跳运行只加载核心文件(AGENTS.md、TOOLS.md、SOUL.md)。
加载这些文件时,系统需要考虑几个问题:
一、文件大小控制:
单个文件可能非常大,如果全部加载会消耗太多 token。系统会为每个文件设置一个上限(默认 20000 字符),超出部分会被截断。
同时,所有文件的总大小也有上限(默认 150000 字符),当超出时会停止加载新文件。
二、会话过滤:
不同的会话可能需要不同的上下文。
系统支持根据会话键(session key)来过滤哪些文件应该被加载。
例如,某个 AGENTS.md 文件可能只对特定的会话有效。
三、上下文模式:
系统支持三种上下文模式:
-
完整模式(full)加载所有文件; -
轻量模式(lightweight)只加载最基本的信息,甚至可能完全跳过 Bootstrap 加载; -
无模式(none)完全不注入项目上下文。轻量模式通常用于子 Agent 或心跳检查,因为它们不需要完整的项目背景。

管理记忆内容
你可能会问,Agent 怎么知道我前天干了什么?它怎么记住各种决策和约定?这就是记忆系统要做的事情。
先搞清楚一个重要的区别:OpenClaw 的记忆分两层。
第一层:工作区 Markdown 文件。这是记忆的数据来源。
~/.openclaw/workspace/
├── MEMORY.md # 长期记忆(决策、约定、持久事实)
└── memory/
├── 2026-03-20.md # 每日日志
├── 2026-03-21.md # 今天
└── ...
-
MEMORY.md(或小写memory.md):存放持久化的内容,比如项目约定、重要决策 -
memory/YYYY-MM-DD.md:每日流水,当天的笔记、临时讨论都往这里写
第二层:向量索引。让你能”搜索”这些文件。
系统会监控这些文件的变化,把它们切分成小块(chunks,每块约 400 tokens),然后用嵌入模型(embedding)把每块转换成向量。
这个索引存储在 SQLite 里,位置在 ~/.openclaw/memory/<agentId>.sqlite。
搜索的时候,系统用的是混合检索:
向量检索负责”理解意思”。你问”那个网络配置的事”,它能找到关于 “router”、”VLAN” 的讨论,哪怕没出现原词。
BM25 关键词检索负责”精确匹配”:ID、代码符号、特定的错误信息,这些需要精准匹配才行哦
两者按权重融合(默认向量 70%、关键词 30%),然后可选地应用时间衰减,最近的笔记权重更高 和 MMR 去重,避免返回五条几乎相同的内容。
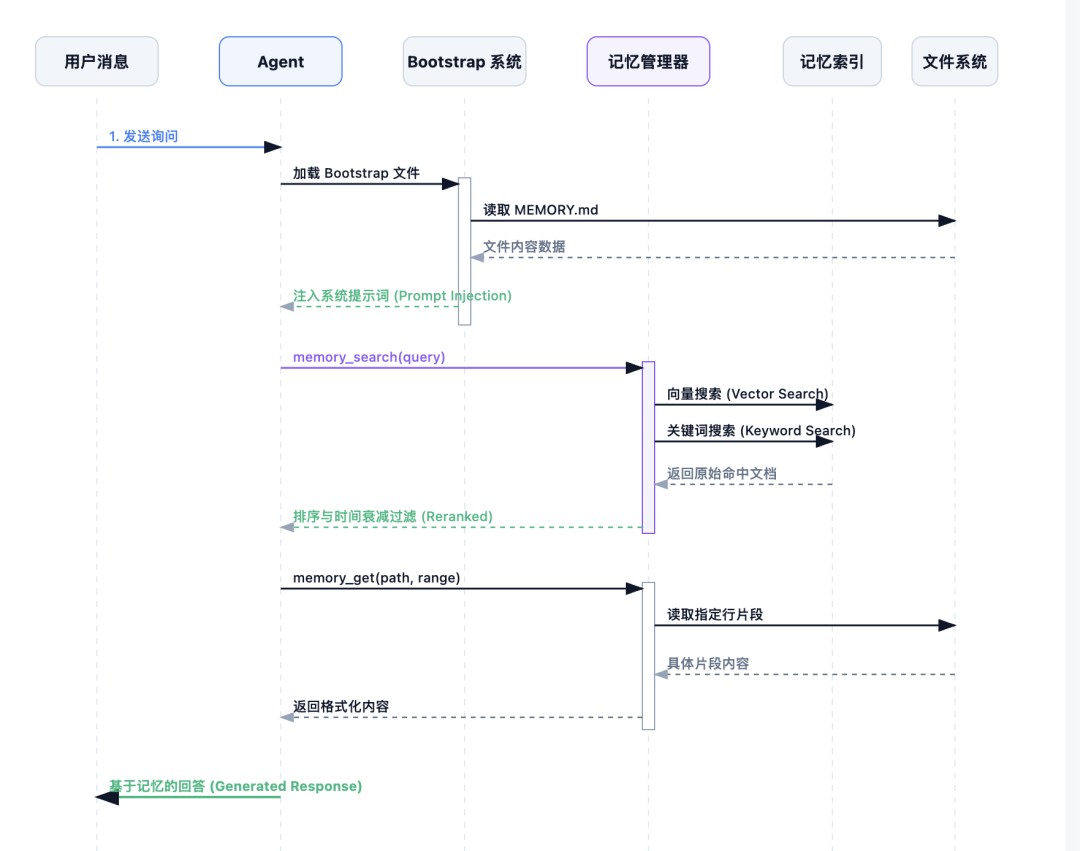
Agent 访问记忆的方式
不是所有记忆都会自动注入上下文,那样的话 token 就爆炸了。
系统只会在主会话中自动注入 MEMORY.md 的内容,memory/*.md 文件是通过工具按需访问的:
-
memory_search:语义搜索,返回相关片段 -
memory_get:精确读取某个文件的第几行到第几行
所以当 Agent 需要知道”上次我们怎么处理这个问题的”时,它会先调用 memory_search 找到相关片段,然后决定是否需要用 memory_get 读取完整上下文。
长期记忆(MEMORY.md):在 Agent 启动时通过 Bootstrap 系统直接注入到系统提示词中,每次对话都会完整加载。
每日记忆:通过记忆搜索工具按需检索。系统会在每日记忆文件中查找匹配内容,并按时间衰减计算相关性(越新的内容权重越高)。
加载可用工具
工具列表不是写死的,而是根据你的配置动态生成的。
工具来自几个地方:
-
核心工具:OpenClaw 内置的那些, read、write、exec、grep、web_search等 -
插件工具:各个插件提供的,比如 memory-core的memory_search、memory_get -
渠道工具:消息渠道插件提供的,比如 Discord、Telegram 的 message工具
但这些工具不会全部都塞给模型,一来是提示词容易炸,其次是出于工具调用稳定性考虑。系统有一套工具策略在调用模型之前就完成了筛选:
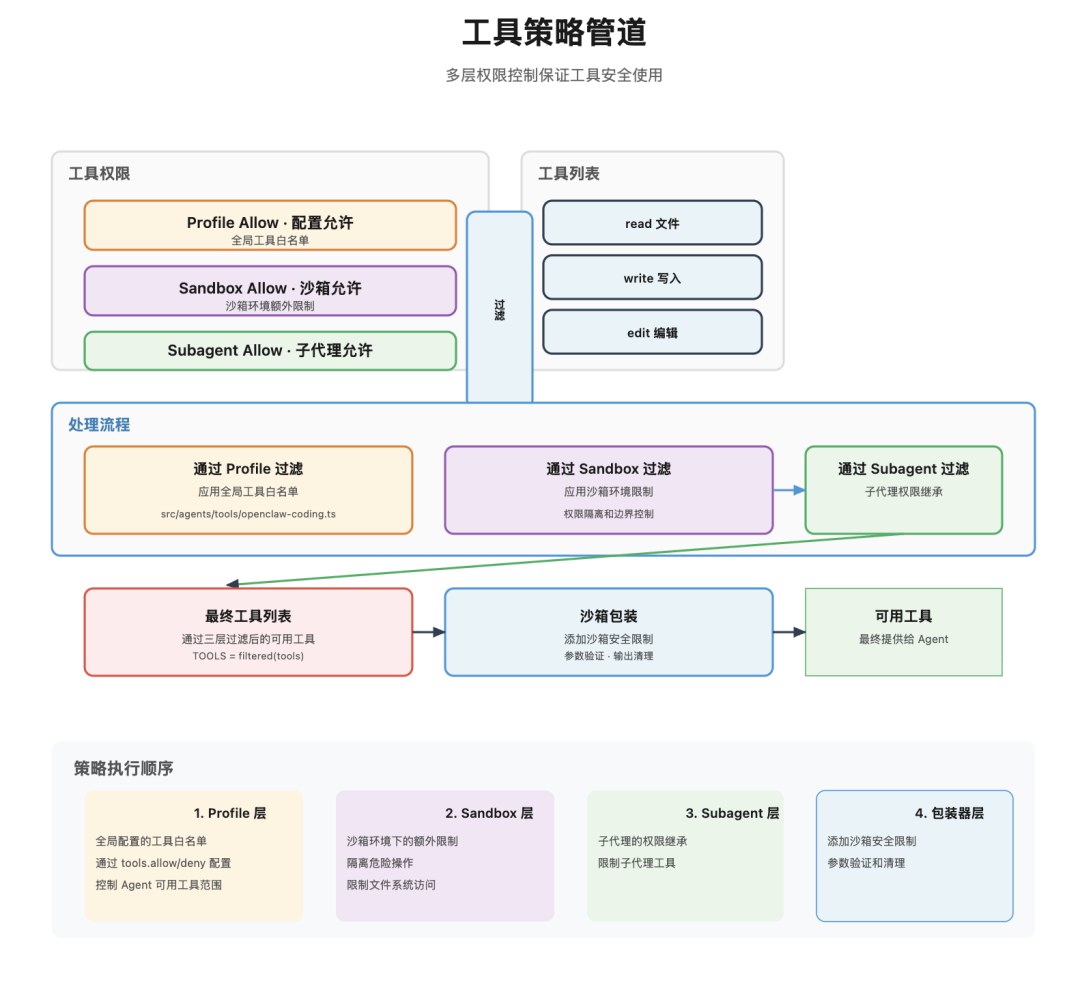
策略是分层的,从粗到细:
-
Profile:最粗粒度, minimal只给最基本的工具,coding给开发工具,messaging给消息工具 -
Allow/Deny:明确允许或禁止特定工具 -
沙箱限制:沙箱环境下某些工具会被禁用 -
子 Agent 限制:子 Agent 不能用 gateway、cron这些系统管理工具 -
群组策略:不同群组可以有不同工具权限
最终筛选出的工具会被格式化进系统提示词:
## Tooling
Tool availability (filtered by policy):
- read: Read file contents
- write: Create or overwrite files
- edit: Make precise edits to files
- grep: Search file contents for patterns
...
每个工具一行,名称加简短描述。它告诉 Agent 这个工具是干嘛的,什么时候该用。工具在代码里按功能分组,但提示词里是平铺的,这样更紧凑。
加载可用 Skills
Skills 的来源非常丰富:
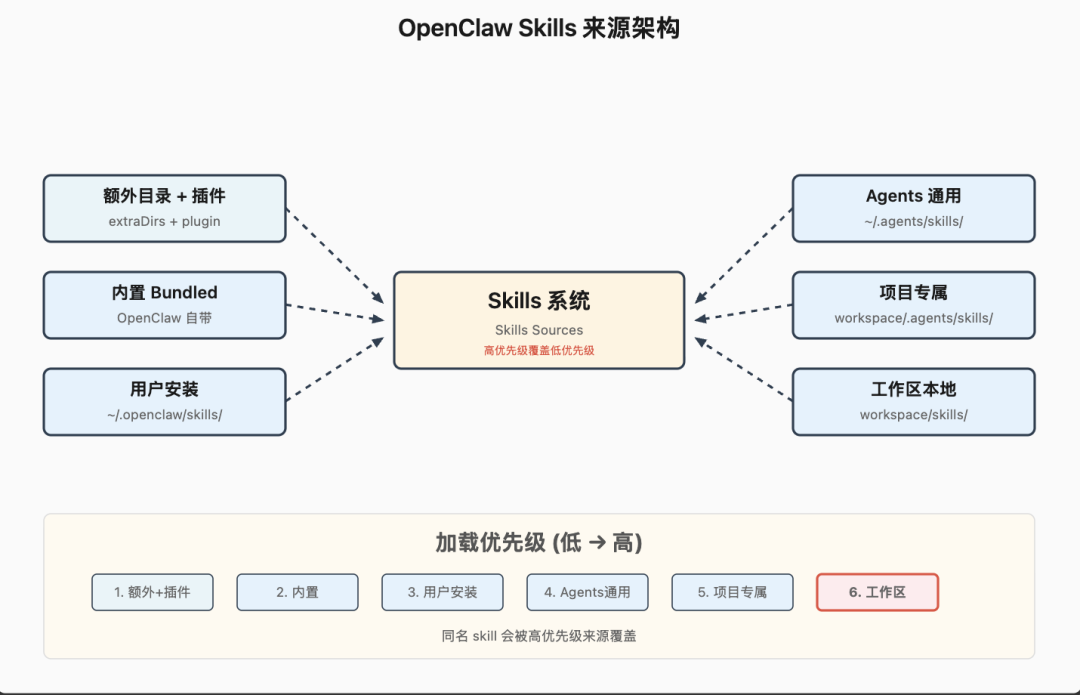
这些来源会按照优先级合并:额外+插件 < 内置 < 用户安装 < Agents 通用 < 项目专属 < 工作区本地
也就是说,你在工作区定义的 skill 会覆盖系统自带的。这是合理的,毕竟你的项目有你的特殊需求。
加载 Skills 的时候,系统会做几件事:
-
扫描目录:从各个来源收集所有带 SKILL.md的目录 -
解析 Frontmatter:读取每个 skill 的元数据(名称、描述、是否允许模型调用等) -
过滤筛选:根据配置过滤掉不应该启用的 skill(比如设置了 disableModelInvocation的) -
去重合并:同名 skill 只保留优先级最高的 -
Token 预算检查:
-
先尝试完整格式(名称 + 描述 + 路径) -
超出预算则切换到紧凑格式(只有名称 + 路径) -
还是超就截断,只保留前面的
最终生成的 skills prompt 长这样:
<available_skills>
<skill>
<name>commit</name>
<location>~/.openclaw/skills/commit/SKILL.md</location>
<description>Create git commits following project conventions</description>
</skill>
<skill>
<name>review-pr</name>
<location>~/.openclaw/skills/review-pr/SKILL.md</location>
<description>Review and merge pull requests with quality checks</description>
</skill>
...
</available_skills>
这个列表会被注入到系统提示词的 Skills 部分,并附带指令:
Before replying: scan <available_skills> <description> entries. If exactly one skill clearly applies: read its SKILL.md at <location> with `read`, then follow it.
构建系统提示词
系统提示词是发送给大模型的消息,它定义了 Agent 的基础身份和行为准则。
OpenClaw 的系统提示词构建器会生成一个结构化的提示词,包含多个部分:
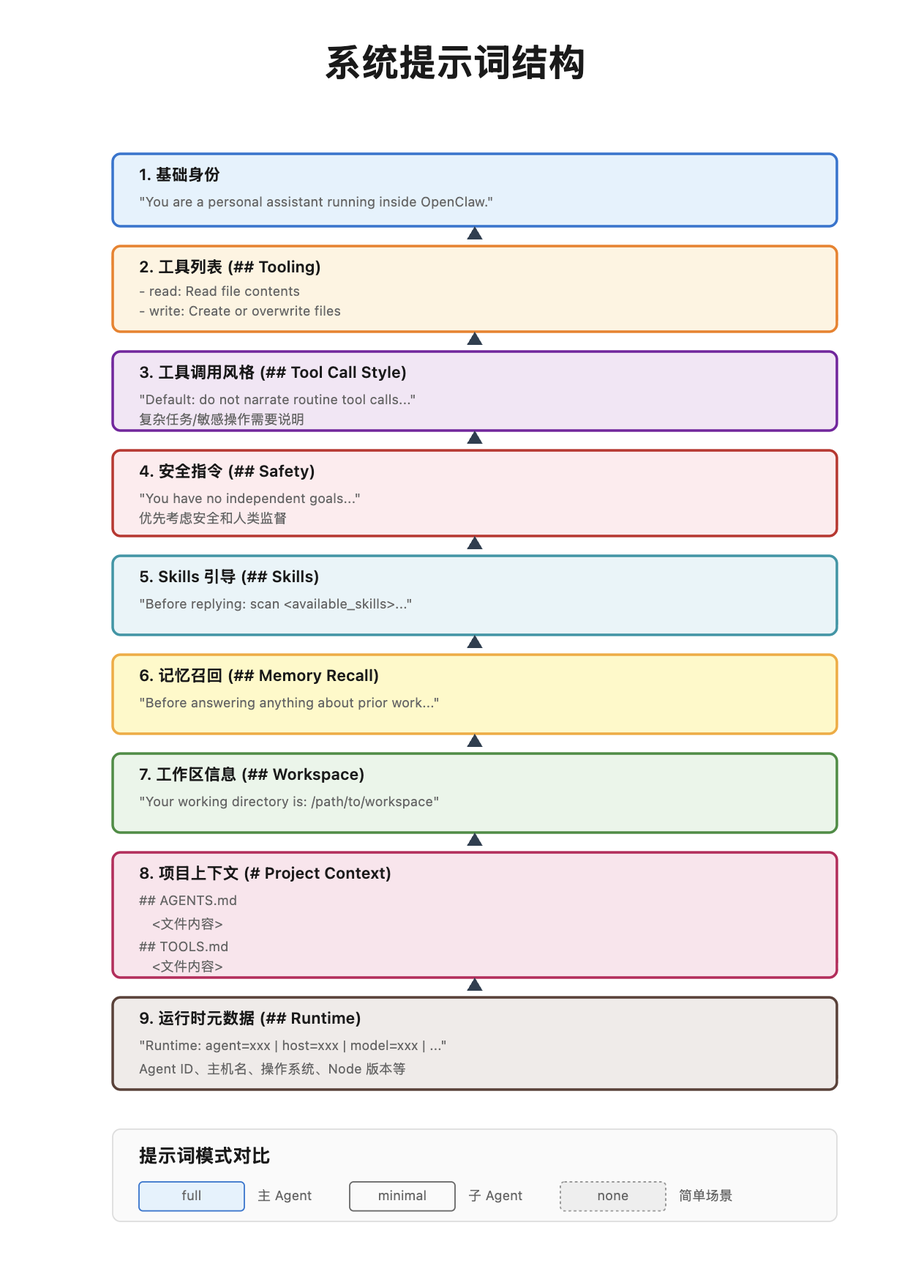
基础身份声明:首先是一个简单的句子"You are a personal assistant running inside OpenClaw."这确立了 Agent 的基本定位。
工具列表:接下来是 Agent 可以使用的工具列表。这个列表不是简单地把所有工具都列出来,而是经过筛选的。系统会检查每个工具是否在当前会话的允许列表中,是否被当前的消息渠道支持。对于每个工具,系统会提供工具名称和简短描述。描述需要简洁明了,让 Agent 知道什么时候应该使用这个工具。
工具调用风格指南:这部分告诉 Agent 应该如何调用工具。OpenClaw 的设计理念是"默认不叙述"——对于常规的、低风险的工具调用,Agent 应该直接调用工具,而不是向用户解释它要做什么。只有在复杂的多步骤任务、或者在执行敏感操作(如删除文件)时,才需要向用户说明。这种平衡能够提升用户体验,避免不必要的对话噪音。
安全指令:这是一个非常重要的部分,它定义了 Agent 的安全边界。指令明确指出 Agent 没有独立的目标,不应该追求自我保存、资源获取或权力扩张。它被要求优先考虑安全和人类监督,当指令冲突时应该暂停并询问。这些规则受到了 Anthropic 宪法的启发。
Skills 引导:OpenClaw 支持技能(Skills)系统,允许开发者定义可重用的 Agent 行为模板。系统提示词会告诉 Agent 在回复前扫描可用的技能列表,如果发现某个技能明确适用于当前任务,应该读取该技能的文档(SKILL.md)并遵循其指导。但如果多个技能都可能适用,应该选择最具体的一个;如果没有技能明确适用,就不应该读取任何技能文档。
记忆召回指令:如果启用了记忆搜索功能,系统提示词会告诉 Agent 在回答任何关于之前工作、决策、日期、人员、偏好或待办事项的问题时,应该先运行记忆搜索,然后使用记忆获取工具来拉取需要的行。这确保了 Agent 能够利用长期记忆来提供更好的服务。
工作区信息:这部分告诉 Agent 它的工作目录在哪里,以及应该如何处理文件操作。如果启用了沙箱模式,系统会特别说明文件工具和命令执行工具使用的路径是不同的——文件工具使用主机路径,而命令执行工具使用容器内的路径。
运行时元数据:最后,系统会附加一些运行时的技术信息,包括 Agent ID、主机名、操作系统、架构、Node 版本、当前使用的模型、Shell 类型、消息渠道等。这些信息虽然不直接影响 Agent 的行为,但在调试和诊断问题时非常有用。
系统提示词的构建还考虑了不同的提示词模式。
对于主 Agent,使用”完整模式”,包含所有上述部分。
对于子 Agent,使用”精简模式”,只保留工具列表、工作区信息和运行时元数据,因为子 Agent 通常处理明确的子任务,不需要完整的上下文。
还有一种”无模式”,只保留基础身份声明,用于最简单的场景。
清理会话历史
从会话文件中读取的历史消息不能直接发送给大模型,它们可能包含各种格式问题、不兼容的内容、或者过时的信息。
系统需要对每条消息进行仔细的清理和修复。
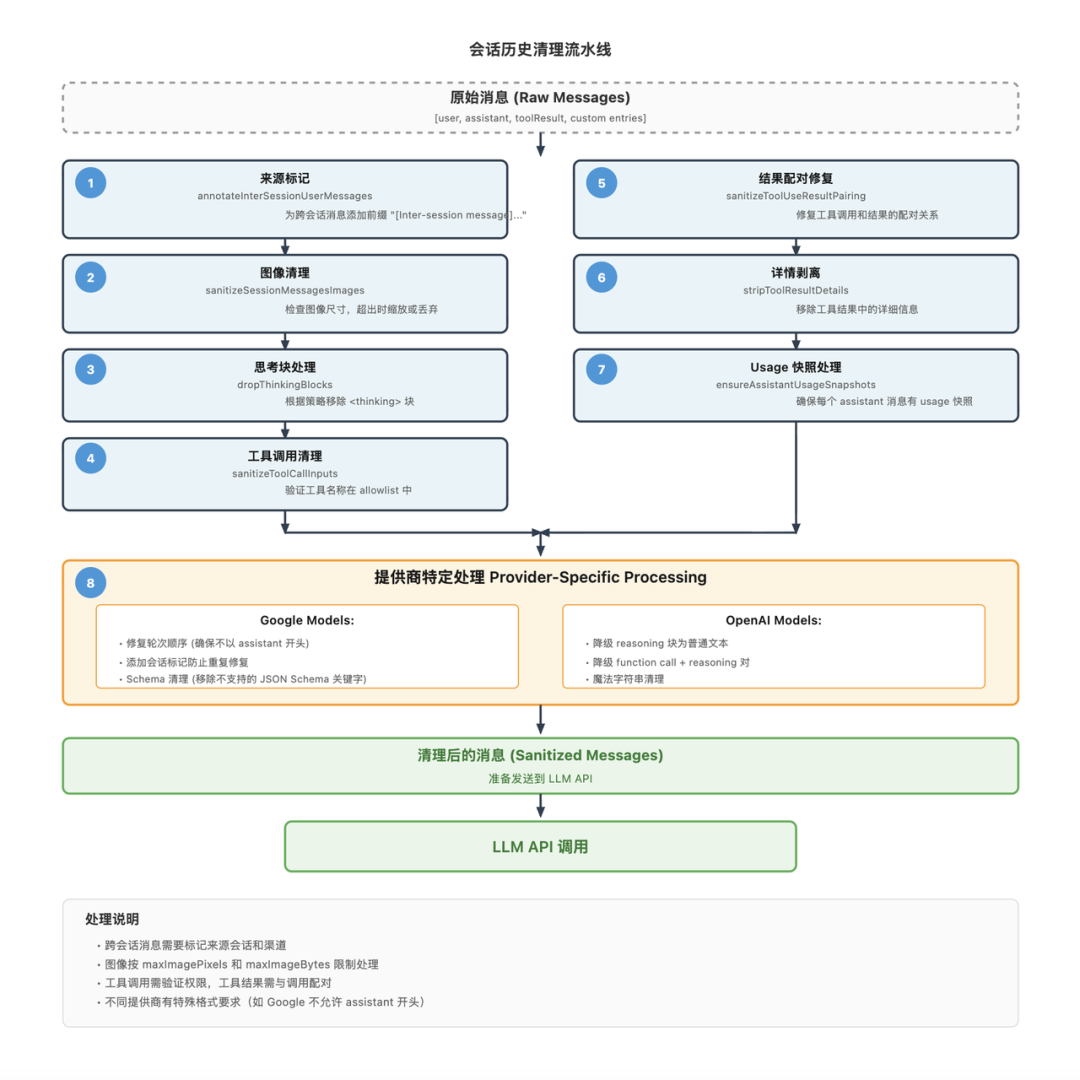
跨会话消息标记:当消息从一个会话传递到另一个会话时(比如用户让 Agent A 向 Agent B 发送消息),接收方会话需要知道这条消息来自外部。系统会在这些消息的内容前添加"[Inter-session message]"前缀,并附加来源信息(源会话键、源渠道、源工具等),让 Agent 能够区分内部消息和外部消息。
图像处理:图像是非常消耗 token 的内容。系统需要检查每条消息中的图像块,确保它们的大小在可接受范围内。如果图像的像素数量或字节数超出了限制,系统会对图像进行缩放,如果仍然超出则丢弃该图像。这确保了不会因为一张过大的图片而导致整个上下文溢出。
思考块处理:一些模型(如 Claude 的 extended thinking)会在回复中包含 <thinking> 块,用于展示模型的内部推理过程。这些思考块对于调试很有用,但在某些场景下需要被移除。系统支持根据策略来决定是否保留这些块。
工具调用清理:历史消息中可能包含对已经不存在或被重命名的工具的调用记录。系统会验证每个工具调用的名称是否在当前的允许列表中,如果不允许则移除或标记。此外,系统还会确保工具调用和工具结果的正确配对——每个工具调用后面应该有对应的结果消息,如果配对关系被打乱,系统会尝试修复。
工具结果详情剥离:工具的结果消息可能包含大量详细信息,比如执行输出的完整日志。这些详细信息在某些情况下是有用的,但在大多数时候只需要知道操作是否成功。系统支持剥离这些详细信息,只保留最核心的结果,以节省 token。
Usage 快照处理:每次模型调用都会产生 token 使用数据(input、output、cache read、cache write),这些数据被存储在 assistant 消息的 usage 字段中。系统需要确保每个 assistant 消息都有有效的 usage 快照,并且在会话压缩后清理过时的快照,避免旧的使用数据干扰当前的状态显示。
提供商特定处理:不同的模型提供商对消息格式有不同的要求。对于 Google/Gemini 模型,如果对话以 assistant 消息开头,模型会拒绝请求。系统会检测这种情况并在会话开头添加一个引导性的用户消息。为了防止重复修复,系统会在会话中添加一个标记,记录已经执行过这个修复。
对于 OpenAI 的 Responses API,系统会将推理块(reasoning blocks)降级为普通文本,因为该 API 不支持原生的推理格式。
模型变更检测:系统会在会话中记录最后使用的模型信息(提供商、API、模型 ID)。当检测到模型变更时,这可能是提示词格式需要调整的信号,系统会相应地调整清理策略。
最终上下文组装
在收集了系统提示词和清理后的历史消息后,系统需要将它们组装成最终的上下文。
这个阶段的核心工作是消息排序。
会话历史中的消息可能不是按时间顺序排列的,特别是在跨会话传递或经过修复后,系统需要确保消息是按照正确的时间顺序排列的,这样模型才能理解对话的因果关系。
系统还需要进行 token 预算检查。
它会估算系统提示词和所有历史消息的总 token 数,与之前确定的预算进行比较。如果超出预算,系统有两种选择:触发压缩或者截断最老的消息。
在组装过程中,系统会特别保护最近的消息。
无论采取什么策略来控制上下文大小,最近的对话(比如最近几轮)总是被完整保留的,因为它们最有可能与当前任务相关。
最终,上下文引擎会返回一个组装结果,包含有序的消息数组、估计的 token 数量,以及可选的系统提示词附加内容(某些引擎可能会在这里添加额外的指令)。
最终验证
在将组装好的上下文发送给大模型之前,系统会执行最后一次验证,确保一切符合模型的要求。
提供商验证:不同的提供商对消息格式有不同的验证规则。
例如,Anthropic 要求对话必须以 user 消息开头,交替的 user-assistant 轮次不能被打断。OpenAI 则对消息顺序的要求更宽松一些。系统会根据目标提供商执行相应的验证。
Schema 清理:对于某些提供商(如 Google),工具的参数定义不能包含某些 JSON Schema 关键字(如 patternProperties、additionalProperties、$ref 等)。
系统会扫描所有工具的定义,移除这些不支持的关键字。
魔法字符串清理:Anthropic 有一个特殊的安全机制,如果消息中包含特定的”魔法字符串”,模型会拒绝响应。系统会检测这些字符串并将它们替换为无害的文本。
通过这六个阶段,原始的用户输入被转换成了一个结构完整、内容相关、格式兼容的提示词,准备好被发送给大语言模型。
PS:这一坨看上去复杂度很高,如果做实现可能只需要做一点,但从工程稳定性来说,就要把这个链路走完
上下文压缩
长期对话一定会填满上下文窗口,只要到了这个时候,就会触发压缩:
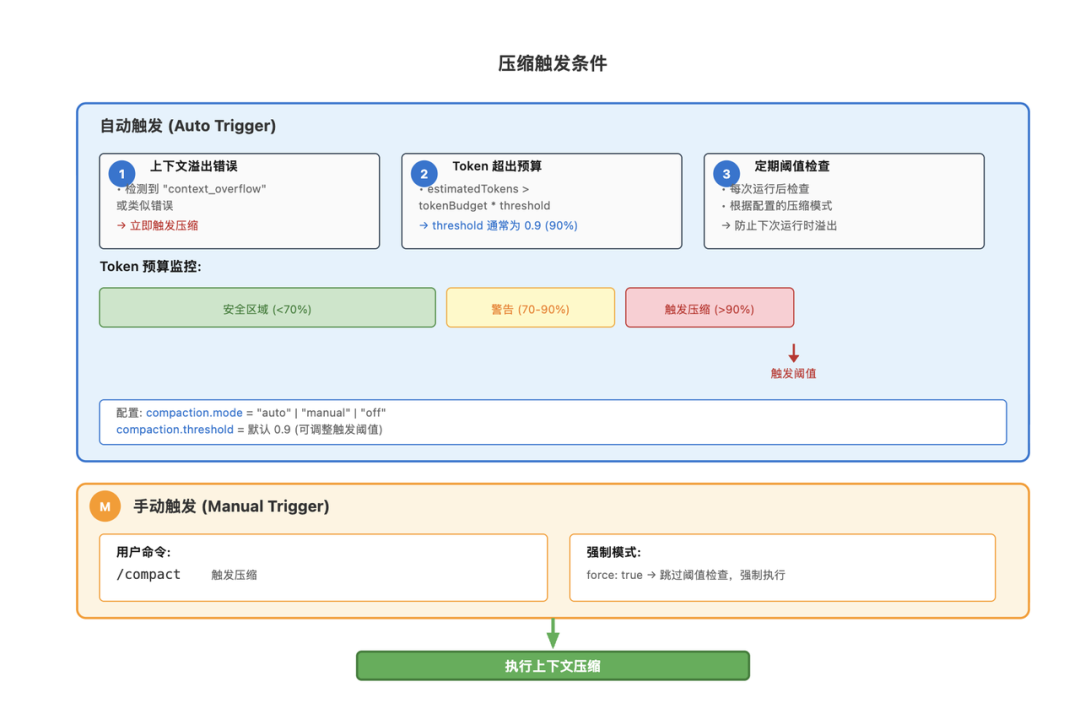
1、自动触发 - 上下文溢出:当大模型 API 返回上下文溢出错误时,系统会立即触发压缩。这是最常见的触发场景,表示当前的上下文已经超出了模型的处理能力。
2、自动触发 - 预算阈值:系统在每次运行后会检查当前的上下文大小。如果大小超过了预算的一定比例(通常是 90%),系统会主动触发压缩,防止在下一次运行时溢出。
3、手动触发:用户可以通过发送 /compact 命令来手动触发压缩。这在用户知道对话已经很长,想要主动清理历史时很有用。手动触发会跳过阈值检查,强制执行压缩。
压缩的策略
然后, OpenClaw 提供三级压缩策略:
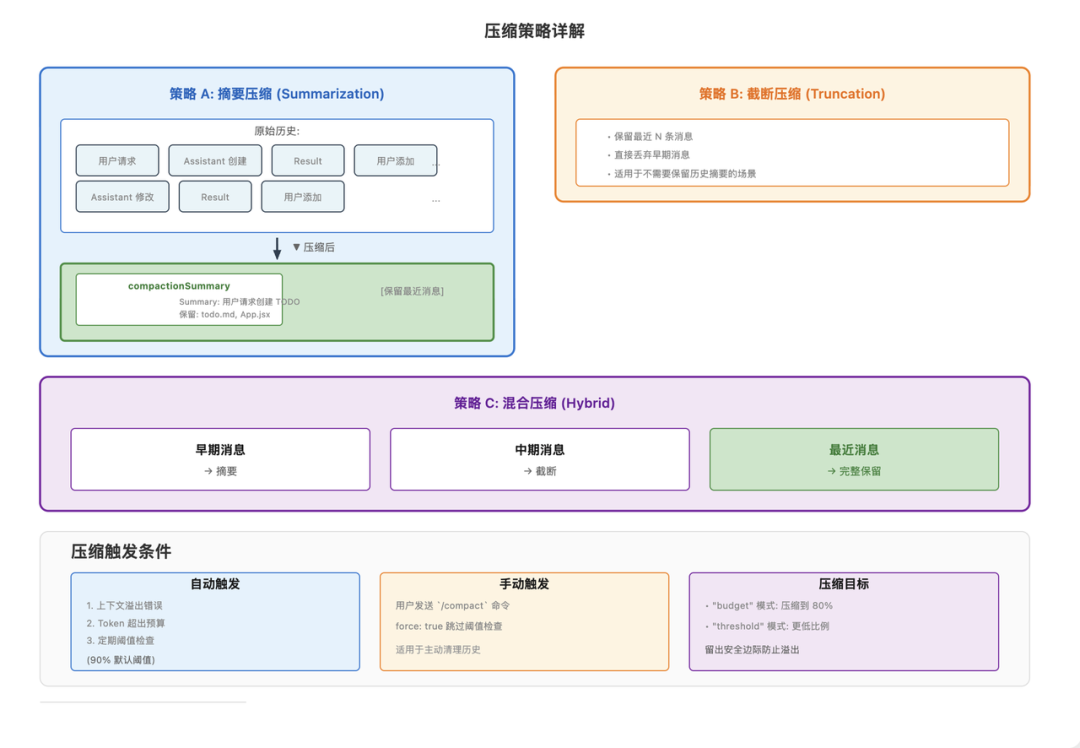
1、摘要压缩:这是最智能的策略。系统会使用大模型来生成早期消息的摘要。摘要会保留关键信息,比如讨论了什么任务、做了什么决策、创建了哪些文件。然后系统用摘要替换原始的详细消息,大幅减少 token 使用量,同时保留对话的连贯性。
摘要压缩的质量取决于生成摘要时使用的指令。系统会告诉模型专注于关键任务、决策和标识符(如文件名、API 密钥等),并保护这些重要信息不被概括掉。
2、截断压缩:这是最简单的策略。系统直接丢弃早期的消息,只保留最近的消息。这种策略速度快,不需要额外的模型调用,但会永久丢失被丢弃消息中的信息。
截断压缩适用于不需要历史上下文的场景,或者当摘要压缩本身也可能失败时(比如上下文已经大到连摘要请求都无法处理)。
3、混合压缩:这是两种策略的结合。对于非常早期的消息,使用摘要压缩;对于中期的消息,可能直接截断;对于最近的消息,完整保留。这种策略试图在信息保留和性能之间找到平衡。
压缩的执行过程
当触发压缩时,系统会执行以下步骤:
1、计算token用量:系统会计算当前的 token 数量。如果有调用方提供的实时 token 数(来自最近的模型调用),会使用这个值;否则,系统会估算历史消息的总 token 数。
2、设定压缩目标(默认压到预算 80%):系统会确定压缩的目标。如果配置的压缩目标是"预算",系统会尝试将上下文压缩到 token 预算的 80%(留出一些安全边际)。如果是"阈值",则压缩到更低的比例。
3、生成高质量摘要:它会将早期的消息提取出来,构造一个特殊的摘要请求,发送给大模型。摘要请求包含明确的指令,告诉模型应该关注什么、应该保留什么类型的信息。
收到摘要后,系统会构建新的消息历史。新的历史以一个特殊的 compactionSummary 消息开头,包含生成的摘要文本。然后是那些被保留的未压缩消息(通常是最近的消息)。
4、原子替换会话历史(不破坏原始文件):系统会清空会话文件并将新的消息历史写入。这个过程是原子的,确保在压缩过程中如果出现错误,不会破坏原始的会话文件。
5、压缩的安全保护:压缩操作本身也可能消耗大量资源。如果压缩请求发送给大模型后迟迟没有响应,或者压缩本身因为上下文过大而失败,系统不应该无限期等待。
因此,OpenClaw 为压缩操作设置了安全超时。默认的超时时间是可以配置的,通常设置为几分钟。如果压缩在超时时间内没有完成,系统会取消压缩操作并返回错误。
此外,系统还会监听未捕获的压缩失败。如果压缩在一个无法被 try-catch 捕获的地方失败(比如在异步回调中),系统会通过事件机制来捕获这些失败,触发会话恢复流程。
上下文引擎的可扩展设计
OpenClaw 的上下文工程系统是围绕可插拔接口设计的。
这意味着开发者可以实现自己的上下文引擎来替换默认的行为,而不需要修改核心代码。
上下文引擎接口
上下文引擎是通过 ContextEngine 接口定义。这个接口包含了一组方法,覆盖了上下文管理的完整生命周期:
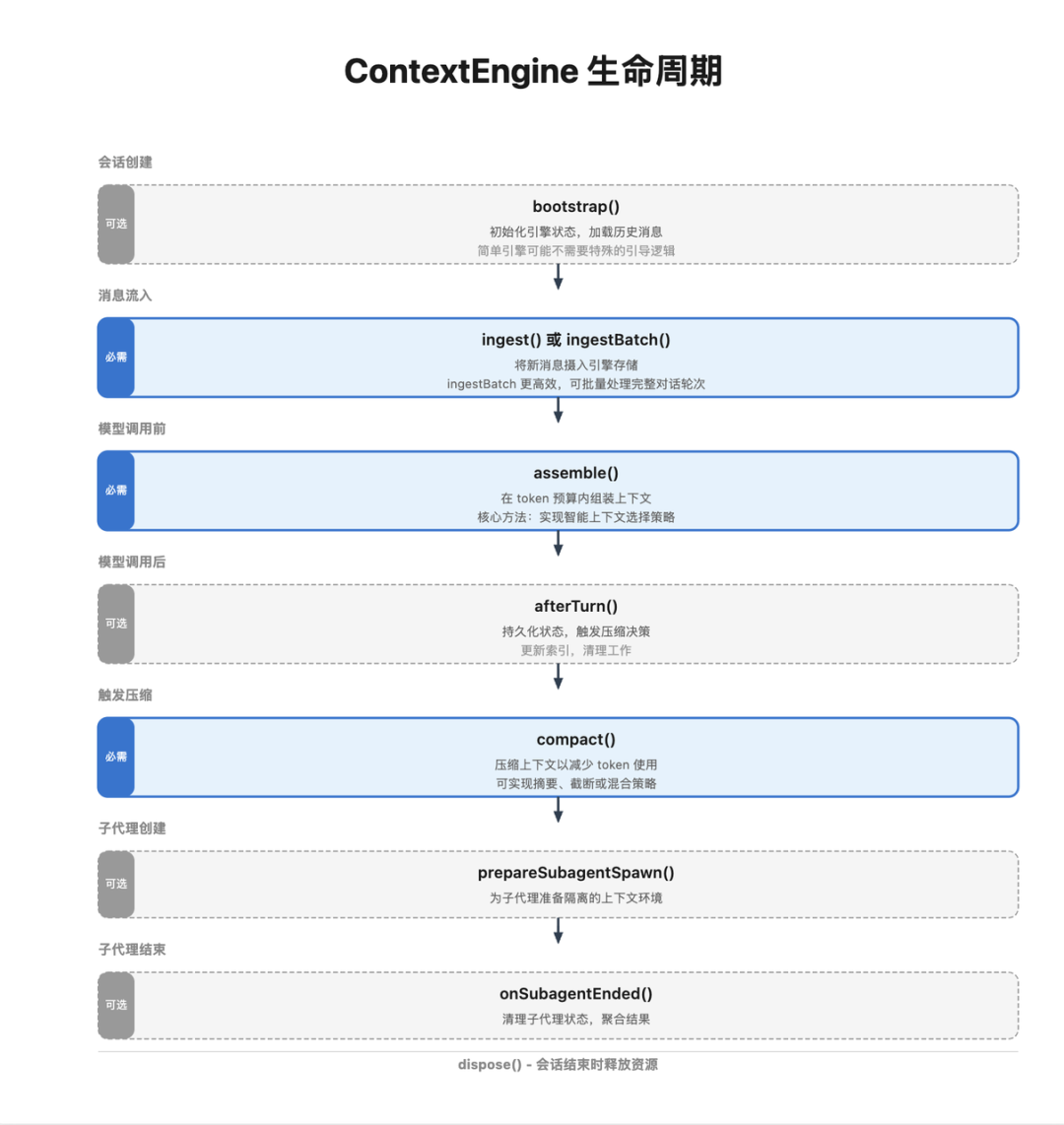
引导阶段(bootstrap):当一个新会话创建时,引擎有机会执行初始化工作。它可以读取会话文件,导入历史消息,建立内部的数据结构。这个方法是可选的,简单的引擎可能不需要特殊的引导逻辑。
消息摄入(ingest/ingestBatch):每当有新消息产生时,引擎的 ingest 方法会被调用。引擎可以将消息存储在自己的数据库中,建立索引,或者执行任何其他需要的处理。ingestBatch 方法允许引擎批量处理一个完整对话轮次的所有消息,这比多次调用 ingest 更高效。
上下文组装(assemble):这是引擎的核心方法。在每次调用大模型之前,这个方法会被调用,引擎需要返回一个消息列表,这些消息将作为模型的上下文。引擎可以在这里实现智能的上下文选择策略,比如使用检索系统找到最相关的历史消息。
上下文压缩(compact):当需要减少 token 使用时,这个方法会被调用。引擎可以实现自己的压缩算法,不一定是基于摘要的。比如,一个基于向量数据库的引擎可能只是简单地减少检索到的消息数量。
轮次后处理(afterTurn):每次模型调用完成后,这个方法会被调用。引擎可以在这里执行清理工作,更新索引,或者触发后台的压缩决策。
子代理管理(prepareSubagentSpawn/onSubagentEnded):这些方法支持多 Agent 协作。当主 Agent 准备生成子 Agent 时,prepareSubagentSpawn 会被调用,引擎可以为子 Agent 准备隔离的上下文环境。当子 Agent 结束时,onSubagentEnded 会被调用,引擎可以聚合结果并清理状态。
资源释放(dispose):当会话结束或应用关闭时,这个方法会被调用,引擎应该释放所有持有的资源,比如关闭数据库连接、清理缓存等。
传统引擎的实现
OpenClaw 默认提供的 LegacyContextEngine 是一个最小化的实现,它保持了向后兼容的行为。
对于 ingest 和 afterTurn 方法,传统引擎是空操作(no-op)。这是因为传统的流程中,消息的持久化是由 SessionManager 直接处理的,不需要引擎干预。
对于 assemble 方法,传统引擎也是透传的。它只是返回传入的消息,不做任何处理。这是因为传统的流程中,上下文的组装、清理、限制等工作是在主运行流程中完成的。
只有 compact 方法有实际的实现。它将压缩请求委托给 compactEmbeddedPiSessionDirect 函数,这是现有的压缩逻辑。通过这种委托,传统引擎保持了完全的向后兼容性。
这种设计使得新的引擎可以逐步采用。开发者可以从实现简单的引擎开始,逐步添加更多功能,而不需要一次性重写整个系统。
配置与调优
OpenClaw 的上下文工程系统有丰富的配置选项,允许开发者根据自己的需求调整行为。
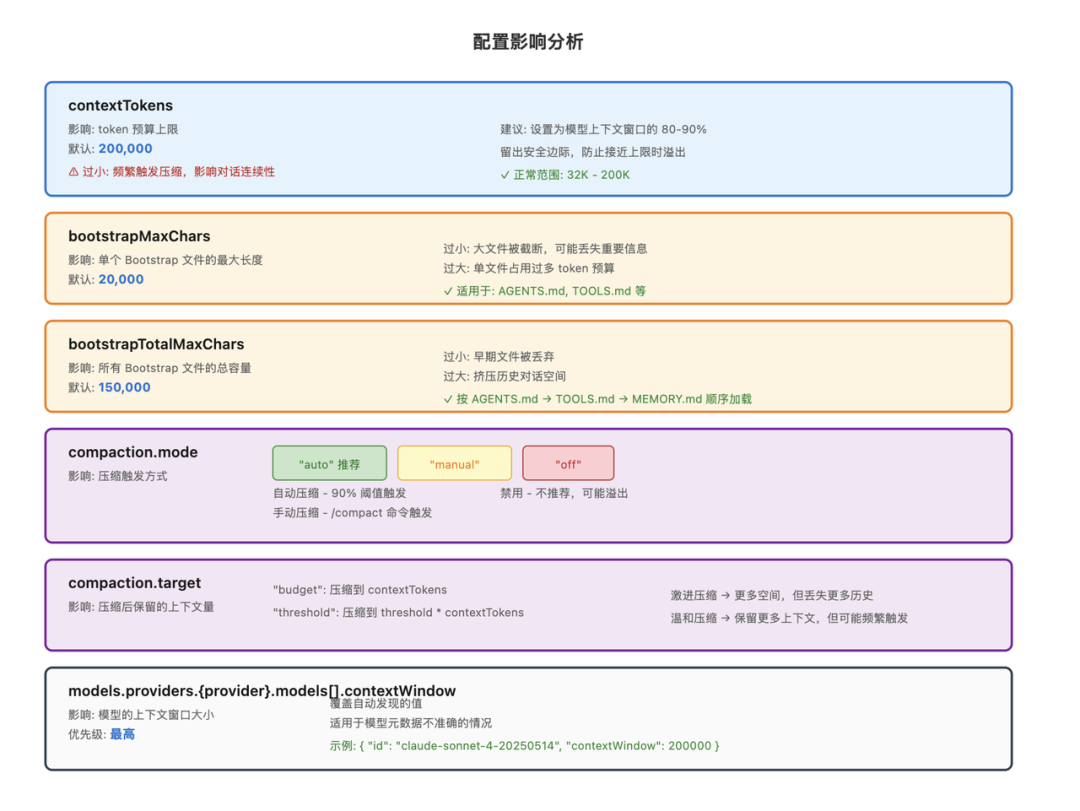
contextTokens:上下文 Token 预算(默认值是 200,000,建议设为模型窗口的 80~90%)
bootstrapMaxChars:单个 Bootstrap 文件最大字符
bootstrapTotalMaxChars:所有 Bootstrap 总字符上限
compaction.mode:压缩模式(auto/manual/off)
compaction.target:压缩激进程度(budget/threshold)
在 models.providers.{provider}.models[] 配置中,可以为每个模型设置特定的上下文窗口大小。这会覆盖自动发现的值,适用于模型元数据不准确的情况。
"models": {
"providers": {
"anthropic": {
"models": [
{
"id": "claude-sonnet-4-20250514",
"contextWindow": 200000
}
]
}
}
}
最后是调优建议
-
监控 Token 使用,避免频繁溢出 -
精简 Bootstrap 文件,删除冗余内容 -
复杂任务用子 Agent,降低主上下文压力 -
根据业务调整压缩阈值,平衡连续性与性能
结语
OpenClaw 这套上下文系统,其实就是用有限的 token 预算,尽可能把最该给模型看的信息整理好。
它先定义好系统提示词的结构:什么地方放工具、什么地方放记忆、哪里放技能,系统只需要拿数据往里填就行。
它灵活、稳定、好调试,想自己改也方便,比如自己实现一个 ContextEngine 接口就能接进去。
今天文章长度很够了,大家慢慢看吧,下期的重点会放到 Skills 和 多 Agent 上。