
书接上文:OpenClaw vs Hermes:拆解 Hermes Agent 五层架构
上一篇写 Hermes-Agent,我们选了一条比较笨但好用的路:跟一条消息走一遍。
从终端里敲下一句话,到 Agent 把最后一个字回到屏幕上,中间其实绕了很长一圈:
-
消息先被入口收进去,变成内部统一的消息; -
会话和上下文被重新组织; -
模型开始一轮轮判断,必要时调用工具;
过程太长时,系统还要整理上下文、保住历史,并在任务结束后尝试沉淀经验。
这条线走完以后,Hermes-Agent 的骨架基本就出来了。
只不过,这种方式更像是在做源码游读,主打个走马观花,看到什么就说什么、看到一个模块,就解释它在这条消息路径里负责什么、看到一个工程细节,就顺手拆一下为什么这么做。
但问题也出在这,走流程容易可以熟悉框架,但对于很多设计其实是懵逼的,比如:
-
Profile 为什么要靠 HERMES_HOME 隔离 -
系统提示词为什么越稳定越靠前 -
记忆为什么会在会话开始时冻结成快照 -
上下文压缩后为什么不覆盖旧会话,而是开一个新会话接上父子链 -
……

这些细节,如果不从全局出发,只是走马观花,是很难得到完美的答案的。
这些东西单独拆开看都不算大,甚至有些只是很小的工程取舍,可这些东西放在一起,就会指向同一个问题:
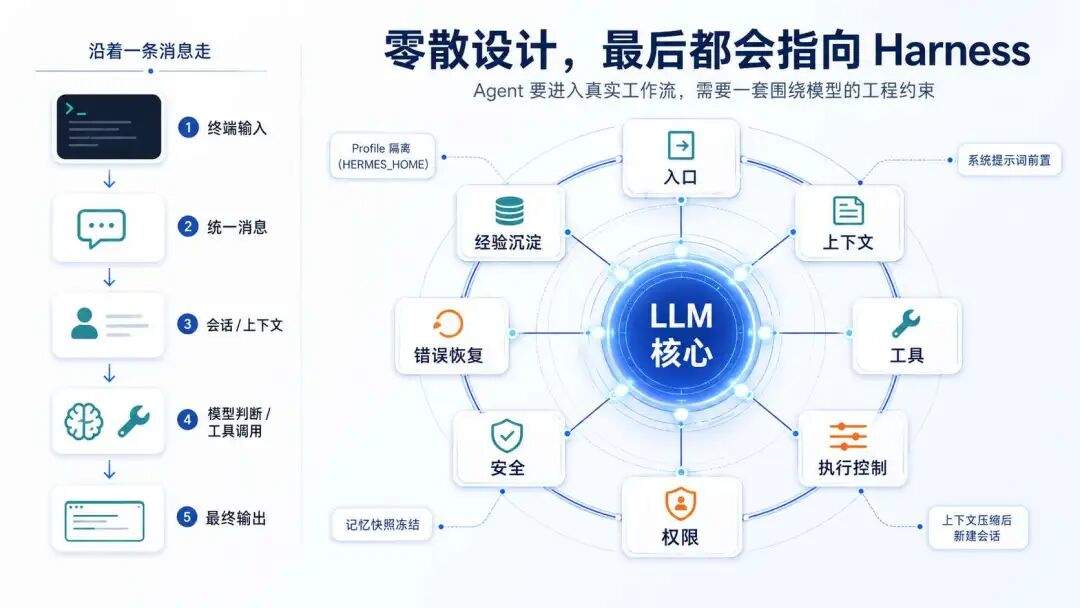
Agent 要进入真实工作流,需要一套围绕模型的工程约束
上一篇跟着一条消息走,看到的是模块怎么跑。这篇换个角度:这些模块放在一起,到底构成了什么?
为什么这些看起来零散的设计,最后会指向同一层系统,也就是 Harness;
再往前看一步,未来的软件是不是也要开始为 Agent 设计/整改。
Harness 是什么
在软件工程里,test harness 是一个成熟概念:围绕被测代码搭的那层基础设施,负责提供输入、捕获输出、管理执行环境,让测试可重复、可自动化地跑。
被测代码本身不用改,harness 在外面把它包住,替它处理所有外部依赖和环境问题。
而大模型的本质是就是一段文字输入,经过推理后输出一段文字。
但它自己不会调工具,也不会替你管理上下文、处理错误、记住上次做了什么。这些能力需要外面有一层系统来提供。
这层东西,现在我们叫它 Harness(貌似最近又出了个什么环境工程,我是真没法跟了…)。
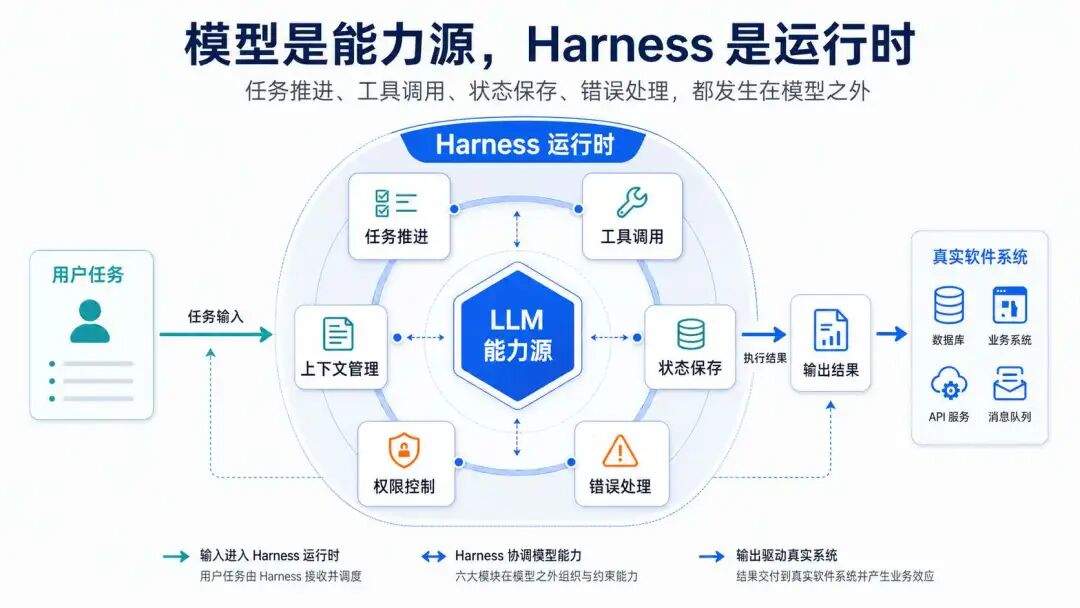
我更愿意把 Harness 理解成 Agent 的运行时。模型负责提供能力,但任务怎么推进、工具怎么用、状态怎么保存,都要靠这层系统处理。
模型是能力源,Harness 决定这股能力能不能走出 demo。
现在做 Agent 项目,一开始都一个样:接一个模型,写一段系统提示词,加几个工具函数,再做一个聊天入口。
这个阶段很容易出效果,特别是 demo 级别的演示作品,任务简单,工具少,只要模型不是 7B 这种小模型,效果都会很不错。
但是用户的意图是无限的,不会只问一个孤立问题,今天让你查资料,让你接着昨天的结论改方案,改天又补一条新的限制。
Agent 做一半发现缺文件权限,需要确认,跑测试发现环境不对,工具返回的错误无法理解。
再加上上下文越来越长,工具页变多了,原来那个模型加函数的结构很快就撑不住了…
这时候,难点已经从会不会调用工具,转成了能不能在一套可控系统里做事。这些问题如果不在系统里处理,就会被丢给 prompt。
但 prompt 扛不了这么多东西,你也可以在 prompt 里写一些要求:
请谨慎操作,确保安全
请先检查
请保存经验
请不要越权
......
开始的时候也许有用,任务越长,这些说明文档很快就会被模型忘掉。这些判断不能都靠模型来猜,得在模型外面有一层系统把这些东西管起来。
这些东西一开始像是零散的工程补丁,放在一起看,其实就是 Harness 的最初的形状。
下面我们沿着 Hermes-Agent 里几个最典型的设计往下看,每个点都不大,但合起来,会看到一个 Agent 从聊天壳往运行时系统长出来的过程。
LLM 与系统
上一篇从一条消息开始,用户输入一句话,看起来只是让 LLM 帮忙做事,但系统内部其实已经发生了很多转换。
入口层先把不同来源的消息统一起来。
命令行、Telegram、Slack、飞书、Email,这些入口的交互方式完全不一样,但进入核心之后,都会被收敛成一套内部消息对象。
出去的时候也一样,模型不需要知道飞书怎么传附件、Discord 怎么带文件,它只要吐出统一的媒体协议,网关再转回各平台自己的格式。
这一步,是把平台差异挡在 Agent 核心之外。
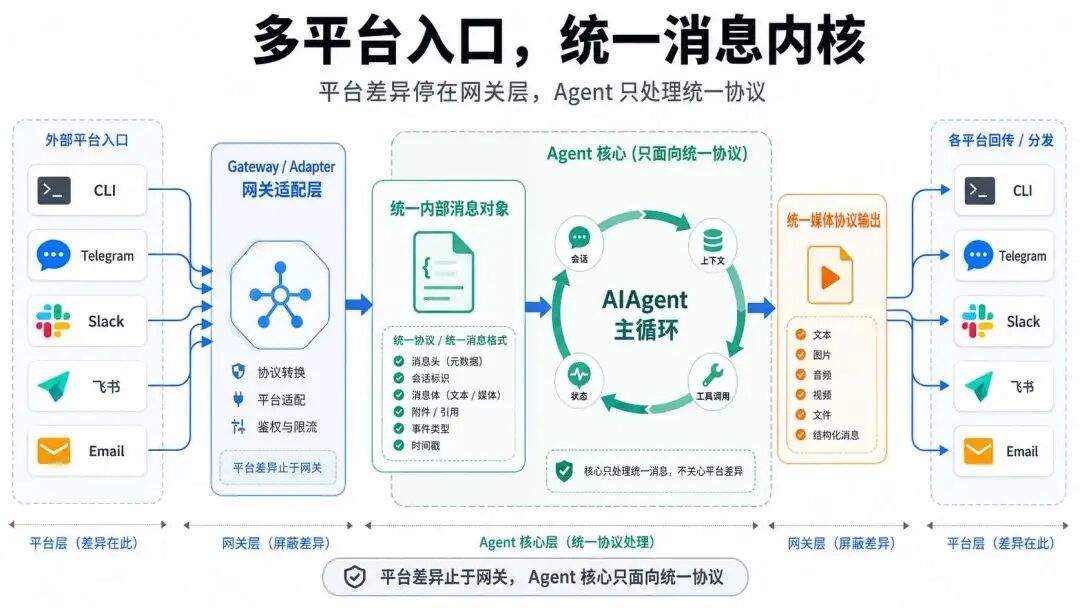
再往下走,是 AI Agent 的主循环:它先决定要调用什么工具,系统去执行,然后把结果拿回来给它,它再根据结果判断下一步。就这样反复,直到给出最终回答,或者预算花光,又或者用户主动打断。
但 Agent 做事也不是一帆风顺,中间会报错,也需要模型根据工具的执行结果不断思考和重试。
一个真正能工作的 Agent,必须允许这种来回调整,否则它就只能做短任务,任务一复杂,要么做不下去,要么直接返回一个看起来很像答案的假结果。
上一篇我们是把这些都拆开讲了的,现在回头看,它们其实都在回答同一个问题:
一个 Agent 要怎么进入真实系统,并且长期跑下去?
真正难的不是让模型回答一句话,而是在入口很多、工具很多、上下文越来越长的环境里,还能守住权限边界,失败以后也能把事情继续往前推。
Harness 这个概念就不是为了显得高级才冒出来的,它是被模型能力不足 给逼出来的,是解决一个个 BUG 逐渐诞生的集合。
上下文管理
上下文管理是 Harness 里最核心的模块。
系统的上下文处理尤其麻烦。模型能不能好好做决策,很大程度上就看这一层。用户说过的话、项目里的规则、工具返回的结果、记忆里的偏好,都可能影响下一步判断。
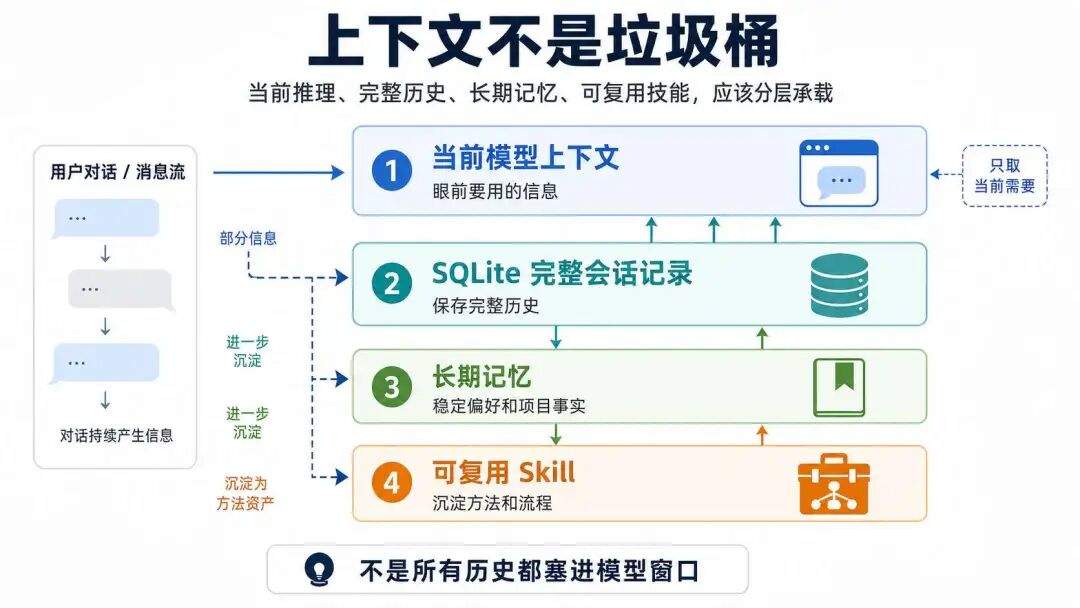
但模型窗口再大,也不是垃圾桶。Hermes-Agent 里那些压缩、缓存、摘要、冻结快照的设计,指向的都是同一个问题:当前推理到底该带什么,什么只要存在数据库里,什么值得进入长期记忆。
一个短任务 Agent,可以不太在意历史。用户问一句,模型答一句,工具跑一跑,完事;
一个长期运行的 Agent 就不一样。连续对话会积累,项目上下文会变,工具结果会越堆越多,用户还会在半路提出新的需求。
这里最怕两件事:一是把所有东西都塞进上下文。短期看信息很全,长期看又贵又慢,而且旧信息会污染新判断、二是把历史直接丢掉。这样成本是省了,但用户回头追问时,Agent 会失忆。
Hermes-Agent 的处理方式是分层。当前推理只保留必要上下文,完整历史进 SQLite,稳定偏好和项目事实进入记忆,真正能复用的流程再沉成 skill。
不同类型的数据,不该用同一个地方承载:
模型上下文适合放眼前要用的信息
数据库适合放完整记录
记忆适合放稳定偏好和项目事实
技能适合放可复用的方法和流程
把它们混在一起,就会很乱。
我第一次读到上下文压缩后新开 session、旧 session 作为 parent 保留下来的设计时,停了一下。我没想到还可以这样处理上下文,也算是给了我一个新的尝试方向。
记忆不是把所有聊天记录都塞回系统提示词,那样容易失控。Hermes-Agent 把会话中的记忆写入磁盘,但当前会话里的系统提示词快照不变,下次新会话再加载,这个没什么好说,一切都是为了成本。
这是用一致性换性能的工程权衡。说实话,我不确定这个取舍在所有场景下都对。如果用户的偏好在会话中间发生了明确变化,Agent 可能要到下一次会话才能反应过来…
上下文解决的是当前任务怎么做,记忆解决的是下一次能不能少走弯路。
工具编排
很多人聊工具调用,说得挺轻巧,好像就是给模型挂几个函数。但真的遇到工具乱调用、不调用又手足无措了…
人用软件的时候,界面会给你很多暗示:按钮放哪儿、什么颜色代表警告、报错以后弹了什么提示,人会自己补上下文。但 Agent 不会。它只能看到工具名、参数说明、返回结果,如果这些写得不清不楚,它就只能靠猜。
所以给 Agent 写的工具,跟普通 API 不是一回事。
API 以前主要是给人用的。
人看不懂还能翻文档,参数传错了可以看报错,跑不通就打断点,一边试一边改。哪怕接口设计得别扭一点,人也能靠经验兜住。
但工具一旦交给 Agent 用,情况就不太一样了。
Agent 不会像工程师那样慢慢摸索,它需要在一次推理里做出判断:
这个工具到底适不适合当前任务
该传什么参数
参数错了会不会造成严重后果
调用失败之后,是重试、换工具,还是直接告诉用户做不了
......
这些东西如果不写清楚,Agent 很容易乱用工具,不是不会调用,而是看起来会用,实际用得一塌糊涂。
所以给 Agent 设计工具,不能只写一份给人看的 API 文档。更像是在给它写一份操作说明:
什么时候用
什么时候别用
参数有什么约束
失败后怎么处理
......
写得越清楚,Agent 做判断时越不容易跑偏,同时API返回的错误信息也会变得特别重要。
如果一个工具只返回失败,人可以去翻日志,Agent 很可能就卡住了,更糟的是它还会自己瞎编一个解释接着跑。
好的错误信息应该能让它看出来下一步怎么办:比如权限不够、路径不存在、网络临时断了,还是本来就不该做这个动作。
工具一多,问题就会更加明显。
一开始只有两个工具,模型大概还能猜。工具多了以后,你得按场景分工具集,参数别太啰嗦,危险操作要确认,别让两个工具干冲突的事。
Hermes-Agent 里那些工具注册、并行执行、路径检查,说到底就是为了让 Agent 能搞清楚自己到底能干什么、不能干什么。
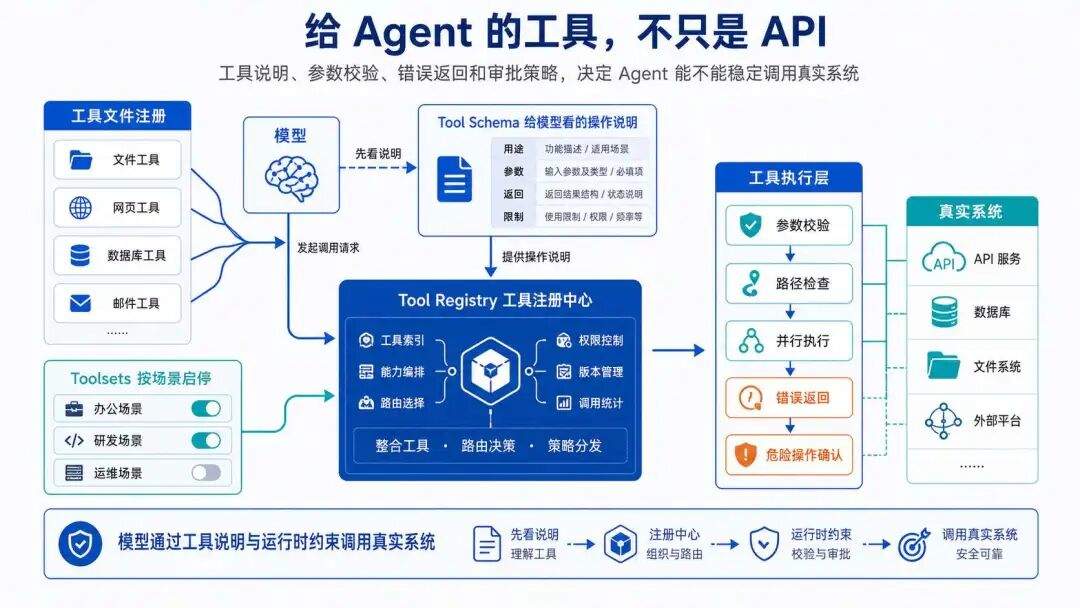
执行控制:预算和中断
Agent 跑起来以后,最怕两件事:一是无限循环烧 token,二是用户按了 Ctrl+C 后台还在跑。
迭代预算解决第一个问题。主循环有一个硬性预算:父 Agent 上限 90 轮,子 Agent 50 轮。模型每推理一轮消耗 1 次,不管这轮并行调了几个工具。
预算耗尽就退出,这是硬上限,防止模型在错误循环或幻觉里把 token 烧光。
级联中断解决第二个问题。父 Agent 每 30 秒给子 Agent 发一次心跳。一旦父被用户中断或者自己挂了,心跳断开,子 Agent 就会连锁停下。没有这个机制,用户按了 Ctrl+C 之后,后台还会有一堆子 Agent 继续烧 token。
用户中断的处理也值得说一句。中断发生时不是 raise 抛异常,而是 break 出循环,先持久化已有结果,再返回 interrupted=True。
如果前面有工具调用已经追加到消息列表但还没执行,系统会补一个伪造的错误 tool result,保证消息结构对 API 合法。
这个伪造的错误 tool result 非常实用。做过 Agent 的人都知道这个梗:用户中断后工具执行也被中断,没有记录结果,下一轮调用的消息结构就不完整,API 直接报错。伪造一个结果回去,下次恢复对话就不会被 Provider 拒。
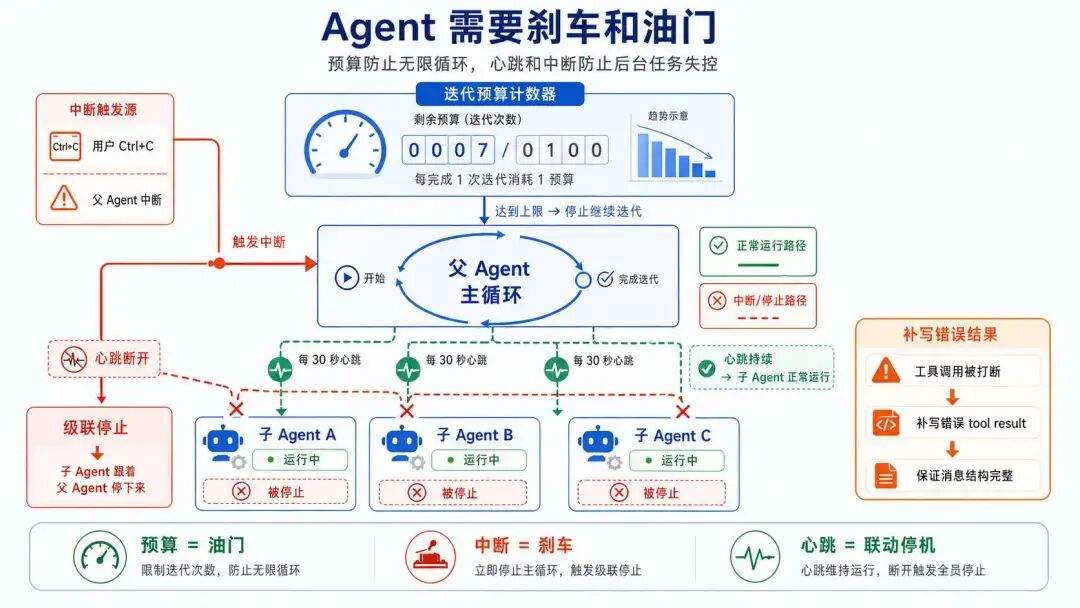
工具让 Agent 碰到了真实系统,执行控制给了它刹车和油门,但跑了以后一定会出错,出错以后怎么办?
错误恢复
主循环每一步都可能出问题:上下文不够用、API 超时、凭证限流、服务器 500。各种错误长得都不一样,HTTP 状态码不同,报错信息不同,模块来源也不同。
Hermes 的做法是按错误分类,各走各的恢复路径,而不是一个大 try/except。
API 调用会失败的原因各种各样:认证失败、额度耗尽、限流、上下文超限、模型不存在、网络中断。
FailoverReason 枚举把这些归了 14 种。每个错误抛出时先过一道分类器,再封装成 ClassifiedError,只带四个布尔恢复标记:
retryable: bool # 能不能直接重试
should_compress: bool # 要不要先压缩上下文再重试
should_rotate_credential: bool # 要不要切换到下一个 API Key
should_fallback: bool # 要不要切到 fallback 模型
主循环拿到 ClassifiedError 之后不自己做字符串匹配,只看这四个标记决定下一步。
像 rate_limit、insufficient_funds,或者 openai 模块抛出的 BadRequestError 这种脏活儿,全都集中在分类器里。分类器先把错误映射到恢复动作,主循环只负责 dispatch。
为什么要分得这么细?一个典型的对比是 HTTP 402 和 429。它们表面都是限额类错误,但处理方式完全不同:
-
429 是临时限流:Provider 告诉你请求太快,需要歇一下再来,退避重试同一个 Key 就能恢复 -
402 是额度耗尽:账户上的钱已经扣光了,同一个 Key 短期内不会恢复,必须立即切到下一个 Key
不分清楚的话,Agent 会在一个已经没钱的 Key 上反复退避到天荒地老。分类器把这两种错误映射到不同的恢复标记组合,主循环看标记就知道该退避还是该换钥匙。
对做过后端的人来说,这应该不陌生。和微服务里的重试、熔断、降级是同一类问题。只是放在 Agent 场景下,错误来源更杂。
模型 API、工具执行、文件系统和网络都可能抛出不一样的失败,分类器的作用就是在这个大杂烩里理出头绪。
错误恢复解决的是出了事怎么继续走。但 Agent 还有一类问题比出错更麻烦:它做了不该做的事怎么办?
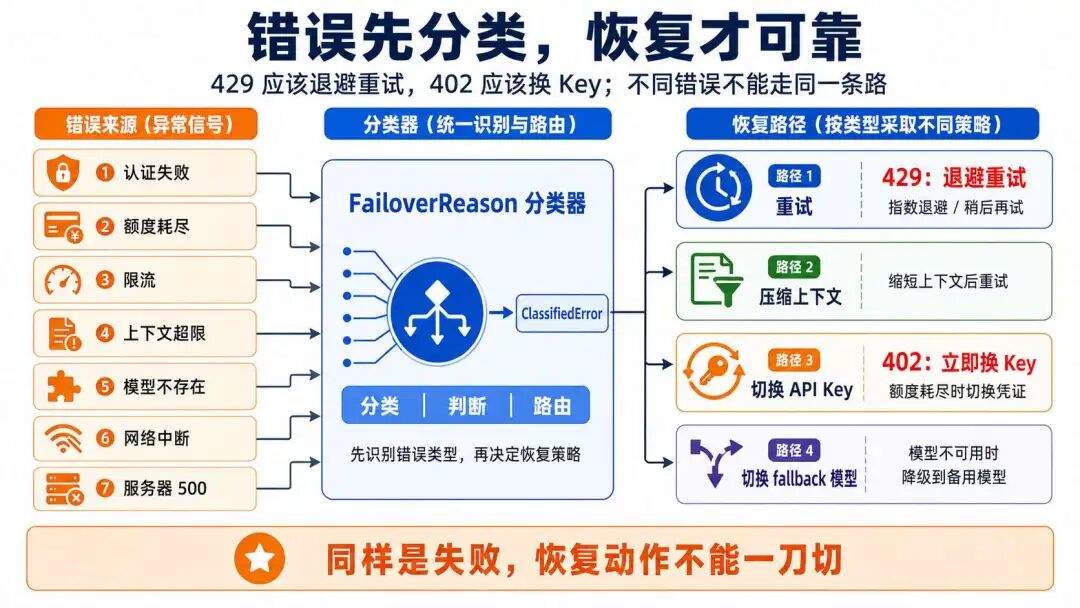
权限与安全
一提权限,其实挺烦的。我们在使用 Claude Code 的时候,经常会遇到一个弹窗:是否允许它执行某个操作。
从体验上说,这东西很打断,每多一次确认,自动化就少一点顺滑感。尤其是做演示的时候,一个 Agent 从头跑到尾,中间完全不问人,看起来当然最厉害。
但问题在于,Agent 不是只在聊天框里生成文字。它开始影响真实环境了:改文件、跑命令、调外部 API、发消息,甚至触发一整套业务流程。
虽然我们也不想要权限,但它确实是真实运行时的一部分,并且还是非常重要的一步。
回想当年做信息化转型的时候,财务的数据无论如何都进不去,财务部门的人咬死不松口,就是这个道理
写文件这件事本身不一定危险。写到 /tmp 目录,很多时候可以直接放行;但如果要改 .env、配置文件、启动脚本,那就不是一回事了。
跑命令也是一样。ls、cat、git status 这类读状态的命令,通常没必要每次都拦;但一旦涉及删除、覆盖、部署、提交变更,就必须让人确认。
外部 API 更明显。查一条订单信息,和取消一笔订单,虽然都叫调用接口,风险完全不是一个级别。
所以权限控制最好绑定到具体动作和上下文,而不是只绑定到某个工具名。
Agent 真正跑起来以后,最麻烦的不是会不会调用工具,而是它可以自己做什么,什么必须停下来问人。
读一个文件,可以直接放行
删一个目录,就不能这么随便
发一封邮件、下一个订单、改一段共享记忆,这些动作更不能全交给模型自己判断
......
边界说不清,Agent 看起来是在自主执行,实际上就是靠默认策略硬跑。跑对了叫智能,跑错了就是事故。
Hermes-Agent 这块当然还谈不上终局方案,但它至少已经把边界放进了运行时,而不是只停留在提示词里。比如:
工具集可以启停,危险命令要审批
子 Agent 不能无限套娃式地继续委托,也不能直接写共享记忆、不能随便对外发消息
父 Agent 一旦被中断,下面的子 Agent 也要跟着停
工具调用被打断了,系统也要补一个结果回去,避免下一轮消息结构直接乱掉
......
这些设计看起来很细,其实解决的是同一个问题:Agent 可以有自主性,但不能乱跑乱撞。
权限解决的是 Agent 能不能做、做到哪里。可任务做完以后,还有另一个运行时问题:这次执行带来的经验,能不能留给下一次。
经验沉淀
Agent 做完一次任务以后,到底留下了什么?聊天记录,工具调用日志,模型请求日志……
如果答案只是聊天记录,那这套系统其实没有变聪明,下次遇到类似问题,它还得重新摸索,最多是用户自己去翻历史,把上次的经验再喂给它。
我们和 AI 交互时经常这么做:把有用的提示词、排查步骤、项目习惯记到自己的小本本里,下次再复制进去。
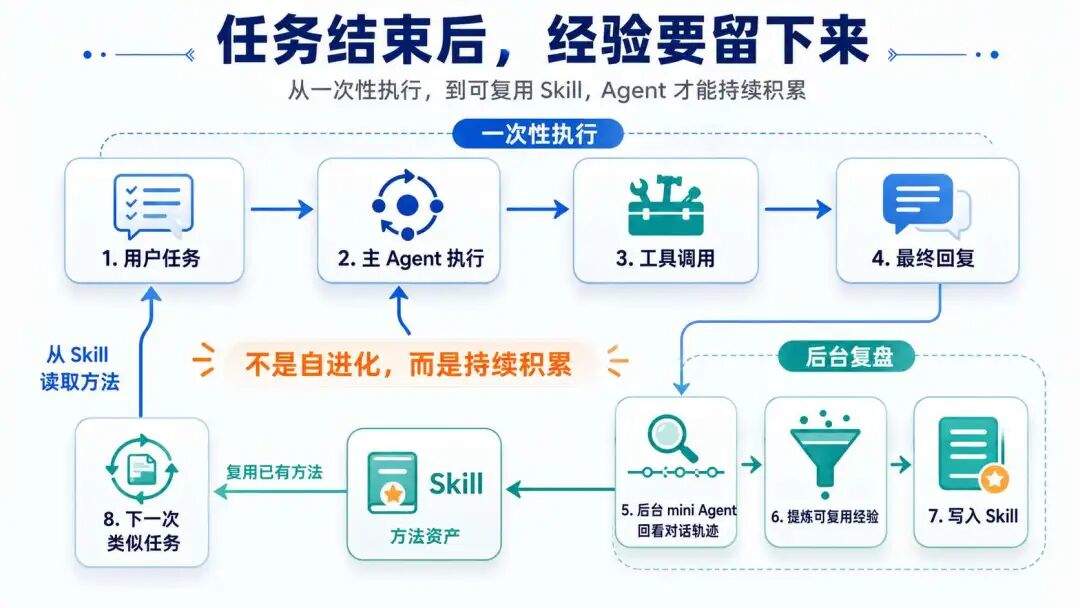
Hermes-Agent 有一个很有意思的主张:经验保存到技能,越用越聪明。
技能不是神奇能力,说简单点,就是一份可复用的操作笔记。
某个项目怎么跑测试,某类问题以前怎么排查,某个工具有什么坑,这些东西如果只散落在对话里,Agent 下次未必找得到。沉成 skill 以后,它就从一次性的过程,变成了系统可以再次调用的经验。
核心动作就是,任务结束后,另起一个安静的 mini Agent 回看这段对话,判断有没有值得保存的方法。这个动作放在用户收到回复之后,不抢主任务的注意力,也不增加用户等待时间。
这一点其实很像团队里的经验沉淀。
一个团队不会因为项目做完了就自然变强。真正让团队变强的,通常是项目之后留下来的东西:复盘结论、更新过的文档、补齐的工具、调整后的流程。没有这些沉淀,忙完一轮,下一次还是从头摸索。
Agent 也一样。
一次任务跑完,过程再精彩,如果执行轨迹没有留下来,下次遇到类似问题,它还是要重新试一遍。这个时候,所谓自主执行其实更像一次性劳动。
Hermes 用 Skills 机制完成了这一切,但我不太愿意把这叫自进化,这个词太大,也太容易把事情讲玄。
更准确地说,它是在做持续积累:Agent 不只是把眼前这件事做完,还要尽量把有用的经验带到下一轮。
到这里,Harness 的边界就从 Agent 自身往外扩了一步。Agent 想沉淀经验,前提是它能读懂自己操作过的系统;而软件想被 Agent 稳定使用,也得开始把动作、状态和失败原因讲清楚。
软件要适应 Agent
如果 Harness 继续成熟,软件本身也会被反向改造。
过去做软件,默认使用者是人。界面上的按钮、菜单和流程,都是围绕人的理解方式组织的。人能看懂上下文,也能靠经验判断什么时候该点、出了错该怎么查、什么操作会影响线上数据。
这个前提不会消失。人仍然要看界面、做判断、承担责任,UI 也仍然重要。
但 Agent 进入工作流以后,软件会多出另一种使用者。
Agent 可以看页面、点按钮,甚至模拟浏览器操作,但这不是最稳定的方式。页面里有太多默认语境:一个提交按钮,人知道它大概意味着什么;一句操作失败,人会去查日志、问同事、回想业务规则。
Agent 没有这些经验,只能猜。所以未来的软件能力,不能全藏在 UI 里,也不能只停留在传统 API 层。
很多系统早就有 API,但那些 API 主要是给工程师集成用的。字段名可能只有内部人懂,错误信息可能只是方便查日志,权限规则也可能散在业务代码里。
工程师可以一边调试一边补理解,Agent 不行。它要稳定调用一个能力,需要系统把运行时语义说清楚。比如提交审批这个动作,光有接口还不够。
Agent 需要知道当前状态能不能提交,提交前要补齐什么字段,失败后是缺字段、没权限,还是流程状态不允许。它还需要知道这个动作会造成什么后果,是否需要先停下来等人确认。
能把这些东西表达出来,才算是在为 Agent 设计。
这并不是说以后软件都会变成聊天框。界面不会消失,人也不会退出流程。变化在于,软件除了给人看、给人点,还要把一部分能力整理成 Agent 能理解、能判断、能安全调用的形式。
这个变化会先影响内部系统。
以前做内部系统,一个功能能点到、能看懂、别太反人类,基本就能交差。Agent 进来以后,标准会多一层:这个功能能不能被它接住,条件有没有写清楚,失败信息够不够它判断下一步,而不是只返回一句操作失败。
一旦这个标准成立,软件设计的重心就会慢慢偏移。
功能入口不再只是页面上的按钮,也可能是 Agent 编排任务时的一块积木。流程也不一定非要按页面一步步走。只要权限、状态、前置条件和风险边界足够清楚,Agent 就可以在边界内重新组合动作。
日志也会变得更重要。它不只是给工程师排查问题,还会成为 Agent 理解执行过程的依据:刚才发生了什么,哪一步失败了,失败之后还能不能继续。
所以不是 UI 消失了。
更准确地说,是软件多了一层新的读者:以前主要写给人看,现在还要让 Agent 看得懂、接得住、用得稳。

结语
在我们真正做 Agent 开发的时候,会发现基于半年前的模型和半年后的模型对于工程能力的要求是不一样的。
只不过模型当然重要,没有模型能力,Harness 只是一个空架子。但长期看,只讨论模型,很容易把问题讲窄。
模型会变,能力边界也会变。今天是某个模型工具调用更稳,明天可能是另一个模型上下文更长,后天又冒出一个新的推理模型。系统如果把自己绑死在某一个模型上,迟早会被动。
更值得投入的,是模型外面那层东西。
上下文不是越多越好,工具也不是挂上去就完事。权限要落到具体动作上,失败以后要能接着走,历史和经验也得能被下一次任务找回来。
这些没有模型发布会那么热闹,但它们决定 Agent 能不能在真实工作里长期跑。
Hermes-Agent 给我的启发就在这里。
它当然不是标准答案,也不是未来所有 Agent 系统都该照着它长。但它像一个很好的早期切片:你能看到一个 Agent 从聊天壳往运行时系统长出来的过程。
上一篇文章,我们跟着一条消息走了一遍,看到的是 Hermes-Agent 怎么把一次对话跑完:
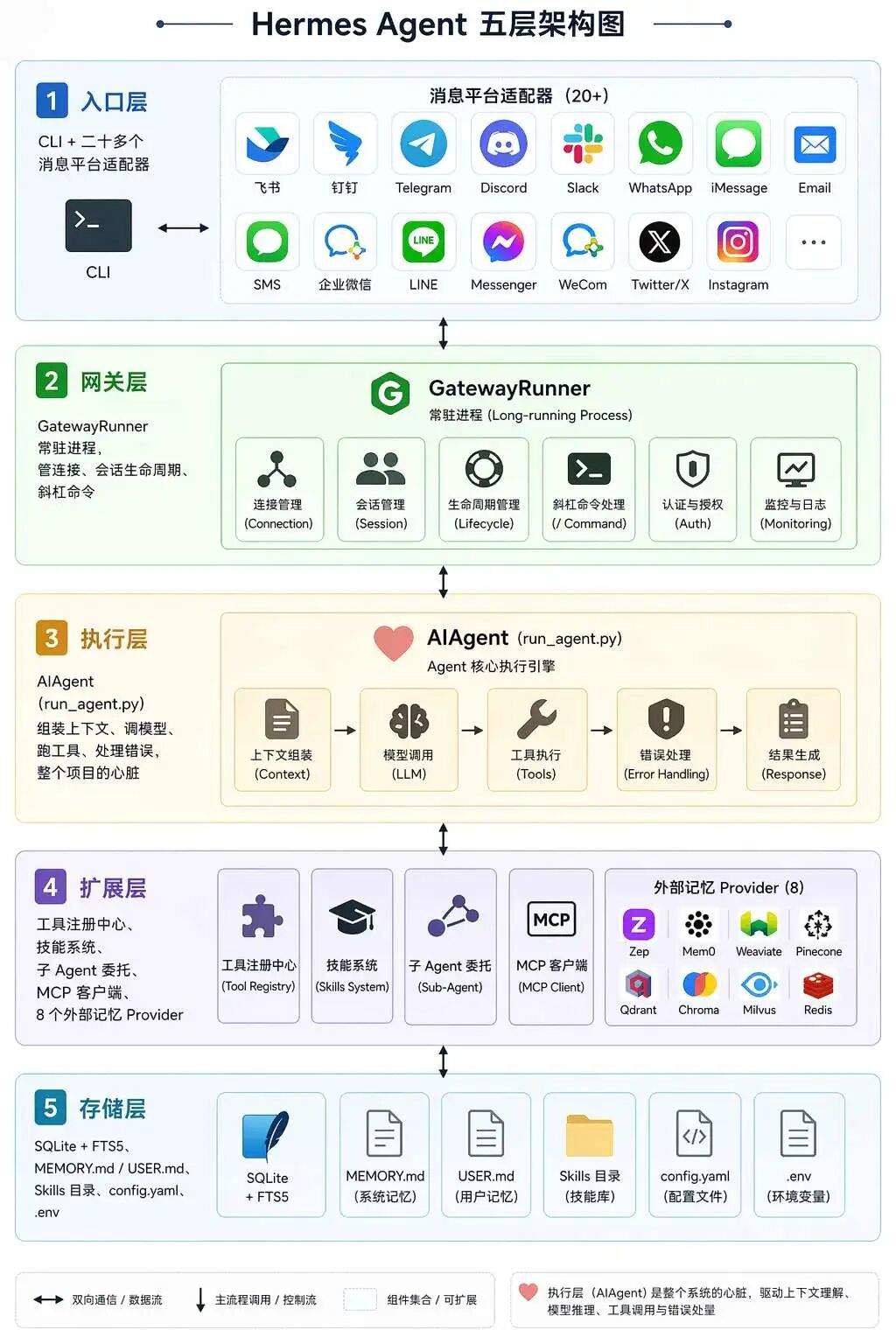
这一篇看的是另一层:如果把这条链路放远一点,它背后正在成形的是一套 Harness。它关心的不是某一次回答够不够聪明,而是模型能力能不能在真实工作流里稳定、安全、可持续地运行。
再往前看一步,Harness 还会反过来影响软件本身。
未来的软件不会只被人使用,Agent 也会使用它。系统不能只给 Agent 一个接口地址,还得把动作的语义说清楚:什么时候能用,当前处在什么状态,越界了怎么办,失败之后还能不能补救,什么地方必须停下来等人确认。
这些听起来都是工程细节,但新一代软件的入口,很可能就是从这些不起眼的地方长出来的。
我现在对 Agent 的判断也更保守了一点。
一个 Demo 能跑通,说明不了太多。真正值得看的,是它连续跑十几轮之后还稳不稳;出错的时候,会不会停下来,而不是继续硬冲;任务做完以后,有没有把过程里的经验留下来。
还有一个更容易被忽略的问题:它接入的那个软件,本身有没有给 Agent 留出清楚的动作层。
如果这些问题回答不上来,再强的模型也只能撑一阵。
如果回答得上来,Agent 才可能真的从聊天框走出来,成为软件系统里一层新的执行能力。