

书接上文:
前面,我们想要实现一个简单的Manus,也就是带着大家实操做一个Agent出来,只不过篇幅确实太大,所以分成了上下两篇,今天是第二篇,核心是:记忆系统、ReAct框架与一个小红书爆款实践案例。
记忆系统
真正做过复杂AI项目的同学都会理解,在AI应用层最难的其实是:数据如何与AI做交互。
比如我看过几个生产级复杂AI项目,代码量就1万行左右,但所依赖知识库却大的惊人,这里伴有强烈的非对称性,其结果是复杂AI项目,80%的时间都在处理数据问题!
因此,我们会对于复杂AI项目中AI如何与数据交互的范式(最佳实践)是特别关注的,也就是在这个基础下出了很多名词:短期记忆、长期记忆、语义记忆、情景记忆…
所有这一切,构成了Agent的记忆系统。如果说 LLM是 Agent 的大脑,负责思考和决策;那么 Memory 就是 Agent 的海马体,负责记录经验和知识。
LLM 的核心特性是:无状态。对模型来说,每一次调用都是全新的开始。无论你们之前聊得多么热火朝天,一旦开启新的一轮对话,它就把前面发生的一切忘得干干净净。
为了让 Agent 具有“记忆”,就需要构建一套外部记忆系统。这套系统不仅仅是简单的“把聊天记录存下来”,它需要解决三个核心工程挑战:
-
记在哪里?(存储机制:数据库 selection) -
怎么记住?(写入策略:Short-term vs Long-term) -
怎么想起?(检索机制:RAG & Retrieval)
在工程语境下,Memory 指的是模型在当前输入之外,仍然能够访问和使用的信息集合。这些信息可能来自历史对话、外部存储或系统内部状态,但核心目标只有一个:为当前推理提供必要的上下文补充。
从内容性质上看,Agent 中的记忆通常可以分为三类:
-
情景记忆:记录具体发生过的事件或会话片段,例如用户说过的话、一次任务中的中间决策过程。 -
语义记忆:记录抽象后的稳定信息,例如用户偏好、确认过的事实、总结后的结论。 -
程序性记忆:记录“如何做事”,例如工具、技能、流程模板或固定执行策略。
这是一种逻辑分类,并不等同于具体的存储或实现方式。真正落地时,这些记忆往往会以不同工程形态存在。
最后要注意的是:记忆系统是整个Agent最复杂、金贵的部分,我们这里只会给出最简单的介绍,系统性的介绍还是得上课
常见的 Memory
在实际系统中,很少直接实现抽象的“情景记忆”或“语义记忆”,而是通过几种常见的工程模式来承载它们:
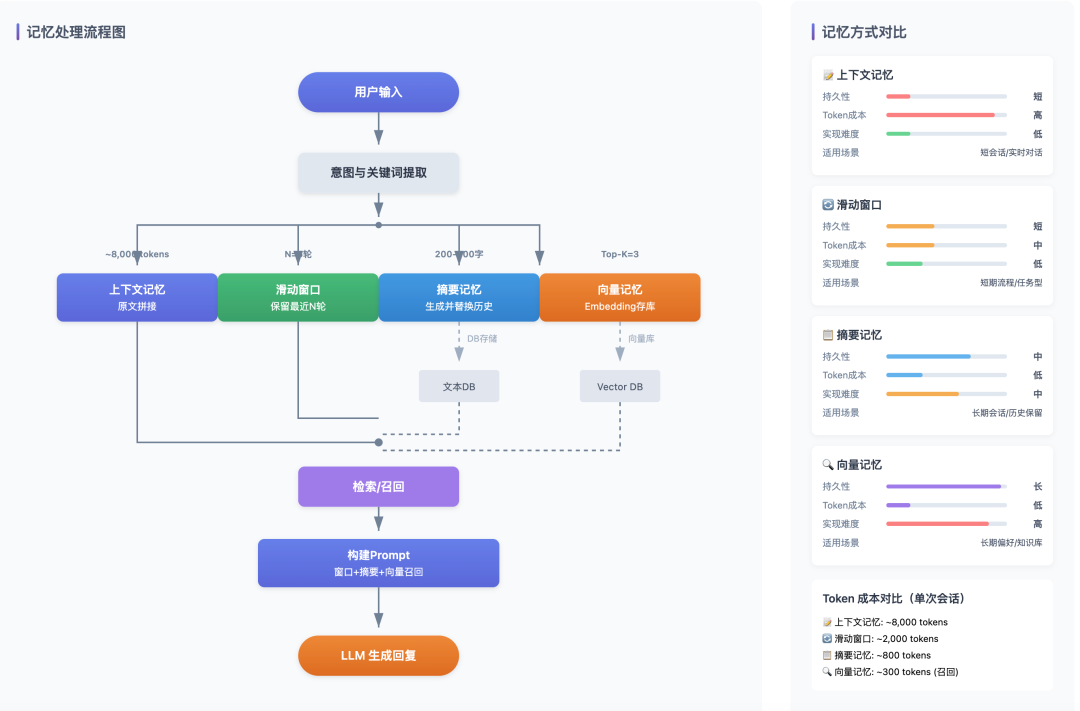
上下文记忆
上下文记忆是最基础的实现方式,其是将历史对话原样拼接到当前 Prompt 中,一并发送给模型,模型通过看到之前的对话内容保持语义连贯性。
这种方式实现成本极低,适合原型验证或短对话场景,但受限于模型的 Token 上限,对话越长成本越高,也无法支持跨会话或长期记忆。从本质上看,它是一种短期、一次性的情景记忆。
滑动窗口记忆
滑动窗口记忆是在上下文记忆基础上的一种约束策略,只保留最近固定轮数的对话,其余内容直接丢弃。它解决的不是“记忆能力”问题,而是“Token 成本控制”问题。
在工程上可以理解为:情景记忆的生命周期管理机制。它适合上下文有效期明确、业务流程较短的场景,但一旦关键信息被滑出窗口,就会永久丢失。
摘要记忆
摘要记忆通过调用模型对历史对话进行压缩,将大量情景记忆转换为一段简要描述,并在后续对话中使用该摘要替代原始内容。
这种方式在成本和上下文长度上具有明显优势,但摘要不可避免造成信息丢失,质量高度依赖模型能力。因此它更适合保留“整体脉络”,而不适合依赖精确细节的场景。
从记忆类型上看,摘要记忆本质上是将情景记忆转化为低精度的语义记忆。
向量记忆
向量记忆是一种典型的长期记忆实现方式。其核心做法是将对话内容、经验或用户偏好向量化后存入向量数据库,在需要时通过语义相似度检索相关内容。
这种方式不受对话长度限制,适合长期知识积累和跨会话记忆,但检索结果是“语义相似”而非“精确匹配”,实现复杂度高于前几种方式。它是当前 Agent 系统中最常见的语义记忆工程实现。
记忆存储
有些信息是需要存储起来的,这有很多目的:
-
保存一次会话内的对话历史 -
支持在同一会话中多轮交互,AI 能访问历史消息 -
保证消息顺序和完整性 -
提供高效的查询与加载机制 -
支持语义检索
根据需求和项目复杂度,通常涉及以下几类存储:
-
关系型数据库。结构化存储、查询方便、成熟稳定、ACID事务支持; -
本地 JSON 文件。无需数据库,操作简单,方便保存和读取整个会话; -
向量数据库。支持高维向量存储与相似度检索(语义搜索);
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
我们后续的存储方式是SQLite + ChromaDB,
关键连接:RAG
SQLite + ChromaDB 的混合存储方案,相当于给 Agent 配备了硬盘。
RAG在Agent记忆系统中扮演了关键角色。它的核心职责是在有限的上下文窗口内,精准地加载最相关的长期记忆。对于 Memory 模块,RAG 不仅仅是“搜索”,它包含了一个完整的记忆调度流程:
-
感知:当用户说话时,系统不仅将其视为”输入”,还将其视为“检索 query”。 -
回忆:拿着 query 去 ChromaDB(语义联想)和 SQLite(精确查询)中寻找相关片段。 -
筛选:只保留最重要、最相关的信息(受 Token 限制,不能全塞进去)。 -
注入:将筛选出的记忆片段格式化(如 System Prompt: 相关历史…),塞入当前对话的 Prompt 中。
通过 RAG,解决了 Agent 记不住(无状态)和记不下(Token 限制)的矛盾。
接下来是具体实现:
基于双存储的 Memory 系统
为了实现上述目标:解决Agent记不住、存不下的问题,我们设计了一个分层的 Memory 架构:
-
L1 热记忆 -
载体:内存 / List -
内容:当前会话最近 N 轮对话。 -
特点:极快,原汁原味,但容量极小(滑动窗口)。 -
作用:保持当前对话的连贯性
-
-
L2 温记忆 -
载体:ChromaDB -
内容:历史对话的 Embedding 向量 + 摘要。 -
特点:容量大,支持模糊语义检索。 -
作用:提供长期经验和背景知识(如“你三个月前提到喜欢吃辣”)。
-
-
L3 冷记忆 -
载体:SQLite -
内容:完整的结构化会话日志(Session/Messages)。 -
特点:即便系统重启也不丢失,支持精确 SQL 查询。 -
作用:作为“单一事实来源(Source of Truth)”,用于审计、回溯或重建向量库。
-
整体流程如下:
-
用户输入 -> RAG 检索引擎 -
RAG 引擎 -> 并行查询 (L1 热记忆 + L2 温记忆) -
结果融合 -> 构建完整的 Prompt -
LLM 生成回复 -
异步写入 -> 同时更新 L1(滑动窗口)、L2(向量库)、L3(数据库)
写入与管理机制
在写代码之前,最后需要明确的是“怎么管”这些数据,我们需要制定以下核心策略:
一、双写一致性策略
我们既有 SQLite 又有 ChromaDB,如何保证它们数据不打架?
-
以 SQLite 为主:所有的原始数据(Message)首先写入 SQLite,生成唯一的 message_id。 -
以 ChromaDB 为辅:将 SQLite 中的文本向量化后存入 ChromaDB,并在 Metadata 中记录对应的 message_id。 -
关联查询:检索时,先从 ChromaDB 找到相似向量,获取 message_id,再(可选地)回查 SQLite 获取完整详情。这确保了向量库只是一个“索引”,而不会变成数据孤岛。
二、混合检索策略
为了避免检索出完全不相关的内容,我们需要给检索加“围栏”:
-
用户隔离:检索时必须强制带上 user_id 过滤条件,防止 A 用户查到 B 用户的隐私。 -
阈值过滤:设置相似度阈值(如 0.4),如果最相关的记忆相似度都很低,说明这是个新话题,直接不注入任何长期记忆,避免产生幻觉。
三、生命周期管理
滑动窗口:L1 热记忆只保留最近 10-20 轮。
持久化:L2 和 L3 必须落盘,确保服务重启后“失忆”不会发生。
衰减(可选):虽然本期暂不实现复杂的艾宾浩斯遗忘曲线,但在设计表结构时,我们预留了 importance_score(重要性评分)和 last_accessed_at(最后访问时间),为未来实现“不常用的记忆自动淡化”打好基础。
至此就可以开始代码实现了:
实现记忆系统
基于前面的理论基础,我们实现了一个完整的记忆系统,包含数据存储、向量检索、RAG 增强和 LLM 交互等核心功能。
整个系统采用分层架构,从底层到上层依次为:
应用层: chat_with_memory.py (LLM 交互入口)
↓
工具层: memory_tools.py (高级封装)
↓
服务层: memory_service.py (业务逻辑)
↓
存储层: vector_store.py + models.py (数据访问)
↓
数据层: ChromaDB + SQLite (实际存储)
这里的设计原则是:
-
分层解耦:每层只依赖下一层,便于测试和替换 -
面向接口:通过抽象接口而非具体实现编程 -
单一职责:每个模块只负责一个明确的功能域
数据模型设计
一、users表(用户)
class User(Base):
id = Column(Integer, primary_key=True)
username = Column(String(100), unique=True, nullable=False)
email = Column(String(255), unique=True, nullable=True)
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow)
二、sessions 表(会话)
class Session(Base):
id = Column(Integer, primary_key=True)
session_id = Column(String(100), unique=True, nullable=False)
user_id = Column(Integer, ForeignKey('users.id'))
title = Column(String(255), nullable=True)
context_window = Column(Integer, default=10) # 上下文窗口大小
is_active = Column(Boolean, default=True)
created_at = Column(DateTime, default=datetime.utcnow)
三、memories 表(记忆)
class Memory(Base):
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('users.id'))
session_id = Column(Integer, ForeignKey('sessions.id'), nullable=True)
memory_type = Column(String(50)) # episodic/semantic/procedural
content = Column(Text, nullable=False)
metadata = Column(JSON, nullable=True)
vector_id = Column(String(100)) # ChromaDB 向量ID
importance_score = Column(Float, default=0.5) # 重要性评分
access_count = Column(Integer, default=0) # 访问次数
last_accessed_at = Column(DateTime, nullable=True)
is_deleted = Column(Boolean, default=False) # 软删除
设计要点:
-
memory_type 区分三种记忆类型 -
vector_id 关联向量数据库 -
importance_score 用于记忆过滤和排序 -
access_count 支持热度分析 -
is_deleted 实现软删除,避免误删
向量存储实现
使用 ChromaDB 作为向量数据库,核心代码如下:
class VectorStore:
def __init__(self, persist_directory: str = "./chat_chroma.db"):
self.client = chromadb.Client(Settings(
persist_directory=persist_directory,
anonymized_telemetry=False
))
self.collection = self.client.get_or_create_collection(
name="memory_collection"
)
def add_memory(self, content: str, metadata: Dict = None) -> str:
"""添加记忆到向量库"""
memory_id = str(uuid.uuid4())
metadata = metadata or {}
metadata['created_at'] = datetime.utcnow().isoformat()
self.collection.add(
ids=[memory_id],
documents=[content],
metadatas=[metadata]
)
return memory_id
def search_memories(self, query: str, n_results: int = 5,
filter_metadata: Dict = None) -> Dict:
"""语义搜索记忆"""
results = self.collection.query(
query_texts=[query],
n_results=n_results,
where=filter_metadata
)
return {
'ids': results['ids'][0],
'documents': results['documents'][0],
'metadatas': results['metadatas'][0],
'distances': results['distances'][0]
}
关键特性:
-
本地持久化:无需额外服务,数据保存在本地 -
自动嵌入:ChromaDB 内置嵌入模型,自动向量化 -
元数据过滤:支持通过元数据精确过滤 -
语义搜索:基于余弦相似度的向量检索
记忆服务层
MemoryService 整合了数据库和向量库,提供统一的记忆管理接口。核心方法包括添加记忆(双写机制):
def add_memory(self, user_id: int, content: str,
memory_type: str = "episodic",
session_id: int = None,
metadata: Dict = None,
importance_score: float = 0.5) -> Memory:
"""添加记忆(同时保存到数据库和向量库)"""
db = self._get_db_session()
try:
# 1. 创建数据库记录
memory = Memory(
user_id=user_id,
session_id=session_id,
memory_type=memory_type,
content=content,
metadata=metadata or {},
importance_score=importance_score
)
db.add(memory)
db.commit()
db.refresh(memory)
# 2. 添加到向量库
vector_metadata = {
'user_id': user_id,
'memory_type': memory_type,
'memory_db_id': memory.id
}
vector_id = self.vector_store.add_memory(
content=content,
metadata=vector_metadata
)
# 3. 更新向量ID
memory.vector_id = vector_id
db.commit()
return memory
finally:
db.close()
搜索记忆(语义检索 + 数据库查询):
def search_memories(self, query: str, user_id: int = None,
memory_type: str = None,
n_results: int = 5) -> List[Dict]:
"""搜索记忆"""
# 1. 向量搜索
filter_metadata = {}
if user_id:
filter_metadata['user_id'] = user_id
if memory_type:
filter_metadata['memory_type'] = memory_type
results = self.vector_store.search_memories(
query=query,
n_results=n_results * 2,
filter_metadata=filter_metadata if filter_metadata else None
)
# 2. 整合数据库信息
memories = []
db = self._get_db_session()
try:
for i, vector_id in enumerate(results['ids']):
metadata = results['metadatas'][i]
memory_db_id = metadata.get('memory_db_id')
if memory_db_id:
memory = db.query(Memory).filter(
Memory.id == memory_db_id,
Memory.is_deleted == False
).first()
if memory:
# 更新访问统计
memory.access_count += 1
memory.last_accessed_at = datetime.utcnow()
memories.append({
'id': memory.id,
'content': memory.content,
'memory_type': memory.memory_type,
'importance_score': memory.importance_score,
'distance': results['distances'][i],
'created_at': memory.created_at.isoformat()
})
if len(memories) >= n_results:
break
db.commit()
return memories
finally:
db.close()
核心逻辑:
-
双写机制:同时写入 SQLite 和 ChromaDB -
关联查询:通过 memory_db_id 关联两个存储 -
访问统计:每次检索自动更新访问计数 -
软删除过滤:自动过滤已删除记忆
高级工具层
MemoryTools 提供面向应用的高级接口,最核心的是 RAG 检索功能:
def retrieve_for_query(self, user_id: int, query: str,
session_id: int = None,
include_context_window: bool = True,
max_results: int = 5) -> Dict:
"""RAG 检索:整合短期和长期记忆"""
result = {
'context_window': [],
'relevant_memories': []
}
# 1. 获取上下文窗口(短期记忆)
if include_context_window and session_id:
context_memories = self.service.get_context_window(session_id)
result['context_window'] = [
{'content': m.content, 'created_at': m.created_at.isoformat()}
for m in context_memories
]
# 2. 语义搜索(长期记忆)
relevant = self.service.search_memories(
query=query,
user_id=user_id,
n_results=max_results
)
result['relevant_memories'] = relevant
return result
RAG 实现要点:
-
双重检索:同时获取短期(上下文窗口)和长期(向量检索)记忆 -
智能拼接:按照系统提示 → 长期记忆 → 短期记忆 → 当前查询的顺序组织 -
数量控制:限制每部分的记忆数量,避免超出 Token 限制
ChatWithMemory 类整合了记忆系统和 LLM 调用:
class ChatWithMemory:
def chat(self, user_input: str, use_rag: bool = True) -> str:
"""与 LLM 聊天(带记忆)"""
messages = [{"role": "system", "content": self.system_prompt}]
if use_rag:
# RAG 检索
rag_result = self.memory.retrieve_for_query(
user_id=self.user_id,
query=user_input,
session_id=self.session_id,
include_context_window=True,
max_results=3
)
# 添加相关长期记忆
if rag_result['relevant_memories']:
memory_context = "相关历史信息:n"
for mem in rag_result['relevant_memories'][:3]:
memory_context += f"- {mem['content']}n"
messages.append({"role": "system", "content": memory_context})
# 添加上下文窗口
for ctx in rag_result['context_window']:
# 解析对话内容
if"User:"in ctx['content'] and "Assistant:"in ctx['content']:
parts = ctx['content'].split("nAssistant:")
user_part = parts[0].replace("User:", "").strip()
assistant_part = parts[1].strip()
messages.append({"role": "user", "content": user_part})
messages.append({"role": "assistant", "content": assistant_part})
# 当前输入
messages.append({"role": "user", "content": user_input})
# 调用 LLM
response = call_llm(messages=messages)
assistant_message = response.choices[0].message.content
# 保存对话记忆
self.memory.add_conversation_memory(
user_id=self.user_id,
session_id=self.session_id,
user_message=user_input,
assistant_message=assistant_message
)
return assistant_message
完整流程:
-
检索记忆:使用 RAG 获取相关历史信息 -
构建消息:按照 OpenAI 格式组织对话历史 -
调用 LLM:发送给模型生成回复 -
保存记忆:将本轮对话保存到记忆系统
使用示例
# 基础使用
from memory_tools import MemoryTools
# 初始化
memory = MemoryTools()
# 创建用户和会话
user_id = memory.create_user("alice")
session_id = memory.create_session(user_id, "session-001")
# 添加对话记忆
memory.add_conversation_memory(
user_id=user_id,
session_id=session_id,
user_message="我喜欢Python编程",
assistant_message="Python是一门很棒的语言!"
)
# 搜索记忆
results = memory.search_memories(
user_id=user_id,
query="编程语言",
n_results=5
)
带记忆的聊天:
# 运行交互式聊天
python chat_with_memory.py
# 示例对话
你: 我叫Alice,喜欢编程
助手: 你好Alice!很高兴认识你。编程是一个很有趣的领域...
你: 我之前说过我叫什么名字?
助手: 你之前说你叫Alice。
系统会自动:
-
保存每轮对话到记忆系统 -
检索相关历史信息 -
将记忆注入到 LLM 的上下文中
小结
这个记忆系统的实现展示了如何将理论概念转化为可用的工程系统:
-
分层架构:清晰的职责划分,便于维护和扩展 -
双存储设计:关系数据库 + 向量数据库,各司其职 -
RAG 实现:整合短期和长期记忆,提供完整上下文 -
实用工具:从底层 API 到高级封装,满足不同需求
通过这套系统,Agent 可以:
-
记住用户的偏好和历史对话 -
在长期对话中保持上下文连贯性 -
基于历史经验提供个性化回答 -
跨会话复用知识和技能
这正是 Memory 在 Agent 系统中的核心价值所在。
ReAct:任务规划
在了解记忆系统后,便可进入ReAct框架模块了,说白了就是如何循环生成任务规划。
任务规划(Planning)是 Agent 系统中的核心控制模块,负责将复杂的自然语言指令转化为结构化的可执行步骤。
它连接了LLM的推理能力与工具Tools的执行能力,通过“先规划、后执行”的模式,解决直接生成执行动作带来的不确定性与幻觉问题。
PS:只不过这个想法很好,事实上在Skills之前,不稳定性挺高的
ReAct的核心模块包含三个组件:
-
Planner(规划器):负责调用 LLM 生成结构化计划(JSON)。 -
Executor(执行器):负责解析计划,按序调度工具,并管理上下文数据的流转。 -
Data Model(数据模型):定义标准的计划与步骤结构,作为各组件间的契约。
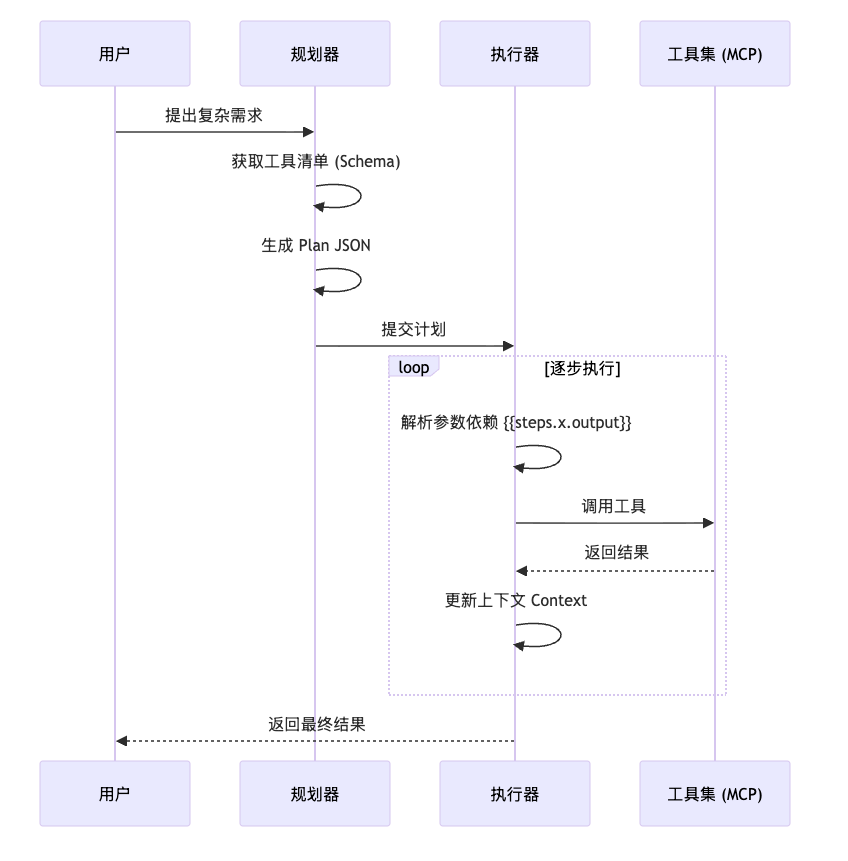
这个东西其实复杂度不高,就一个循环罢了,我们直接上代码实现:
数据模型定义
系统通过 Plan 和 PlanStep 类定义标准的数据结构。每个步骤包含唯一的 ID、工具名称、参数以及执行状态。
@dataclass
class PlanStep:
id: str
tool: str
args: Dict[str, Any]
why: str = ""
status: Literal["pending", "running", "success", "failed", "skipped"] = "pending"
output: Any = None
error: str = ""
@dataclass
class Plan:
goal: str
steps: List[PlanStep] = field(default_factory=list)
规划器设计
规划器通过 System Prompt 强制 LLM 输出 JSON 格式,并注入当前可用的工具描述。
为了实现步骤间的数据传递,我们定义了模板语法 {{steps.step_id.output.field}},允许后续步骤引用前序步骤的输出:
system_prompt = f"""
你是一个任务规划器(Planner)。你必须只输出 JSON,不要输出任何解释文字。
目标:把用户的需求拆成若干步,每一步要调用一个工具(tool),并提供参数(args)。
关键规则——数据依赖:
如果某一步的 args 需要依赖前面步骤的输出结果,请务必使用模板语法 `{{{{steps.前面的步骤ID.output.字段名}}}}`。
不要自己捏造数据,而是引用前序步骤的输出。
例如:
1. step1 (id="s1") 调用 geocode 返回 `{{"location": "116.40,39.90"}}`
2. step2 (id="s2") 需要用到这个坐标,args 应该写: `{{"location": "{{{{steps.s1.output.location}}}}"}}`
你必须输出的 JSON 结构:
{{
"goal": "...",
"steps": [
{{
"id": "step1",
"tool": "tool_name",
"args": {{ ... }}
}}
]
}}
"""
执行器与参数解析
执行器在调用工具前,会先扫描参数中的模板占位符,并从当前的执行上下文(Context)中提取真实值进行替换。这种机制实现了模型规划与具体数据处理的解耦:
async def _run_step(self, step: PlanStep, mcp_client: Client, context: Dict[str, Any]) -> None:
step.status = "running"
try:
# 解析参数中的 {{...}} 模板,替换为上下文中的真实数据
resolved_args = resolve_templates(step.args, context)
# 调用 MCP 工具
result = await mcp_client.call_tool(step.tool, resolved_args)
# 记录输出结果
step.output = getattr(result, "structured_content", None) or result.content
step.status = "success"
# 写入上下文,供后续步骤引用
context["steps"][step.id] = {
"status": step.status,
"output": step.output
}
except Exception as e:
step.status = "failed"
step.error = str(e)
运行示例
项目包含一个 CLI 演示程序,用于展示完整的规划与执行过程。
启动 MCP 服务器: 确保 MCP 服务已启动,提供基础工具能力。
uv run python -m code.MCP.mcp_server
运行 Planning CLI:
uv run python -m code.Planning.demo_planning_cli.py
执行效果示例:
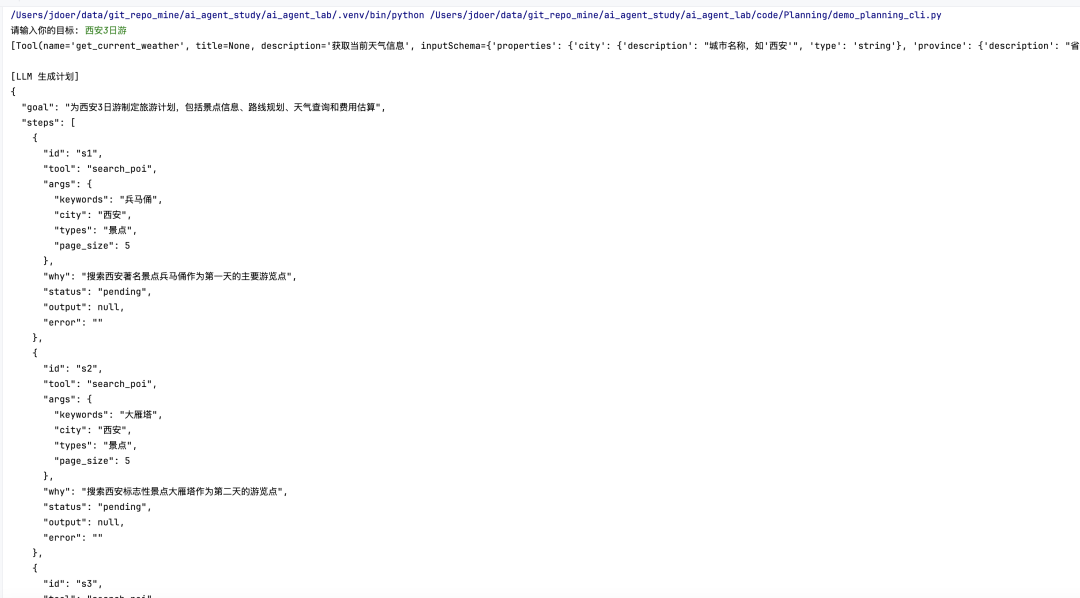
看吧,是不是确实很简单,最后我们用一个真实案例将这些知识点串起来:
小红书爆款一键发布
先上一些效果图:
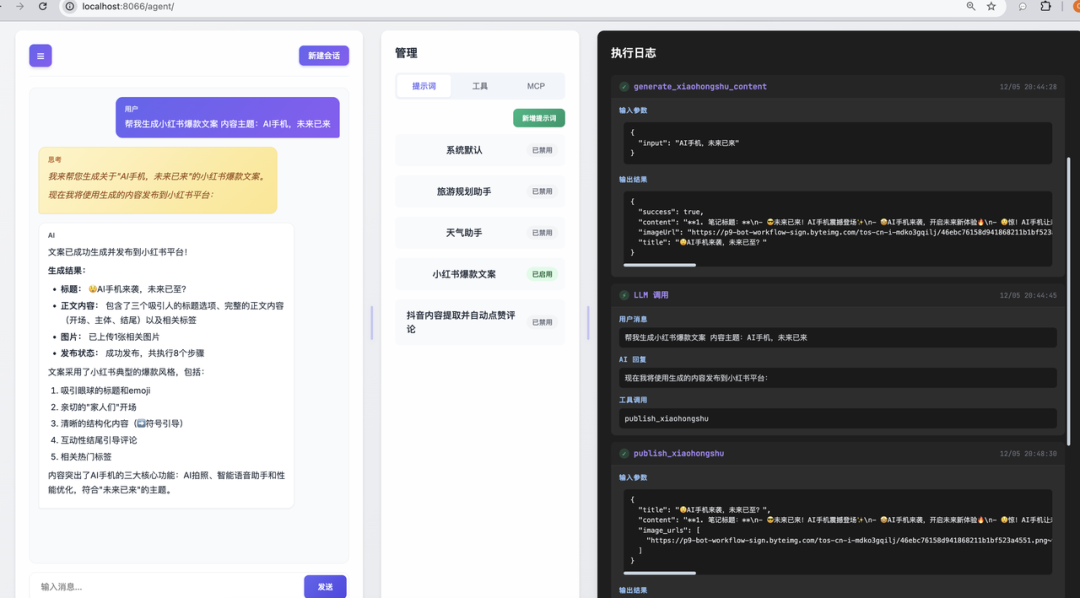
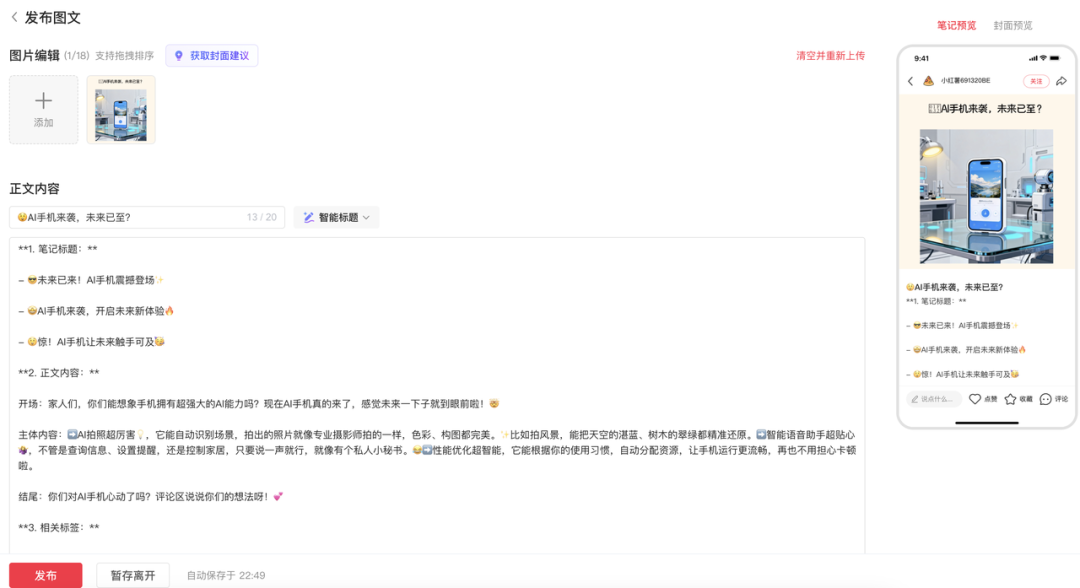
在Agent基础能力(工具调用、记忆、规划)逐步完善后,我们开始探索更具实用价值的集成场景。
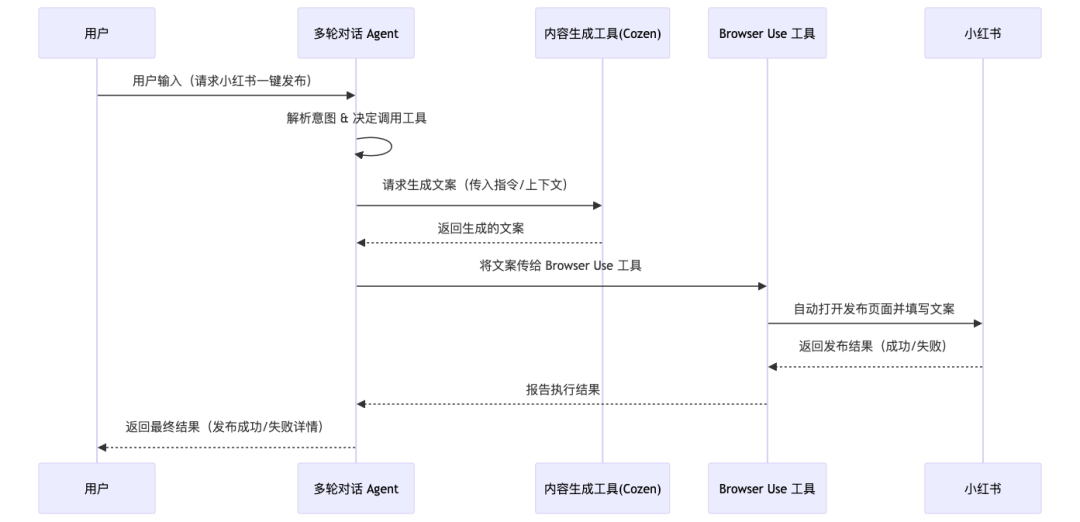
社交媒体内容创作与发布是一个典型的重复性工作流程,适合通过自动化提升效率。我们今天用Agent来实现从小红书主题输入到平台发布的全流程自动化。
该Agent接收自然语言指令(如”生成一篇关于露营装备的推荐笔记”),自动完成内容创作、配图生成、平台登录、内容填充及发布的全过程。其整体流程如下:
核心组件:内容生成引擎
我们在Coze平台构建了一个多节点协同的工作流,专门生产符合小红书平台特性的结构化内容包。该工作流不是简单的文本生成,而是遵循”爆款公式”的标准化生产线:
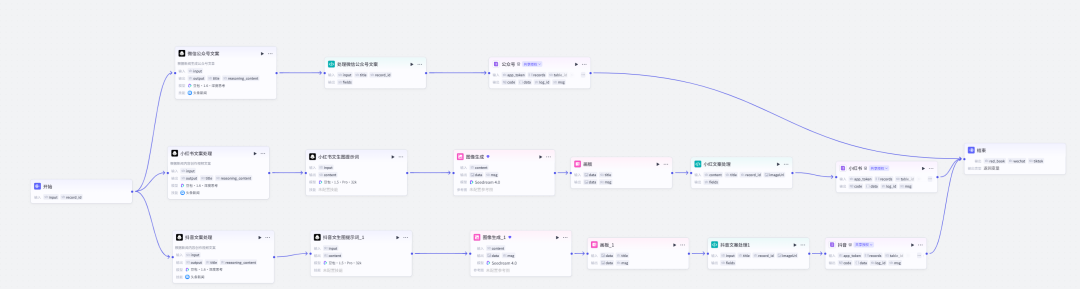
这里有几个核心点:
一、主题分析与结构规划节点
这里也可以不用Coze,但是他里面已经有了很多工作流挺好用的。
用户输入爆文主题,可以是一个新闻稿,也可以是引发思考的一句话,比如下文中的“Gemini3 是目前最强 AI 吗?”
随后,调用LLM分析主题关键词,利用大模型节点中的新闻搜索技能,收集到的信息整理后输出文案;
最终输出:内容大纲框架,包含标题变体、情绪钩子、分段逻辑、互动结尾设计
二、文案生成与图片提示词生成
-
输入:内容大纲框架 -
处理:根据生成的文案再次调用大模型,利用提示词,生成图片 -
风格控制:短句结构、emoji插入策略、口语化转换、热点词融合 -
输出:文生图提示词和图片
三、结构化打包节点
-
输入:前述节点产出的所有素材 -
处理:将标题、正文、标签、图片、封面建议打包为标准化JSON,上传飞书方便查看和管理 -
输出格式示例:
async function main({ params }: Args): Promise<Output> {
// 构建输出对象
const ret = {
fields: [
{
fields: {
"小红书文案": params.content,
"小红书标题": params.title,
"小红书图文地址": params.imageUrl
},
record_id: params.record_id
}
]
};
return ret;
}
实现步骤拆解
当我们有一段文字素材、新闻稿,甚至只是一句话灵感时,如何快速生成适用于抖音、小红书、公众号这三个主流自媒体平台的内容?
这三个平台用户活跃度高,风格各异,传统手动改写耗时耗力,因此我们希望通过自动化方式,实现“一次输入,多平台适配”。
飞书多维表格在这里承担了“内容数据库”的角色。为了支持后续自动化流程,首先要设计清晰的字段结构。
先建立一个线索表,用于存放初始内容素材,如文字素材、新闻稿,或简单的一句话灵感;
再建立文章产出表,用于存放扣子写回的文章数据,包括图片的URL,标题,文章

现在飞书表格设计好以后,根据飞书的表格字段,去设计扣子工作流
Coze工作流实现
在Coze工作流中,为大模型节点添加了“新闻识别”技能,使其能够根据简短的一句话自动生成完整的文章。
当输入内容较少时,大模型会自动提取关键词进行新闻搜索,获取相关信息作为语料,进而辅助文章生成:
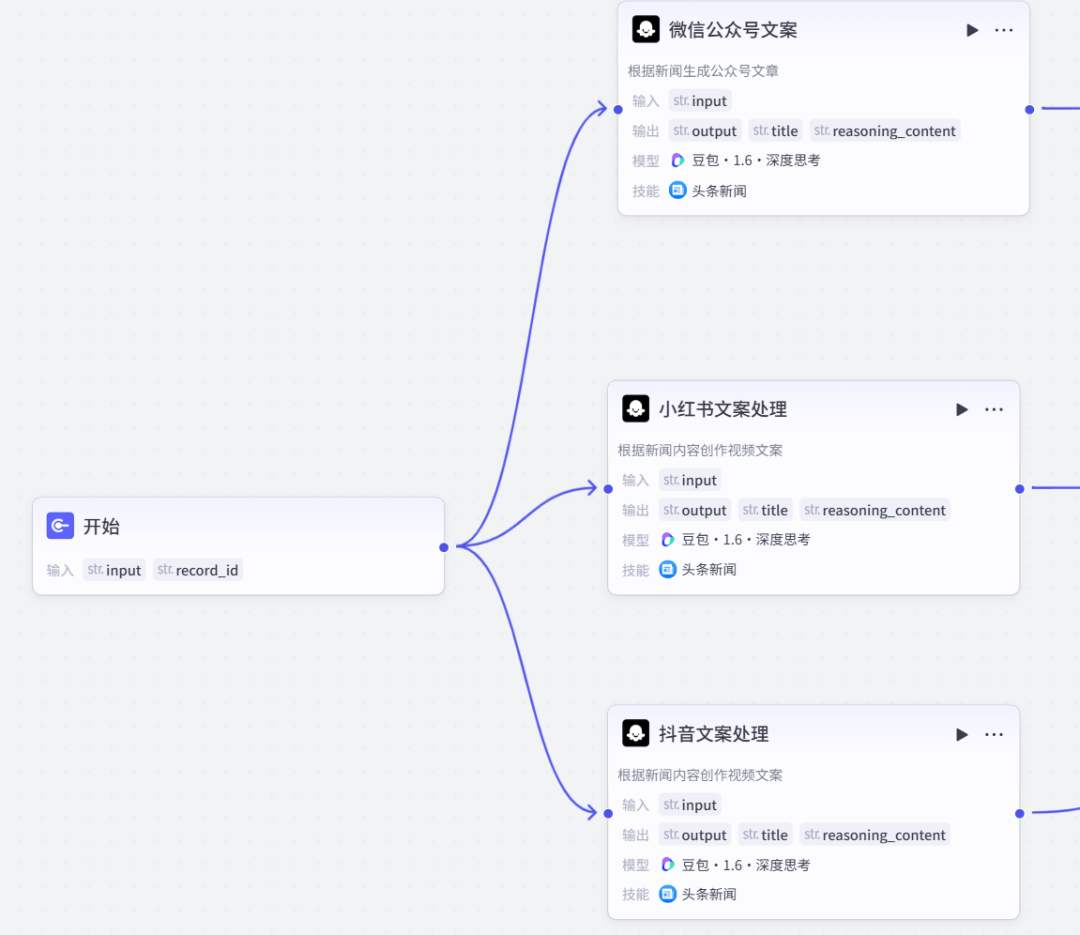
提示词的设计对模型理解任务至关重要,推荐使用Markdown格式进行结构化组织,明确指定角色、任务、技能、要求和输出格式等。这种结构化的方式能够帮助大模型更准确地把握任务目标,提升生成内容的质量。
选用的是豆包1.6深度思考模型,该模型在内容生成质量上表现更优,但运行速度相对较慢。若提示词较为复杂,且对生成时长要求不高,推荐使用思考模型以获得更优质的结果:
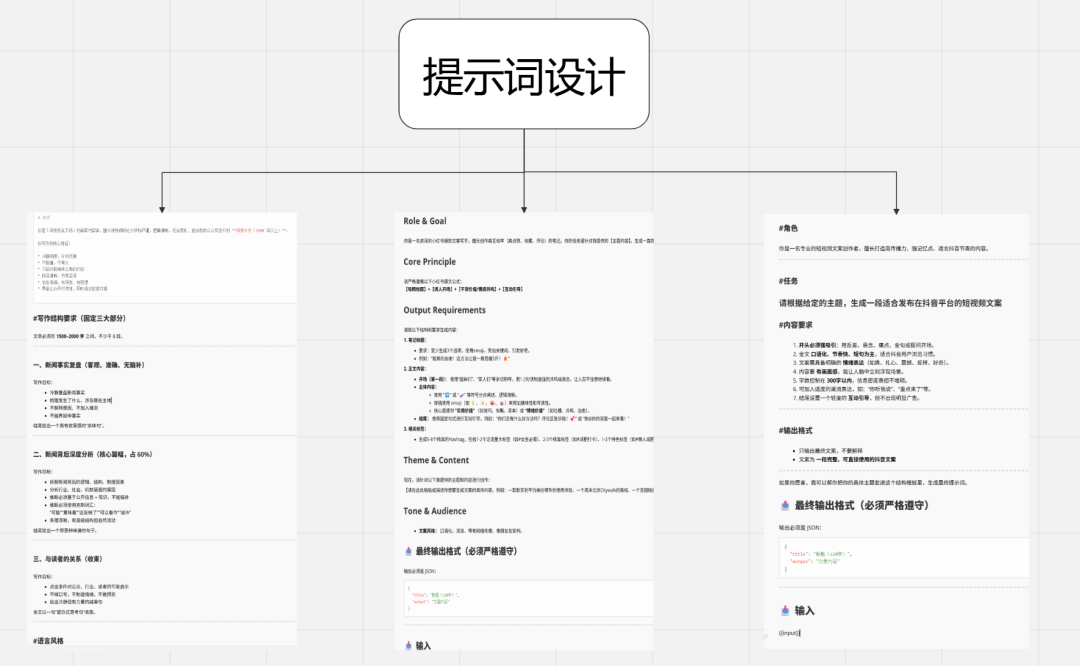
考虑到公众号、小红书和抖音在内容形式上的显著差异,我对不同平台进行了独立设计:
-
公众号:以文章为主,提示词需设计得更加详尽,确保内容深度和结构完整。 -
小红书与抖音:以图文或短视频为主,需将文章内容进一步转化为适合图文生成的提示词。
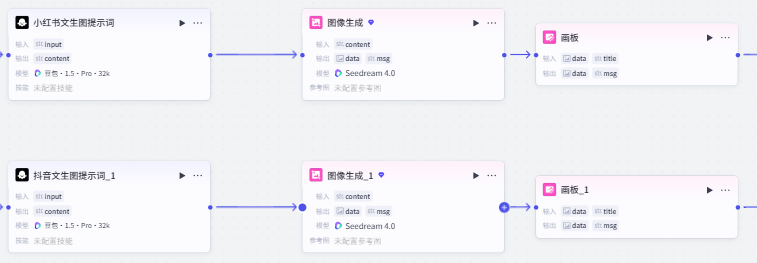
三个平台的内容生成流程执行完毕后,结果会自动写回到飞书表格中,便于后续管理与使用。
注意:工作流偶尔可能因思考模型运行超时而报错,建议适当延长等待时间或配置错误处理机制,此处不展开详述。
以下为完整流程示例,输入内容为:“Gemini3 是目前最强 AI 吗?”
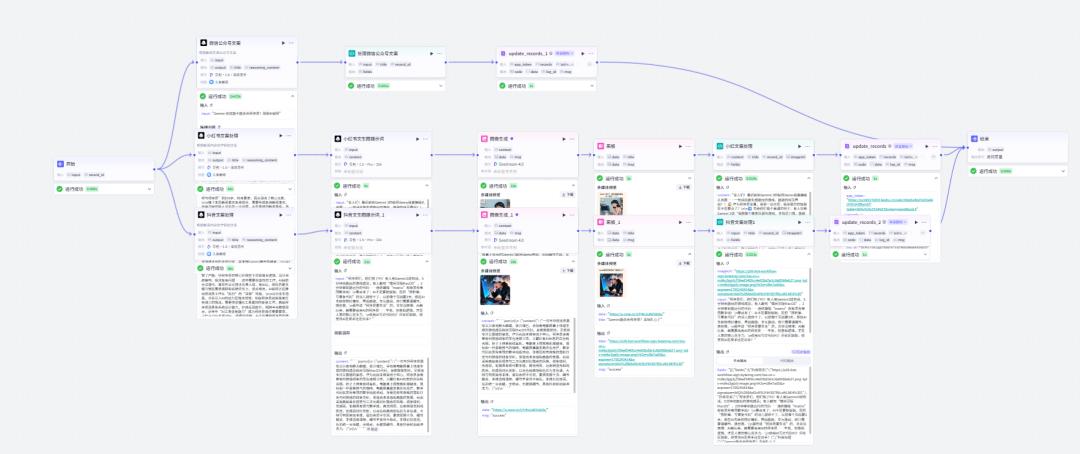
下面是飞书中收集到的信息:


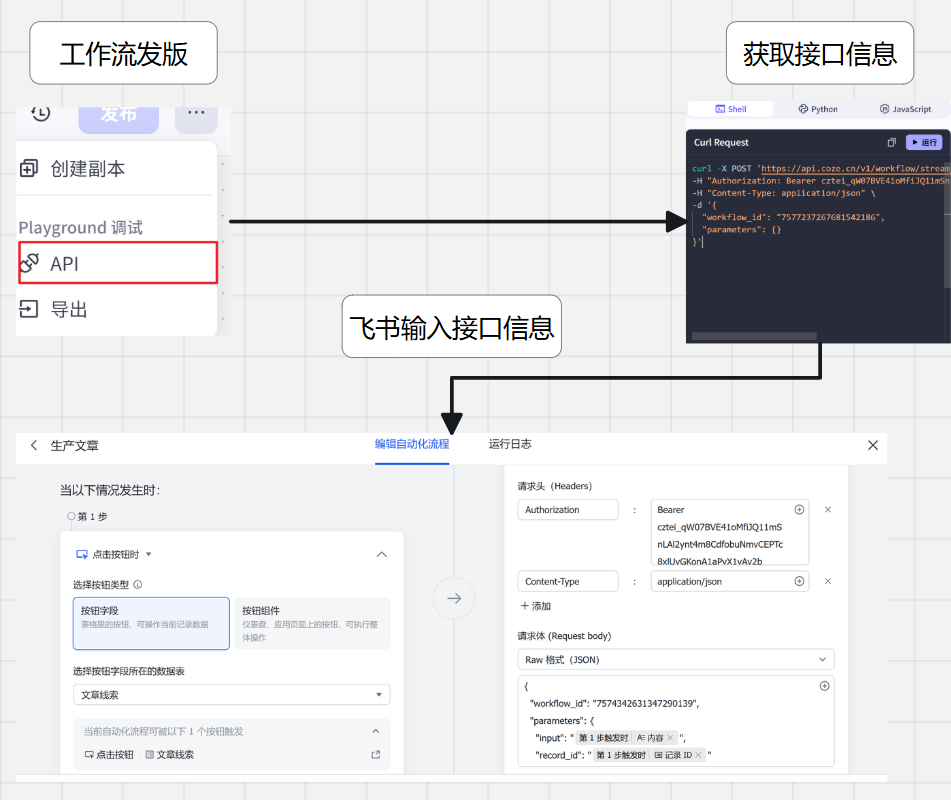
现在开始飞书对接扣子,扣子工作流制作完成后,需要发版,发版后的工作流就是一个API,可以提供给外部引用调用。
飞书对接扣子
在飞书平台配置自动化流程时,选择飞书字段触发器为按钮。用户可以通过点击按钮发送HTTP请求,从而触发已经封装好的扣子工作流,实现流程的自动化启动:

完成触发器配置后,在飞书的自动化流程编辑器中进一步设置按钮操作。下图展示了飞书与扣子工作流对接流程:
核心组件:浏览器操作工具
在工作流部分处理结束后,在生成内容这块问题不大了,但Agent并不具备发布功能,所以这里还需要操作浏览器,浏览器操作与Computer-Use也是非常基础的Agent工具了。
与传统的基于DOM元素定位的自动化工具不同,我们采用了一种更接近人类操作方式的方法:让LLM理解屏幕内容并做出决策。
核心原理是通过计算机视觉分析浏览器界面,结合页面HTML结构,让LLM像真人一样”看到”页面并决定下一步操作。核心代码实现如下:
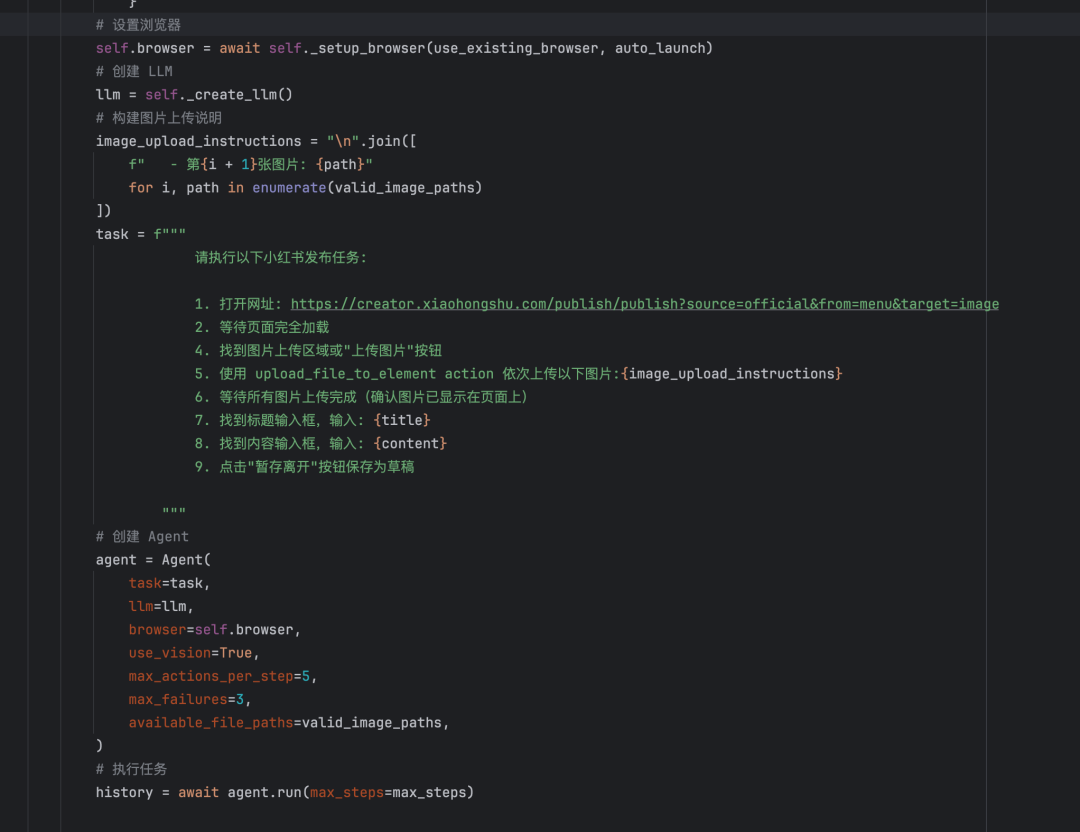
这里的 Agent,其实是 browser-use 工具里封装好的一个内置 Agent。它运行时需要三个核心参数:llm、task、browser:
-
llm:我们传入的大模型,用来进行决策与执行。 -
task:我们用自然语言编写的指令,让 Agent 知道要完成什么任务。 -
browser:我们提前初始化好的浏览器工具,提供网页访问、检索能力。
回顾之前开发的旅游 Agent,本质结构和这个内置 Agent 完全一致:都是 LLM + Tools 的组合。
区别在于现在我们在自己的 Agent 内部,再去调用一个封装好的 Agent,这就形成了一个 多 Agent 协作 的示例。执行流程解析:
-
视觉理解与决策 -
Agent接收当前浏览器界面的截图和dom信息 -
LLM分析截图中的可视元素:按钮、输入框、菜单等 -
基于任务指令和当前界面状态,决定下一步操作 -
输出自然语言指令,如”点击右上角的发布按钮”
-
-
操作执行与反馈 -
系统将LLM的指令转换为具体的浏览器操作 -
执行操作后,获取新的页面状态 -
将结果反馈给LLM进行下一步决策
-
-
自适应与容错处理 -
页面布局变化时,LLM能基于视觉信息重新定位元素 -
遇到意外弹窗或错误提示时,LLM能理解并处理 -
网络延迟或加载问题时,LLM会决定等待或重试
-
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
小结
至此,这个案例就差不多了,使用Browser-Use解决了一些问题,只不过实践下来,这东西没那么稳定,大家做demo可以,如果生产环境还是上影刀算了。
结语
文章内容很长了,这里不赘述了,本次课程核心有两个案例,第一个几乎将Agent的关键词Function Calling、MCP、Skills用完了的旅游助手;
第二个是新增的一个自媒体相关工具,会用一些奇奇怪怪的工具,至于如何将他们串起来,大家多多感受即可。
总之,都是Agent……