
Claude Code 又双叒叕更新了!!!
如果你平时没有持续盯着它的版本变化,隔一段时间再打开,大概率都会有一种熟悉又陌生的感觉:怎么又多了新命令,怎么又冒出来一些之前没注意过的新能力…
Claude Code 更新是很快的,但真正被大多数人用起来的,往往还是最基础的那几个命令,多数情况也就够了。
所以很多人对 Claude Code 的使用,还停留在“打开终端,开始对话”的阶段,最多再用一下 help 看看能做什么。
至于上下文管理、权限控制、技能扩展、自动化能力,知道的人不算少,但真正系统用起来的人并不多。
所以,要用好 CC 的关键不在于知道哪些指令,而是你知道这些命令分别该在什么时候用、为什么用。
本文会从实际使用场景出发,把 Claude Code 里那些常用、好用,但又容易被忽视的命令梳理清楚。
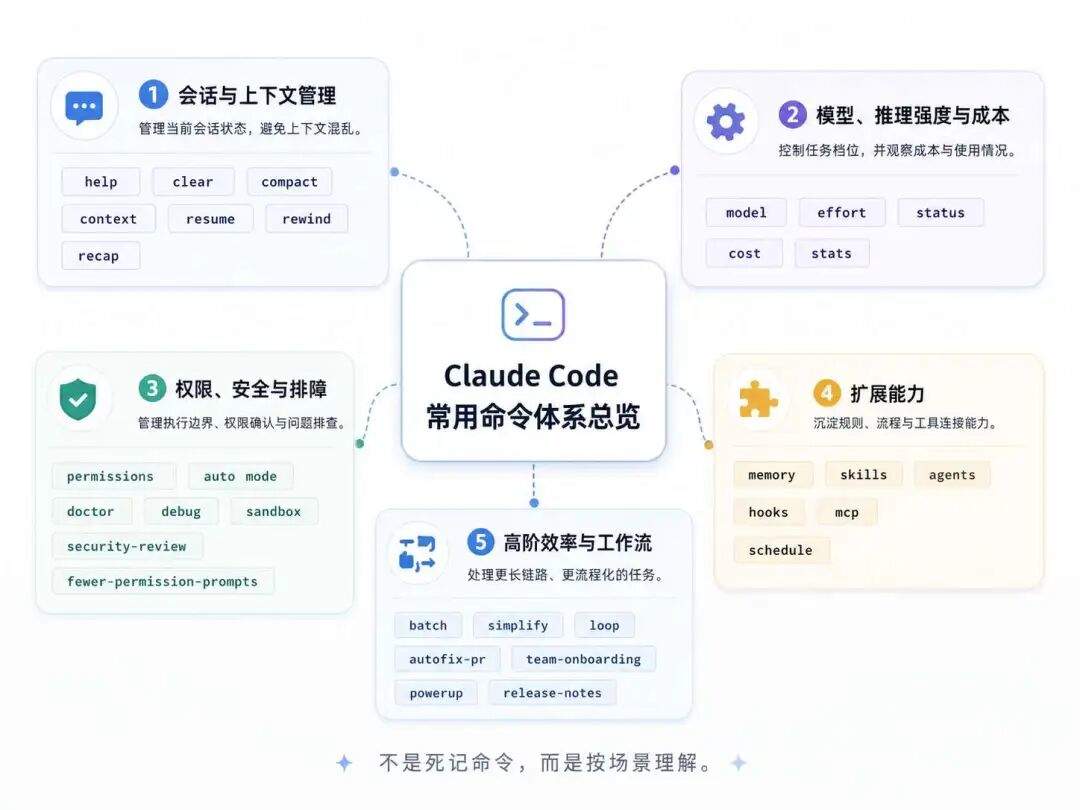
命令是什么
很多人刚开始用 Claude Code 时,对“命令”的理解其实比较简单:输入一个斜杠,加一个单词,执行一个动作。
但在 Claude Code 里,并不是所有 /命令 都是一回事:
-
有些属于内置命令,用来处理会话、上下文、模型、权限这类基础能力; -
有些虽然也是命令形式,但背后对应的其实是 skill; -
还有一些命令,本质上更像某种能力入口,真正连接的是 hooks、agents、MCP、schedule 这类更大的扩展机制;
这也是为什么,很多人明明知道不少命令名,真正用起来还是会觉得乱。问题往往不在于命令不够多,而在于还没有先把这套东西的结构看清楚。
Claude Code 里的这些命令,如果简单归类,大致可以分为 3 类。
这是从能力形态上做的粗分。后面真正展开时,我会按实际使用场景再拆成几组来讲。
1. 基础控制命令
这一类主要解决的是 Claude Code 自己怎么用的问题,比如清理会话、压缩上下文、切换模型、调整推理强度、查看状态、管理权限等。
这类命令最基础,也最常用,基本属于每天都会打交道的那一类。很多时候,Claude Code 用起来顺不顺手,差别往往就在这些基础命令的用法有没有跑偏。
2. 场景化能力命令
这一类命令已经不只是“执行一个动作”了,而是更像把某类任务封装成了一个入口。比如调试、批量处理、循环执行、PR 修复这类命令,背后其实更接近一段完整流程,而不是单点操作。
这类命令也可以理解成:你看到的是一个命令,实际调用的可能是一整套预设好的能力。
3. 扩展能力相关的命令
比如 memory、skills、agents、hooks、MCP、schedule 这些,更适合看成 Claude Code 通向扩展能力的一组入口。
它们和前面两类最大的区别是,前两类更多是在当前会话里更高效地做事,而这一类已经开始涉及怎么把能力沉淀下来、怎么接外部工具、怎么把重复动作变成长期可复用的流程了。
Claude Code 里的命令,并不是记得越多越有用,关键还是先把它们各自是干什么的、适合在什么场景下用搞清楚。
比起把命令一个个摊开来讲,按实际使用场景来拆,理解起来会更顺一些。
第一类:会话与上下文管理命令
会话与上下文管理是最重要的命令。
很多人觉得 Claude Code 越用越慢、越用越乱,第一反应往往是模型不行了,或者上下文太长了。问题当然可能出在这里,但更多时候,还是因为会话没有管好。
这类命令不一定高级,却几乎直接决定日常体验。用得顺,你会觉得它很跟手;用得不顺,很容易出现上下文混乱、指令串味、信息越来越臃肿的问题。
这一组里最值得先掌握的,主要有这几个:clear、compact、context、resume、rewind、recap。
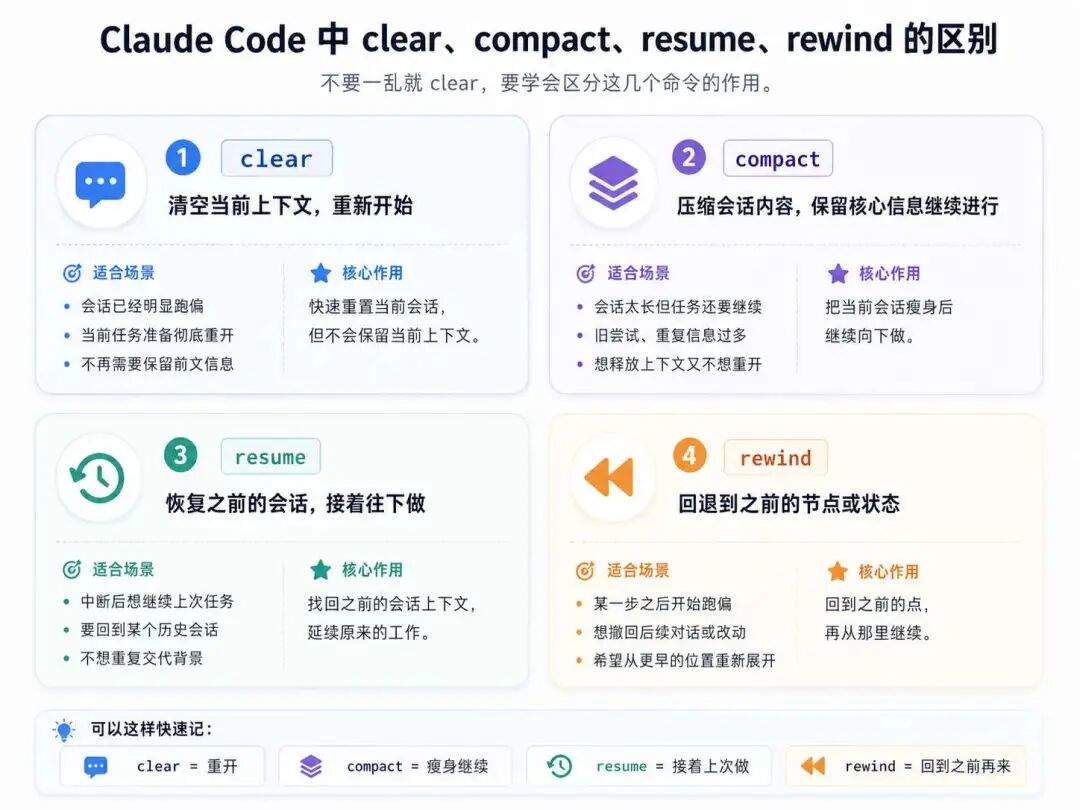
1. clear:彻底清空,重新开始
官方描述:
Start a new conversation with empty context. The previous conversation stays available in /resume.
简单理解:清空当前上下文,开始一段新的会话;之前的会话仍可通过resume找回。
clear 很好理解,就是把当前会话清掉,从一个全新的上下文重新开始。
这个命令几乎每个人都会用,但也最容易被用得过于粗暴。只要感觉聊乱了,就直接 clear,确实简单,但前面已经建立起来的任务背景、约束条件、上下文信息,也会一起被清掉。
所以 clear 更适合下面这几种情况:
-
当前任务已经彻底结束了,准备开始一个新话题 -
会话已经明显跑偏,继续救的价值不大 -
上下文里混进了太多无关信息,继续聊只会越来越乱
简单说,clear 适合“重开一局”,不适合拿来做日常整理。
2. compact:压缩上下文
官方描述:
Free up context by summarizing the conversation so far.
简单理解:通过总结当前会话内容,释放上下文空间。
如果说 clear 是彻底重开,那 compact 更像是“保留主线,清理包袱”。
这个命令非常重要,但很多人并没有真正用起来。
长时间使用 Claude Code 时,最常见的问题不是完全聊崩,而是上下文越来越长,里面混着旧尝试、废弃思路、重复描述、已解决的问题和已失效的指令。这个时候,真正需要的通常不是清空,而是把当前任务压缩成一个更干净、更聚焦的状态继续往下走。
你可以把它理解成一次“会话瘦身”:主线任务还在,必要信息还在,但那些已经不重要、或者会干扰后续判断的内容会被尽量压缩掉。
所以对大多数人来说,compact 应该是比 clear 更高频的命令。
尤其是在下面这些场景里,优先考虑 compact 通常会更合适:
-
任务还没做完,但对话已经很长了 -
中间试了很多方案,想保留结论、丢掉过程噪音 -
需要继续当前任务,但明显感觉上下文开始变重
很多人一觉得会话不顺,就条件反射式地 clear。但更稳的做法往往是先想一下:这个任务到底是该重开,还是只是该瘦身。如果只是后者,那 compact 会更合适。
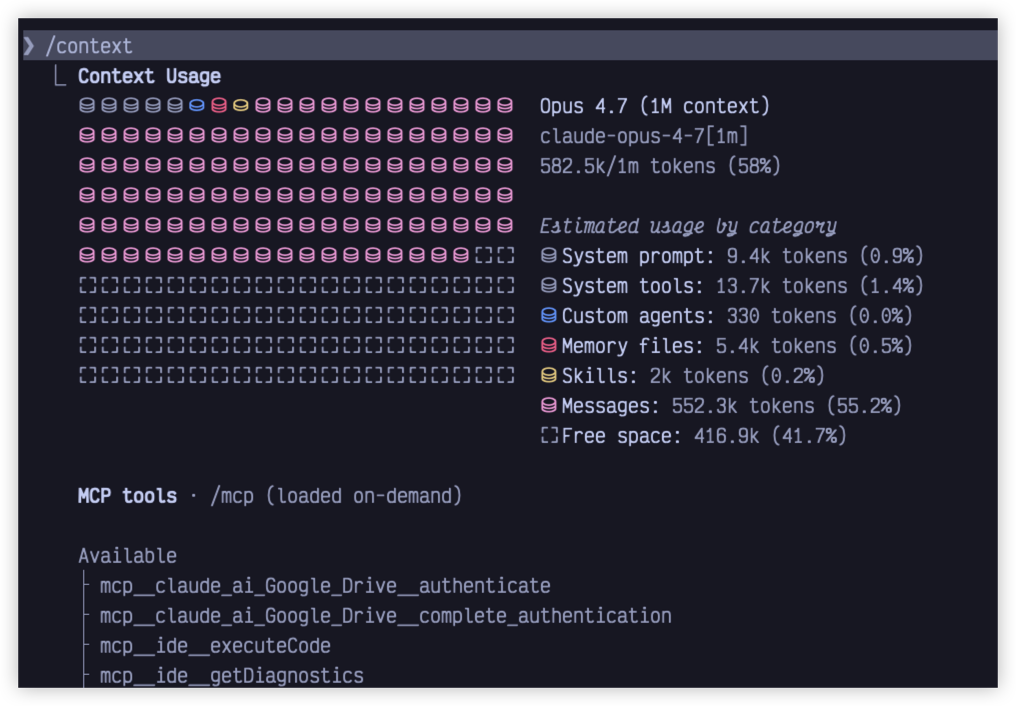
3. context:决定要不要收拾
官方描述:
Visualize current context usage as a colored grid. Shows optimization suggestions for context-heavy tools, memory bloat, and capacity warnings.
简单理解:以可视化方式查看上下文使用情况,并提示哪些内容可能过重。
有时候,会话到底算不算“重”,其实不完全靠感觉。
这时候 context 的价值就出来了。它更像一个查看当前上下文状态的入口:先知道现在大概处在什么状态,再决定下一步是继续聊、做一次 compact,还是干脆 clear。
它能帮你少一点拍脑袋。尤其是任务比较长、信息量比较大时,先看一眼上下文状态,再决定怎么处理,通常会更稳。
4. resume:上次没做完的
官方描述:
Resume a conversation by ID or name, or open the session picker.
简单理解:通过会话 ID、名称或选择器恢复之前的会话。
Claude Code 不是所有任务都适合一次聊完。
有些任务本来就跨度很长,中间可能会停下来,过一段时间再回来继续。这种时候,如果完全重新描述一遍背景,成本很高,也很容易漏信息。resume 的意义就在这里:把之前的会话接回来,减少重复铺垫。
这个命令适合那种“任务主线没变,只是中间暂停过”的情况。相比重新开一个新会话再手动补背景,resume 会省事很多。
5. rewind:不满意就往前退
官方描述:
Rewind the conversation and/or code to a previous point, or summarize from a selected message.
简单理解:将会话或代码状态回退到之前的节点,也可以从指定消息重新总结。
有时候问题不是整个会话都不能用了,而是某一段开始走歪了。
这种情况下,rewind 就很有价值。它更像是把会话或代码状态往前拨回去一点,让你从更合适的位置重新继续,而不是全盘推倒重来。
你可以把它理解成一种“撤回到前一个阶段”的能力。对于那种中途试错很多、但又不想把前面全部丢掉的场景,会比直接 clear 更细。
6. recap:先收个口,再继续
官方描述:
Generate a one-line summary of the current session on demand.
简单理解:按需生成当前会话的一句话摘要。
recap 的作用很适合放在长任务的阶段节点上。
比如一个任务已经聊了很久,这时候你自己也开始有点乱,不确定当前已经做到哪里、结论是什么、还剩什么没做。这个时候先来一个 recap,把当前进度和关键点收一下,再决定下一步怎么继续,通常会清爽很多。
它的价值不在于替代思考,而在于帮你把当前会话的状态整理成更容易继续推进的样子。
这一组命令到底该怎么用
如果把这一组命令放到一起看,其实可以把它们理解成一套“会话整理工具”:
-
clear负责重开 -
compact负责瘦身 -
context负责查看状态 -
resume负责续上次的任务 -
rewind负责往前回退 -
recap负责阶段性收口
这里面最容易被低估的是 compact。
很多人会用 clear,也知道 resume,但真正能明显改善日常体验的,往往是学会在合适的时候用 compact、context 和 recap。
因为这几个命令解决的不是“开新局”,而是“怎么把当前这局打得更顺”。
如果你现在对 Claude Code 的使用,还是偏向于一条会话从头聊到尾,或者一乱就直接 clear,那这一组命令很值得尽快熟悉起来。
第二类:模型、推理强度与成本相关命令
如果说上一组命令解决的是“会话怎么管”,那这一组解决的就是:这件事,到底该让 Claude Code 用什么状态来做。
很多人刚开始用 Claude Code 时,容易形成一个习惯:不分任务,统一上高配。小问题也想让它多想一会儿,简单修改也直接拉满,结果往往是成本上去了、响应变慢了,体感却未必更好。
问题不在于高配没有价值,而在于不是所有任务都值得这么配。
这一组里比较值得关注的,主要有这几个:model、effort、status、cost、stats。
1. model:先判断
官方描述:
Select or change the AI model.
简单理解:选择或切换当前使用的 AI 模型。
model 解决的是“让谁来做这件事”的问题。
这件事听起来像配置项,但实际非常关键。因为不同任务对模型能力的要求,本来就不是一个级别。
如果你只是让 Claude Code 做一些边界很清楚的事情,比如:
-
改一段已经很明确的代码 -
修一个已经定位清楚的小 bug -
调整样式、文案、配置 -
按照已经定好的方案补实现细节
这类任务更像执行题,重点是准确完成,不一定需要最强的分析能力。
举个例子。你在做一个 React 页面,只是想把弹窗里的按钮文案改掉,再补一个 loading 态。这个任务没有太多分析空间,Claude Code 只需要按要求把代码改对就行。像这种场景,过度追求模型配置,收益其实不明显。
但如果换一个场景,你接手了一个陌生项目,里面的下单流程有时成功、有时失败。你现在还不知道问题在前端状态、接口参数、权限校验,还是某个边界条件。这个时候让 Claude Code 先读代码、梳理链路、列可能原因,再决定怎么查,模型能力就会明显重要很多。
所以我更建议先问自己一个问题:这个任务是执行型任务,还是判断型任务?
执行型任务,优先考虑效率;判断型任务,再优先考虑能力。这个判断一旦做对,后面的体验会稳定很多。
2. effort:任务明确就收低,任务复杂再往上拨
官方描述:
Set the model effort level. Accepts low, medium, high, xhigh, or max; available levels depend on the model.
简单理解:设置模型的推理强度,可选档位会随模型不同而变化。
effort 解决的是“这次要不要让它多想一点”的问题。
这个设置很容易被误用。很多人的直觉是:既然更高的 effort 代表更深的思考,那默认开高一点,至少不会亏。但实际不是这样。
比如你已经知道问题出在哪了:submitOrder 调用前漏了一层判空,只需要补一个保护分支,再加一条 toast 提示。这个任务的目标已经非常明确,Claude Code 需要的是执行,不是推演。这个时候把 effort 拉很高,往往只是让一个本来几分钟能结束的问题变慢。
相反,如果你面对的是这类任务,就值得把 effort 往上调:
-
需求本身有歧义,需要先分析 -
有多个方案,需要比较取舍 -
代码链路很长,需要先读懂 -
问题来源不明确,需要排查原因 -
需要先整理思路,再决定怎么落地
再举个对比例子:
帮我给这个表单加上邮箱校验和提交按钮禁用逻辑
这是实现题,低一点的 effort 往往就够了。
帮我判断这个权限系统到底应该放在网关层、服务层,还是前端只做展示控制,并说明取舍
这是分析题,effort 就应该明显往上提。
所以 effort 最好不要长期固定在某个档位。我的理解很简单:任务明确,就收低;任务复杂,再往上拨。
3. status:确认当前状态
官方描述:
Open the Settings interface (Status tab) showing version, model, account, and connectivity.
简单理解:打开设置里的状态页,查看版本、模型、账号、连接状态等信息。
status 不是很有存在感的命令,但它很适合在“感觉哪里不对”的时候用。
比如你前面为了分析一个复杂问题,把模型切了,effort 也调高了。后来任务做完了,你开始让 Claude Code 帮你补几个小修改,结果发现它还是慢,回复也明显比平时重。
这时候很多人会下意识觉得:今天 Claude Code 状态不太好。
但更常见的情况其实是:你还停留在前面那套配置里。
这个时候先看一眼 status,就能避免很多靠感觉判断的问题。尤其是在你切过模型、改过配置、调过权限之后,status 更像是一个确认当前状态的入口。
只要你觉得它今天表现和我预期不一样,先别急着改 prompt,先看当前状态。
4. cost:成本意识
官方描述:
Alias for /usage.
简单理解:cost是usage的别名,用来查看会话成本、计划用量和活动统计。
cost 这个命令,很多人平时不太会主动看。
但只要你开始高频使用 Claude Code,它就很值得偶尔看一眼。
比如你觉得最近也没让 Claude Code 做什么特别大的事情,但花费就是不低。回头一看,问题可能不是某一次任务特别贵,而是很多本来很小的任务,也一直在用偏重的模型和 effort 去跑。
单次看不明显,累积起来就很明显。
cost 的意义不是让你盯着数字焦虑,而是帮你建立成本感。你会慢慢知道:哪些任务值得用更高配置,哪些任务其实是在用“高射炮打蚊子”。
当你开始频繁使用 Claude Code,或者尝试更高模型、更高 effort 时,可以定期看一下 cost。不是为了少用,而是为了用得更清楚。
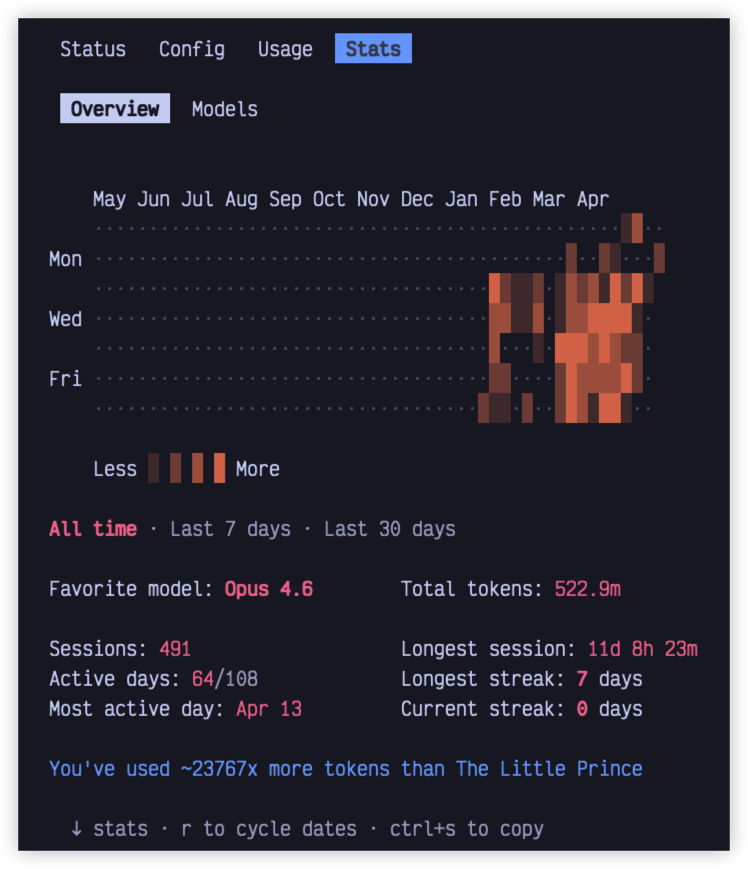
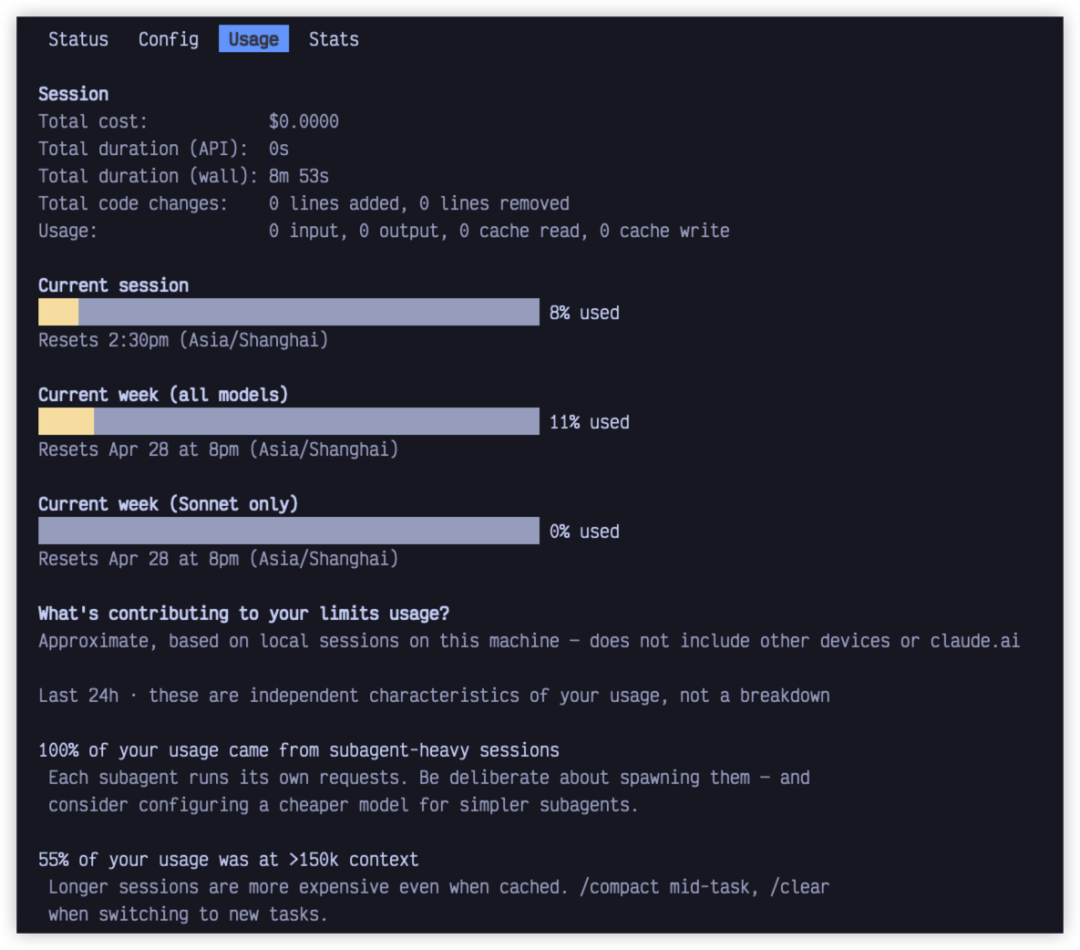
5. stats:看结构
官方描述:
Alias for /usage. Opens on the Stats tab.
简单理解:stats是usage的别名,会直接打开 Stats 标签页。
stats 可以理解成一个使用情况面板。它真正有价值的地方,不是告诉你一个孤立的数字,而是帮你看清楚:最近这段使用,到底把资源花在了哪里。
打开之后,我会重点看几个方向。
第一,看总成本。这不是为了制造焦虑,而是先建立一个大概的成本感。尤其是你连续几天都在高频使用 Claude Code 时,总成本能让你快速判断最近的使用是不是已经明显偏高。
第二,看Token 使用情况。这比单纯看成本更有参考价值。因为成本高,很多时候不是某一次任务特别夸张,而是上下文太长、会话太重、反复把大量历史信息带进去。比如一个小修改,本来几句话就能说清楚,但因为你一直在一个长会话里硬撑,每次请求都带着大量上下文,Token 自然会被不断放大。
第三,看时间维度。这里可以关注 API 实际耗时和真实使用时长之间的差异。比如你发现真实使用时间很长,但有效调用时间并不多,那问题可能不是模型慢,而是中间被你频繁打断、等待确认、来回补充上下文。反过来,如果 API 耗时本身就很长,那可能就要回头看模型、effort、上下文长度是否过重。
第四,看代码改动量。如果你花了不少成本,但代码改动很少,就要判断这次使用是不是主要消耗在“理解、分析、试错”上。这不一定是坏事,但它能提醒你:这类任务以后是不是应该先让 Claude Code 做计划和排查,再进入修改阶段,避免边想边改、来回返工。
第五,看活动分布。如果统计里能看到命令、会话或工具使用情况,就可以顺手看看自己的使用结构。比如是不是大量时间花在简单修改上,却一直沿用高 effort;是不是频繁进入长会话,却很少 compact;是不是一直在同类低风险操作上被权限确认打断。
举个例子:你连续一周都觉得 Claude Code 成本偏高,但又说不出为什么。
看一眼 stats,可能会发现:最近大量使用都集中在一些并不复杂的小修改上,但你几乎每次都沿用了之前分析复杂问题时的配置;同时上下文越来越长,却很少做 compact。这时候问题就很清楚了:使用方式不对。
所以 stats 最好不要只看一个总数,而是看几个问题:
-
成本是不是明显高于预期 -
Token 是不是被长上下文持续放大 -
时间主要花在模型调用上,还是花在等待和反复确认上 -
代码改动量和消耗是否匹配 -
使用结构是不是集中在一些低价值、高消耗的任务上
这样看,stats 就不只是统计数字,而是一次使用方式的复盘。
这一组命令到底该怎么用
这一组命令可以帮你建立一套简单的判断流程:先判断任务类型,再决定模型和 effort,最后通过 status、cost、stats 回头看自己的用法有没有跑偏。
这里面最常见的误区有两个。
一个是默认高配。不管任务大小,先把模型和 effort 往高了拉,结果就是更慢、更贵,但效果并没有明显更好。
另一个是从来不看反馈。一直在用,却从来不回头看状态、成本和统计,最后只能靠感觉判断“今天好不好用”“这个工具值不值”。
更稳的做法是:
-
执行型任务,优先考虑快和准 -
判断型任务,再考虑更强模型和更高 effort -
用一段时间之后,定期看 cost和stats -
感觉不对时,先看 status,不要全靠猜
这样一来,Claude Code 的使用就不再是“凭感觉调配置”,而是逐渐变成“按任务调档位”。
第三类:权限、安全与排障相关命令
如果说前两类命令解决的是“怎么聊得顺”和“怎么配得对”,那这一类命令解决的就是:为什么它明明看起来该能做这件事,但就是没做成。
很多人用 Claude Code 时,最常见的不适感不是回答不够聪明,而是下面这些情况:
-
想让它继续干活,结果一路弹确认 -
想调命令、调工具,结果权限不够 -
明明装了、配了,还是用不起来 -
报错是报错了,但根本不知道该从哪里查
这类问题看起来像“Claude Code 不太行”,但最后往往不是模型本身的问题。
更常见的原因是:权限没配好、环境没打通、执行边界没设清楚、排障入口没找对。
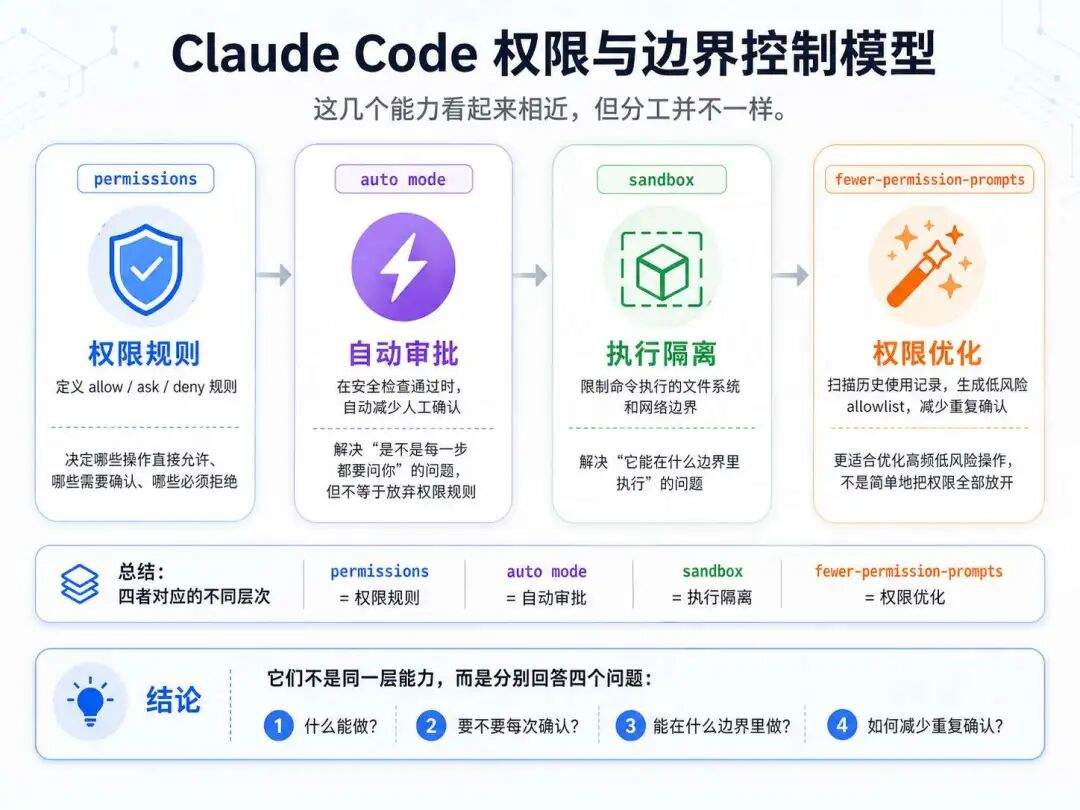
这一类里,最容易混在一起的是权限相关能力。可以先用一个模型理解:
|
|
|
|
|---|---|---|
permissions |
|
|
auto mode |
|
|
sandbox |
|
|
fewer-permission-prompts |
|
|
先把这几层分清楚,后面看 doctor、debug、security-review 这些排障和安全命令,就会顺很多。
这一组里比较值得重点关注的,主要有这些命令和能力:permissions、auto mode、doctor、debug、sandbox、security-review、fewer-permission-prompts。
1. permissions:别只点确认
官方描述:
Manage allow, ask, and deny rules for tool permissions.
简单理解:管理工具权限中的允许、询问和拒绝规则。
很多人第一次觉得 Claude Code “有点烦”,基本都是从权限确认开始的。
看个文件确认一次,跑个命令确认一次,改个内容可能还要再确认一次。单次不算什么,但连续做事时,这种反复确认会非常影响节奏。
这个时候不要只想着“能不能少问一点”,而是应该打开 permissions 看三件事:
-
哪些操作已经被 allow -
哪些操作仍然会 ask -
哪些操作已经被 deny
这三个词很关键。allow 代表 Claude Code 可以直接做,不再每次问你;ask 代表每次遇到都要确认;deny 代表直接禁止。真正要管理的是这三类规则之间的边界,而不是简单地全部放开。
第一类,低风险、高频、重复出现的操作,可以考虑 allow。
比如:
-
读取项目里的普通源码文件 -
搜索关键词 -
查看目录结构 -
执行 npm run lint -
执行 npm run test -
执行 git status、git diff这类只读检查
这些操作本身风险低,而且经常出现。如果每次都弹确认,效率会被切得很碎。像这类命令,就可以考虑加入允许规则,例如:
{
"permissions": {
"allow": [
"Bash(npm run lint)",
"Bash(npm run test *)",
"Bash(git status)",
"Bash(git diff *)"
]
}
}
第二类,有风险但不是绝对不能做的操作,建议保留 ask。
比如:
-
修改项目文件 -
执行构建脚本 -
安装依赖 -
执行迁移脚本 -
运行会改变本地状态的命令
这些操作不是不能让 Claude Code 做,但最好不要无脑放行。比如 npm install、pnpm install、数据库 migration、脚本修复这类动作,一旦执行就可能改变本地环境或项目状态,保留确认会更稳。
第三类,明确不希望它碰的东西,应该直接 deny。比如:
-
.env、.env.* -
secrets/** -
私钥、证书、凭据文件 -
生产配置 -
高风险命令,比如 git push、rm -rf、生产发布脚本
这类东西不要靠“我到时候看弹窗再判断”,最好一开始就写进 deny。比如:
{
"permissions": {
"deny": [
"Read(./.env)",
"Read(./.env.*)",
"Read(./secrets/**)",
"Bash(git push *)",
"Bash(rm -rf *)"
]
}
}
这里还有一个很容易忽视的点:deny 的优先级最高。 即使某个操作在别的地方被 allow 了,只要命中了 deny,仍然会被拦住。所以真正敏感的东西,要优先放进 deny,而不是只靠 ask。
另外,permissions 不是只能管 Bash。它也可以管文件读取、文件编辑、WebFetch、MCP 工具、Agent 等能力。比如你可以限制读取敏感文件,也可以限制某个 MCP server 下的工具,或者禁止某些 subagent 被调用。
所以这部分真正值得看的,不只是“弹窗太多怎么办”,而是你能不能把操作分成三层:
-
可以默认放行的低风险动作 -
需要人工确认的中风险动作 -
必须直接禁止的高风险动作
如果你准备长期使用 Claude Code,先把项目里的权限规则过一遍。尤其是 .env、密钥目录、生产脚本、发布命令、git push 这类东西,最好先 deny;lint、test、git status、git diff 这类高频低风险动作,再考虑 allow。
补充:auto mode 不是替代权限规则,而是减少确认疲劳
auto mode 很容易被误解成“有了它,就不用管 permissions 了”。这个理解不太准确。
auto mode 本质上是一个权限模式,目标是减少人工确认,让 Claude Code 在后台安全检查通过的情况下,自动批准更多工具调用。也就是说,它解决的是“要不要每一步都问你”的问题。
但 permissions 解决的是另一件事:你提前定义哪些事情可以做、哪些事情要问、哪些事情绝对不能做。
一个比较稳的理解是:auto mode 负责运行时判断,permissions 负责静态边界。
比如你开启了 auto mode,希望它能连续完成一个修 bug 的任务。但你仍然应该把 .env、密钥目录、生产脚本、git push 这类高风险内容放进 deny。这样即使 auto mode 倾向于减少确认,真正敏感的边界也不会被轻易越过。
如果只是个人小项目,auto mode 可以明显减少确认疲劳;但如果是公司项目、涉及敏感配置、生产脚本、客户数据,就不要只依赖 auto mode,还是应该配好 permissions,尤其是 deny 规则。
2. doctor:先体检,再排障
官方描述:
Diagnose and verify your Claude Code installation and settings.
简单理解:诊断并检查 Claude Code 的安装和配置状态。
doctor 适合解决那种“明明装好了,但就是不好使”的问题。
这类问题很常见:命令能启动,界面也正常,但一到具体功能就不对。比如某个工具调不起来,某个能力不生效,或者行为和你预期差很多。
这种时候最怕靠猜。你猜是模型问题,我猜是网络问题,折腾半天,最后发现只是认证状态不对、依赖没装好、某个环境项没有生效。
举个例子。
你刚装完 Claude Code,能正常进入对话,于是以为环境没有问题。结果开始接 MCP 或调用外部工具时,总是失败。这个时候很多人会直接去搜报错、改配置,甚至开始怀疑版本问题。其实更稳的顺序,是先跑一遍 doctor,看看基础环境、认证、配置有没有明显异常。
doctor 不一定能直接告诉你最终答案,但它能先帮你排除一批低级但高频的问题。
遇到“刚配置完但不好使”的情况,先跑 doctor,再去查更细的问题。
3. debug:别反复试错,要把问题卡在哪一层看清楚
官方描述:
Enable debug logging for the current session and troubleshoot issues by reading the session debug log.
简单理解:开启当前会话的调试日志,并通过日志排查问题。
有些问题,doctor 能帮你快速发现;但也有些问题,它只能告诉你有异常,没法直接告诉你根因。
这时候就该轮到 debug。
很多人排障时喜欢这样做:看到报错,改一点,再试一下;不行,再换个方向改一点。简单问题这么做没问题,但链路一复杂,就很容易变成撞运气。
比如你接了一个 MCP 服务,配置文件看起来没问题,但 Claude Code 调用时一直失败。这个时候如果只是反复改配置,很容易越改越乱。更有效的做法是打开 debug,先看清楚问题到底卡在哪一层:
-
是命令根本没执行到 -
是服务没有连上 -
是认证没过 -
是请求发出去了,但返回失败 -
还是 Claude Code 当前状态和你理解的不一致
能不能把这一层看清楚,决定了你是在排障,还是在试手气。
只要问题已经不是“一眼能看出来”,就不要一直靠猜,尽早打开 debug 看链路。
4. sandbox:让它更自由地干活,但只能在边界内干活
官方描述:
Toggle sandbox mode. Available on supported platforms only.
简单理解:在支持的平台上开启或关闭沙箱模式。
sandbox 最容易被误解成“限制”,但它真正解决的是另一个问题:如何让 Claude Code 在边界明确的前提下连续执行命令。
它和 permissions、auto mode 不是一层东西。
permissions 决定这个动作按规则能不能做;auto mode 决定这一次工具调用能不能自动放行;sandbox 则决定即使执行了,也只能碰哪些文件、目录和网络资源。
举个例子。
你让 Claude Code 帮你排查一个前端项目的构建失败。它可能需要读取 package.json、查看 Vite 配置、执行 npm run build、执行 npm run test、查看错误日志,甚至生成一些临时构建产物。
如果没有 sandbox,每次执行 Bash 命令都可能触发确认,你会被打断很多次。
如果只有 auto mode,它可能会自动判断这些操作比较安全,然后减少确认。但这些命令本身仍然是在你的真实环境里执行。
如果开启 sandbox,并且这些命令都能在沙箱边界内运行,那么 Claude Code 就可以更顺畅地完成这些只影响当前项目范围的操作。你不用每一步都点确认,同时它也不能随便写到项目外面、读不该读的敏感文件,或者访问不该访问的网络资源。
这就是 sandbox 的核心好处:减少低价值确认,同时保留执行边界。
它特别适合下面这些场景:
-
让 Claude Code 跑测试、跑 lint、跑 build -
让它在项目目录内做排查和验证 -
让它执行一些会产生临时文件或构建产物的命令 -
让它自动尝试修复问题,但不希望它越过项目边界 -
团队希望减少权限确认,但又不想完全放开 Bash 执行权限
不过 sandbox 不是万能安全开关。
有些命令需要访问项目外部路径,比如 ~/.kube、全局缓存目录、Docker、系统级工具,可能就需要额外配置写入路径,或者明确排除某些命令。还有些环境下 sandbox 需要平台支持和依赖,如果环境不支持,它可能并不会按你预期生效。
只要你开始让 Claude Code 执行命令,而不是只让它看代码、写建议,就应该认真了解一下 sandbox。它最大的好处不是“更安全”这四个字,而是让 Claude Code 在边界明确的前提下,真正进入连续工作的状态。
5. security-review:让 Claude Code 帮你做一次安全审查
官方描述:
Analyze pending changes on the current branch for security vulnerabilities.
简单理解:分析当前分支待提交改动中的安全风险。
security-review 直译过来就是“安全审查”。
它的作用也很直接:让 Claude Code 从安全角度检查当前代码或当前改动,帮你看看有没有明显的风险点。比如权限控制有没有漏、外部输入有没有校验、敏感信息有没有暴露、文件处理有没有边界问题、依赖或调用链路里有没有潜在风险。
所以它不是用来实现功能的命令,而是用来给功能“补一层安全检查”的命令。
很多时候,功能能跑通,并不代表它足够安全。尤其是 Claude Code 参与了代码修改之后,更应该有意识地补一层安全视角。
比如下面这些场景,就很适合用一下:
-
刚做完一轮比较大的代码改动 -
引入了新的依赖或新的执行链路 -
修改了权限、鉴权、数据处理相关逻辑 -
做了文件上传、回调接口、第三方集成 -
准备把某段流程固化成长期自动化能力
举个例子。你让 Claude Code 帮你补完一段上传文件的逻辑,功能测试没问题,文件也能正常传上去。但这里面有没有限制文件类型?有没有控制文件大小?有没有处理越权访问?有没有留下路径穿越之类的风险?这些问题不会因为功能跑通了就自动消失。
这时候补一轮 security-review,就比上线前临时想起来要稳得多。
只要改动碰到权限、数据、文件、外部输入,就顺手做一次安全审查。它不一定每次都能发现问题,但能帮你多一个安全视角,避免只盯着“功能有没有跑通”。
6. fewer-permission-prompts
官方描述:
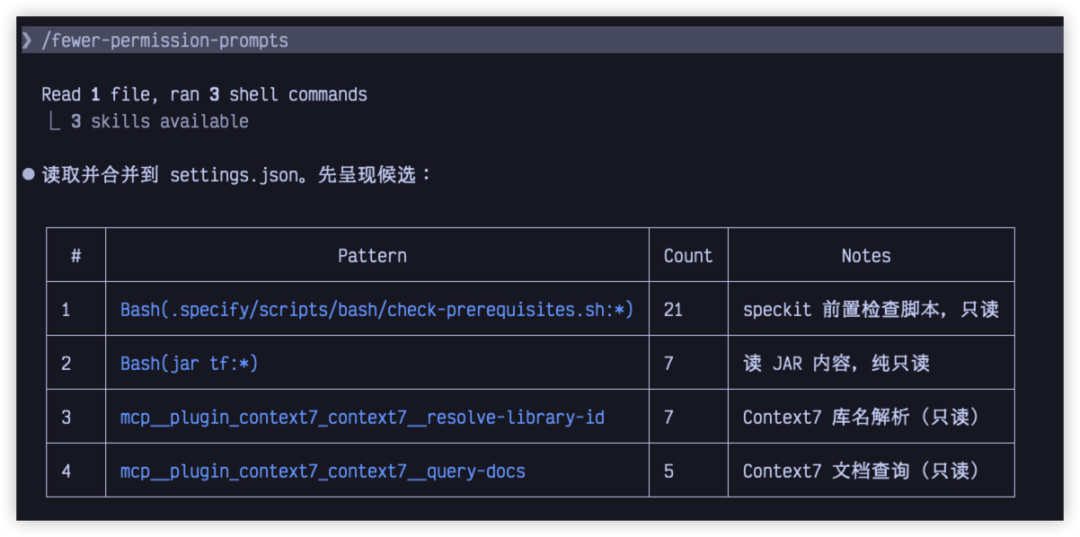
Scan your transcripts for common read-only Bash and MCP tool calls, then add a prioritized allowlist to project .claude/settings.json to reduce permission prompts.
简单理解:扫描历史使用记录,把常见低风险只读调用加入项目允许列表,减少权限确认。
fewer-permission-prompts 这个命令,如果只看名字,可能会以为它是某种“少弹窗模式”。
但它真正做的事情更具体:扫描你之前的使用记录,找出那些经常出现、风险较低的只读 Bash 命令和 MCP 工具调用,然后帮你把它们加入项目级 .claude/settings.json 的 allowlist。
也就是说,它不是让 Claude Code 以后什么都少问,而是帮你把“已经反复确认过、基本可以信任的低风险操作”沉淀成权限规则。
举个例子。假设你这几天一直在同一个前端项目里让 Claude Code 做这些事情:
-
执行 git status -
执行 git diff -
执行 npm run lint -
执行 npm run test -
调用某个只读 MCP 工具查询任务状态 -
调用某个只读 MCP 工具读取文档内容
这些动作每次都要你点确认。刚开始你可能会认真看,但连续点了十几次之后,大概率已经不是在审核风险,而是在机械点击。
这时候 fewer-permission-prompts 的价值就出来了。
它会基于你过去的使用记录,分析哪些只读命令和 MCP 工具调用反复出现,然后给出一份更适合当前项目的 allowlist。生成之后,这些低风险高频操作就可以少打断你。
所以 fewer-permission-prompts 更像是一个“权限优化助手”。
前面说的 permissions 是你手动定规则;auto mode 是运行时尽量少打断;sandbox 是限制执行环境;而 fewer-permission-prompts 的位置,是根据历史使用记录,帮你找出哪些低风险动作值得沉淀成 allowlist。
它不是替你做安全决策,也不是让你跳过权限体系,而是帮你回答一个很实际的问题:过去一段时间里,哪些确认其实已经重复太多次了,应该沉淀成规则?
这里要注意两点。
第一,它更适合优化只读、低风险、高频的操作。
比如 git status、git diff、测试命令、lint 命令、只读 MCP 查询,这些都比较适合。因为这些动作不会直接改代码、不会修改环境,也不会触碰生产系统。
第二,它生成 allowlist 之后,最好还是人工过一眼。
不要看到它推荐了一组规则,就直接无脑接受。尤其是涉及外部 MCP 工具时,要看清楚这个工具到底只是读取数据,还是可能触发写入、同步、发布、删除这类动作。
当你发现自己总是在同一类低风险操作上反复点确认,就可以跑一次 fewer-permission-prompts。它最适合解决的不是“我要完全放开权限”,而是“我想把那些已经反复确认过的低风险动作自动化掉”。
这样理解就比较清楚了:permissions 是你手动定规则,fewer-permission-prompts 是 Claude Code 根据你过去的使用记录,帮你找出哪些规则值得加入 allowlist。
这一组命令到底该怎么用
这一组命令其实是在帮你回答三个问题:
-
Claude Code 现在有没有权限做这件事 -
当前环境和执行链路是不是正常 -
这件事交给它做,边界和风险是否可控
这里面最常见的误区,是把所有异常都归因到“模型不行”。
但很多时候,问题要朴素得多:权限没配好,环境没打通,日志没往下看,边界也没有先设清楚。
所以这类命令真正的价值,不是“出问题了再补救”,而是让你把使用方式慢慢变稳:
-
经常被打断,先看 permissions -
刚装完或刚配置完不好使,先跑 doctor -
问题不是一眼能看懂,打开 debug -
涉及命令执行、文件修改、外部工具调用,考虑 sandbox -
涉及权限、数据、文件、外部输入,补一轮 security-review -
低风险确认太多,再用 fewer-permission-prompts优化
这样一来,Claude Code 才更像是在一个可控环境里稳定干活,而不是一边用、一边猜它下一步会不会掉链子。
第四类:扩展能力相关命令
前面几组命令,更多是在解决“当前这一次怎么用得更顺”。
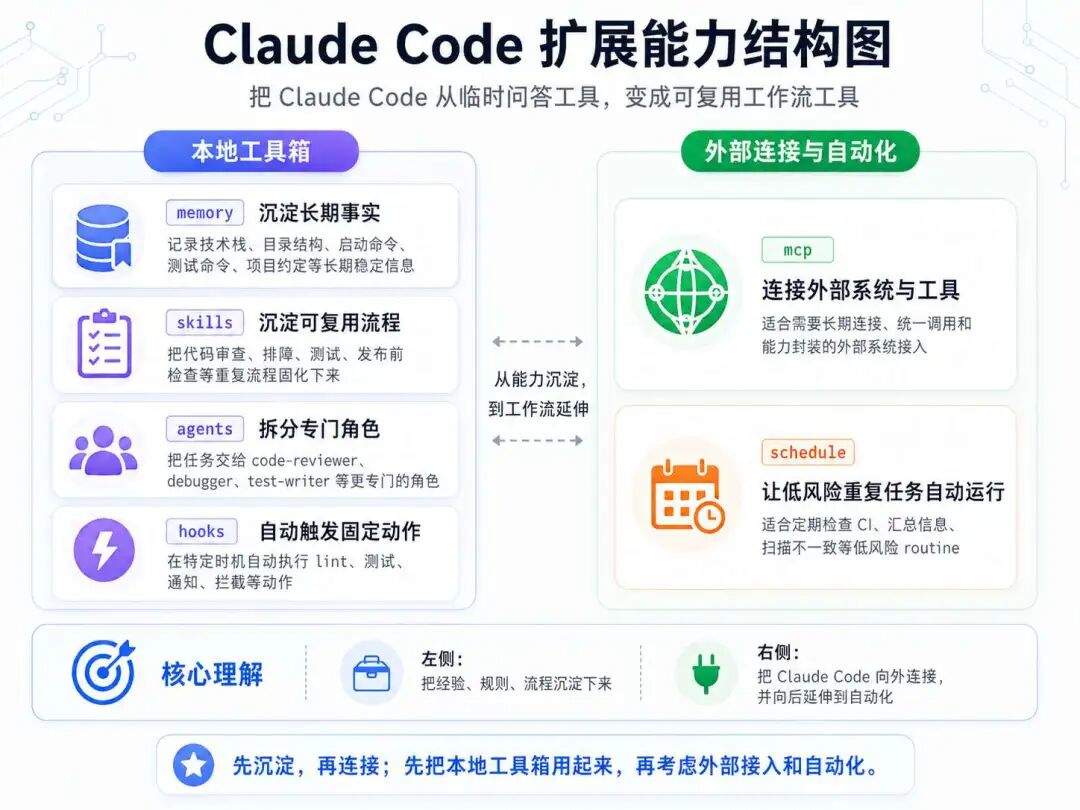
memory、skills、agents、hooks、mcp、schedule 这一组,解决的是更长期的问题:怎么把经验、规则、工具和流程沉淀下来,让 Claude Code 不只是临时帮你写几段代码,而是逐渐变成一个更贴合你工作方式的开发助手。
这一组命令看起来有点散,但可以分成两层理解。
第一层,是把团队经验沉淀成本地工具箱。
memory 负责记住长期事实,skills 负责沉淀可复用流程,agents 负责拆出专门角色,hooks 负责把固定动作挂到关键节点上。它们解决的是:Claude Code 如何更懂你的项目、更贴合你的团队习惯。
第二层,是向外连接系统,并把重复任务延伸成自动化流程。
mcp 负责连接外部工具和数据源,schedule 负责把重复任务变成 routine。它们解决的是:Claude Code 如何走出当前会话和当前目录,进入更完整的研发工作流。
这样看,这一组命令其实是在回答几个很关键的问题:
-
哪些信息应该长期记住 -
哪些流程应该沉淀成可复用能力 -
哪些任务适合拆给专门的 agent -
哪些动作可以自动触发 -
哪些外部系统可以接进来 -
哪些事情可以定时、重复、自动跑
这也是 Claude Code 真正开始拉开差距的地方。
1. memory:哪些东西应该长期记住
官方描述:
Edit CLAUDE.md memory files, enable or disable auto-memory, and view auto-memory entries.
简单理解:编辑CLAUDE.md记忆文件,开启或关闭自动记忆,并查看自动记忆内容。
memory 解决的是“哪些信息应该长期保留下来”的问题。
很多人刚开始用 Claude Code 时,会把项目里的所有规则、说明、约束、流程都往 CLAUDE.md 里塞。看起来很认真,但时间一长,很容易变成另一个问题:记忆文件越来越大,真正重要的信息反而被埋住了。
所以 memory 的关键不是“能不能记”,而是“什么值得记”。
我会把适合放进 memory 的内容,大致分成这几类:
-
项目长期稳定的技术栈 -
常用启动、测试、构建命令 -
代码风格和目录约定 -
团队明确要求遵守的规则 -
这个项目里长期有效的注意事项
比如一个前端项目长期使用 React、Vite、Ant Design、Biome,测试用 Vitest,这些信息就适合写进 memory。Claude Code 后面再做改动时,就不需要每次重新问你技术栈和测试命令。
但下面这些内容,就不太适合长期记住:
-
某一次临时排查结论 -
一次性需求背景 -
已经废弃的方案 -
当前会话里的中间尝试 -
只对某个短期任务有效的约束
这些东西如果都写进 memory,后面反而可能干扰判断。
举个例子。你今天让 Claude Code 临时绕过某个接口,因为后端还没联调完成。这个信息对今天有用,但过一周可能就过期了。如果它被长期记住,后面 Claude Code 可能还会继续沿用这个临时假设,导致新的实现方向跑偏。
所以 memory 里只放长期稳定、跨任务复用的信息,不要把它当成会话垃圾桶。
如果开启了 auto-memory,也要定期看一眼自动记住了什么。自动记忆不是坏事,但自动记住的内容不一定都适合长期保留。项目越大,这件事越重要。
2. skills:把重复流程沉淀成自己的命令
官方描述:
List available skills. Press t to sort by token count.
简单理解:查看当前可用的 skills,也可以按 token 占用进行排序。
skills 解决的是“重复流程怎么沉淀”的问题。
很多人会把 Claude Code 用成这样:每次做代码审查,都复制一大段审查要求;每次做故障复盘,都复制一套复盘模板;每次做接口联调,都重新描述一遍检查清单。
这样当然能用,但很累,也容易不一致。更好的方式,是把这些反复出现的流程沉淀成 skill。
比如你可以做这些 skill:
-
code-review:按团队规范做代码审查 -
api-review:检查 OpenAPI、字段命名、错误码、权限点是否一致 -
incident-review:按固定模板整理故障复盘 -
release-check:上线前检查分支、配置、测试、风险项 -
spec-check:检查需求文档、接口契约、验收标准是否一致
这样后面要用的时候,就不是每次重新写一大段 prompt,而是直接调用对应 skill。
这里有一个很关键的区别:CLAUDE.md 更适合放事实和规则,skills 更适合放流程和方法。
比如“这个项目使用 pnpm”是事实,适合放进 memory;“每次发布前要按 10 个步骤检查”是流程,更适合做成 skill。
还有一个好处是,skill 的正文不是每次会话一开始就全部塞进上下文,而是在需要时才加载。对于那些很长的检查清单、SOP、方法论文档,这一点非常重要。
举个例子。你有一套内部代码审查规则,里面包括命名规范、异常处理、权限校验、日志规范、测试要求。如果把这套内容全部塞进 CLAUDE.md,每次会话都带着,会很重;但如果做成 code-review skill,只有在你真正要审查代码时才加载,成本和干扰都会小很多。
只要你发现自己连续三次以上复制同一套提示词或检查清单,就应该考虑把它做成 skill。
3. agents:把任务交给专门的“角色”去做
官方描述:
Manage agent configurations.
简单理解:管理 subagent 配置。
agents 解决的是“复杂任务怎么分工”的问题。
如果说 skill 更像一套可复用流程,那 agent 更像一个专门负责某类任务的角色。
比如你可以有这些 agent:
-
code-reviewer:专门审代码质量和风险 -
test-writer:专门补测试 -
debugger:专门排查错误和失败用例 -
architecture-reviewer:专门看架构、边界和依赖关系 -
docs-writer:专门整理文档和说明
这类 agent 的价值,不是名字好听,而是它可以有自己的提示词、工具权限、模型、记忆和工作边界。
举个例子。你让主会话里的 Claude Code 同时完成“读代码、改实现、补测试、审风险、写说明”,它当然也能做,但上下文会很重,关注点也容易来回切。
如果任务比较复杂,你可以让主会话负责协调,把一部分工作交给专门的 agent。比如让 debugger 先排查失败原因,让 test-writer 补测试,让 code-reviewer 最后审一轮改动。
这时候主会话就不需要什么都亲自做,而是更像一个协调者。
不过 agent 也不是越多越好。
如果只是改一个按钮文案、补一个简单判断、修一个明确的小 bug,没必要专门拉 agent。agent 更适合下面这些情况:
-
任务需要明显分工 -
子任务之间相对独立 -
需要不同视角检查同一批代码 -
希望某类能力长期稳定复用 -
希望给不同角色配置不同工具和权限
不要急着创建一堆 agent。可以从最常用的两个开始:一个 code-reviewer,一个 debugger。前者负责把关质量,后者负责排查问题。用顺之后,再扩展到测试、文档、架构等方向。
4. hooks:把重复动作自动挂到关键节点上
官方描述:
View hook configurations for tool events.
简单理解:查看工具事件相关的 hook 配置。
hooks 解决的是“哪些动作不应该每次靠人提醒”的问题。
很多团队在用 AI 写代码时,最大的问题不是 Claude Code 不会写,而是它写完之后,有些固定动作总容易漏。
比如:
-
改完代码后忘了格式化 -
改完接口后忘了跑类型检查 -
改完关键文件后忘了跑测试 -
执行危险命令前没有二次提醒 -
修改配置后没有记录日志或通知
这些动作如果每次都靠你在 prompt 里提醒,就很低效。因为它们本质上不是“智能判断”,而是“固定流程”。
这正是 hooks 的价值。
hooks 可以在 Claude Code 的一些工具事件前后触发命令。你可以理解成:当 Claude Code 准备做某件事,或者刚做完某件事时,自动执行一段你预先配置好的脚本。
举个例子。
你可以配置一个 hook:只要 Claude Code 修改了前端代码,就自动跑 formatter 或 lint;如果它准备执行某些高风险 Bash 命令,就先拦下来或给出提示;如果它修改了某些关键目录,就自动跑对应测试。
这类事情不一定需要 Claude Code 每次“想起来”,而是应该交给 hook 固化。
这里要注意一点:hooks 和 skills 不一样。
skills 是给 Claude Code 的一套工作方法,偏“怎么做”;hooks 是工具事件触发的自动动作,偏“什么时候自动执行”。
比如:
-
“代码审查时要检查哪些内容”适合做 skill -
“每次修改后自动跑 lint”适合做 hook
凡是你在 prompt 里反复提醒 Claude Code 做的固定动作,都可以想一想是不是更适合放进 hooks。尤其是格式化、测试、校验、通知、危险命令拦截这类事情,非常适合自动化。
5. mcp
官方描述:
Manage MCP server connections and OAuth authentication.
简单理解:管理 MCP 服务连接和 OAuth 认证。
mcp 解决的是“Claude Code 如何连接外部系统和工具”的问题。
我现在更愿意先用一句话概括它的位置:CLI 是工具本身的操作入口,skill 是 Claude Code 的使用说明书,MCP 是 AI 客户端之间的标准连接层。
现在看外部工具接入,不能一上来就默认选 MCP。很多工具已经有成熟的官方 CLI,而且还配套了对应的 skill。比如 Playwright 可以通过 CLI 跑测试、生成用例、调试和查看报告;飞书也可以通过 lark-cli 完成文档、多维表、消息等操作。
这种情况下,优先考虑 CLI + 配套 skill 往往更合适:CLI 负责执行,skill 负责流程说明。这样既贴近工具本身的用法,也更容易控制输入输出。
比如 Playwright 场景,如果只是跑一遍 E2E 测试、调试失败用例、查看测试报告,直接走 Playwright CLI 就很自然。配套 skill 负责告诉 Claude Code 测试怎么跑、报告怎么看、失败后怎么处理。如果团队还有自己的约定,比如默认浏览器、测试目录、失败重试策略、报告输出格式,再基于现有 skill 做一层二次封装就够了。
飞书场景也类似。如果只是读取文档、更新多维表、拼接字段后写回,用 lark-cli 这类官方或团队维护的 CLI 会更轻。真正需要封装的,通常不是“怎么调用飞书”,而是你们自己的业务流程,比如更新前先 dry-run、输出必须是 JSON、批量更新前先校验记录、失败后保留原始响应等。
这也是 CLI + skill 的优势:CLI 负责把事情做了,skill 负责把事情按正确姿势做。
另外,在很多命令式、可脚本化的任务里,CLI + skill 通常也更省上下文。因为 Claude Code 只需要知道命令怎么用、参数怎么传、输出怎么读;skill 正文也只有在使用时才加载。而 MCP 往往需要暴露工具列表、参数 schema、工具说明和返回结构,工具多、说明长、返回内容大时,Token 消耗就会更明显。
当然,这不是说 MCP 没有价值。
MCP 更适合下面这些场景:
-
没有好用的官方 CLI,但有 API 可以封装; -
需要跨 Claude Code、Claude Desktop 或其他 AI 客户端复用; -
希望把一组工具以统一 schema 暴露给模型; -
需要统一 OAuth、权限边界和工具描述; -
工具能力比较复杂,不适合每次靠 shell 拼参数; -
需要团队级统一接入和治理。
所以我现在会用一个简单标准来判断:
-
一次性、命令式、可脚本化的任务,优先 CLI + skill; -
已有配套 skill 的工具,先用现成能力,再按团队流程二次封装; -
需要标准化、长期化、跨客户端复用的能力,再考虑 MCP。
6. schedule:把重复任务变成 routine
官方描述:
Create, update, list, or run routines. Claude walks you through the setup conversationally.
简单理解:创建、更新、查看或运行 routine,并通过对话式方式完成配置。
schedule 解决的是“哪些事情不需要你每次手动启动”的问题。
它对应的是 routines,可以理解成一类定时或可重复运行的 Claude Code 任务。
这类能力和 loop 有点像,但使用场景不完全一样。
loop 更像是在当前会话里反复跑某个提示,比如每 5 分钟检查一次部署结果;schedule 更像是把某个任务变成可管理、可重复运行的 routine,比如每天早上检查一次仓库状态,或者每周生成一次项目摘要。
举几个可能的例子:
-
每天早上汇总当前仓库的未合并 PR -
每天下班前检查 CI 失败情况 -
每周生成一次项目进展摘要 -
定期检查依赖升级风险 -
定期扫描文档和代码是否存在明显不一致 -
定期整理某个项目的最近变更
schedule 的价值,不是让 Claude Code “自动帮你写代码”,而是让一些原本需要你手动发起的固定检查,变成可持续运行的流程。
比如你负责一个长期项目,每周都要看一遍 PR、CI、近期改动和潜在风险。以前你可能每周手动打开几个系统查一遍,再让 Claude Code 帮你总结;如果这件事非常固定,就可以考虑做成 routine,让它按固定节奏跑。
不过这类能力也要谨慎。
因为一旦任务变成定时运行,它就不再只是“你当前盯着的一次会话”。如果 routine 会访问仓库、外部系统、敏感信息,就更应该提前配好权限、MCP、sandbox 和相关边界。
我的建议是:schedule 适合那些低风险、重复性强、输出以总结和提醒为主的任务。不要一上来就让它定时做高风险写操作。先从读、查、汇总、提醒开始,会更稳。
这一组命令到底该怎么用
这一组命令是在帮你把 Claude Code 从“临时问答工具”变成“可复用工作流工具”。
可以简单这样理解:
-
memory负责记住长期事实 -
skills负责沉淀可复用流程 -
agents负责拆出专门角色 -
hooks负责自动触发固定动作 -
mcp负责接入外部工具和数据源 -
schedule负责把重复任务变成 routine
这里面最容易混淆的是 memory 和 skills。判断标准很简单:
-
如果是一条长期事实,放 memory -
如果是一套操作流程,做成 skill -
如果需要一个专门角色长期处理某类问题,做 agent -
如果是固定时机自动执行的动作,配 hook -
如果需要连接外部系统,走 MCP -
如果需要定期重复执行,考虑 schedule
这组命令不一定是新手第一天就要全部掌握的,但它们决定了你能不能把 Claude Code 真正用深。
如果只是临时问问题,前面几组命令就够用了;但如果你希望 Claude Code 长期适配你的项目、你的团队、你的流程,那这一组迟早都绕不开。
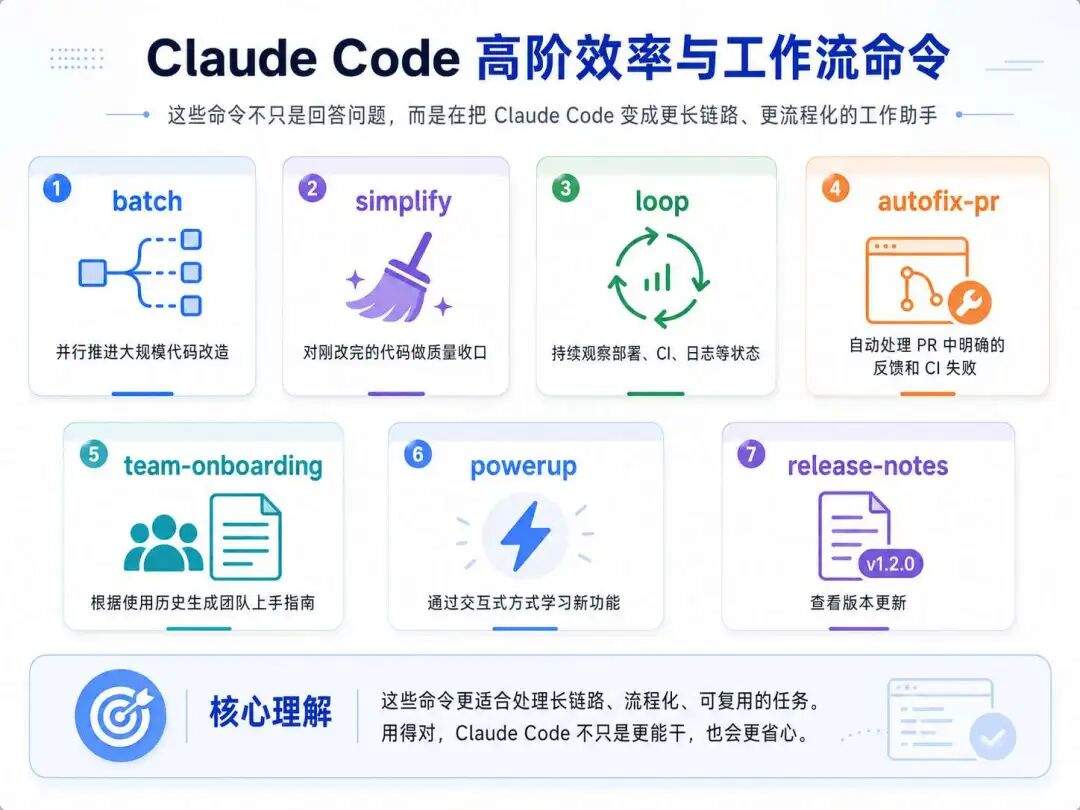
第五类:高阶效率和工作流命令
前面几类命令,更多是在解决 Claude Code 的基础使用体验。
batch、simplify、loop、autofix-pr、team-onboarding、powerup、release-notes 这些命令,平时不一定每天都会用,但一旦遇到合适场景,效率提升会非常明显。
它们的共同点是:不再只是执行一个小动作,而是更接近一个完整工作流。
比如批量改造代码、循环检查状态、自动修 PR、生成团队上手指南、学习新功能,这些都不是“问一句、答一句”的传统交互方式,而是在让 Claude Code 承担更长链路的任务。
这一类命令,我会把它理解成 Claude Code 的“效率放大器”。
1. batch:适合大规模、可拆分的代码改造
官方描述:
Orchestrate large-scale changes across a codebase in parallel.
简单理解:把大规模代码改造拆成多个独立任务,并行推进。
batch 不是用来修一个小 bug 的。
它更适合那种范围大、重复性强、可以拆分成多个独立子任务的代码改造。
比如:
-
把某个目录下的旧组件迁移到新组件体系 -
批量替换一套过时 API -
把多个模块从旧状态管理方案迁移到新方案 -
批量调整一类接口调用方式 -
在多个相对独立的模块里补同一种能力
这类任务如果只靠一个会话慢慢改,很容易出现两个问题:上下文越来越重,任务边界也越来越乱。
batch 的思路更像是:先研究代码库,再把任务拆成多个独立单元,然后并行交给后台 agent 处理。每个 agent 在自己的 git worktree 里实现、测试,最后提交 PR。
举个例子。
假设你要把 src/legacy 下面的一批旧页面逐步迁移到新的组件体系。这件事不太适合一次性塞给 Claude Code 让它在一个会话里全改完,因为文件多、范围大、上下文也容易乱。
但如果这些页面之间相对独立,就比较适合 batch:先让它分析哪些页面可以拆开迁移,再生成拆分计划,确认后并行推进。
不过 batch 也不是越用越好。
如果任务本身还没想清楚,或者多个模块之间强耦合,直接批量拆出去反而容易制造更多返工。
只有当任务满足三个条件时,再考虑 batch:
-
范围足够大; -
子任务之间相对独立; -
验收标准比较清楚。
如果只是一个局部修改,没必要上 batch。
2. simplify:改完之后,让它帮你收一轮
官方描述:
Review your recently changed files for code reuse, quality, and efficiency issues, then fix them.
简单理解:检查最近修改过的文件,发现复用、质量和效率问题,并尝试修复。
simplify 很适合放在一轮代码修改之后用。
很多时候,Claude Code 帮你把功能做出来了,但代码不一定已经足够干净。可能有重复逻辑,可能有临时实现,可能能跑但不够简洁,也可能某些地方可以复用却没有复用。
这时候 simplify 的价值就出来了。
它不是让 Claude Code 重新实现一遍功能,而是对最近改过的文件做一轮质量检查,并尝试把明显的问题收掉。
举个例子。
你让 Claude Code 连续改了一个表单页、一个接口封装和一个状态管理模块,功能已经跑通了。但你回头看代码,会发现有些校验逻辑写了两遍,有些 loading 状态处理比较散,有些错误提示没有统一。
这时候可以用 simplify 让它重点看代码复用、可读性、效率和重复逻辑。
如果你有特别关注的方向,也可以加上 focus,比如:
/simplify 重点检查重复的表单校验逻辑
或者:
/simplify 重点检查内存使用和性能问题
simplify 很适合放在“功能做完、提交之前”这个阶段。它解决的不是从 0 到 1,而是从“能跑”到“更干净”。
3. loop:让 Claude Code 持续盯一件事
官方描述:
Run a prompt repeatedly while the session stays open.
简单理解:在当前会话保持打开时,重复执行某个提示。
loop 解决的是“我不想一直手动问同一件事”的问题。
有些任务不是一次性完成的,而是需要持续观察。
比如:
-
等部署是否完成 -
等 CI 是否通过 -
每隔一段时间检查日志里是否还有错误 -
持续观察某个任务队列是否清空 -
反复检查某个页面或接口是否恢复正常
如果每次都手动问 Claude Code,一方面麻烦,另一方面也容易忘。
loop 更适合这种场景。
比如:
/loop 5m 检查部署是否已经完成
这类用法就很直观:每 5 分钟检查一次部署是否结束。
如果不传 interval,Claude Code 也可以自己控制节奏;如果不传 prompt,则可以跑一个自主维护检查,或者使用 .claude/loop.md 里的默认提示。
不过 loop 也要注意边界。
它适合持续观察、持续检查,不适合无边界地自动改代码。尤其是涉及生产环境、数据变更、外部系统操作时,不要让它长时间无监督执行高风险动作。
loop 优先用于“看”和“查”,谨慎用于“改”。比如检查部署、观察日志、确认 CI 状态都很适合;自动反复修改和发布,就要非常谨慎。
4. autofix-pr:让它盯着 PR 自动修反馈
官方描述:
Spawn a Claude Code on the web session that watches the current branch’s PR and pushes fixes when CI fails or reviewers leave comments.
简单理解:启动一个 Claude Code Web 会话,监听当前分支 PR,在 CI 失败或评审有评论时自动推送修复。
autofix-pr 这个命令很有代表性,因为它已经不是简单的本地命令了,而是把 Claude Code 接到了 PR 工作流里。
它适合解决这种问题:你已经提了 PR,但后面还有一堆零碎反馈需要处理。
比如:
-
CI 挂了,需要修 lint 或类型错误 -
Reviewer 留了几个小修改意见 -
测试失败,需要根据失败日志修一下 -
代码风格不一致,需要补格式化或调整命名
以前这些事情都要你自己反复看 PR、看 CI、改代码、push、再等结果。
autofix-pr 的价值在于,它可以启动一个远程 Claude Code 会话,监听当前分支对应的 PR。当 CI 失败或者 reviewer 留评论时,自动尝试修复并 push。
举个例子。
你提了一个 PR,核心实现已经没问题,但 CI 里挂了几个类型错误,还有 reviewer 提了两个命名建议。这个时候你可以让 autofix-pr 处理这些明确、局部、可验证的问题,而不是一直自己盯着。
不过这个命令有前提。
它需要 gh CLI,也需要能访问 Claude Code on the web。并且它默认会根据当前 checkout 的分支识别 PR;如果你要处理别的 PR,需要先切到对应分支。
autofix-pr 很适合处理明确反馈和 CI 失败,不适合自动处理大范围设计争议。比如 lint、类型错误、测试失败、review 小建议,都比较适合;涉及架构方向、产品取舍、复杂重构,还是应该人工先判断。
5. team-onboarding:把你的使用经验整理给团队
官方描述:
Generate a team onboarding guide from your Claude Code usage history.
简单理解:根据你的 Claude Code 使用历史,生成一份团队上手指南。
team-onboarding 是一个很容易被忽视,但挺有意思的命令。
它不是帮你写代码,而是帮你把过去一段时间怎么用 Claude Code 的经验整理出来。
比如它会根据你最近的使用历史、命令、MCP server 等信息,生成一份 markdown 指南,方便团队其他成员快速上手。
这个命令适合下面这些场景:
-
团队准备统一推广 Claude Code -
已经有人先试用了一段时间,希望把经验同步给其他人 -
项目里已经形成了一些固定用法,但还没写成文档 -
新成员加入项目,需要快速知道怎么用 Claude Code 配合当前仓库
举个例子。
你自己已经在某个项目里用 Claude Code 跑通了很多流程:怎么跑测试、怎么做代码审查、怎么调用内部 CLI、哪些权限可以放开、哪些目录不能碰。其他同事如果从零摸索,会很慢。
这时候用 team-onboarding 生成一份初稿,再人工补充和删改,就比从零写团队指南快很多。
不过它生成的是“基于历史使用的初稿”,不是最终制度。
可以把它当成团队 Claude Code 使用规范的起点,但不要直接不审就发给团队。尤其是涉及权限、MCP、内部工具、敏感目录时,要人工过一遍。
6. powerup:更新太快,就让它带你补课
官方描述:
Discover Claude Code features through quick interactive lessons with animated demos.
简单理解:通过带动画演示的交互式小课程,了解 Claude Code 的功能。
powerup 很适合解决一个现实问题:Claude Code 更新太快,很多新功能你根本来不及一个个看文档。
它不是生产力命令,而是学习命令。
比如你隔了一段时间没关注 Claude Code,回来发现多了新的权限模式、新的 Web 能力、新的 routines、新的 review 能力。这时候直接翻 changelog 当然可以,但不一定有体验感。
powerup 的作用,就是用比较短的交互式课程,让你快速理解某些功能怎么用。
如果你觉得自己只会用最基础的几个命令,可以先跑一遍 powerup。它不一定解决当前任务,但能帮你发现一些原来不知道的能力。
尤其是 Claude Code 最近这种更新节奏,定期用它补一下课,比一直靠别人转发新功能截图要靠谱。
7. release-notes:别等别人告诉你又更新了
官方描述:
View the changelog in an interactive version picker. Select a specific version to see its release notes, or choose to show all versions.
简单理解:通过交互式版本选择器查看 changelog 和 release notes。
release-notes 是一个特别适合放在这篇文章结尾前的命令。
因为这篇文章的起点本身就是:Claude Code 更新太快,很多人不知道新命令怎么用。
release-notes 解决的就是这个问题:不要只等别人总结,也不要只靠别人转发的截图,自己可以直接在 Claude Code 里看版本更新。
它适合下面这些场景:
-
隔了一段时间没用 Claude Code,想看看最近更新了什么 -
看到别人提到一个新命令,但自己不确定从哪个版本开始有 -
某个命令行为变了,想回头看 release notes -
想确认最近有没有和权限、MCP、skills、routines 相关的更新
举个例子。
如果你突然发现某个命令不见了,或者行为和之前不一样了,与其第一时间怀疑自己配置错了,不如先看一眼 release-notes。Claude Code 现在更新很快,有些命令会新增、改名、移除,release notes 反而是最直接的确认入口。
可以把 release-notes 当成 Claude Code 的“版本说明入口”。尤其是你看到一个新功能,但自己本地没有,或者命令行为和别人不一样时,先查版本,再判断是不是环境、套餐、平台或功能开关的问题。
这一组命令到底该怎么用
如果把这一组放在一起看,它们更像是处理“长链路任务”的命令:
-
batch适合大规模、可拆分的代码改造 -
simplify适合功能做完后的代码收口 -
loop适合持续观察状态 -
autofix-pr适合处理 PR 后续反馈 -
team-onboarding适合把个人经验整理成团队指南 -
powerup适合快速学习新能力 -
release-notes适合跟踪版本变化
这类命令不一定是每天最高频的,但很适合在特定节点发挥作用。
我的判断是:
-
做大规模改造,先想 batch -
改完代码想收质量,试试 simplify -
需要持续观察状态,用 loop -
PR 后续反馈比较明确,用 autofix-pr -
团队要推广 Claude Code,用 team-onboarding -
自己跟不上更新,用 powerup和release-notes
这一组命令的价值,不是让你在日常小任务里多打一堆命令,而是在遇到更长、更重、更重复的任务时,知道 Claude Code 其实已经提供了更合适的入口。
如果只想先记一小部分,应该从哪些命令开始
前面讲了这么多命令,可能有人会觉得:看起来都挺有用,但一下子记不住。
这很正常。Claude Code 的命令不需要一次性全学完,更合理的方式是按使用阶段来选。
刚开始用,先把基础体验打顺;高频使用后,再关注权限、成本、上下文和排障;如果要推广到团队,再看 skills、hooks、agents、MCP、schedule 这些更偏工作流的能力。
1. 新手先掌握这 6 个就够了
如果你只是刚开始用 Claude Code,可以先从这 6 个命令开始:
-
help -
clear -
compact -
model -
effort -
permissions
help 用来知道当前环境里到底有哪些命令。这个很重要,因为 Claude Code 的命令会受版本、平台、套餐、配置影响,不同人看到的命令可能不完全一样。
clear 和 compact 负责处理上下文。前者是重开,后者是瘦身。新手最容易犯的错误,就是一乱就 clear,但很多时候更适合先 compact。
model 和 effort 负责控制任务档位。不要所有任务都默认高配,也不要所有问题都用同一个思考强度。执行题和判断题,应该区别对待。
permissions 负责减少使用摩擦。只要开始让 Claude Code 读文件、跑命令、改代码,就一定会遇到权限确认。早点把 allow、ask、deny 的关系搞明白,后面会顺很多。
新手阶段,不建议一上来就研究所有高级能力。先把这几个命令用顺,日常体验会提升很明显。
2. 高频使用者重点看这几类
如果你已经每天都在用 Claude Code,就不能只停留在“会问问题”这个层面了。
这时候更应该关注这些命令:
-
context -
stats -
cost -
doctor -
debug -
sandbox -
fewer-permission-prompts
context 帮你判断当前会话是不是已经太重。
stats 和 cost 帮你看使用结构和成本,不要一直凭感觉判断“今天是不是变贵了”“是不是变慢了”。
doctor 和 debug 用来排查环境和调用问题。尤其是接 MCP、CLI、外部工具之后,不要一出错就怀疑模型,先看是不是环境、认证、配置、权限出了问题。
sandbox 和 fewer-permission-prompts 更偏效率和安全之间的平衡。前者让 Claude Code 在边界内连续干活,后者帮你把低风险、高频确认沉淀成 allowlist。
这个阶段的重点不是“多知道几个命令”,而是让 Claude Code 更稳定、更省心、更可控。
3. 团队使用重点看这几类
如果你已经不是自己一个人在用,而是希望把 Claude Code 推到团队里,重点就要变了。
个人使用时,很多事情可以靠习惯解决;团队使用时,就必须靠机制解决。
这时候最值得关注的是这些命令:
-
memory -
skills -
agents -
hooks -
mcp -
schedule -
team-onboarding
memory 负责沉淀长期事实,比如技术栈、目录结构、启动命令、测试命令、项目约定。
skills 负责沉淀团队流程,比如代码审查、接口检查、发布前检查、故障复盘、需求验收。
agents 负责把复杂任务拆给更专门的角色,比如 code-reviewer、debugger、test-writer。
hooks 负责把固定动作自动化,比如改完代码自动 lint,执行危险命令前拦截,修改关键目录后自动测试。
mcp 和 CLI + skill 的关系前面已经讲过。团队场景里,更重要的不是“接得多”,而是判断哪些能力应该通过 CLI + skill 落地,哪些能力值得做成 MCP 这类长期连接层。
schedule 适合把低风险、重复性的检查任务变成 routine,比如定期检查 CI、汇总 PR、扫描文档和代码是否不一致。
team-onboarding 适合在团队推广初期使用。它可以根据已有使用历史生成上手指南,再由人修订成团队规范。
团队阶段真正要解决的,不是每个人会不会用某个命令,而是能不能把好的用法固化下来,让大家用得一致、可控、可复用。
4. 我的个人优先级
如果按优先级排,我会这样分:
第一优先级:compact、permissions、model、effort。
这几个直接影响日常体验。上下文管不好,权限理不顺,模型和 effort 乱用,Claude Code 很容易变得又慢又贵,还不好控。
第二优先级:context、stats、cost、doctor、debug。
这几个让你从“凭感觉使用”变成“有反馈地使用”。会话是不是太重、成本是不是异常、环境是不是有问题,都可以更快看出来。
第三优先级:skills、hooks、agents、sandbox。
这几个决定你能不能把 Claude Code 用深。一个人临时用,可能没那么强烈;但只要你要长期用、团队用、稳定用,这些能力迟早要看。
第四优先级:mcp、schedule、batch、autofix-pr。
这几个更看场景。用得对会很强,用得早了反而可能增加复杂度。比如 MCP 不是所有工具都要接,schedule 也不适合一上来就跑高风险写操作,batch 更适合大规模、可拆分的任务。
不要看到新命令就急着都学一遍。更好的方式是:先解决日常摩擦,再解决稳定性,再沉淀流程,最后再上更重的自动化。
5. 按场景快速查命令
最后放一张速查表,方便你在具体场景里快速找到入口。
|
|
|
|---|---|
|
|
context
compact、clear |
|
|
resume |
|
|
rewind |
|
|
recap |
|
|
model
effort、cost、stats |
|
|
status |
|
|
permissions
fewer-permission-prompts |
|
|
auto mode
sandbox、permissions |
|
|
doctor |
|
|
debug |
|
|
security-review |
|
|
memory |
|
|
skills |
|
|
agents |
|
|
hooks |
|
|
mcp |
|
|
schedule |
|
|
batch |
|
|
simplify |
|
|
loop |
|
|
autofix-pr |
|
|
team-onboarding |
|
|
powerup |
|
|
release-notes |
这个表不是让你一次性全记住,而是帮助你在具体场景里快速定位命令。
结语
很多人学习 Claude Code,第一反应是研究 prompt。
这当然重要。你问得清不清楚,任务描述得准不准,都会直接影响结果。但用久了之后会发现,只会写 prompt 还不够。
Claude Code 真正好不好用,很大程度上取决于你有没有把它当成一个完整工具来管理:上下文怎么收、模型和 effort 怎么选、权限边界怎么定、哪些流程要沉淀、哪些工具该接进来、哪些重复任务可以自动化。
所以,Claude Code 的命令不是拿来背的。更重要的是知道:什么时候该用哪个,为什么要用它,用了之后能解决什么问题。
这也是这篇文章想表达的核心:
Claude Code 最值得学的,不只是怎么问,还有怎么用。
如果你现在还只会打开终端直接提需求,最多再用一下 help,也没关系。先从几个高频命令开始,把上下文、权限、模型和成本理顺,就已经能明显改善体验。
至于 skills、hooks、agents、schedule、MCP 这些更重的能力,可以等你真的有重复流程、团队协作和外部工具接入需求时,再一步步往上加。
不要为了“高级”而高级。先解决真实问题,再选择合适命令。这才是 Claude Code 更稳定、也更长期的用法。